Production AI agents
Unified platform to build and govern AI agents that continuously improve.
Manage agent sprawl. Build agents with confidence.
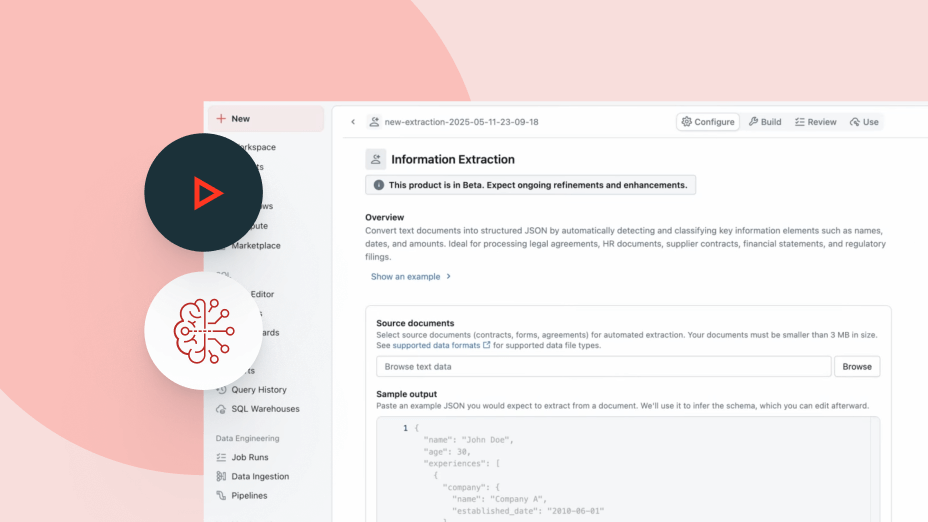
Unify development, management and governance of enterprise AI agents.Agents that know your data
Agent Bricks uses your enterprise context — schemas, business definitions and custom semantics — to make smarter decisions about which tools and tables to use, how to join data correctly and how to produce accurate, consistent answers.
Open and multi-AI
Access every leading AI model, from OpenAI, Anthropic and Google to open source, through a single platform. Agent Bricks lets you switch models instantly to optimize cost, quality and performance without re-architecting your stack.
Unified governance
Only Databricks governs the full stack — from data to AI models — in a single system of record. Track every agent, MCP server, model and tool with clear ownership and end-to-end permissions that ensure agents never access more than they’re allowed to.

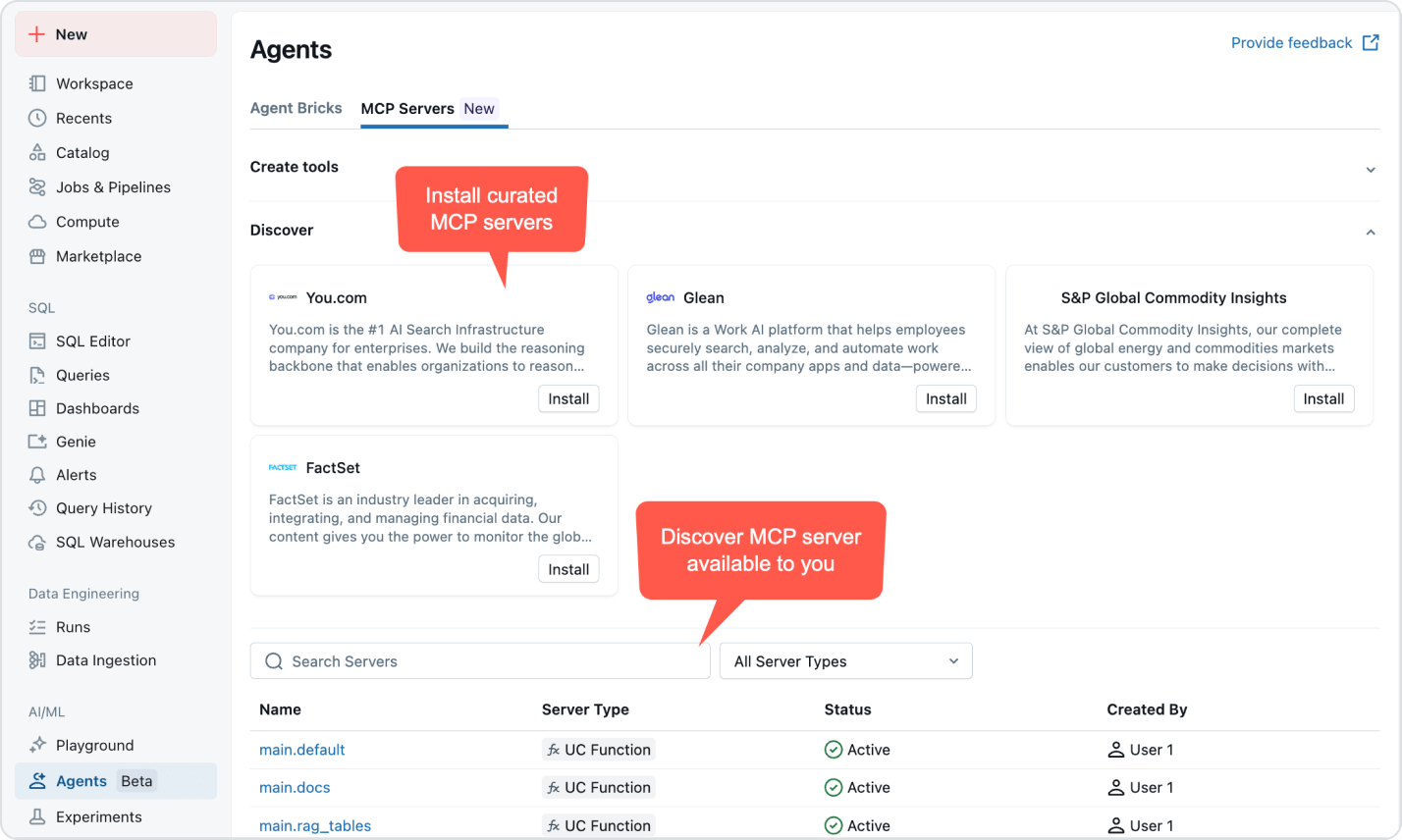
TOP TEAMS SUCCEED WITH AGENT BRICKS
Everything you need to build, govern and scale agents
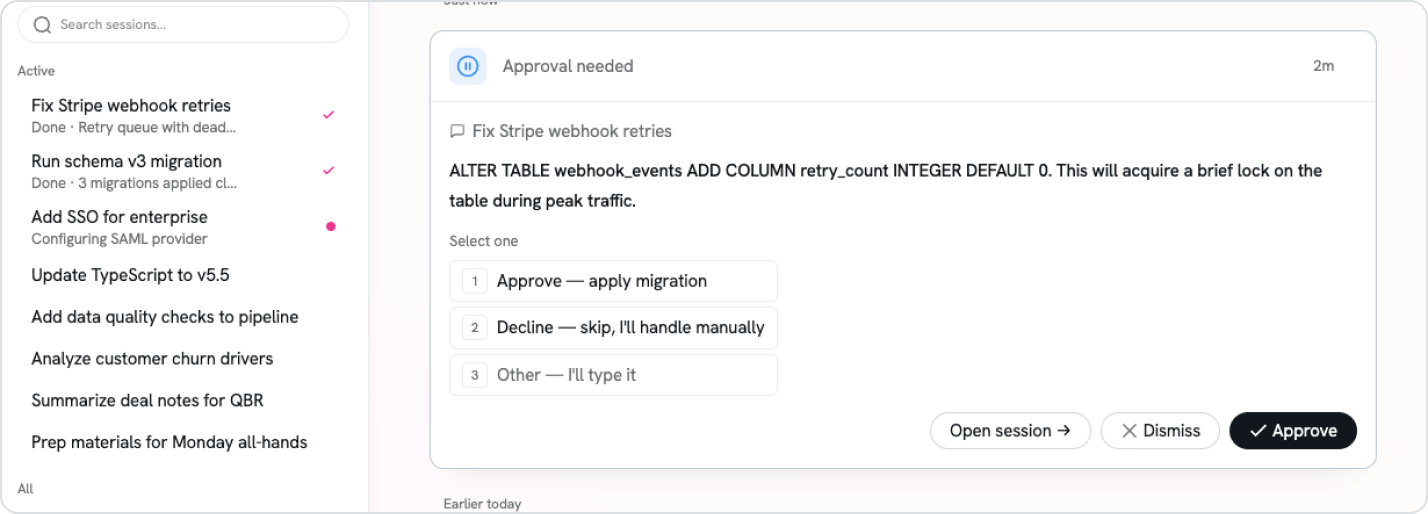
Run, supervise and share any agent or harness, hosted on Databricks
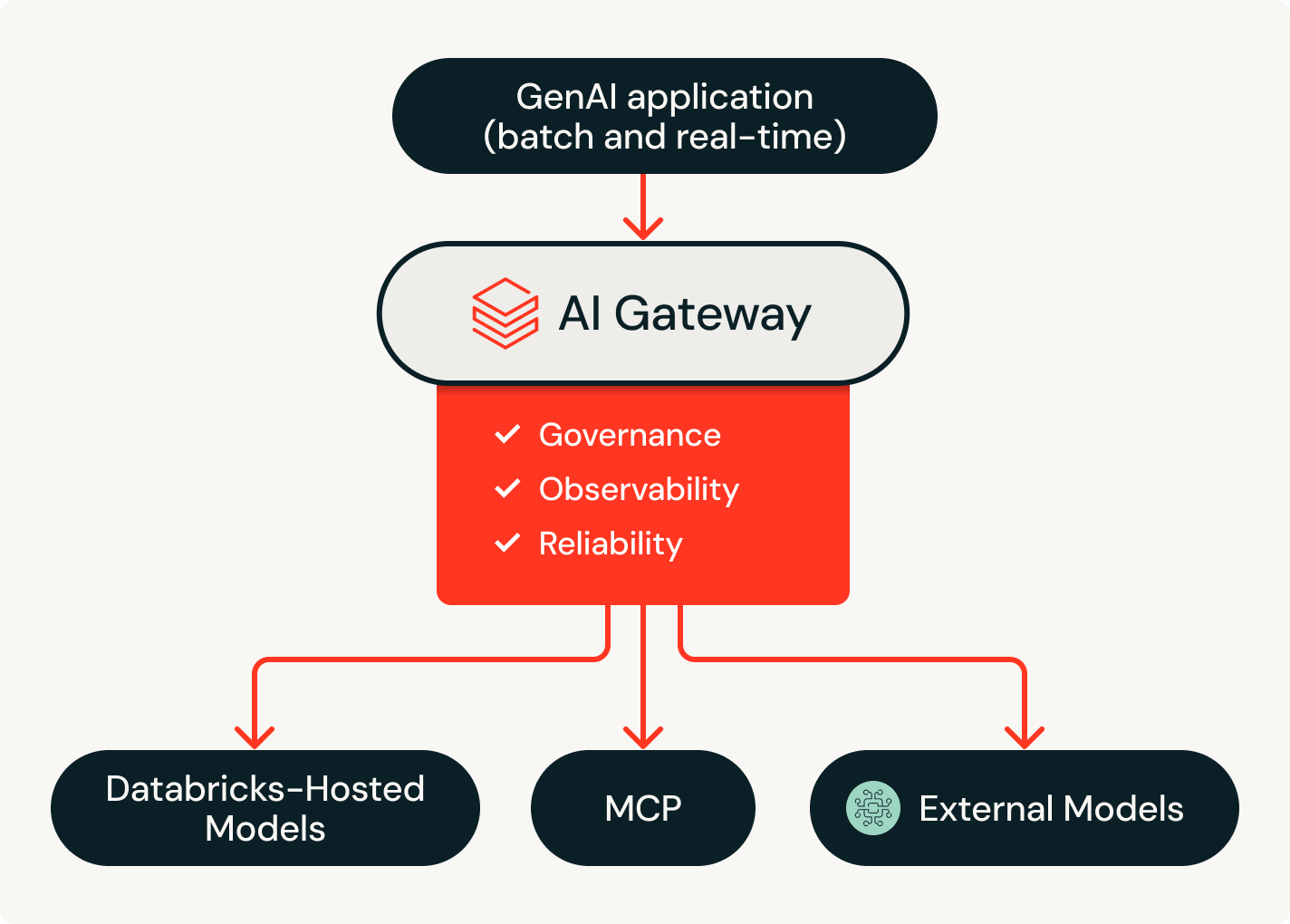
Omnigent runs your agents above the harnesses you already use, so you can compose Claude Code, Codex and custom agents in one workflow. Contextual policies (e.g., progressive safety and cost controls) are enforced at runtime through Unity AI Gateway, and every session is traced in MLflow and shareable with a single link.
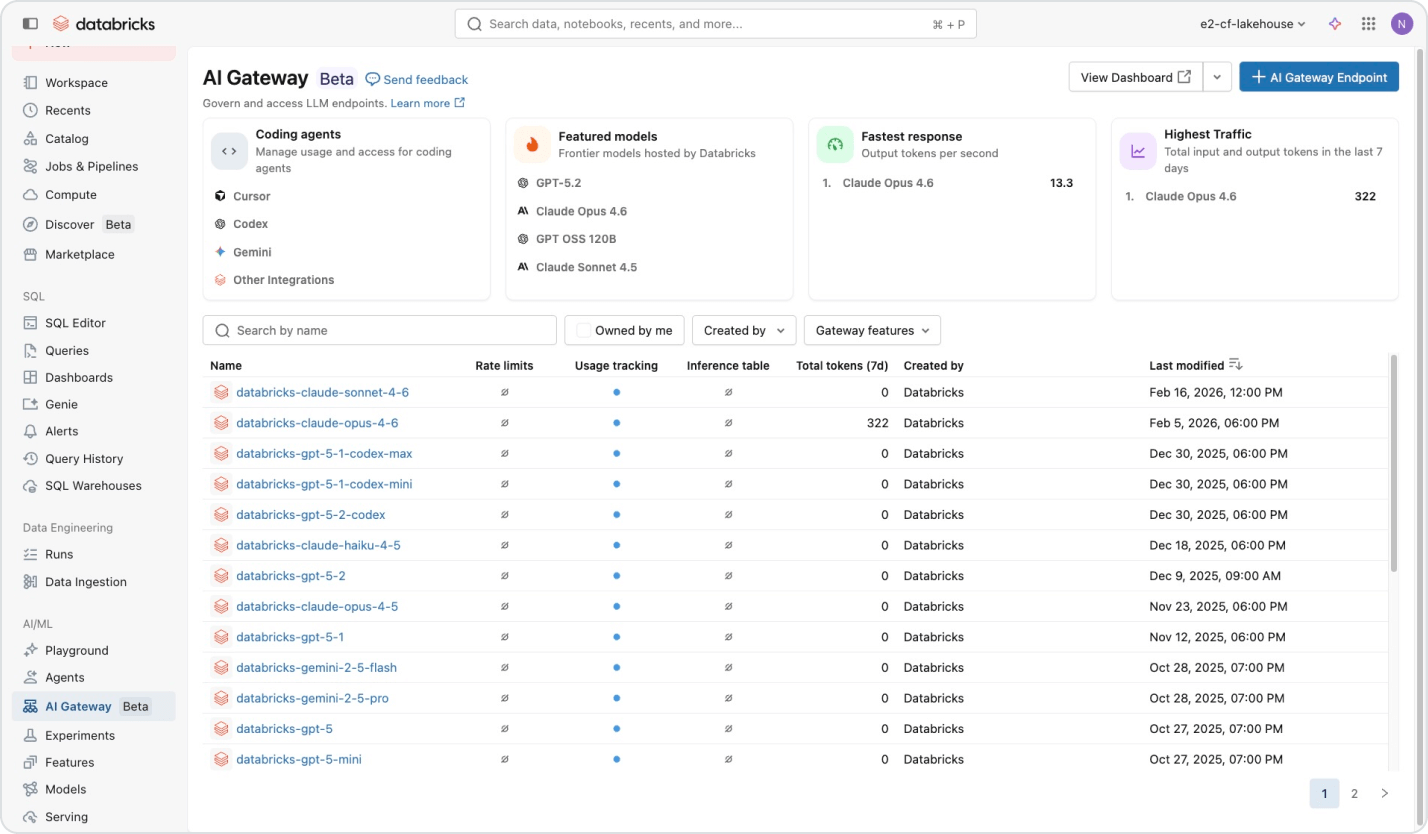
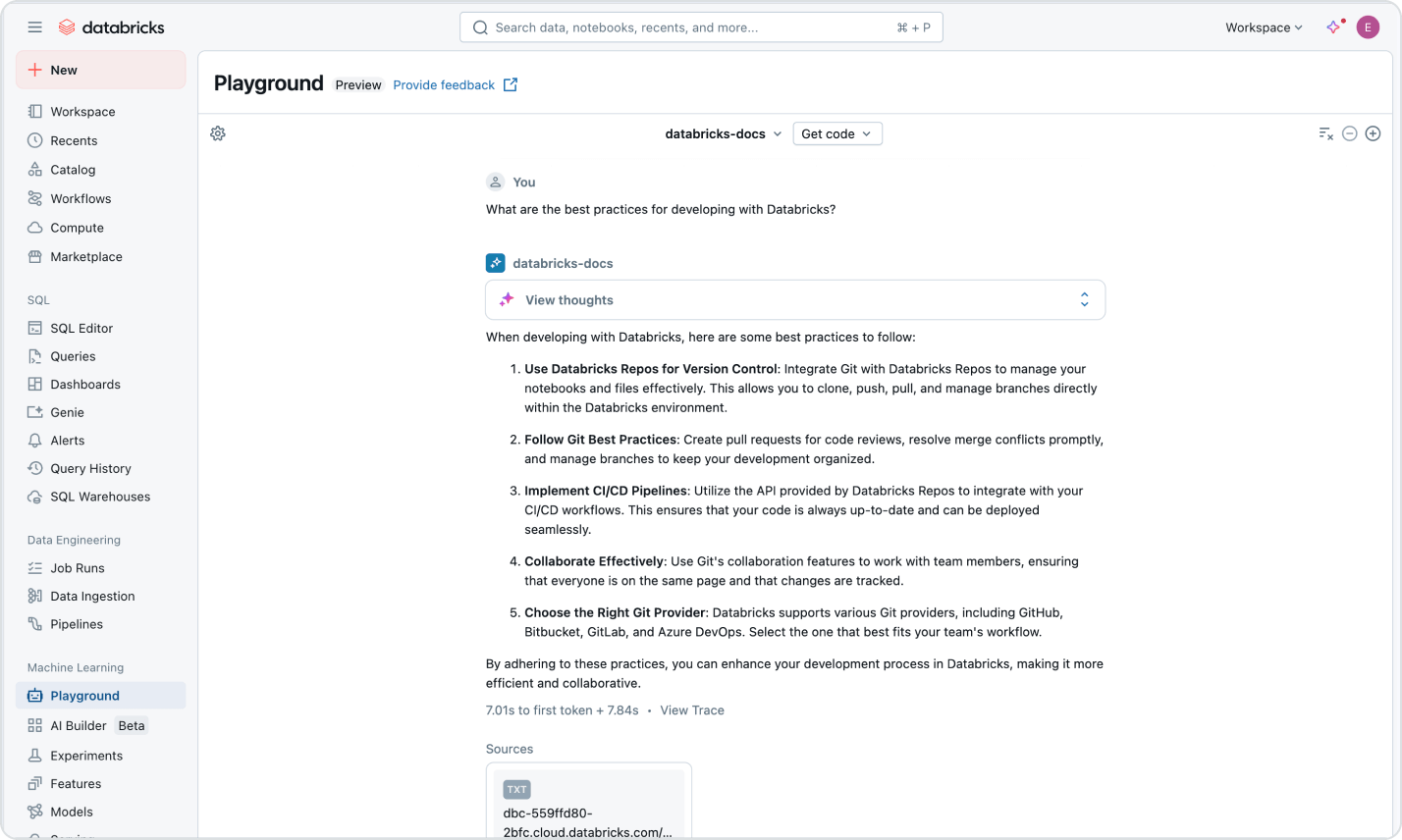
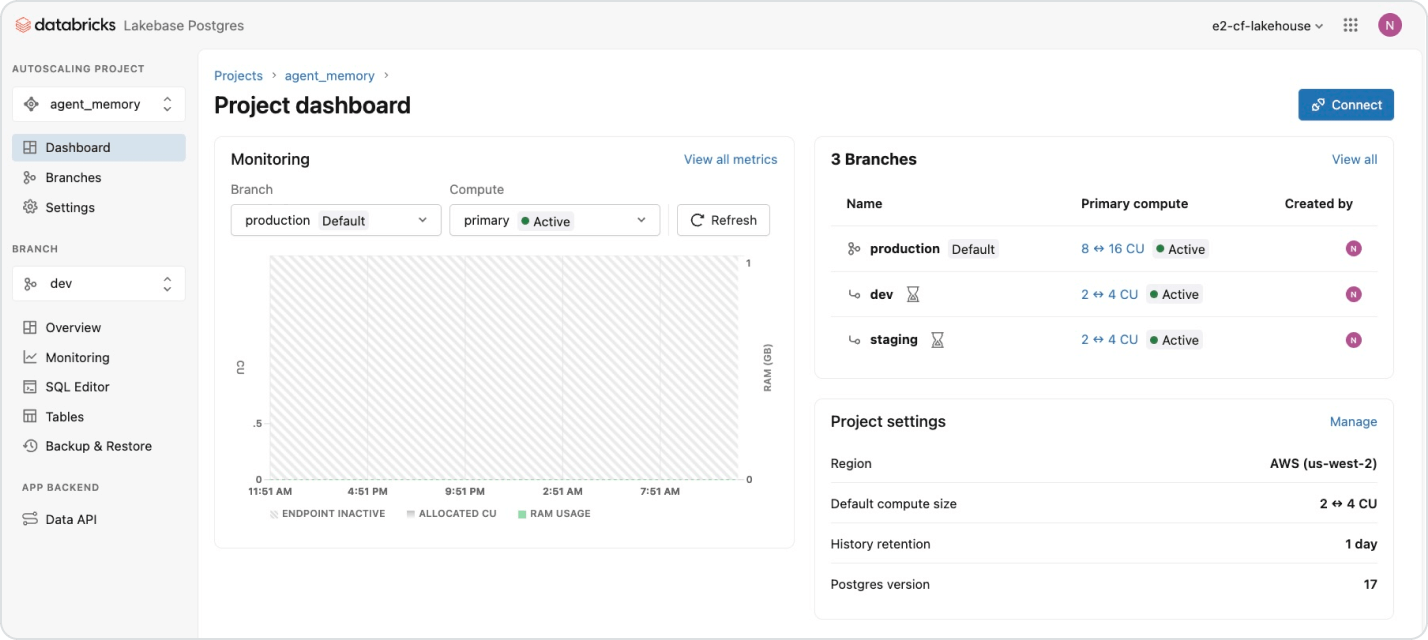



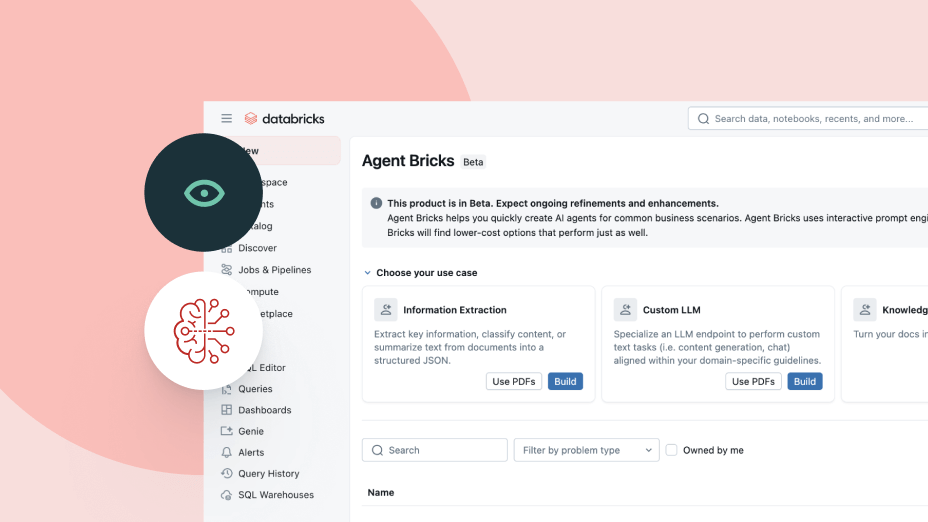
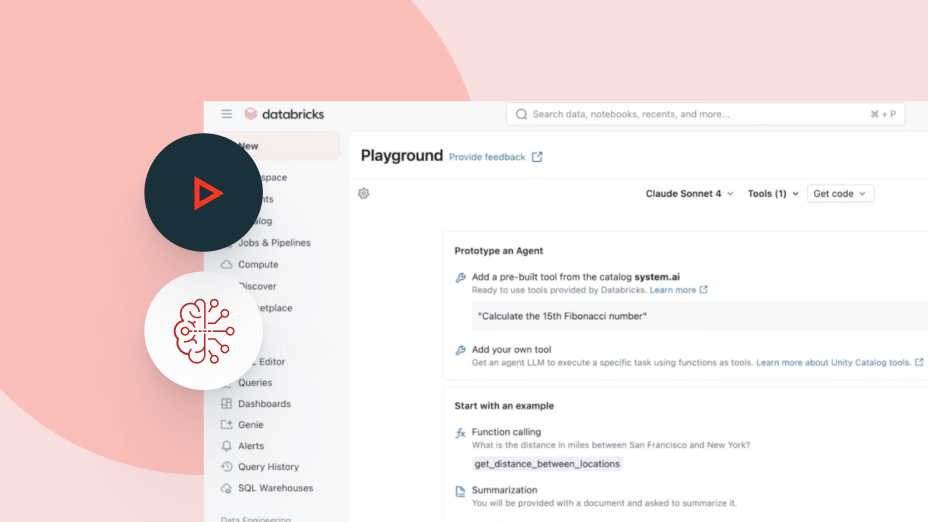
Usage-based pricing keeps spending in check
Only pay for the products you use at per-second granularity.Discover more
Learn more about how the Databricks Data Intelligence Platform empowers your team across all your data and AI workloads.
Genie One
Get insights from your data simply by asking questions in natural language.

Databricks Apps
Turn Custom Agents into secure, user-facing AI applications on Databricks. Build full experiences on top of governed data and models, with serverless infrastructure and built-in scaling.

Model Serving
Deploy and govern any AI model or agent in production with built-in observability, scale and enterprise controls.

AI Search
Power real-time AI applications with a high-performance vector database that continuously syncs your source data.

Unity Catalog
Seamlessly govern structured and unstructured data, ML models, notebooks, dashboards and files on any cloud or platform.

Artificial Intelligence
Explore the full suite of Databricks AI tools for end-to-end AI agent systems.

The Databricks Data Intelligence Platform
Explore the full range of tools available on the Databricks Platform to seamlessly integrate data and AI across your organization.
Take the next step




Agent Bricks FAQ
Ready to become a data + AI company?
Take the first steps in your data transformation