From Legacy to Lakehouse: How Mazda Accelerated GenAI for Technical Service Operations
How a lean team built a governed GenAI assistant using RAG, Unity Catalog, and AI Search
by Tim Marx (Mazda), Foon Hoe Campbell-Wong (Mazda), Jiayi Wu, Arthur Dooner and Olivia Zhang
- How Mazda used the Databricks Lakehouse to bring together service history, diagnostics, and documents as a foundation for GenAI
- How the team designed the GenAI assistant, including retrieval over the right documents and sharing logic between the UI and the agent
- How Mazda moved from ad‑hoc GenAI testing to repeatable evaluations and test cases using MLflow
Automotive service organizations are under pressure. Call volumes continue to rise, electric vehicles introduce new diagnostic complexity, and connected cars generate more data than service hotline agents can realistically sift through. Every model year brings hundreds of service information (SI) documents, each with unique procedures and conditions. When something changes, service hotline agents need time to absorb it before they can confidently guide technicians through unfamiliar issues. That lag matters when a customer is waiting.
Mazda already had the raw ingredients to solve this: a growing lakehouse of warranty, recall, diagnostic codes, service and vehicle history, as well as a constantly updating library of service documents.The challenge was bringing these assets together in a way that enhances agents ability to do their job with accuracy, consistency, and confidence.
That’s where Databricks came in. The Mazda data science team moved fast and learned by doing, going from kickoff to a working concept in roughly eight weeks. There was no lengthy planning phase. The team built, tested, broke things, and adjusted as they went, delivering a pilot that had real impact and value to Mazda.
Starting Point: A Lean Team With Big Ambitions
This project was one of Mazda’s first end-to-end GenAI initiatives built entirely on its new cloud data platform. The team was small—two data scientists iterating rapidly—and the tooling was early. Data pipelines need to be built. Documents need to be extracted and transformed into vector search indexes. Experiments lived in isolated notebooks, and success relied more on memory than traceability.
For a team this lean, infrastructure overhead had to be minimal. That was a major factor in choosing Databricks. The platform enabled nimbleness: no managing vector databases, no configuring distributed compute frameworks, no bespoke orchestration, no glue services to stitch it all together. The focus is on building value—not infrastructure.
Building The Pilot
Early in the pilot, the team focused on a Retrieval Augmentation Generation (RAG) design, with the main focus on connecting an LLM with our custom corpus. Soon, Mazda noticed testers often wanted agents often wanted a full picture of the vehicle first: its service history, open recalls, past hotline escalations, warranty status.
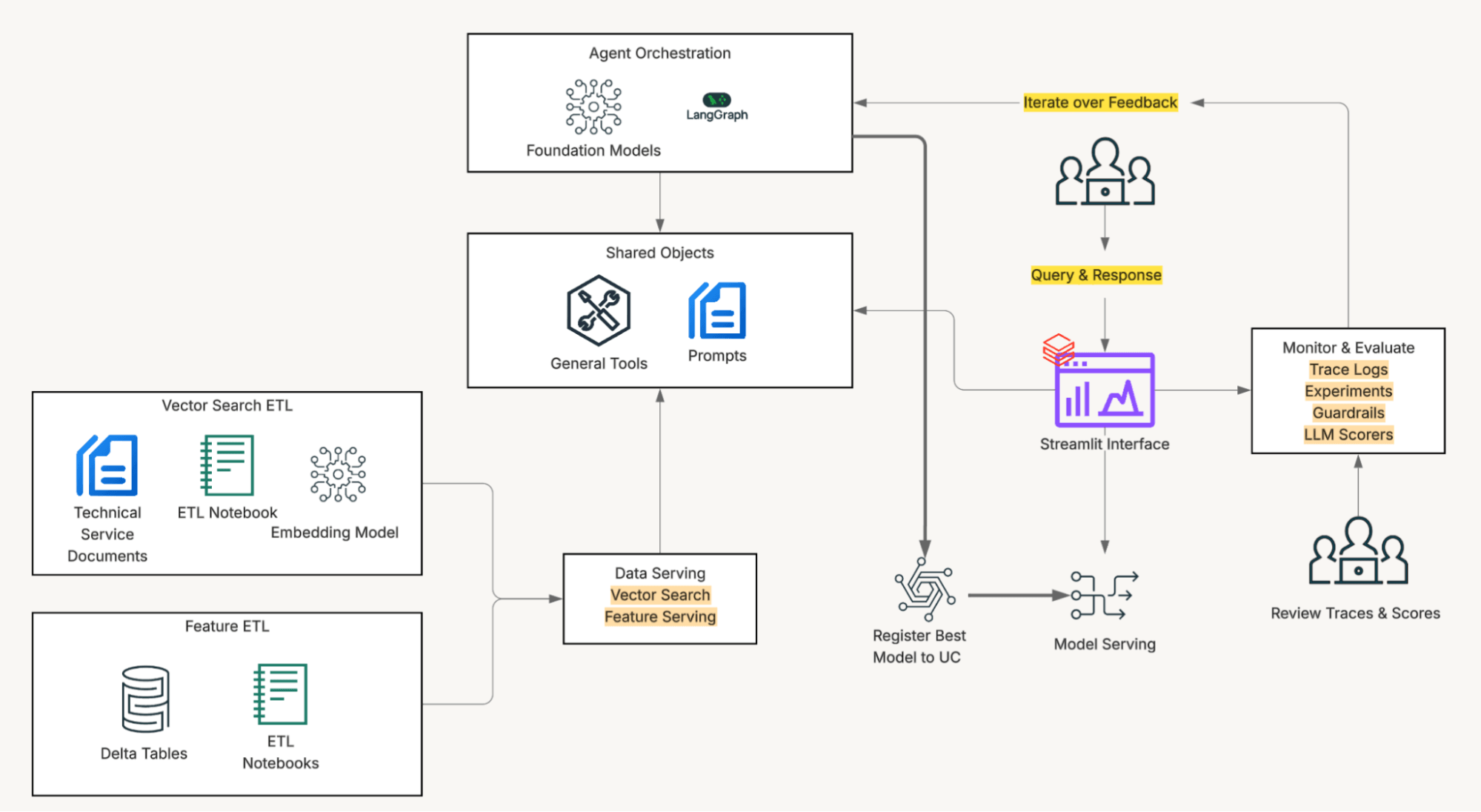
That observation shaped a deliberate architectural choice: the frontend and the agent share code and tooling. Vehicle data access, transformation, and prompting logic are implemented once and used identically by both the Streamlit interface and the deployed agent endpoint.
When a service agent enters a VIN at the start of a session, the frontend pre-loads complete vehicle context (repair history, hotline escalations, warranty data, recall status) and injects it into the system prompt before the first message is sent. This eliminates tool calls and provides immediate interactivity.
On the other hand, if the AI agent is invoked without that pre-loaded context, it will use the same toolbox that the users interact with. The output is structurally identical either way, and the system prompt handles both paths explicitly: use injected context if present, call tools if not. One prompt, two execution modes, no behavioral drift between surfaces.
Unity Catalog
The solution is powered by the Databricks Lakehouse. Unity Catalog provides governed access to the data the service agents rely on every day, and where embeddings, vector search, SQL tool calls, and model serving all run in the same environment, simplifying development and removing integration friction. Mazda used LLMs via foundation models API (pay-per-token) and embedding model via the managed vector search endpoint.
Everything lives inside Unity Catalog: SI documents, Delta tables with vehicle history and diagnostic codes, vector search indexes, data transformations, and models. Unified governance means the ability to isolate access to specific subsets of data, make changes on the fly, and observe the impact immediately. Then, Databricks Apps ties it together with a Streamlit frontend that service teams can use without new training or tools.
Precise corpus Filtering, enabled by Unity Catalog Functions
A naive vector search across the full corpus returns results that are semantically plausible but not necessarily applicable to the vehicle in front of the technician. Getting retrieval right meant solving a scoping problem before solving a relevance problem.
The team implemented filtering through Unity Catalog user-defined functions. Before any vector search runs, the system calls a UC function that maps the VIN (or diagnostic trouble code) to the subset of the applicable documents for that vehicle, constraining semantic matching to only the documents that apply.
Hosting this logic as a Unity Catalog function rather than application code meant the applicability rules live alongside the data they govern, are accessible to both the agent and any other downstream application, and can be updated independently of the agent deployment cycle.
From ad-hoc testing to test-driven development
Mazda piloted the application with 10 service agent testers. Early in the pilot, iteration was feedback-driven: testers would report issues, the team would adjust prompts or retrieval configuration, and evaluate the result informally. That worked for initial development but didn't scale as the system grew more complex.
MLflow 3's native GenAI evaluation framework changed the team's workflow. MLFlow 3 provides a comprehensive way to create evaluation datasets and a variety of LLM and deterministic scorers. For rapid testing, draft evaluation datasets are defined in YAML before promoting to standard evaluation dataset. When testers surfaced a gap, the team added it to the evaluation dataset and treated passing those cases as the acceptance criterion for any fix. When new features and data sources were added, new evaluation cases were written before the integration was accepted.
The result was a shift from "it seems better" to "it is better, and here's the evidence." Experiment traces captured prompts, retrieval strategies, token counts, and response quality metrics so changes could be compared objectively rather than by memory.
Multilingual capability
The quick initial success prompted the question of whether the same architecture could serve other locales. After experimenting with multilingual embedding models, the team realized that LLM can translate the user prompts and final response, without making modification to the core architecture and tools. That has implications for Mazda's broader plans to expand the application across markets.
Governance
Aligning permissions across Apps, clusters, warehouses, endpoints, and agents had a learning curve, but once standardized, it created a reusable governance pattern that’s secure and applicable across future GenAI applications. The pattern that worked: route all access through the serving endpoint's service principal, and define grants at the catalog and schema level to role-based access control groups. Once that was established, it became reusable — onboarding a new model or data source meant granting access to the same service principal against the same schema, not renegotiating the permission structure. Combined with private connectivity for AI traffic, this gives Mazda a controlled, secure path between applications and governed data.
The partnership with the Databricks field engineering team enabled Mazda to move faster, guided by best practices and pre-empting roadblocks.
Impact and What’s Next
Mazda now has a repeatable foundation for GenAI applications that combine structured and unstructured data, all inside the lakehouse: vector search indexes, model serving, evaluations, observability, catalog-level governance, and frontend delivery through a web app. Having these capabilities on a single platform removed the need to stitch together multiple services, which accelerated development manyfold.
Two data scientists who started with siloed notebooks are now running AI applications and experiments with full traceability on Databricks. The team is expanding the approach to additional diagnostic workflows and exploring how generative agents can support technicians, field engineers, and customer support.
This shift isn’t just technical. It moves Mazda from descriptive reporting to intelligent, generative applications built directly on governed enterprise data.
Takeaway
You don’t need a large team or a mature MLOps practice to build meaningful GenAI applications. Mazda had two data scientists, tight timelines, and a lot to learn. Databricks as a Platform carried more of the heavy lifting than expected, and Databricks helped us ship something real, fast.
At its core, the project is an expression of omotenashi — Mazda’s guiding principle of wholehearted hospitality. Giving Mazda technician service agents better tools helps them take better care of its customers. And now, with this foundation in place, the team is just getting started.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.