Engenharia de Desempenho para Inferência de LLM: Melhores Práticas
por Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo e Daya Khudia
Neste post, a equipe de engenharia da MosaicML compartilha as melhores práticas sobre como capitalizar modelos de linguagem grandes (LLMs) populares de código aberto para uso em produção. Também fornecemos diretrizes para a implantação de serviços de inferência criados em torno desses modelos para ajudar os usuários na seleção de modelos e hardware de implantação. Trabalhamos com vários backends baseados em PyTorch em produção; essas diretrizes são baseadas em nossa experiência com FasterTransformers, vLLM, o futuro lançamento da NVIDIA TensorRT-LLM, e outros.
Entendendo a Geração de Texto de LLMs
Modelos de Linguagem Grandes (LLMs) geram texto em um processo de duas etapas: "prefill", onde os tokens do prompt de entrada são processados em paralelo, e "decodificação", onde o texto é gerado um 'token' por vez de forma autorregressiva. Cada token gerado é anexado à entrada e realimentado no modelo para gerar o próximo token. A geração para quando o LLM gera um token especial de parada ou quando uma condição definida pelo usuário é atendida (por exemplo, um número máximo de tokens foi gerado). Se você quiser mais informações sobre como os LLMs usam blocos de decodificação, confira este post.
Tokens podem ser palavras ou sub-palavras; as regras exatas para dividir texto em tokens variam de modelo para modelo. Por exemplo, você pode comparar como os modelos Llama tokenizam texto com como os modelos OpenAI tokenizam texto. Embora os provedores de inferência de LLM frequentemente falem sobre desempenho em métricas baseadas em tokens (por exemplo, tokens/segundo), esses números nem sempre são comparáveis entre tipos de modelo dadas essas variações. Para um exemplo concreto, a equipe da Anyscale descobriu que a tokenização do Llama 2 é 19% mais longa do que a tokenização do ChatGPT (mas ainda tem um custo geral muito menor). E pesquisadores da HuggingFace também descobriram que o Llama 2 exigiu ~20% mais tokens para treinar sobre a mesma quantidade de texto que o GPT-4.
Métricas Importantes para Servir LLMs
Então, como exatamente devemos pensar sobre a velocidade de inferência?
Nossa equipe usa quatro métricas principais para servir LLMs:
- Tempo Para o Primeiro Token (TTFT): Quão rapidamente os usuários começam a ver a saída do modelo após inserir sua consulta. Baixos tempos de espera para uma resposta são essenciais em interações em tempo real, mas menos importantes em cargas de trabalho offline. Essa métrica é impulsionada pelo tempo necessário para processar o prompt e, em seguida, gerar o primeiro token de saída.
- Tempo Por Token de Saída (TPOT): Tempo para gerar um token de saída para cada usuário que está consultando nosso sistema. Essa métrica corresponde à forma como cada usuário perceberá a "velocidade" do modelo. Por exemplo, um TPOT de 100 milissegundos/token seria 10 tokens por segundo por usuário, ou ~450 palavras por minuto, o que é mais rápido do que uma pessoa comum consegue ler.
- Latência: O tempo total que o modelo leva para gerar a resposta completa para um usuário. A latência geral da resposta pode ser calculada usando as duas métricas anteriores: latência = (TTFT) + (TPOT) * (o número de tokens a serem gerados).
- Throughput: O número de tokens de saída por segundo que um servidor de inferência pode gerar para todos os usuários e solicitações.
Nosso objetivo? O tempo mais rápido para o primeiro token, o maior throughput e o tempo mais rápido por token de saída. Em outras palavras, queremos que nossos modelos gerem texto o mais rápido possível para o maior número de usuários que pudermos suportar.
Notavelmente, há um trade-off entre throughput e tempo por token de saída: se processarmos 16 consultas de usuários concorrentemente, teremos um throughput maior em comparação com a execução sequencial das consultas, mas levaremos mais tempo para gerar tokens de saída para cada usuário.
Se você tem metas gerais de latência de inferência, aqui estão algumas heurísticas úteis para avaliar modelos:
- O comprimento da saída domina a latência geral da resposta: Para latência média, você geralmente pode pegar o comprimento esperado/máximo de tokens de saída e multiplicá-lo por um tempo médio geral por token de saída para o modelo.
- O comprimento da entrada não é significativo para o desempenho, mas é importante para os requisitos de hardware: A adição de 512 tokens de entrada aumenta a latência menos do que a produção de 8 tokens de saída adicionais nos modelos MPT. No entanto, a necessidade de suportar entradas longas pode tornar os modelos mais difíceis de servir. Por exemplo, recomendamos o uso do A100-80GB (ou mais novo) para servir o MPT-7B com seu comprimento de contexto máximo de 2048 tokens.
- A latência geral escala de forma sublinear com o tamanho do modelo: No mesmo hardware, modelos maiores são mais lentos, mas a proporção de velocidade não corresponderá necessariamente à proporção da contagem de parâmetros. A latência do MPT-30B é ~2,5x a latência do MPT-7B. A latência do Llama2-70B é ~2x a latência do Llama2-13B.
Muitas vezes nos perguntam por clientes potenciais para fornecer uma latência média de inferência. Recomendamos que, antes de se fixar em metas específicas de latência ("precisamos de menos de 20 ms por token"), você gaste algum tempo caracterizando seus comprimentos de entrada esperados e desejados.
Desafios na Inferência de LLMs
A otimização da inferência de LLMs se beneficia de técnicas gerais, como:
- Fusão de Operadores: Combinar diferentes operadores adjacentes geralmente resulta em melhor latência.
- Quantização: Ativações e pesos são comprimidos para usar um número menor de bits.
- Compressão: Esparsidade ou Destilação.
- Paralelização: Paralelismo de tensores entre vários dispositivos ou paralelismo de pipeline para modelos maiores.
Além desses métodos, existem muitas otimizações importantes específicas do Transformer. Um exemplo principal disso é o cache KV (chave-valor). O mecanismo de Atenção em modelos baseados em Transformer apenas com decodificador é computacionalmente ineficiente. Cada token atende a todos os tokens vistos anteriormente e, portanto, recalcula muitos dos mesmos valores à medida que cada novo token é gerado. Por exemplo, ao gerar o N-ésimo token, o (N-1)-ésimo token atende aos tokens (N-2), (N-3) … 1º. Da mesma forma, ao gerar o (N+1)-ésimo token, a atenção para o N-ésimo token novamente precisa olhar para os tokens (N-1), (N-2), (N-3), … 1º. O cache KV, ou seja, o salvamento de chaves/valores intermediários para as camadas de atenção, é usado para preservar esses resultados para reutilização posterior, evitando cálculos repetidos.
Largura de Banda de Memória é Fundamental
As computações em LLMs são predominantemente dominadas por operações de multiplicação de matrizes; essas operações com dimensões pequenas são tipicamente limitadas pela largura de banda da memória na maioria dos hardwares. Ao gerar tokens de forma autorregressiva, uma das dimensões da matriz de ativação (definida pelo tamanho do lote e número de tokens na sequência) é pequena em tamanhos de lote pequenos. Portanto, a velocidade depende de quão rápido podemos carregar os parâmetros do modelo da memória da GPU para caches/registradores locais, em vez de quão rápido podemos computar sobre os dados carregados. A largura de banda de memória disponível e alcançada no hardware de inferência é um preditor melhor da velocidade de geração de tokens do que seu desempenho de pico de computação.
A utilização do hardware de inferência é muito importante em termos de custos de serviço. GPUs são caras e precisamos que elas façam o máximo de trabalho possível. Serviços de inferência compartilhados prometem manter os custos baixos combinando cargas de trabalho de muitos usuários, preenchendo lacunas individuais e agrupando solicitações sobrepostas. Para modelos grandes como o Llama2-70B, alcançamos bom custo/desempenho apenas em tamanhos de lote grandes. Ter um sistema de serviço de inferência que possa operar em tamanhos de lote grandes é crítico para a eficiência de custos. No entanto, um lote grande significa um tamanho de cache KV maior, e isso, por sua vez, aumenta o número de GPUs necessárias para servir o modelo. Há um cabo de guerra aqui e os operadores de serviço compartilhado precisam fazer algumas concessões de custo e implementar otimizações de sistema.
Utilização de Largura de Banda do Modelo (MBU)
Quão otimizado está um servidor de inferência de LLM?
Como explicado brevemente anteriormente, a inferência para LLMs em tamanhos de lote menores — especialmente no tempo de decodificação — é limitada pela rapidez com que podemos carregar os parâmetros do modelo da memória do dispositivo para as unidades de computação. A largura de banda da memória dita a rapidez com que a movimentação de dados ocorre. Para medir a utilização do hardware subjacente, introduzimos uma nova métrica chamada Utilização de Largura de Banda do Modelo (MBU). MBU é definida como (largura de banda de memória alcançada) / (largura de banda de memória de pico), onde a largura de banda de memória alcançada é ((tamanho total dos parâmetros do modelo + tamanho do cache KV) / TPOT).
Por exemplo, se um modelo de 7B parâmetros rodando com precisão de 16 bits tem TPOT igual a 14ms, então ele está movendo 14GB de parâmetros em 14ms, o que se traduz em um uso de largura de banda de 1TB/seg. Se a largura de banda de pico da máquina é de 2TB/seg, estamos operando com um MBU de 50%. Para simplificar, este exemplo ignora o tamanho do cache KV, que é pequeno para tamanhos de lote menores e comprimentos de sequência mais curtos. Valores de MBU próximos a 100% implicam que o sistema de inferência está utilizando efetivamente a largura de banda de memória disponível. O MBU também é útil para comparar diferentes sistemas de inferência (hardware + software) de forma normalizada. O MBU é complementar à métrica Model Flops Utilization (MFU; introduzida no artigo PaLM), que é importante em cenários com gargalo de processamento.
A Figura 1 mostra uma representação pictórica do MBU em um gráfico semelhante a um gráfico roofline. A linha inclinada sólida da região sombreada em laranja mostra a vazão máxima possível se a largura de banda da memória estiver totalmente saturada em 100%. No entanto, na realidade, para tamanhos de lote pequenos (ponto branco), o desempenho observado é inferior ao máximo – o quão inferior é uma medida do MBU. Para tamanhos de lote grandes (região amarela), o sistema está limitado pelo processamento, e a vazão alcançada como uma fração da vazão máxima possível é medida como Model Flops Utilization (MFU).
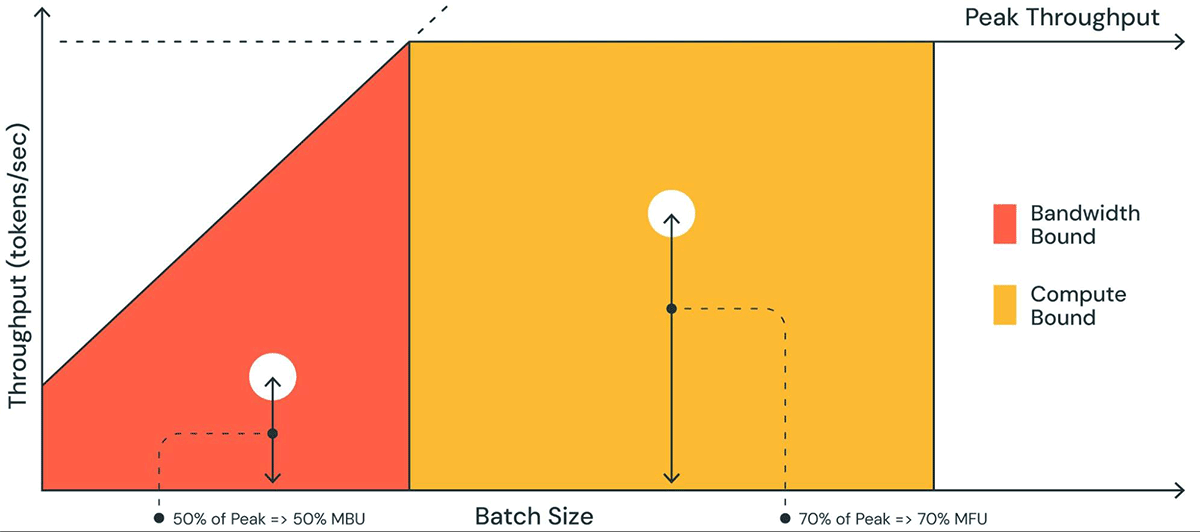
MBU e MFU determinam quanto espaço adicional está disponível para aumentar a velocidade de inferência em uma configuração de hardware específica. A Figura 2 mostra o MBU medido para diferentes graus de paralelismo tensorial com nosso servidor de inferência baseado em TensorRT-LLM. A utilização de pico da largura de banda da memória é atingida ao transferir grandes blocos contíguos de memória. Quando modelos menores como o MPT-7B são distribuídos por várias GPUs, observamos um MBU menor, pois estamos movendo blocos de memória menores em cada GPU.
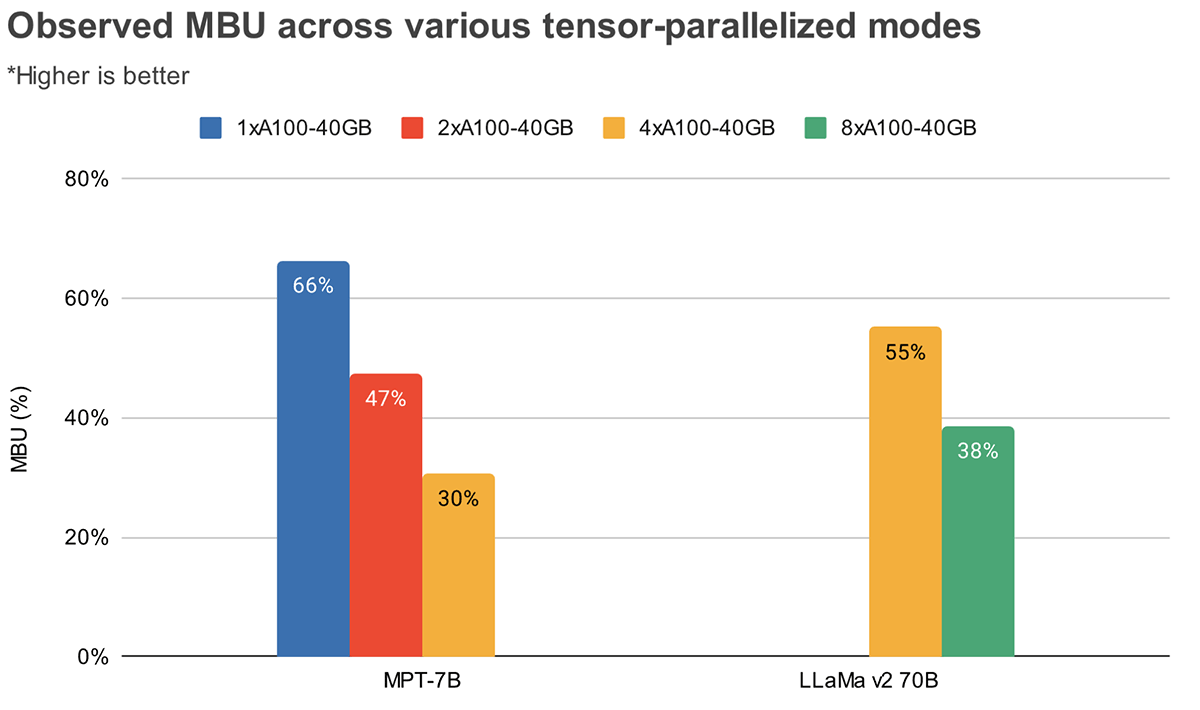
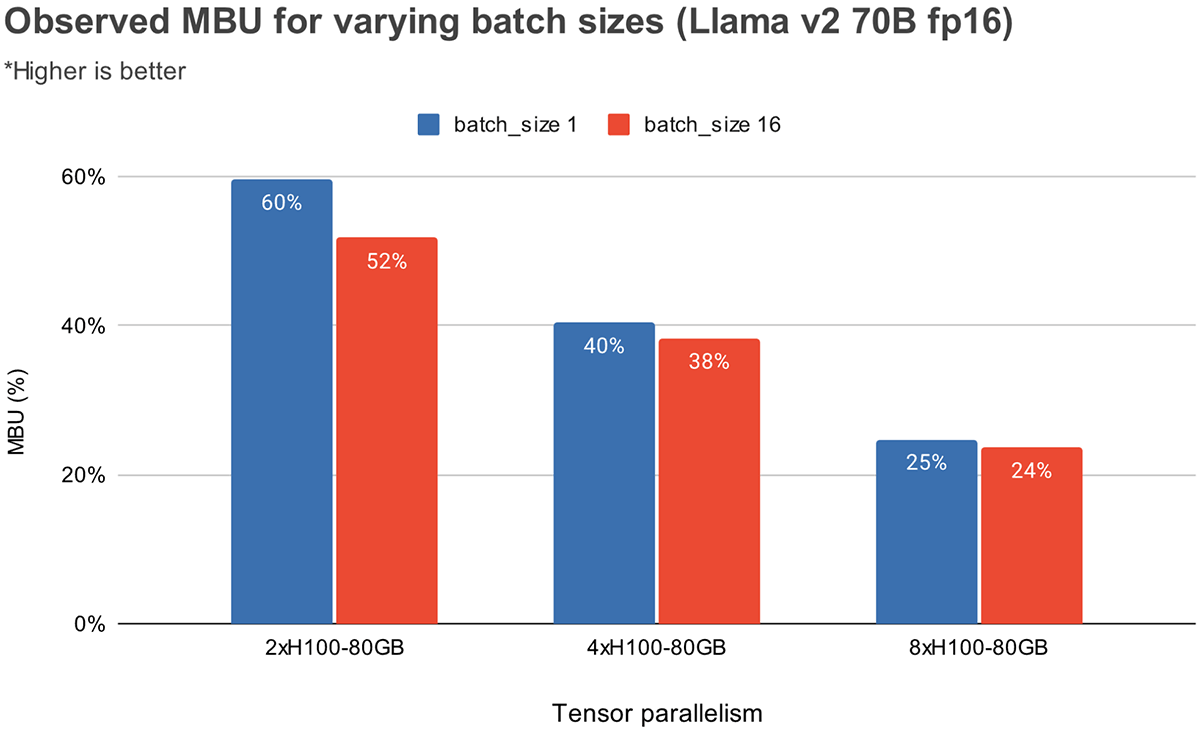
A Figura 3 mostra o MBU observado empiricamente para diferentes graus de paralelismo tensorial e tamanhos de lote nas GPUs NVIDIA H100. O MBU diminui à medida que o tamanho do lote aumenta. No entanto, à medida que escalamos as GPUs, a diminuição relativa no MBU é menos significativa. Vale ressaltar também que a escolha de hardware com maior largura de banda de memória pode impulsionar o desempenho com menos GPUs. No tamanho de lote 1, podemos atingir um MBU mais alto de 60% em 2xH100-80GB em comparação com 55% em 4xA100-40GB GPUs (Figura 2).
Resultados de Benchmarking
Latência
Medimos o tempo para o primeiro token (TTFT) e o tempo por token de saída (TPOT) em diferentes graus de paralelismo tensorial para os modelos MPT-7B e Llama2-70B. À medida que os prompts de entrada se tornam mais longos, o tempo para gerar o primeiro token começa a consumir uma parte substancial da latência total. O paralelismo tensorial em várias GPUs ajuda a reduzir essa latência.
Ao contrário do treinamento de modelos, escalar para mais GPUs oferece retornos decrescentes significativos para a latência de inferência. Por exemplo, para Llama2-70B, passar de 4x para 8x GPUs diminui a latência em apenas 0,7x em tamanhos de lote pequenos. Uma razão para isso é que o paralelismo mais alto tem um MBU menor (como discutido anteriormente). Outra razão é que o paralelismo tensorial introduz sobrecarga de comunicação entre um nó de GPU.
| Tempo para o primeiro token (ms) | ||||
|---|---|---|---|---|
| Modelo | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0,73x) | 26 (0,56x) | - |
| Llama2-70B | Não cabe | 154 (1x) | 114 (0,74x) | |
Tabela 1: Tempo para o primeiro token, dadas requisições de entrada com 512 tokens de comprimento e tamanho de lote de 1. Modelos maiores como Llama2 70B precisam de pelo menos 4 GPUs A100-40B para caber na memória
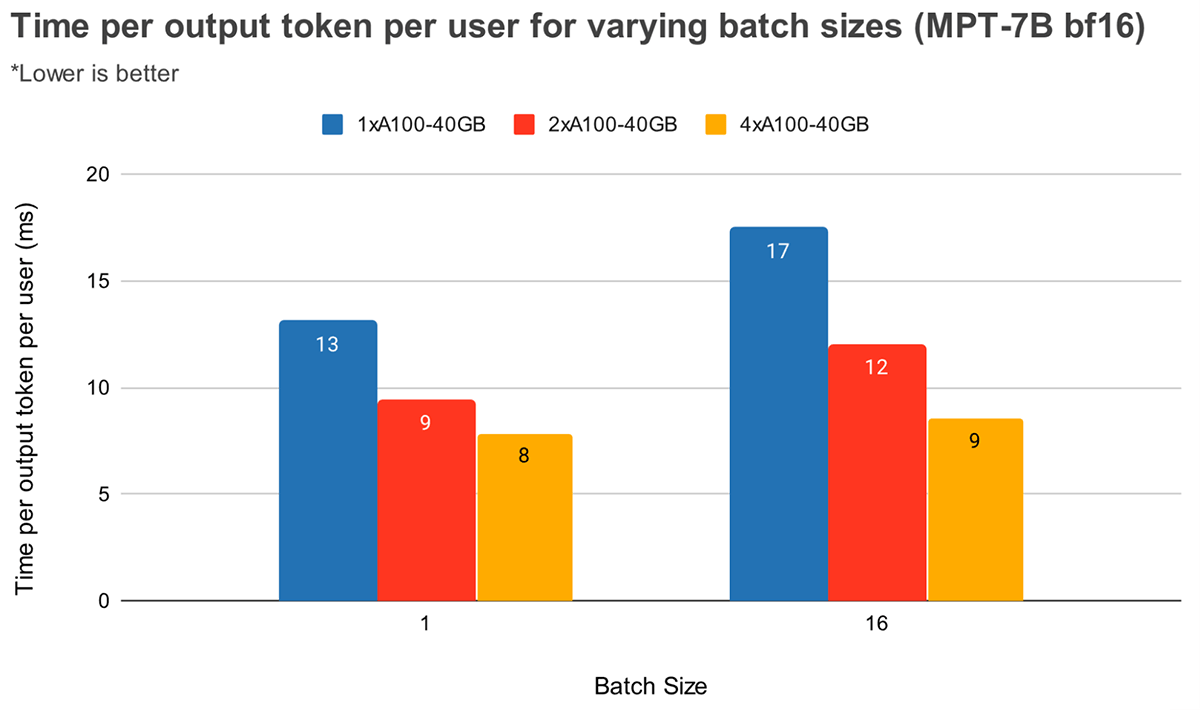
Em tamanhos de lote maiores, o paralelismo tensorial mais alto leva a uma diminuição relativa mais significativa na latência do token. A Figura 4 mostra como o tempo por token de saída varia para o MPT-7B. No tamanho de lote 1, passar de 2x para 4x reduz a latência do token em apenas ~12%. No tamanho de lote 16, a latência com 4x é 33% menor do que com 2x. Isso está de acordo com nossa observação anterior de que a diminuição relativa no MBU é menor em graus mais altos de paralelismo tensorial para o tamanho de lote 16 em comparação com o tamanho de lote 1.
A Figura 5 mostra resultados semelhantes para o Llama2-70B, exceto que a melhoria relativa entre 4x e 8x é menos pronunciada. Também comparamos o escalonamento de GPU em duas configurações de hardware diferentes. Como o H100-80GB tem 2,15x mais largura de banda de memória por GPU em comparação com o A100-40GB, podemos ver que a latência é 36% menor no tamanho de lote 1 e 52% menor no tamanho de lote 16 para sistemas 4x.
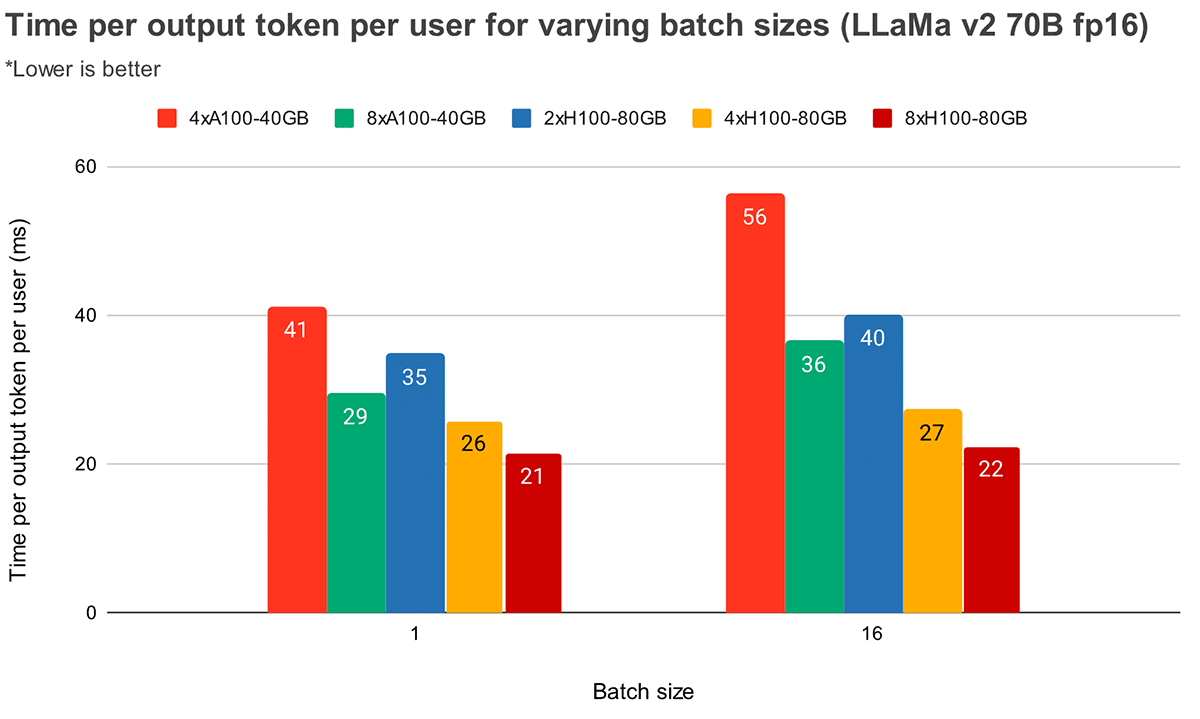
Vazão
Podemos negociar vazão e tempo por token agrupando requisições. Agrupar consultas durante a avaliação da GPU aumenta a vazão em comparação com o processamento sequencial de consultas, mas cada consulta levará mais tempo para ser concluída (ignorando efeitos de enfileiramento).
Existem algumas técnicas comuns para agrupar requisições de inferência:
- Batching estático: O cliente agrupa vários prompts em requisições e uma resposta é retornada após a conclusão de todas as sequências no lote. Nossos servidores de inferência suportam isso, mas não o exigem.
- Batching dinâmico: Os prompts são agrupados em tempo real dentro do servidor. Normalmente, este método tem desempenho inferior ao batching estático, mas pode chegar perto do ideal se as respostas forem curtas ou de comprimento uniforme. Não funciona bem quando as requisições têm parâmetros diferentes.
- Batching contínuo: A ideia de agrupar requisições à medida que chegam foi introduzida neste excelente artigo aqui e é atualmente o método SOTA. Em vez de esperar que todas as sequências em um lote terminem, ele agrupa sequências no nível da iteração. Ele pode atingir uma vazão 10x-20x melhor do que o batching dinâmico.
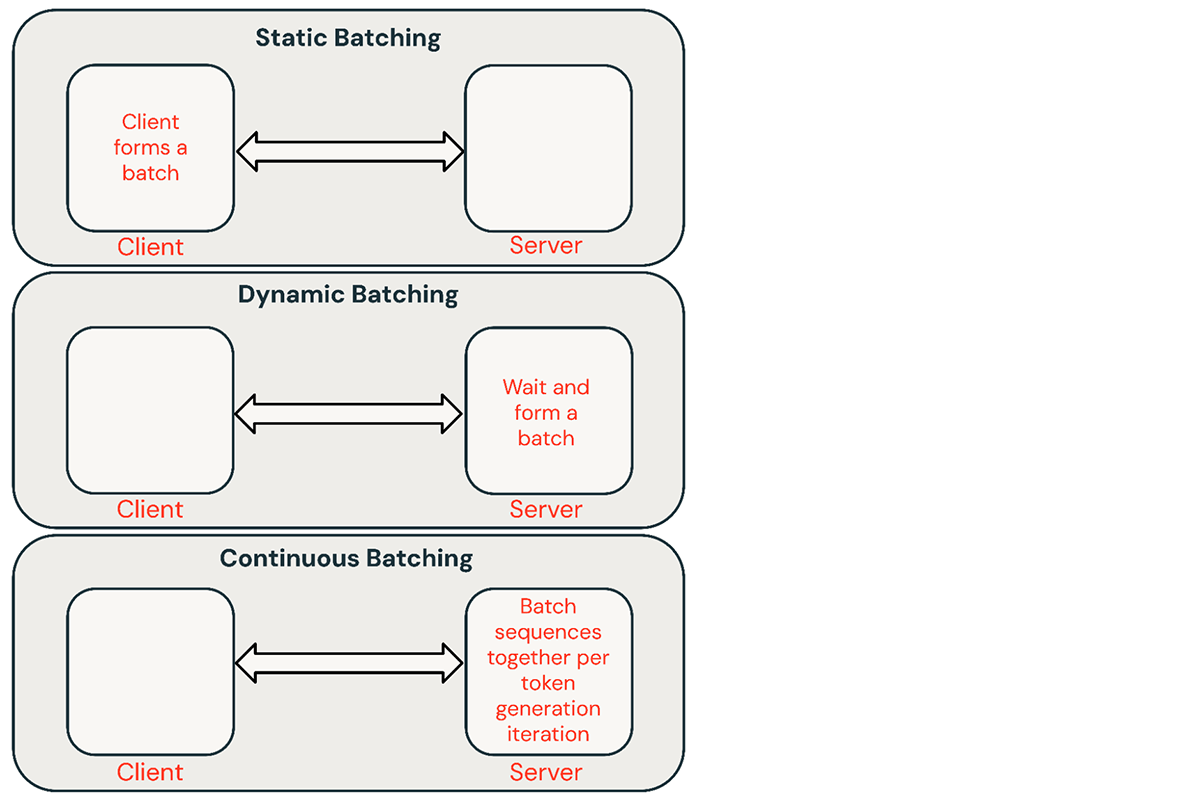
O batching contínuo é geralmente a melhor abordagem para serviços compartilhados, mas há situações em que os outros dois podem ser melhores. Em ambientes de baixo QPS, o batching dinâmico pode superar o batching contínuo. Às vezes, é mais fácil implementar otimizações de GPU de baixo nível em uma estrutura de batching mais simples. Para cargas de trabalho de inferência em lote offline, o batching estático pode evitar sobrecarga significativa e alcançar melhor vazão.
Tamanho do Lote
O desempenho do batching depende muito do fluxo de requisições. Mas podemos obter um limite superior de seu desempenho, comparando o batching estático com requisições uniformes.
| Tamanho do batch | |||||||
|---|---|---|---|---|---|---|---|
| Hardware | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | Erro OOM (Out of Memory) | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
Tabela 2: Throughput máximo (req/seg) do MPT-7B com batching estático e um backend baseado em FasterTransformers. Requisições: 512 tokens de entrada e 64 de saída. Para entradas maiores, o limite de OOM ocorrerá em tamanhos de batch menores.
Trade-off de Latência
A latência da requisição aumenta com o tamanho do batch. Com uma única GPU NVIDIA A100, por exemplo, se maximizarmos o throughput com um tamanho de batch de 64, a latência aumenta 4x enquanto o throughput aumenta 14x. Serviços de inferência compartilhados geralmente escolhem um tamanho de batch balanceado. Usuários que hospedam seus próprios modelos devem decidir o trade-off apropriado de latência/throughput para suas aplicações. Em algumas aplicações, como chatbots, baixa latência para respostas rápidas é a prioridade máxima. Em outras aplicações, como processamento em batch de PDFs não estruturados, podemos querer sacrificar a latência para processar um documento individual para processar todos eles rapidamente em paralelo.
A Figura 7 mostra a curva de throughput vs latência para o modelo de 7B. Cada linha nessa curva é obtida aumentando o tamanho do batch de 1 para 256. Isso é útil para determinar o quão grande podemos tornar o tamanho do batch, sujeito a diferentes restrições de latência. Relembrando nosso gráfico de *roofline* acima, descobrimos que essas medições são consistentes com o que esperaríamos. Após um certo tamanho de batch, ou seja, quando cruzamos para o regime de *compute bound*, cada duplicação do tamanho do batch apenas aumenta a latência sem aumentar o throughput.
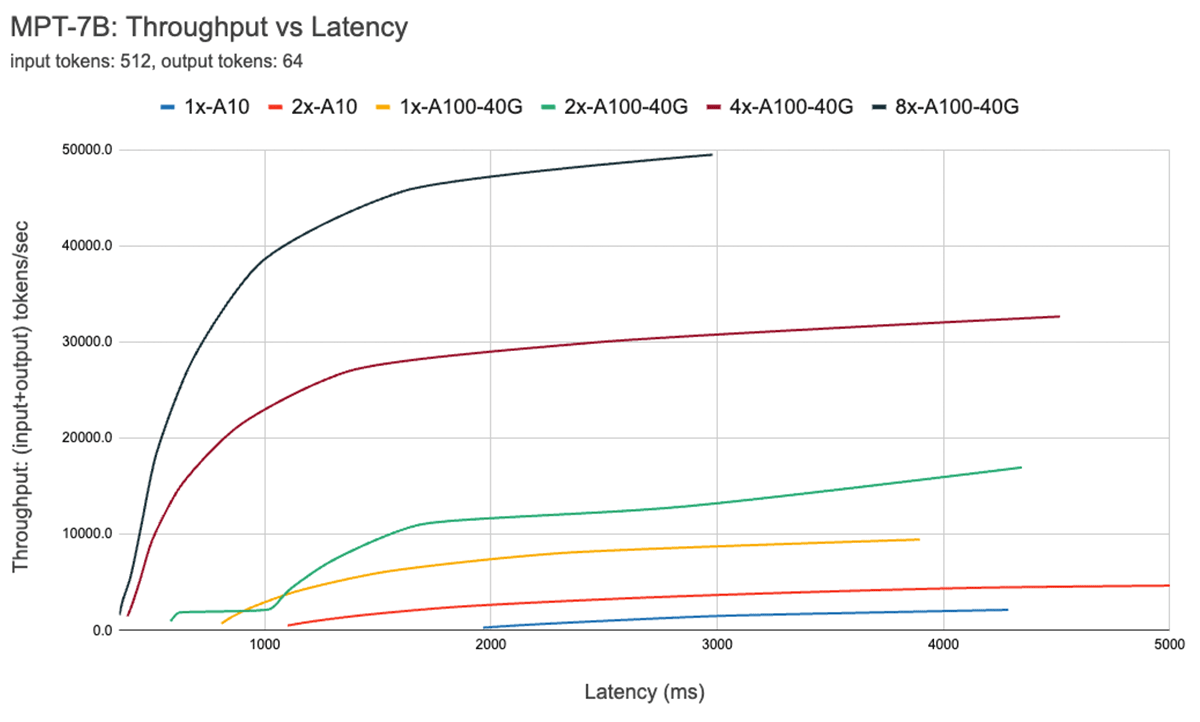
Ao usar paralelismo, é importante entender detalhes de hardware de baixo nível. Por exemplo, nem todas as instâncias 8xA100 são iguais entre diferentes nuvens. Alguns servidores têm conexões de alta largura de banda entre todas as GPUs, outros pareiam GPUs e têm conexões de menor largura de banda entre os pares. Isso pode introduzir gargalos, fazendo com que o desempenho do mundo real se desvie significativamente das curvas acima.
Estudo de Caso de Otimização: Quantização
Quantização é uma técnica comum usada para reduzir os requisitos de hardware para inferência de LLM. Reduzir a precisão dos pesos e ativações do modelo durante a inferência pode reduzir drasticamente os requisitos de hardware. Por exemplo, a troca de pesos de 16 bits para pesos de 8 bits pode reduzir pela metade o número de GPUs necessárias em ambientes com memória limitada (por exemplo, Llama2-70B em A100s). Reduzir para pesos de 4 bits possibilita executar inferência em hardware de consumidor (por exemplo, Llama2-70B em Macbooks).
Em nossa experiência, a quantização deve ser implementada com cautela. Técnicas de quantização ingênuas podem levar a uma degradação substancial na qualidade do modelo. O impacto da quantização também varia entre arquiteturas e tamanhos de modelo (por exemplo, MPT vs Llama). Exploraremos isso com mais detalhes em um post futuro.
Ao experimentar técnicas como quantização, recomendamos usar um benchmark de qualidade de LLM como o Mosaic Eval Gauntlet para avaliar a qualidade do sistema de inferência, não apenas a qualidade do modelo isoladamente. Além disso, é importante explorar otimizações de sistemas mais profundas. Em particular, a quantização pode tornar os caches KV muito mais eficientes.
Como mencionado anteriormente, na geração de tokens autorregressiva, as Chaves/Valores (KV) passados das camadas de atenção são cacheados em vez de serem recalculados a cada passo. O tamanho do cache KV varia com base no número de sequências processadas por vez e no comprimento dessas sequências. Além disso, durante cada iteração da geração do próximo token, novos itens KV são adicionados ao cache existente, tornando-o maior à medida que novos tokens são gerados. Portanto, o gerenciamento eficaz da memória do cache KV ao adicionar esses novos valores é crítico para um bom desempenho de inferência. Modelos Llama2 usam uma variante de atenção chamada Grouped Query Attention (GQA). Observe que quando o número de *heads* KV é 1, GQA é o mesmo que Multi-Query-Attention (MQA). GQA ajuda a manter o tamanho do cache KV baixo compartilhando Chaves/Valores. A fórmula para calcular o tamanho do cache KV é
batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (K e V) * 2 (bytes por Float16) * n_kv_heads
A Tabela 3 mostra o tamanho do cache KV GQA calculado em diferentes tamanhos de batch com um comprimento de sequência de 1024 tokens. O tamanho do parâmetro para modelos Llama2, em comparação, é de 140 GB (Float16) para o modelo de 70B. A quantização do cache KV é outra técnica (além de GQA/MQA) para reduzir o tamanho do cache KV, e estamos avaliando ativamente seu impacto na qualidade da geração.
| Tamanho do Batch | Memória do cache KV GQA (FP16) | Memória do cache KV GQA (Int8) |
|---|---|---|
| 1 | 0.312 GiB | 0.156 GiB |
| 16 | 5 GiB | 2.5 GiB |
| 32 | 10 GiB | 5 GiB |
| 64 | 20 GiB | 10 GiB |
Tabela 3: Tamanho do cache KV para Llama-2-70B com comprimento de sequência de 1024
Como mencionado anteriormente, a geração de tokens com LLMs em baixos tamanhos de batch é um problema limitado pela largura de banda da memória da GPU, ou seja, a velocidade de geração depende da rapidez com que os parâmetros do modelo podem ser movidos da memória da GPU para os caches on-chip. Converter pesos do modelo de FP16 (2 bytes) para INT8 (1 byte) ou INT4 (0,5 byte) requer a movimentação de menos dados e, portanto, acelera a geração de tokens. No entanto, a quantização pode impactar negativamente a qualidade da geração do modelo. Estamos atualmente avaliando o impacto na qualidade do modelo usando o Model Gauntlet e planejamos publicar um post de acompanhamento em breve.
Conclusões e Principais Resultados
Cada um dos fatores que delineamos acima influencia a forma como construímos e implantamos modelos. Usamos esses resultados para tomar decisões baseadas em dados que levam em consideração o tipo de hardware, o stack de software, a arquitetura do modelo e os padrões de uso típicos. Aqui estão algumas recomendações baseadas em nossa experiência.
Identifique seu alvo de otimização: Você se preocupa com o desempenho interativo? Maximizar o throughput? Minimizar o custo? Existem trade-offs previsíveis aqui.
Preste atenção aos componentes da latência: Para aplicações interativas, o tempo para o primeiro token (time-to-first-token) determina a responsividade do seu serviço e o tempo por token de saída (time-per-output-token) determina a velocidade com que ele parecerá.
Largura de banda da memória é fundamental: A geração do primeiro token é tipicamente um problema *compute-bound*, enquanto a decodificação subsequente é uma operação *memory-bound*. Como a inferência de LLM frequentemente opera em cenários *memory-bound*, MBU (Memory Bandwidth Utilization) é uma métrica útil para otimizar e pode ser usada para comparar a eficiência dos sistemas de inferência.
Batching é fundamental: Processar várias requisições simultaneamente é crucial para atingir alta vazão (throughput) e para utilizar GPUs caras de forma eficaz. Para serviços online compartilhados, o batching contínuo é indispensável, enquanto cargas de trabalho de inferência em batch offline podem atingir alta vazão com técnicas de batching mais simples.
Otimizações aprofundadas: Técnicas padrão de otimização de inferência são importantes (ex: fusão de operadores, quantização de pesos) para LLMs, mas é importante explorar otimizações de sistemas mais profundas, especialmente aquelas que melhoram a utilização da memória. Um exemplo é a quantização do cache KV.
Configurações de hardware: O tipo de modelo e a carga de trabalho esperada devem ser usados para decidir o hardware de implantação. Por exemplo, ao escalar para várias GPUs, a MBU (Utilização de Memória de GPU) cai muito mais rapidamente para modelos menores, como o MPT-7B, do que para modelos maiores, como o Llama2-70B. O desempenho também tende a escalar de forma sublinear com graus mais altos de paralelismo de tensor. Dito isso, um alto grau de paralelismo de tensor ainda pode fazer sentido para modelos menores se o tráfego for alto ou se os usuários estiverem dispostos a pagar um extra por latência extra baixa.
Decisões baseadas em dados: Entender a teoria é importante, mas recomendamos sempre medir o desempenho do servidor de ponta a ponta. Existem muitas razões pelas quais uma implantação de inferência pode ter um desempenho pior do que o esperado. A MBU pode ser inesperadamente baixa devido a ineficiências de software. Ou diferenças de hardware entre provedores de nuvem podem levar a surpresas (observamos uma diferença de latência de 2x entre servidores 8xA100 de dois provedores de nuvem).
Para começar com a inferência de LLM, experimente o Databricks Model Serving. Confira a documentação para saber mais.
Veja todos os blogs anteriores da MosaicML
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.