LLMs em lakehouse: um salto quântico para o setor público
por Tim Lortz, Parth Vakil e Lisa Sion

Nos últimos meses, o interesse em Modelos de Linguagem Grandes (LLMs) por parte de agências do Setor Público disparou, pois os LLMs estão mudando fundamentalmente as expectativas que as pessoas têm em suas interações com computadores e dados. Do ponto de vista da Databricks, praticamente todos os clientes e prospects do Setor Público com quem interagimos sentem o dever de injetar LLMs em sua missão. Ouvimos repetidamente perguntas sobre o que são os LLMs (como o Dolly da Databricks), para que podem ser usados e como o Databricks Lakehouse dará suporte a aplicações relacionadas a LLMs. Nesta postagem, abordaremos essas questões no contexto das necessidades, oportunidades e restrições únicas das organizações do Setor Público. Também focaremos nos benefícios de criar, possuir e fazer a curadoria do seu próprio LLM em vez de adotar uma tecnología que exige o compartilhamento de dados com terceiros, como o ChatGPT.
O que são LLMs?
Os LLMs atuais representam a versão mais recente de uma série de inovações no processamento de linguagem natural, começando aproximadamente em 2017 com o surgimento da arquitetura de modelo transformer. Esses modelos baseados em transformer há muito tempo possuem habilidades surpreendentes para entender a linguagem humana bem o suficiente para realizar tarefas como identificar sentimentos, extrair pessoas, lugares e coisas nomeadas e traduzir documentos de um idioma para outro. Eles também são capazes de gerar textos interessantes a partir de um prompt, com diferentes graus de qualidade e precisão. Mais recentemente, pesquisadores e desenvolvedores descobriram que modelos de linguagem muito grandes, "pré-treinados" em fontes de texto muito grandes e diversas, podem ser "ajustados" para seguir uma variedade de instruções de um ser humano para gerar informações úteis.
Anteriormente, a melhor prática era ensinar modelos separados para cada tarefa relacionada ao idioma. O processo de treinamento do modelo exigia recursos: dados com curadoria, compute (normalmente uma ou mais GPUs) e conhecimento avançado em ciência de dados e desenvolvimento de software. Embora tais modelos possam ter alta precisão, existem claramente restrições de recursos, tanto em termos de computação quanto de esforço humano, ao escalonar seu uso. Com a rápida ascensão do ChatGPT ao estrelato, agora vemos que um único LLM - com a quantidade apropriada de contexto e o prompt certo - pode ser usado para realizar muitas tarefas diferentes, às vezes com mais precisão do que um modelo mais especializado. E a capacidade dos LLMs de gerar novos textos - "IA Generativa" - é fascinante e extremamente útil.
Para que os LLMs podem ser usados no Setor Público?
Organizações do setor privado relataram benefícios incríveis dos LLMs, como geração e migração de código, categorização e respostas automatizadas de feedback de clientes, chatbots de call center, geração de relatórios e muito mais. Como um microcosmo de muitas indústrias diferentes, as agências do Setor Público têm as mesmas oportunidades de LLM, além de outras necessidades exclusivas. Os casos de uso comuns do setor público incluem:
- Assistência de compliance regulatória. Com sua capacidade de interpretar e processar texto, um LLM pode ajudar a determinar os requisitos de compliance, analisando documentos regulatórios, textos jurídicos e jurisprudência relevante. Isso pode ajudar agências governamentais e empresas a entender as implicações das regulamentações e garantir o cumprimento da lei.
- Assistente de treinamento e educação. Escale e acelere o aprendizado dos alunos atuando como um instrutor virtual, respondendo a perguntas, explicando conceitos complexos, recuperando partes relevantes de gravações de aulas ou recomendando ofertas do catálogo de cursos.
- Resumindo e respondendo a perguntas de documentos técnicos. Talvez o caso de uso mais comum relacionado a LLMs no setor público seja extrair conhecimento de milhares ou milhões de documentos, incluindo PDFs e emails, em um formato que facilite a localização rápida de conteúdo relevante com base em critérios de pesquisa e, em seguida, usar o conteúdo relevante para gerar resumos ou relatórios.
- Inteligência de fontes abertas. Os LLMs podem aprimorar muito a análise da Comunidade de Inteligência de Inteligência de Fontes Abertas (OSINT), processando e analisando grandes quantidades de informações multilíngues disponíveis publicamente. Os LLMs podem extrair key entidades, relacionamentos, sentimentos e compreensão contextual de diversas fontes, como mídias sociais, artigos de notícias e relatórios e, em seguida, resumir e organizar com eficiência essas informações, ajudando os analistas a compreender rapidamente e extrair percepções de grandes volumes de dados OSINT.
- Modernização de bases de código legadas. As agências governamentais continuam a migrar as cargas de trabalho de dados de mainframes, data warehouses on-premises e software de analítica proprietários. Ao colocar assistentes de programação nas mãos de desenvolvedores e analistas para sugerir código à medida que programam, ou treinar LLMs personalizados para lidar com a conversão de código em massa, o ritmo da migração pode acelerar enquanto os trabalhadores do conhecimento adquirem com naturalidade as habilidades de software relevantes.
- Recursos humanos. Como o maior empregador do país, o governo federal enfrenta desafios únicos na contratação e na garantia da satisfação dos funcionários. O uso de LLMs na área de RH pode ajudar a lidar com esses desafios, automatizando a triagem de currículos, combinando candidatos com descrições de job e analisando o feedback dos funcionários para melhorar os processos de contratação e aumentar o engajamento da força de trabalho. Além disso, os LLMs podem auxiliar na garantia da compliance com as políticas de RH, no apoio a iniciativas de diversidade e inclusão e no fornecimento de recomendações personalizadas de integração e desenvolvimento de carreira.
Como o Databricks apoiará as necessidades das organizações do setor público em um mundo impulsionado por LLMs?
Embora certamente poderosos, os LLMs também apresentam um novo conjunto de desafios que é amplificado por algumas das restrições operacionais nativas das organizações do Setor Público. Vamos analisar alguns deles e alinhá-los com os recursos do Databricks Lakehouse:
Desafio nº 1: Soberania e governança de dados
O desafio?
A maioria das organizações do Setor Público tem controles regulatórios rigorosos em relação aos seus dados. Esses controles existem por motivos de privacidade, segurança e pela necessidade de preservar o sigilo em alguns casos. Até mesmo a tarefa simples de fazer uma pergunta ou um conjunto de perguntas a um LLM poderia revelar informações proprietárias. Além disso, a maioria das agências federais precisará fazer o ajuste fino dos LLMs para atender aos seus requisitos específicos. Por esses motivos, é lógico supor que as agências do Setor Público terão uso limitado de modelos públicos. É provável que elas exijam que o ajuste fino dos modelos seja feito em um ambiente que garanta sua confidencialidade e segurança, e que as interações com os modelos por meio de vários métodos de prompting também sejam confidenciais.
A solução da Databricks
A Databricks Lakehouse Platform tem as ferramentas necessárias para desenvolver e implantar aplicativos de LLM de ponta a ponta. (Mais sobre isso depois.) Além disso, a Databricks possui as certificações necessárias para processar dados para a grande maioria das organizações do setor público dos EUA. A Databricks é um parceiro confiável e capaz para organizações que buscam aproveitar todo o poder dos LLMs sem os riscos que vêm do uso de LLMs proprietários como serviço, como ChatGPT ou Bard.
Além do Databricks, o setor tem visto evidências crescentes de que os LLMs de código aberto, quando usados adequadamente, podem fornecer resultados que se aproximam da paridade com os principais LLMs proprietários. A evidência é mais forte em casos de uso nos quais os LLMs proprietários precisam entender contextos ou instruções com nuances para os quais não foram treinados anteriormente. Nesses casos, os LLMs de código aberto podem receber prompts ou passar por fine-tuning com dados específicos da organização para fornecer resultados surpreendentes. Nessa arquitetura de solução, as organizações podem alcançar resultados de classe mundial com quantidades modestas de tempo de compute e desenvolvimento, sem que os dados saiam dos limites aprovados. Para organizações do setor público, isso representa uma vantagem significativa que não pode ser ignorada.
A crença do Databricks no poder dos LLMs de código aberto é reforçada pelo lançamento do Dolly 2.0, o primeiro LLM de código aberto que segue instruções e que passou por fine-tuning com um dataset de instrução gerado por humanos licenciado para pesquisa e uso comercial. O lançamento do Dolly foi seguido por uma onda de outros LLMs de código aberto capazes, alguns dos quais com um desempenho muito impressionante. A Databricks se esforça para oferecer às organizações do Setor Público uma plataforma para criar aplicações com o LLM de sua escolha — de código aberto ou comercial — e estamos entusiasmados com o que está por vir.

Desafio nº 2: Complexidade arquitetural
O desafio?
A modernização do patrimônio de dados continua sendo uma prioridade para a maioria dos líderes técnicos do Setor Público. Já se foram os dias dos data warehouses on-premises, normalmente substituídos por um data warehouse ou lakehouse na cloud. As organizações que ainda não migraram para a cloud, ou que optaram por um data warehouse na cloud, agora enfrentam outro ponto de inflexão: como adotar LLMs em uma arquitetura que não pode acomodá-los? Dado o imenso potencial dos LLMs de impactar as missões das agências e os servidores públicos que as executam, é fundamental estabelecer uma arquitetura à prova de futuro. É aí que entra o lakehouse.
A solução da Databricks
O Databricks há muito tempo é uma plataforma robusta para cargas de trabalho de machine learning (ML) e inteligência artificial (AI). Os clientes usam LLMs de nível de produção e seus predecessores no Databricks há anos, aproveitando recursos como:
- Compute escalonável para pré-processamento de dados não estruturados como texto, imagens e áudio
- Acesso ao conjunto completo de bibliotecas de ML/AI de código aberto
- Um ambiente de desenvolvimento de notebooks nativo e de primeira classe, com excelente suporte para integração com IDE também
- Recursos de governança de dados via Unity Catalog que garantem controles de acesso adequados a
- Dados estruturados (bancos de dados e tabelas)
- Dados não estruturados (arquivos, imagens, documentos)
- Modelos (LLMs ou outros)
- Opções de compute de GPU para o treinamento e as previsões de modelos de ML: agora um pré-requisito para trabalhar com LLMs baseados em transformadores.
- Gerenciamento de ponta a ponta do ciclo de vida do modelo com MLflow e Unity Catalog. Os modelos são tratados como cidadãos de primeira classe, com linhagem de seus dados de origem e eventos de treinamento, e podem ser implantados em modo de lotes ou em tempo real
- Recursos de servindo modelo, que se tornam cada vez mais essenciais à medida que as organizações fazem o ajuste fino, hospedam e implantam seus próprios LLMs
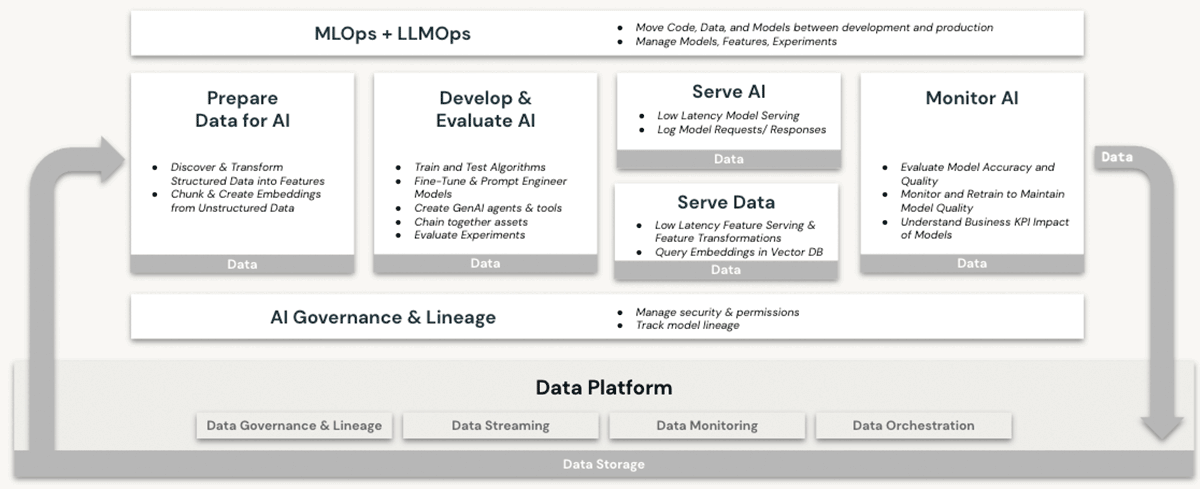
Nenhum desses recursos é oferecido em um data warehouse, mesmo na cloud. Para usar LLMs em conjunto com um data warehouse, uma organização precisaria adquirir outros serviços de software para todas as facetas dos processos de treinamento e implantação do modelo e enviar dados entre esses serviços. Somente a arquitetura Databricks Lakehouse oferece a simplicidade arquitetônica de realizar todas as operações de LLM em uma única plataforma, entregando todos os benefícios explicados em nossa discussão acima sobre soberania de dados.
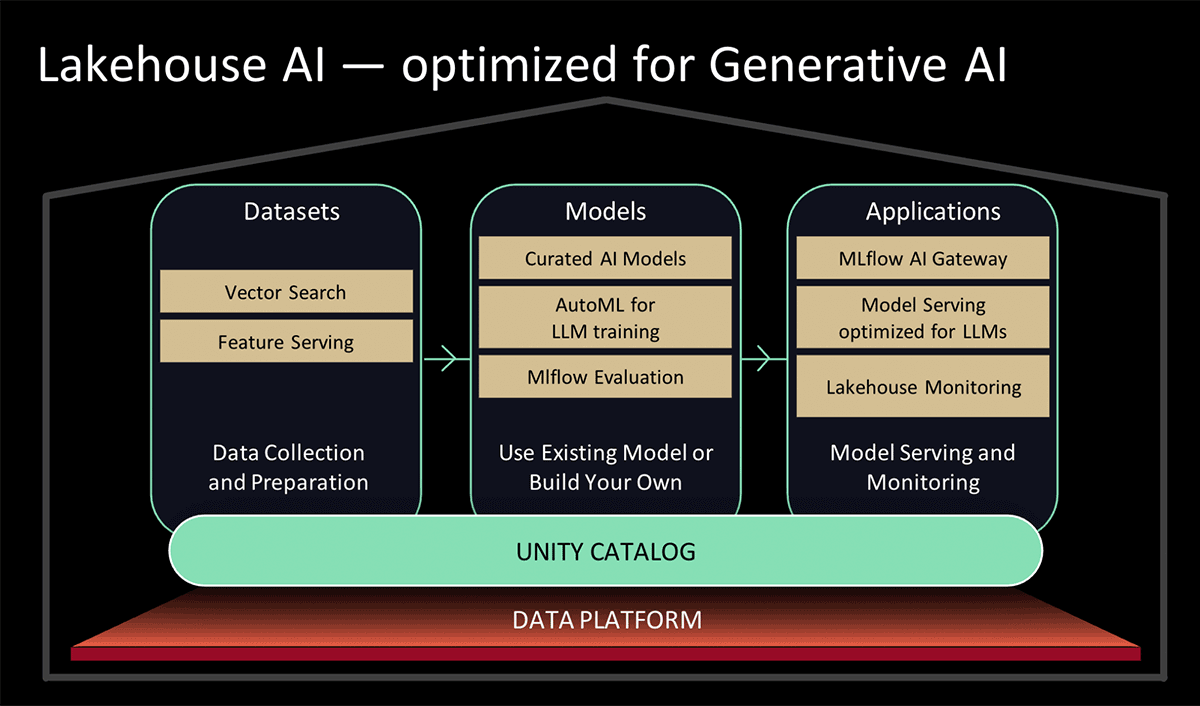
No Data and AI Summit 2023, a Databricks apresentou o Lakehouse AI, que adiciona vários novos recursos importantes relacionados a LLM que simplificam significativamente a arquitetura para LLMOps, incluindo:
- AI Search para indexação. Um banco de dados vetorial hospedado no Databricks ajuda as equipes a indexar rapidamente os dados de suas organizações como vetores de embedding e a realizar pesquisas de similaridade de vetores de baixa latência em implantações em tempo real.
- Monitoramento do lakehouse O primeiro serviço unificado de monitoramento de dados e IA que permite aos usuários rastrear simultaneamente a qualidade de seus ativos de dados e de IA.
- Função de IA. Analistas de dados e engenheiros de dados agora podem usar LLMs e outros modelos do machine learning em uma query SQL interativa ou em um pipeline de ETL SQL/Spark.
- Governança unificada de dados e IA. Aprimoramentos no Unity Catalog para fornecer governança abrangente e acompanhamento de linhagem de ativos de dados e de AI em uma única experiência unificada.
- MLflow AI Gateway O MLflow AI Gateway, parte do MLflow 2.5, é um gateway de API no nível do workspace que permite que as organizações criem e compartilhem rotas, que podem ser configuradas com vários limites de taxa, cache, atribuição de custos etc. para gerenciar custos e uso.
- MLflow 2.4. Esta versão fornece um conjunto abrangente de ferramentas de LLMOps para avaliação de modelos.
Desafio nº 3: Lacuna de habilidades
O desafio?
As agências governamentais têm enfrentado uma persistente "fuga de cérebros" nos últimos anos, especialmente em funções que se sobrepõem a tendências tecnológicas em alta, como cibersegurança, computação em nuvem e ML/IA. O foco intenso atual em LLMs está gerando uma demanda ainda maior por profissionais talentosos em ML/IA. Inevitavelmente, o fascínio e os benefícios que vêm com o emprego em grandes empresas de tecnologia e no cenário das startups agravarão a escassez de talentos no setor público. A liderança do setor público precisa de acesso a plataformas e parcerias que os ajudem a adotar LLMs com facilidade e a capacitar seus funcionários para se tornarem autossuficientes com eles.
A solução da Databricks
O Databricks está implementando recursos que simplificam e expandem as capacidades existentes para trabalhar com LLMs na plataforma lakehouse. Isso inclui:
- Padrões simplificados para usar LLMs pré-treinados do Hugging Face para tarefas de inferência em pipelines de dados ou fazer o ajuste fino deles para obter um melhor desempenho em seus próprios dados no Databricks.
- Simplificando o processo e melhorando o desempenho do carregamento de dados do Apache Spark para o Hugging Face para trabalhos de treinamento ou ajuste fino de modelos.
- Aceleradores de soluções de LLM específicos do setor, mostrando padrões de implementação repetíveis para ganhos rápidos, como analítica de atendimento ao cliente e descoberta de produtos
- O lançamento do MLflow 2.3, com suporte nativo para LLMs, em particular:
- Três novos tipos de modelo: Hugging Face Transformers, funções da OpenAI e LangChain.
- Melhora significativa na velocidade de download e upload de modelos de e para serviços de cloud por meio de download e upload multipartes para arquivos de modelo.
- Uma função integrada do Databricks SQL que permite aos usuários acessar LLMs diretamente do SQL. Este recurso pode contornar os longos e complexos processos de desenvolvimento de modelos de linguagem, permitindo que analistas simplesmente elaborem prompts de LLM eficazes.
- Conforme anunciado no Data & AI Summit 2023,
- Adições ao serviço AutoML da Databricks baseado em UI, que farão o ajuste fino de LLMs para classificação de texto, bem como de modelos de embedding; e
- Modelos com curadoria, apoiados por Model Serving otimizado para alto desempenho. Em vez de gastar tempo pesquisando os melhores modelos de AI generativa de código aberto para o seu caso de uso, você pode contar com modelos com curadoria de especialistas da Databricks para casos de uso comuns.
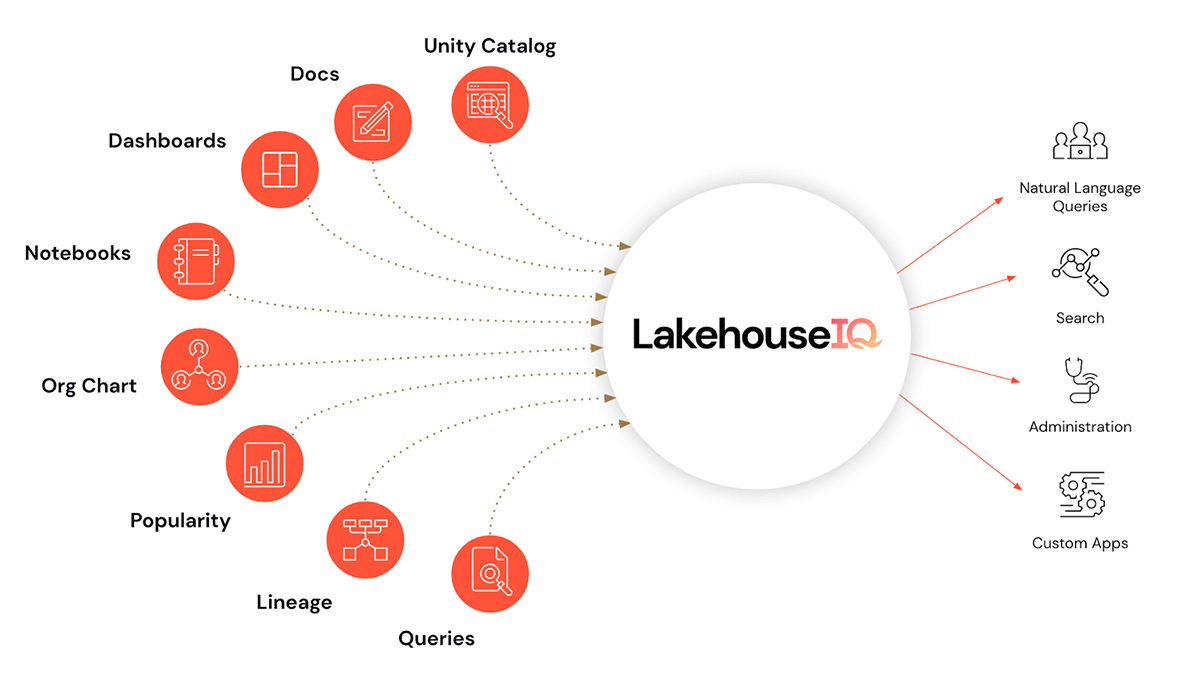
- E, talvez, a cereja do bolo, LakehouseIQ, um mecanismo de conhecimento que aprende as nuances exclusivas do seu negócio e dos seus dados para viabilizar o acesso em linguagem natural a eles para uma ampla variedade de casos de uso.
Além de facilitar o uso de LLMs no Databricks, também estamos introduzindo programas de treinamento e capacitação em LLMs para ajudar as organizações a ampliar sua proficiência em LLMs. Eles são apresentados em um nível acessível para os usuários do setor público da Databricks.
- Parceria com a EdX para oferecer cursos on-line ministrados por especialistas com foco específico na criação e uso de modelos de linguagem em aplicações modernas
Conclusões e os próximos passos
Existem inúmeras oportunidades para aproveitar os LLMs para acelerar os casos de uso do Setor Público. Um valor imenso permanece oculto em dados legados, apenas esperando para ser descoberto e aplicado aos problemas atuais. Venha saber mais sobre como o Databricks pode ajudar você a adotar LLMs em sua missão participando do nosso webinar Grandes modelos de linguagem no setor público em 2 de agosto, ao meio-dia (EDT). Além disso, consulte as inscrições para a prévia dos recursos listadas no anúncio do Lakehouse AI e veja para quais sua organização se qualifica.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.