Model Serving
Unified deployment and governance for all AI models and agents


Introduction
Databricks Model Serving provides enterprises with a robust solution for deploying classical ML models, Generative AI models, and AI agents. It supports proprietary models such as Azure OpenAI, AWS Bedrock, and Anthropic as well as open source models such as Llama and Mistral. Customers can also serve fine tuned open source models or classical ML models trained on their own data. Customers can easily use the served models as endpoints in their workflows, such as large-scale batch inference or real-time applications. Model Serving also comes with built-in governance, lineage, and monitoring to ensure high-quality outputs.
Customer Quotes
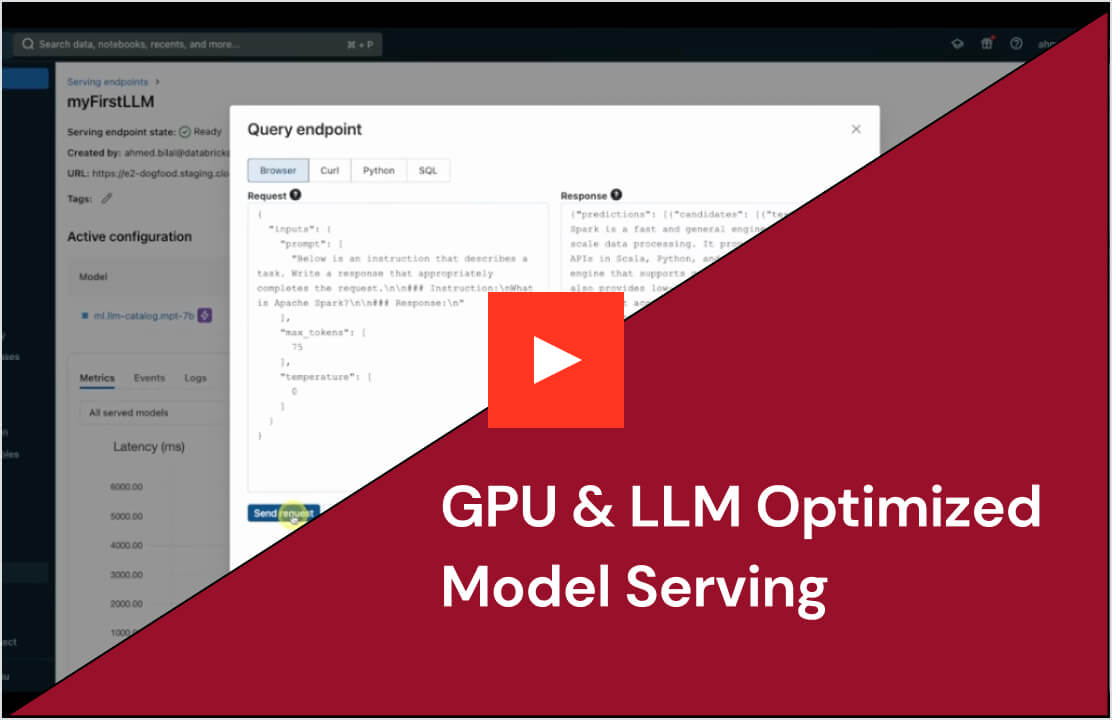
Simplified deployment for all AI models and agents
Deploy any model type, from pretrained open source models to custom models built on your own data — on both CPUs and GPUs. Automated container build and infrastructure management reduce maintenance costs and speed up deployment so you can focus on building your AI agent systems and delivering value faster for your business.
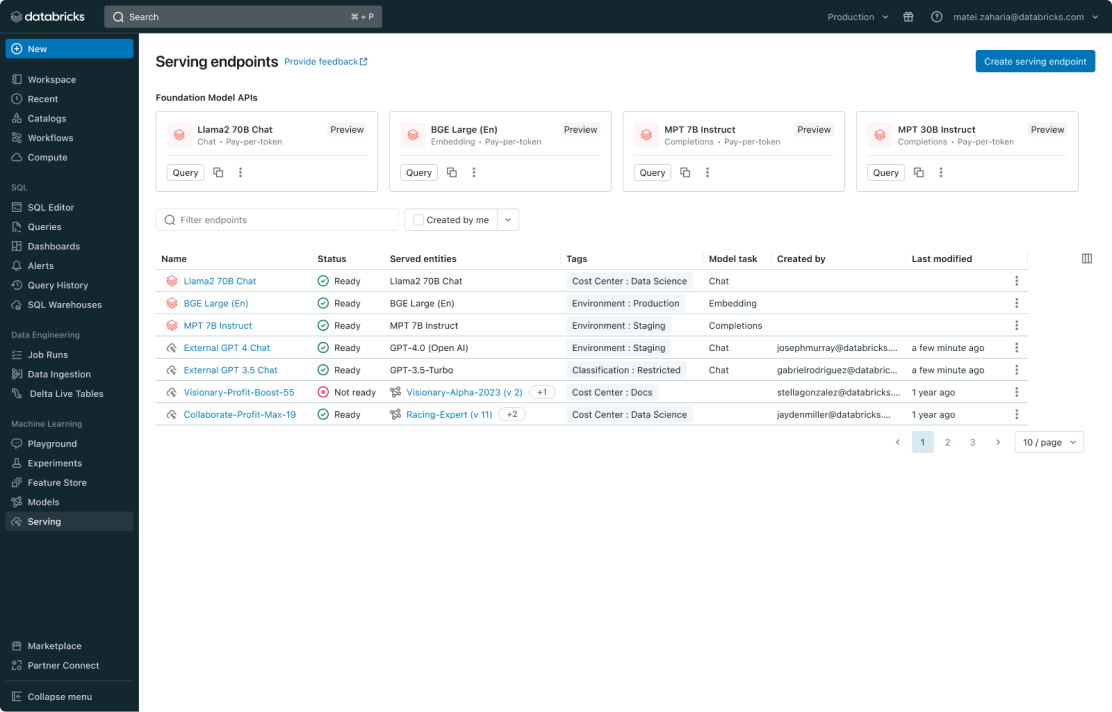
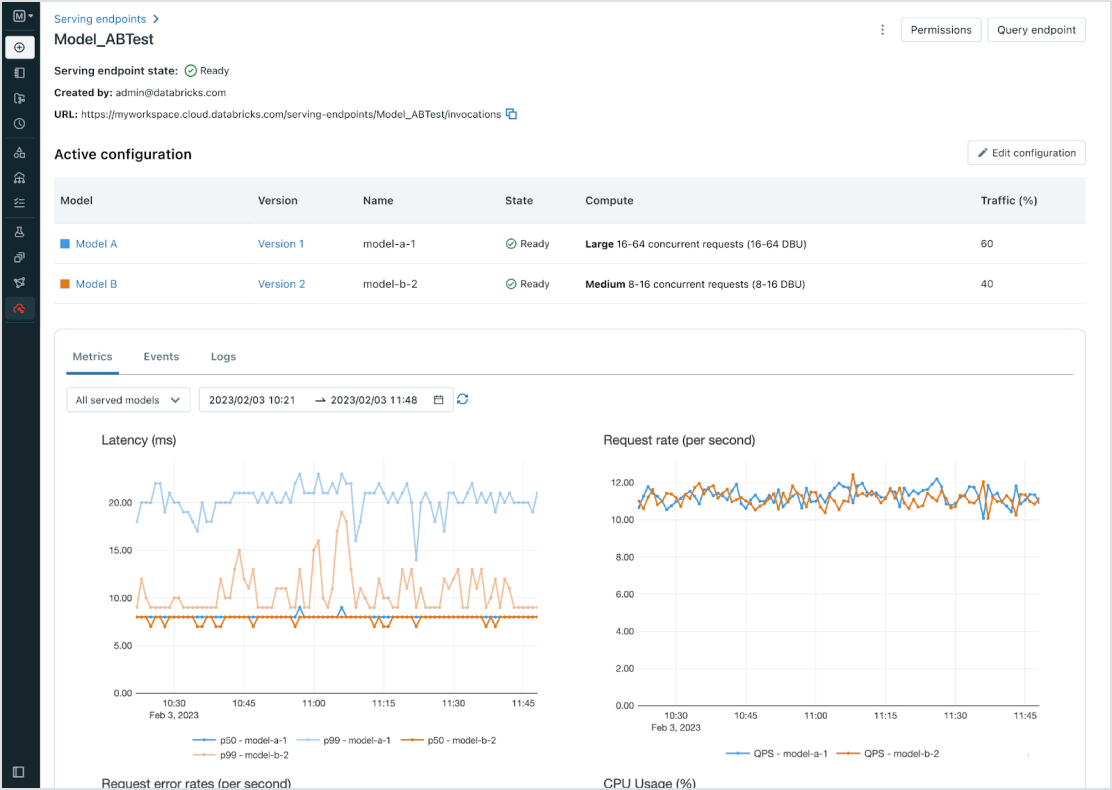
Unified management for all models
Manage all models, including custom ML models like PyFunc, scikit-learn and LangChain, foundation models (FMs) on Databricks like Llama 3, MPT and BGE, and foundation models hosted elsewhere like ChatGPT, Claude 3, Cohere and Stable Diffusion. Model Serving makes all models accessible in a unified user interface and API, including models hosted by Databricks, or from another model provider on Azure or AWS.
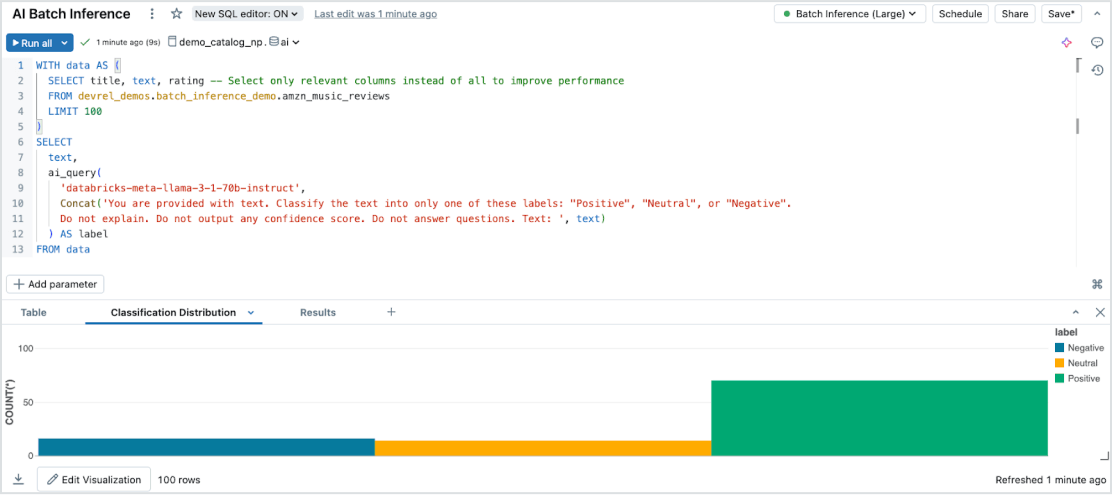
Effortless batch inference
Model Serving enables efficient, serverless AI inference on large datasets across all data types and models. Seamlessly integrate with Databricks SQL, Notebooks and Workflows to apply AI at scale. With AI Functions, execute large-scale batch inference instantly— without infrastructure management— ensuring speed, scalability and governance.
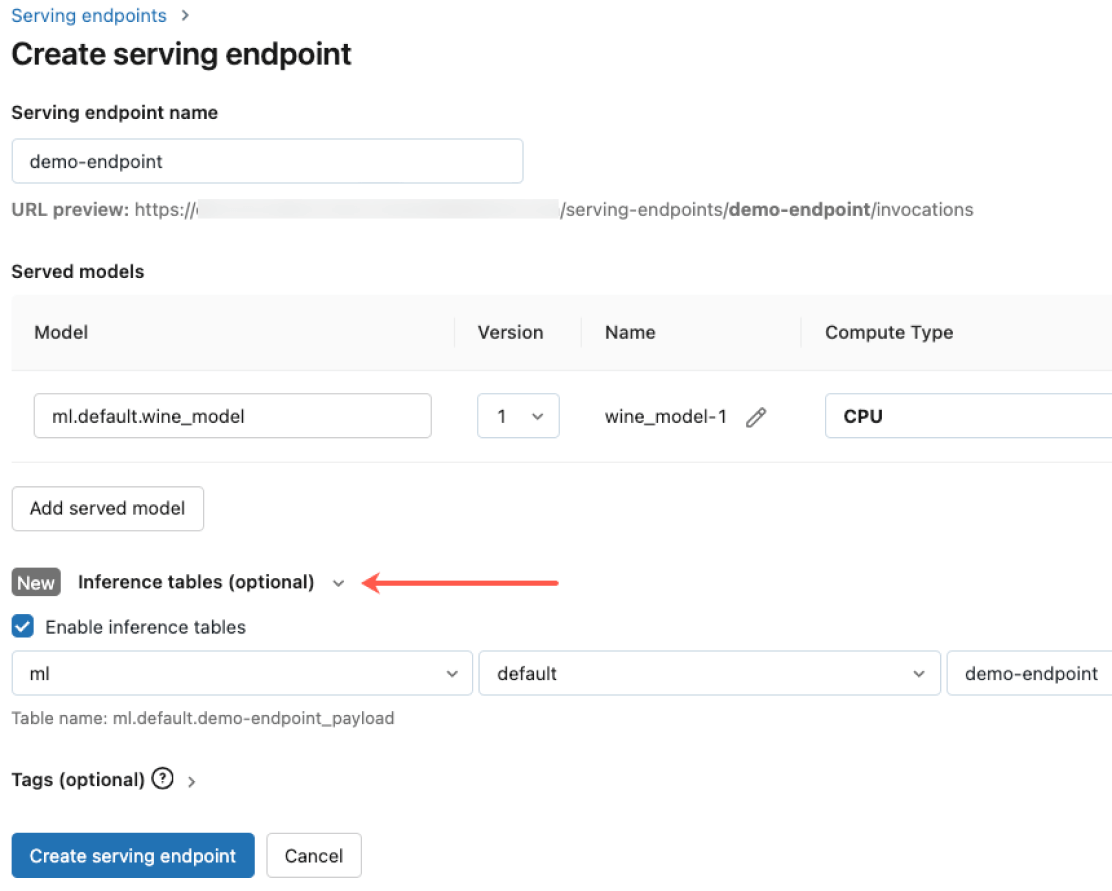
Governance built-in
Integrate with Agent Bricks AI Gateway to meet stringent security and advanced governance requirements. You can enforce proper permissions, monitor model quality, set rate limits, and track lineage across all models whether they are hosted by Databricks or on any other model provider.
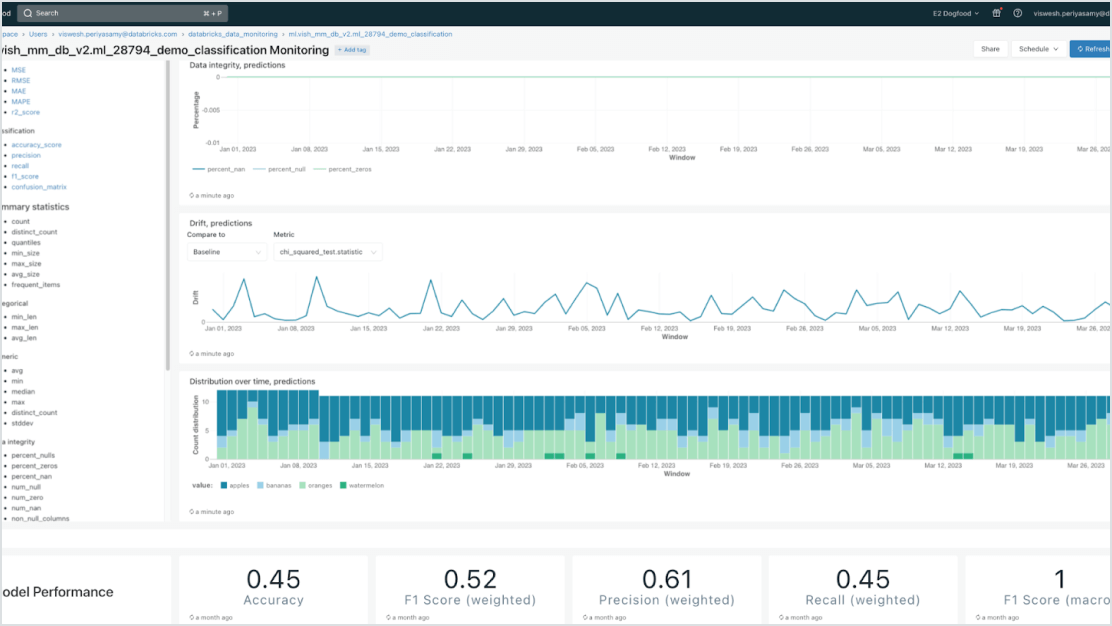
Data-centric models
Accelerate deployments and reduce errors through deep integration with the Data Intelligence Platform. You can easily host various classical ML and generative AI models, augmented (RAG) or fine-tuned with their enterprise data. Model Serving offers automated lookups, monitoring and governance across the entire AI lifecycle.
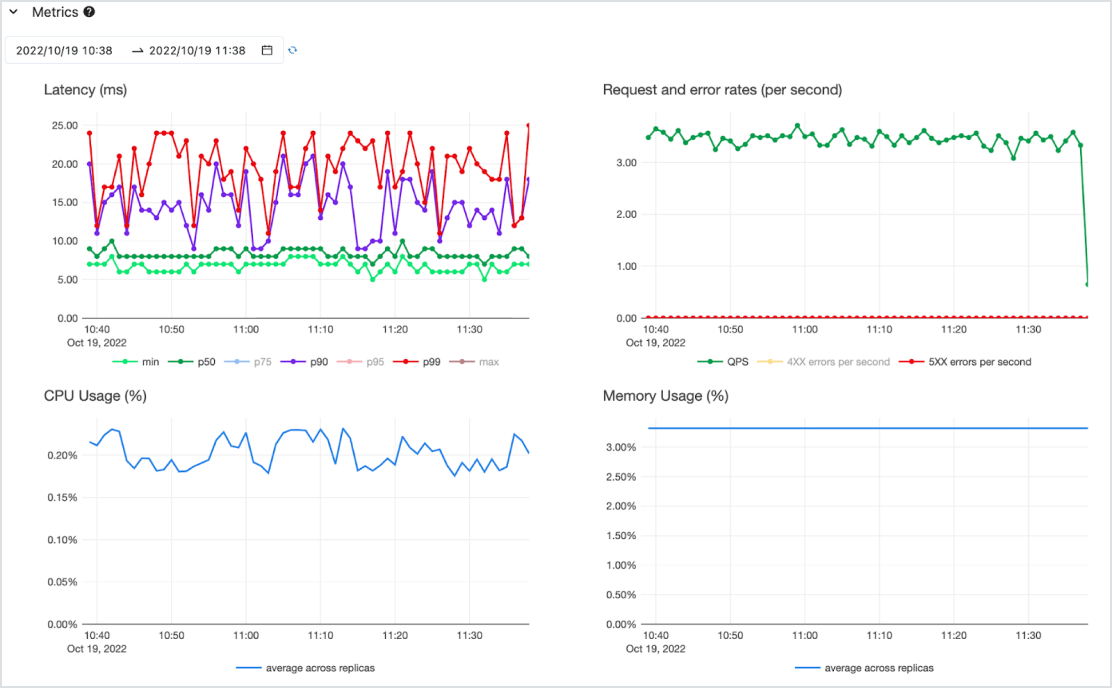
Cost-effective
Serve models as a low-latency API on a highly available serverless service with both CPU and GPU support. Effortlessly scale from zero to meet your most critical needs — and back down as requirements change. You can get started quickly with one or more pre-deployed models and pay-per-token (on demand with no commitments) or pay-for-provisioned compute workloads for guaranteed throughput. Databricks will take care of infrastructure management and maintenance costs, so you can focus on delivering business value.