Build and deploy quality AI agent systems
Securely connect your data with any AI model to create accurate, domain-specific applications.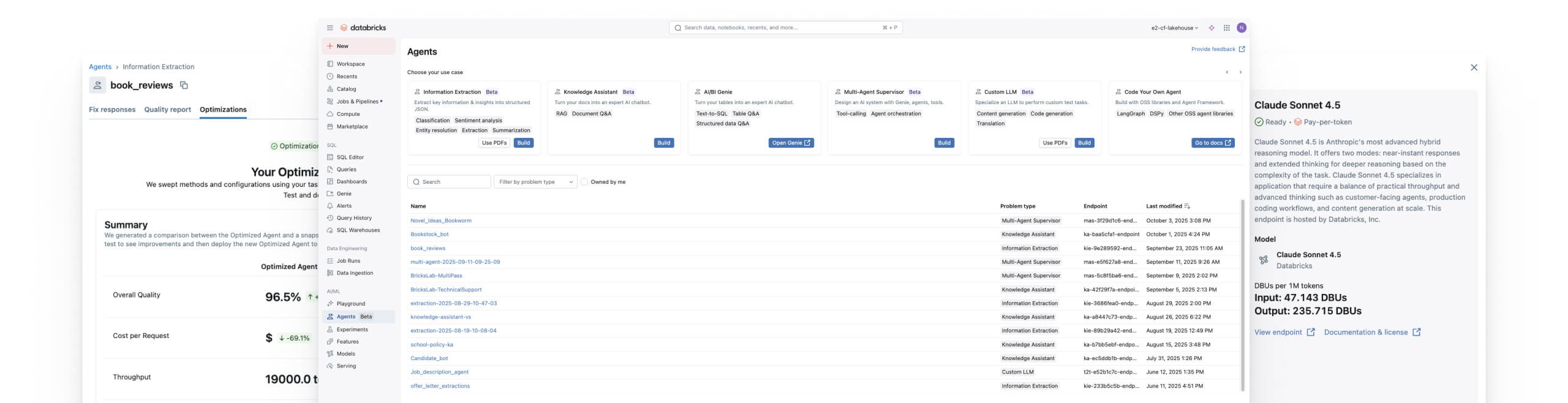
TOP TEAMS SUCCEED WITH DATABRICKS


The only unified platform for agent systems
Stop relying on generic AI models. Databricks has the tools to build agent systems that deliver accurate, data-driven results.Agents built on your data
Quickly develop agents that are tuned on your enterprise data across multiple systems. Use any model, from classical ML to GenAl, to apply the best solution to your application’s needs.
Custom evaluation
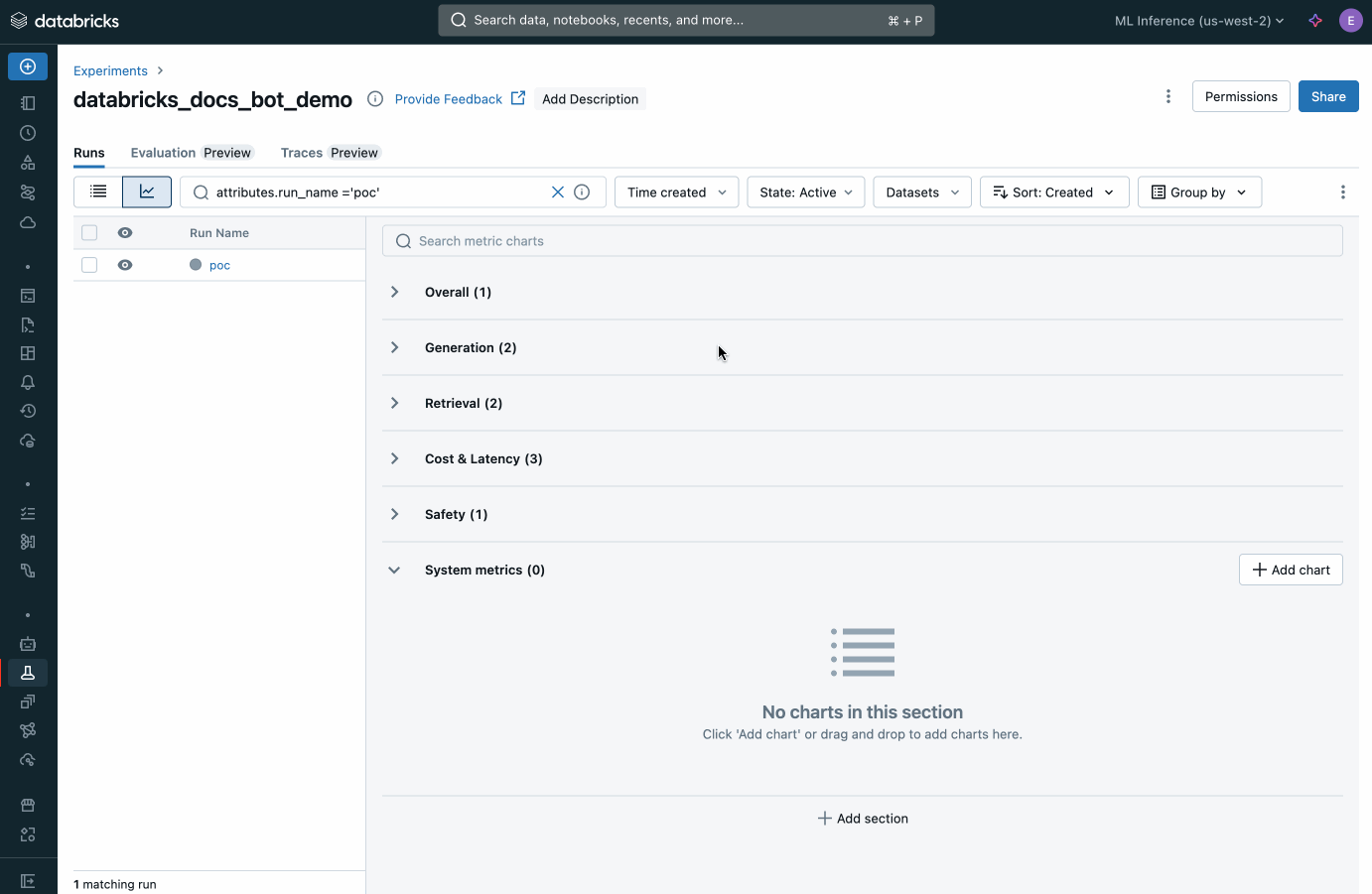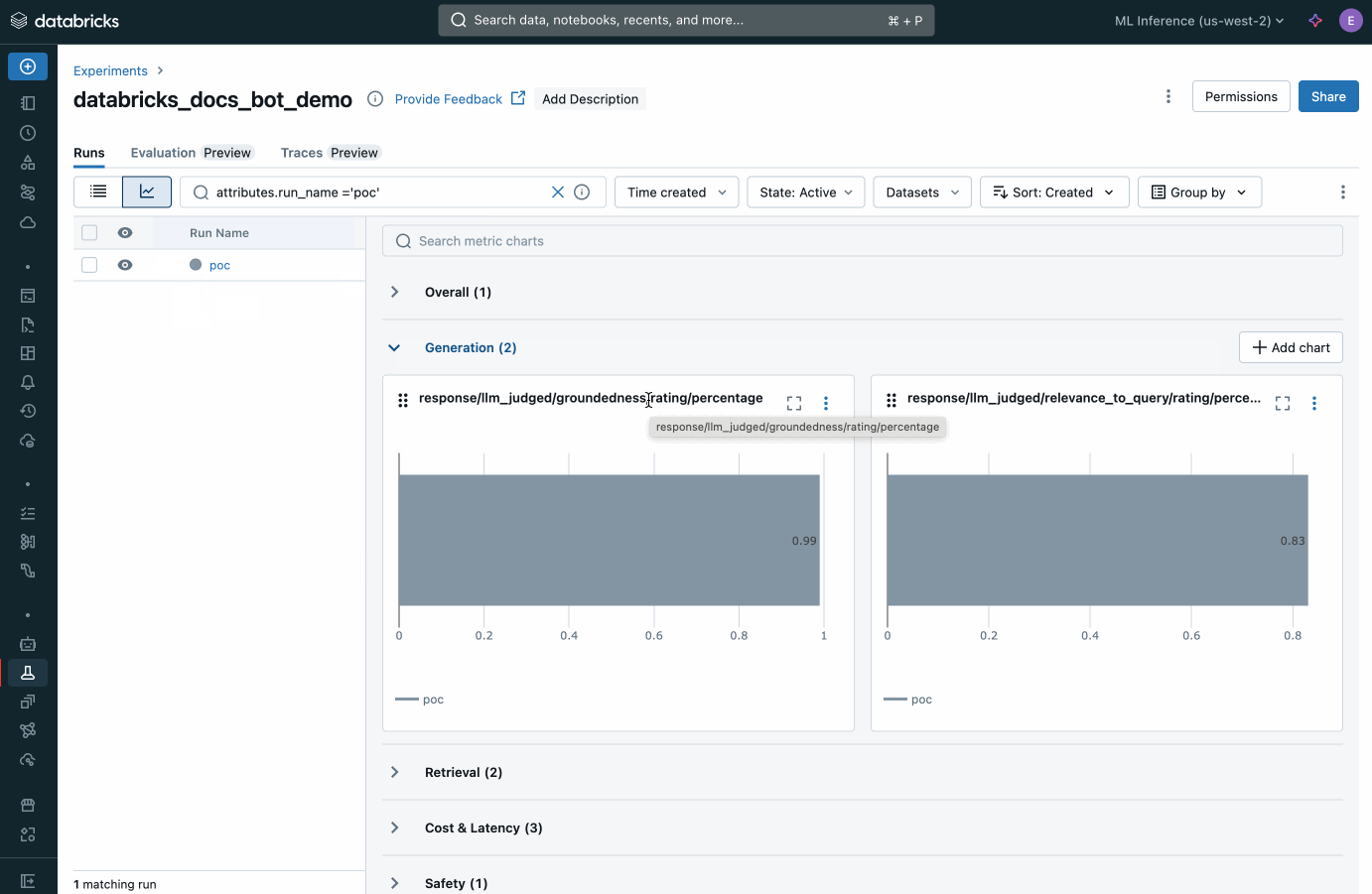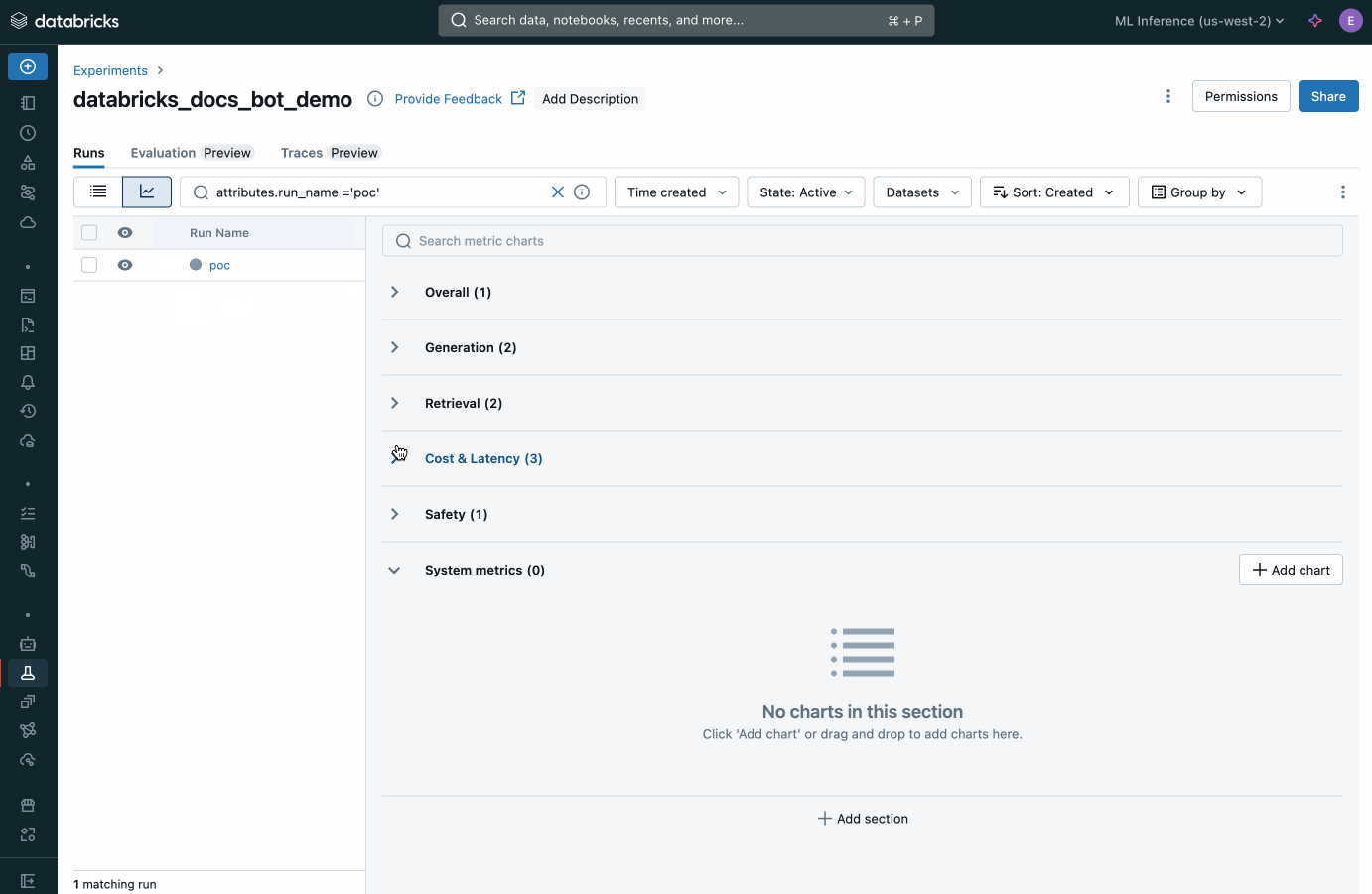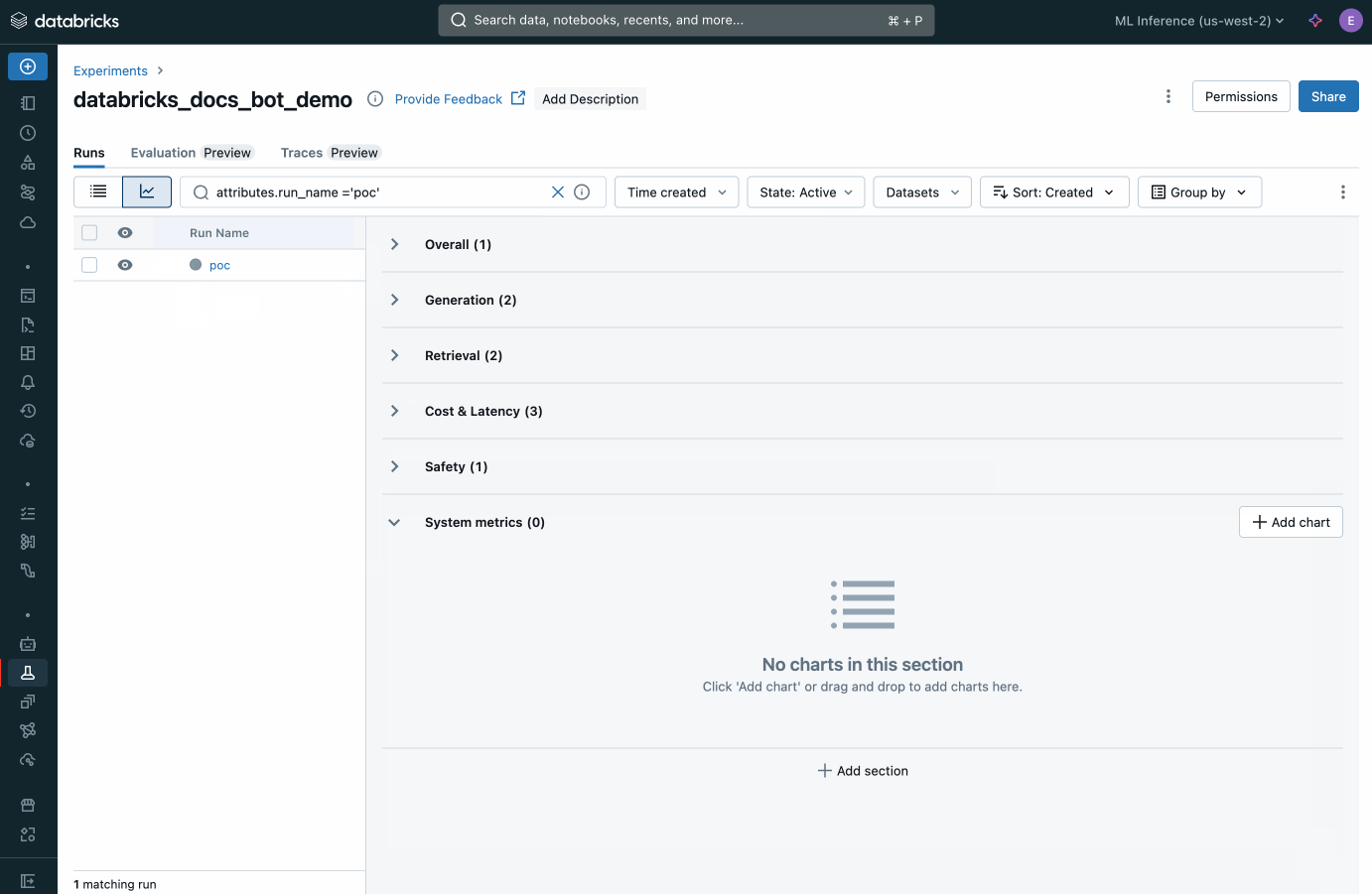
Databricks offers built-in evaluation for agents, supporting any AI model. Measure agent output quality with AI judges, evaluate fixes and redeploy quickly. Across ML and GenAI apps, you can identify production issues, analyze root causes and take corrective actions.
Governance
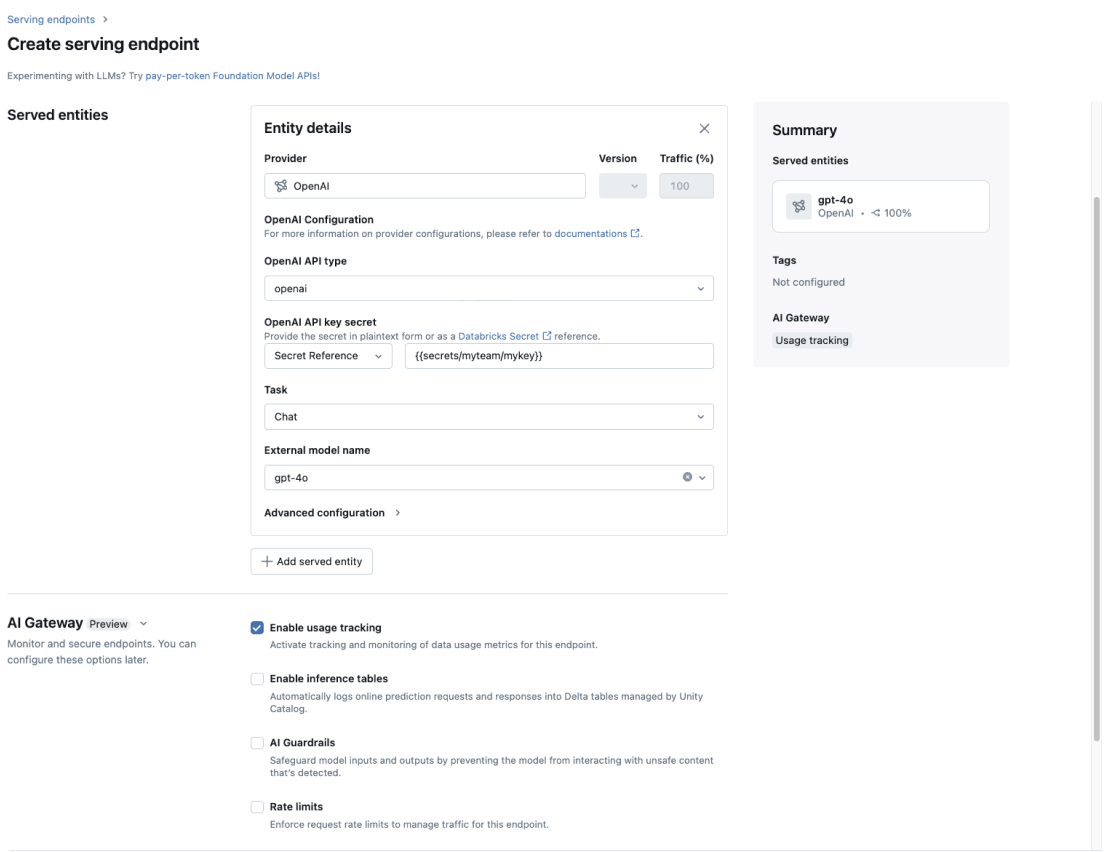
Maintain data security with end-to-end governance for agents. Enforce guardrails for all of your models, automate access controls, set rate limits and track data lineage across your entire workflow.
44% improvement in accuracy
$10M in productivity gains
96% accuracy of responses



Tools for end-to-end AI agent systems

Agent Bricks
Build AI agents grounded in your enterprise data. Databricks Agent Bricks lets you optimize quality and cost with synthetic data, custom evaluation, and automated tuning.
Unity AI Gateway
A single place to apply data governance across every LLM and MCP in your enterprise.
AI Search
A highly performant vector database with real-time syncing of source data.
Agent Framework and Evaluation
Build production-quality AI agents with Agent Framework. Agent Evaluation, an integral feature of the framework, ensures agent output quality with AI-assisted assessments and offers an intuitive UI for feedback from human stakeholders.
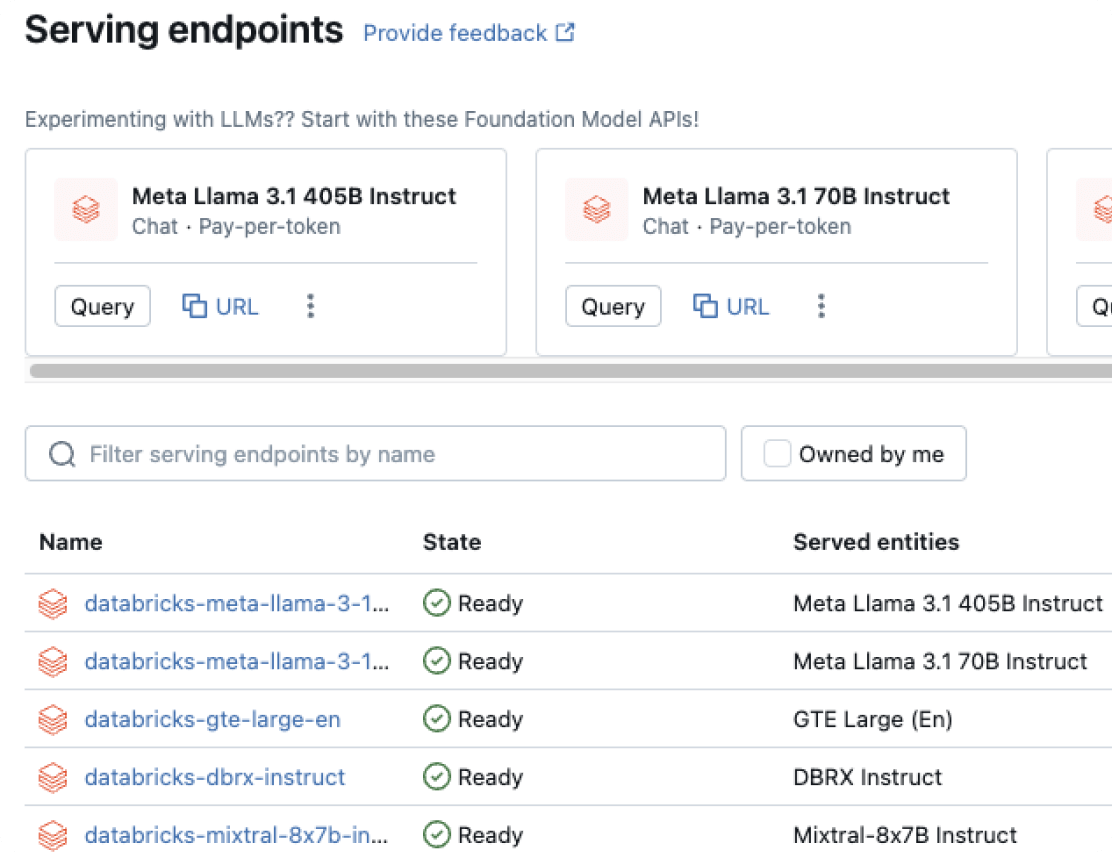
Model Serving
Unified deployment for agents, GenAI and classical ML models.
Model Training
Fine-tune open source LLMs, pretrain custom LLMs or build classical ML models.
Databricks Notebooks
Boost team productivity with Databricks Collaborative Notebooks, enabling real-time collaboration and streamlined data science workflows.
Managed MLflow
Extend open source MLflow, a unified MLOps platform for building better models and generative AI apps, with enterprise-grade reliability, security and scalability.
Data Quality Monitoring
Simple, scalable monitoring that detects anomalies, tracks freshness, and delivers consistent quality signals across your AI assets.
The Databricks Data Intelligence Platform
Explore the full range of tools available on the Databricks Data Intelligence Platform to seamlessly integrate data and AI across your organization.
Build high-quality agent systems

Transform your data effortlessly
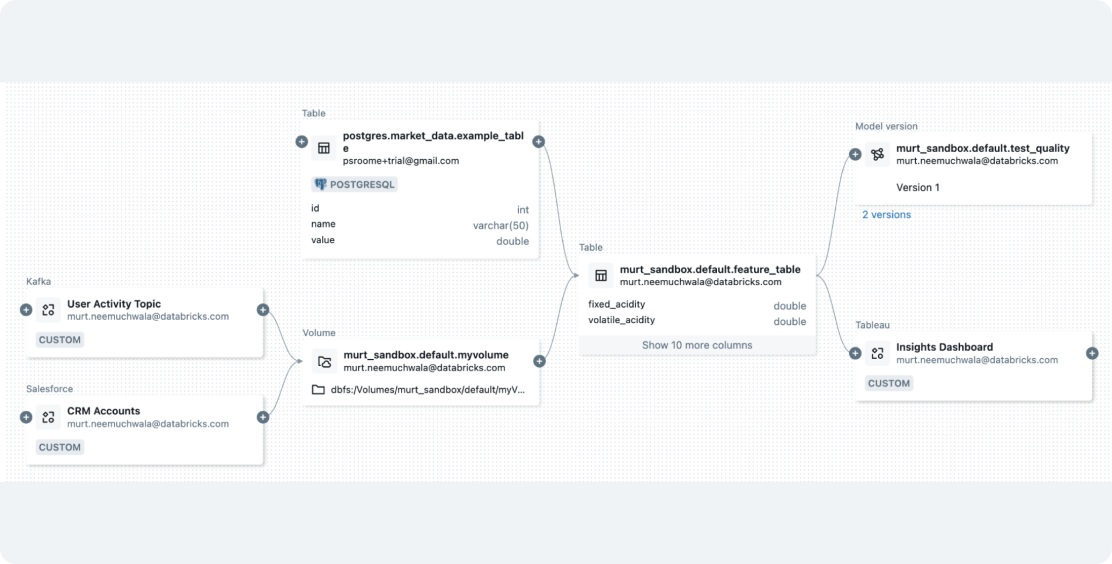
Prepare data with seamless integration for GenAI and ML workflows
Databricks empowers you to ingest any data type and orchestrate jobs to prepare it for your GenAI or ML applications. With built-in governance, it simplifies data featurization and creates vector indexes for RAG using Databricks AI Search, unifying data and model pipelines to streamline workflows and cut costs.

Take the next step




Databricks FAQ
Ready to become a data + AI company?
Take the first steps in your transformation