Do Legado ao Lakehouse: Como a Mazda Acelerou a GenAI para Operações de Serviço Técnico
Como uma equipe enxuta construiu um assistente GenAI governado usando RAG, Unity Catalog e AI Search
por Tim Marx (Mazda), Foon Hoe Campbell-Wong (Mazda), Jiayi Wu, Arthur Dooner e Olivia Zhang
- Como a Mazda usou o Databricks Lakehouse para reunir histórico de serviço, diagnósticos e documentos como base para GenAI
- Como a equipe projetou o assistente GenAI, incluindo recuperação dos documentos corretos e lógica de compartilhamento entre a interface do usuário e o agente
- Como a Mazda passou de testes GenAI ad‑hoc para avaliações repetíveis e casos de teste usando MLflow
Organizações de serviços automotivos estão sob pressão. O volume de chamadas continua a aumentar, os veículos elétricos introduzem nova complexidade de diagnóstico e os carros conectados geram mais dados do que os agentes de suporte técnico conseguem analisar realisticamente. Cada ano de modelo traz centenas de documentos de informações de serviço (SI), cada um com procedimentos e condições exclusivas. Quando algo muda, os agentes de suporte técnico precisam de tempo para absorver essas informações antes de poderem orientar com confiança os técnicos em questões desconhecidas. Essa demora importa quando um cliente está esperando.
A Mazda já possuía os ingredientes brutos para resolver isso: um crescente lakehouse de dados de garantia, recalls, códigos de diagnóstico, histórico de serviço e de veículos, bem como uma biblioteca em constante atualização de documentos de serviço. O desafio era reunir esses ativos de forma a aprimorar a capacidade dos agentes de realizar seu trabalho com precisão, consistência e confiança.
Foi aí que a Databricks entrou. A equipe de ciência de dados da Mazda agiu rapidamente e aprendeu fazendo, passando do pontapé inicial a um conceito funcional em aproximadamente oito semanas. Não houve uma longa fase de planejamento. A equipe construiu, testou, quebrou coisas e ajustou conforme avançava, entregando um piloto que trouxe impacto e valor reais para a Mazda.
Ponto de Partida: Uma Equipe Enxuta com Grandes Ambições
Este projeto foi uma das primeiras iniciativas de GenAI ponta a ponta da Mazda, construída inteiramente em sua nova plataforma de dados na nuvem. A equipe era pequena — dois cientistas de dados iterando rapidamente — e as ferramentas eram iniciais. Pipelines de dados precisavam ser construídos. Documentos precisavam ser extraídos e transformados em índices de busca vetorial. Experimentos viviam em notebooks isolados, e o sucesso dependia mais da memória do que da rastreabilidade.
Para uma equipe tão enxuta, a sobrecarga de infraestrutura tinha que ser mínima. Esse foi um fator importante na escolha da Databricks. A plataforma permitiu agilidade: sem gerenciar bancos de dados vetoriais, sem configurar frameworks de computação distribuída, sem orquestração personalizada, sem serviços de cola para juntar tudo. O foco é na construção de valor — não em infraestrutura.
Construindo o Piloto
No início do piloto, a equipe se concentrou em um design de Geração Aumentada por Recuperação (RAG), com o foco principal em conectar um LLM ao nosso corpus personalizado. Logo, a Mazda percebeu que os testadores frequentemente queriam que os agentes tivessem um quadro completo do veículo primeiro: seu histórico de serviço, recalls em aberto, escalonamentos anteriores de suporte técnico, status de garantia.
Essa observação moldou uma escolha arquitetural deliberada: o frontend e o agente compartilham código e ferramentas. O acesso aos dados do veículo, a transformação e a lógica de prompting são implementados uma vez e usados de forma idêntica tanto pela interface Streamlit quanto pelo endpoint do agente implantado.
Quando um agente de serviço insere um VIN no início de uma sessão, o frontend pré-carrega o contexto completo do veículo (histórico de reparos, escalonamentos de suporte técnico, dados de garantia, status de recall) e o injeta no prompt do sistema antes que a primeira mensagem seja enviada. Isso elimina chamadas de ferramentas e fornece interatividade imediata.
Por outro lado, se o agente de IA for invocado sem esse contexto pré-carregado, ele usará a mesma caixa de ferramentas com a qual os usuários interagem. A saída é estruturalmente idêntica de qualquer forma, e o prompt do sistema lida explicitamente com ambos os caminhos: usar o contexto injetado, se presente, chamar ferramentas, se não. Um prompt, dois modos de execução, sem desvios de comportamento entre as superfícies.
Unity Catalog
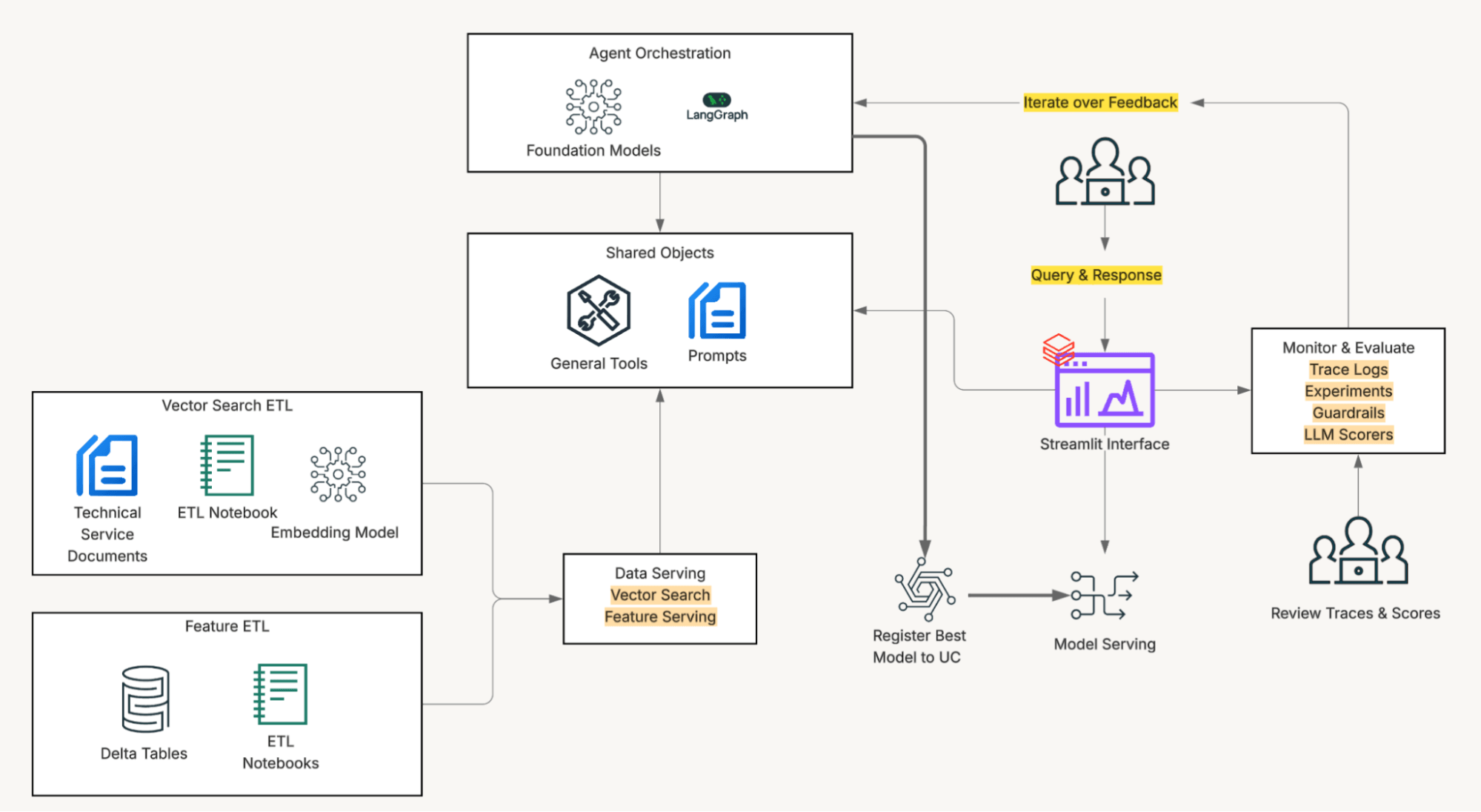
A solução é alimentada pelo Databricks Lakehouse. O Unity Catalog fornece acesso governado aos dados que os agentes de serviço utilizam diariamente, e onde embeddings, busca vetorial, chamadas de ferramentas SQL e serviço de modelos são executados no mesmo ambiente, simplificando o desenvolvimento e removendo atritos de integração. A Mazda utilizou LLMs através da API de modelos de fundação (pago por token) e modelo de embedding através do endpoint de busca vetorial gerenciado.
Tudo reside dentro do Unity Catalog: documentos SI, tabelas Delta com histórico de veículos e códigos de diagnóstico, índices de busca vetorial, transformações de dados e modelos. A governança unificada significa a capacidade de isolar o acesso a subconjuntos específicos de dados, fazer alterações dinamicamente e observar o impacto imediatamente. Em seguida, o Databricks Apps une tudo com um frontend Streamlit que as equipes de serviço podem usar sem treinamento ou ferramentas novas.
Filtragem Precisa do Corpus, Habilitada por Funções do Unity Catalog
Uma busca vetorial ingênua em todo o corpus retorna resultados semanticamente plausíveis, mas não necessariamente aplicáveis ao veículo em frente ao técnico. Acertar a recuperação significou resolver um problema de escopo antes de resolver um problema de relevância.
A equipe implementou a filtragem através de funções definidas pelo usuário do Unity Catalog. Antes que qualquer busca vetorial seja executada, o sistema chama uma função UC que mapeia o VIN (ou código de diagnóstico de falha) para o subconjunto de documentos aplicáveis àquele veículo, restringindo a correspondência semântica apenas aos documentos que se aplicam.
Hospedar essa lógica como uma função do Unity Catalog, em vez de código de aplicação, significou que as regras de aplicabilidade ficam ao lado dos dados que governam, são acessíveis tanto para o agente quanto para qualquer outra aplicação downstream, e podem ser atualizadas independentemente do ciclo de implantação do agente.
De Testes Ad Hoc a Testes Orientados por Testes
A Mazda pilotou a aplicação com 10 testadores agentes de serviço. No início do piloto, a iteração foi baseada em feedback: os testadores relatavam problemas, a equipe ajustava prompts ou configuração de recuperação e avaliava o resultado informalmente. Isso funcionou para o desenvolvimento inicial, mas não escalou à medida que o sistema se tornava mais complexo.
O framework de avaliação GenAI nativo do MLflow 3 mudou o fluxo de trabalho da equipe. O MLFlow 3 fornece uma maneira abrangente de criar conjuntos de dados de avaliação e uma variedade de pontuadores LLM e determinísticos. Para testes rápidos, os rascunhos de conjuntos de dados de avaliação são definidos em YAML antes de serem promovidos para o conjunto de dados de avaliação padrão. Quando os testadores identificavam uma lacuna, a equipe a adicionava ao conjunto de dados de avaliação e tratava a aprovação desses casos como o critério de aceitação para qualquer correção. Quando novos recursos e fontes de dados eram adicionados, novos casos de avaliação eram escritos antes que a integração fosse aceita.
O resultado foi uma mudança de "parece melhor" para "está melhor, e aqui estão as evidências". Os rastros de experimentos capturaram prompts, estratégias de recuperação, contagens de tokens e métricas de qualidade de resposta, para que as mudanças pudessem ser comparadas objetivamente, em vez de por memória.
Capacidade Multilíngue
O rápido sucesso inicial levantou a questão se a mesma arquitetura poderia atender a outras localidades. Após experimentar modelos de embedding multilíngues, a equipe percebeu que o LLM pode traduzir os prompts do usuário e a resposta final, sem fazer modificações na arquitetura e nas ferramentas principais. Isso tem implicações para os planos mais amplos da Mazda de expandir a aplicação para outros mercados.
Governança
Alinhar permissões entre Apps, clusters, warehouses, endpoints e agentes teve uma curva de aprendizado, mas uma vez padronizado, criou um padrão de governança reutilizável que é seguro e aplicável em futuras aplicações GenAI. O padrão que funcionou: rotear todo o acesso através do principal de serviço do endpoint de serviço e definir concessões no nível do catálogo e esquema para grupos de controle de acesso baseado em função. Uma vez estabelecido, tornou-se reutilizável — integrar um novo modelo ou fonte de dados significava conceder acesso ao mesmo principal de serviço contra o mesmo esquema, não renegociar a estrutura de permissão. Combinado com conectividade privada para tráfego de IA, isso oferece à Mazda um caminho controlado e seguro entre aplicações e dados governados.
A parceria com a equipe de engenharia de campo da Databricks permitiu que a Mazda avançasse mais rapidamente, guiada por melhores práticas e antecipando obstáculos.
Impacto e Próximos Passos
A Mazda agora tem uma base repetível para aplicações GenAI que combinam dados estruturados e não estruturados, tudo dentro do lakehouse: índices de busca vetorial, serviço de modelos, avaliações, observabilidade, governança em nível de catálogo e entrega de frontend através de um aplicativo web. Ter essas capacidades em uma única plataforma removeu a necessidade de juntar vários serviços, o que acelerou o desenvolvimento em muitas vezes.
Dois cientistas de dados que começaram com notebooks isolados agora estão executando aplicações e experimentos de IA com rastreabilidade completa no Databricks. A equipe está expandindo a abordagem para fluxos de trabalho de diagnóstico adicionais e explorando como agentes generativos podem apoiar técnicos, engenheiros de campo e suporte ao cliente.
Essa mudança não é apenas técnica. Ela move a Mazda de relatórios descritivos para aplicações inteligentes e generativas construídas diretamente sobre dados corporativos governados.
Conclusão
Você não precisa de uma equipe grande ou de uma prática de MLOps madura para construir aplicações GenAI significativas. A Mazda tinha dois cientistas de dados, prazos apertados e muito a aprender. A Databricks como Plataforma realizou mais do trabalho pesado do que o esperado, e a Databricks nos ajudou a entregar algo real, rapidamente.
Em sua essência, o projeto é uma expressão de omotenashi — o princípio orientador da Mazda de hospitalidade de todo o coração. Dar aos agentes de serviço técnico da Mazda ferramentas melhores os ajuda a cuidar melhor de seus clientes. E agora, com essa base estabelecida, a equipe está apenas começando.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.