Obtendo uma visão completa: unificando os custos do Databricks e da infraestrutura de cloud
Aprenda a automatizar dashboards de custos unificados que as equipes de FinOps e Plataforma realmente queiram usar.
- A nova Cloud Infra Cost Field Solution (disponível para AWS e Azure) demonstra como ingerir, enriquecer, join e view dados de custo do Databricks e da nuvem relacionada para view os custos totais no nível da account, do cluster e até mesmo da tag.
- A implementação da Field Solution fornece às equipes de FinOps e de plataforma uma única e confiável view do TCO, permitindo que eles detalhem os custos totais por workspace, carga de trabalho e unidade de negócios para alinhar o uso com os orçamentos, eliminando a reconciliação manual e transformando os relatórios de custos em um recurso operacional sempre ativo.
- Empresas como a General Motors adotaram essa abordagem para desenvolver uma compreensão holística de seus custos do Databricks, garantindo que sejam visíveis e bem compreendidos.
Entendendo o TCO no Databricks
Compreender o valor dos seus investimentos em IA e dados é crucial — no entanto, mais de 52% das empresas não conseguem medir rigorosamente o Retorno sobre o Investimento (ROI) [Futurum]. A visibilidade completa do ROI exige a conexão do uso da plataforma e da infraestrutura de nuvem em um panorama financeiro claro. Muitas vezes, os dados estão disponíveis, mas fragmentados, pois as plataformas de dados atuais precisam ser compatíveis com uma variedade crescente de arquiteturas de armazenamento e computação.
No Databricks, os clientes gerenciam ambientes multicloud, com múltiplas cargas de trabalho e múltiplas equipes. Nesses ambientes, ter uma visão consistente e abrangente dos custos é essencial para tomar decisões informadas.
A base da visibilidade de custos em plataformas como o Databricks é o conceito de Custo Total de Propriedade (TCO).
Em plataformas de dados multicloud, como o Databricks, o Custo Total de Propriedade (TCO) consiste em dois componentes principais:
- Custos da plataforma, como compute e armazenamento gerenciado, são custos incorridos pelo uso direto dos produtos da Databricks.
- Custos de infraestrutura de cloud, como máquinas virtuais, armazenamento e taxas de rede, são custos incorridos pelo uso subjacente dos serviços de cloud necessários para dar suporte ao Databricks.
Entender o TCO é simplificado ao usar produtos serverless. Como a compute é gerenciada pelo Databricks, os custos de infraestrutura de cloud são incluídos nos custos do Databricks, proporcionando a você visibilidade de custos centralizada diretamente nas tabelas de sistema do Databricks (embora os custos de armazenamento continuem com o provedor de cloud).
Entender o TCO para produtos de computação clássicos, no entanto, é mais complexo. Aqui, os clientes gerenciam o compute diretamente com o provedor de cloud, o que significa que tanto os custos da plataforma Databricks quanto os custos de infraestrutura de cloud precisam ser reconciliados. Nesses casos, existem duas fontes de dados distintas a serem resolvidas:
- As tabelas do sistema (AWS | AZURE | GCP) no Databricks fornecerão metadados operacionais no nível da carga de trabalho e o uso do Databricks.
- Os relatórios de custos do provedor de nuvem detalham os custos da infraestrutura de nuvem, incluindo descontos.
Juntas, essas fontes formam a visão completa do TCO. À medida que seu ambiente cresce em vários clusters, jobs e contas de nuvem, entender esses conjuntos de dados se torna uma parte fundamental da observabilidade de custos e da governança financeira.
A complexidade do TCO
A complexidade de medir o TCO do Databricks é agravada pelas maneiras distintas como os provedores de nuvem expõem e relatam dados de custo. Entender como unir esses conjuntos de dados com tabelas do sistema para produzir KPIs de custo precisos exige um conhecimento profundo da mecânica de faturamento da nuvem – conhecimento que muitos administradores de plataforma focados em Databricks podem não ter. Aqui, aprofundamos a medição do seu TCO para o Azure Databricks e o Databricks na AWS.
Azure Databricks: aproveitando os dados de faturamento primários
Como o Azure Databricks é um serviço primário no ecossistema do Microsoft Azure, as cobranças relacionadas ao Databricks aparecem diretamente no Azure Cost Management junto com outros serviços do Azure, incluindo até mesmo tags específicas do Databricks. Os custos do Databricks aparecem na UI de análise de custos do Azure e como dados de gerenciamento de custos.
No entanto, os dados do Azure Cost Management não conterão os metadados mais detalhados em nível de carga de trabalho e as métricas de desempenho encontradas nas tabelas do sistema Databricks. Assim, muitas organizações procuram trazer as exportações de faturamento do Azure para o Databricks.
No entanto, join totalmente essas duas fontes de dados consome muito tempo e exige profundo conhecimento de domínio — um esforço que a maioria dos clientes simplesmente não tem tempo para definir, manter e replicar. Vários desafios contribuem para isso:
- A infraestrutura deve ser configurada para exportações automatizadas de custos para o ADLS, que podem então ser referenciados e consultados diretamente no Databricks.
- Os dados de custo do Azure são agregados e atualizados diariamente, ao contrário das tabelas do sistema, que são atualizadas na ordem de horas – os dados devem ser cuidadosamente desduplicados e os timestamps, correspondidos.
- A join das duas fontes requer a análise de dados de tags do Azure de alta cardinalidade e a identificação da key de join correta (por exemplo, ClusterId).
Databricks on AWS: alinhando custos de marketplace e infraestrutura
Na AWS, embora os custos do Databricks apareçam no Relatório de Custo e Uso (CUR) e no AWS Cost Explorer, os custos são representados em um nível mais agregado, de SKU, diferentemente do Azure. Além disso, os custos do Databricks aparecem no CUR apenas quando o Databricks é comprado pelo AWS Marketplace; caso contrário, o CUR refletirá apenas os custos de infraestrutura da AWS.
Nesse caso, entender como coanalisar o AWS CUR junto com as tabelas do sistema é ainda mais essencial para clientes com ambientes AWS. Isso permite que as equipes analisem gastos com infraestrutura, uso de DBU e descontos juntamente com o contexto no nível de cluster e de carga de trabalho, criando uma visão mais completa do TCO entre contas e regiões da AWS.
No entanto, unir o AWS CUR com as tabelas do sistema também pode ser desafiador. Os pontos problemáticos comuns incluem:
- A infraestrutura deve ser compatível com o reprocessamento recorrente de CUR, pois a AWS atualiza (refresh) e substitui os dados de custo várias vezes por dia (sem chave primária) para o mês atual e qualquer período de faturamento anterior com alterações.
- Os dados de custo da AWS abrangem vários tipos de itens de linha e campos de custo, exigindo atenção para selecionar o custo efetivo correto por tipo de uso (On-Demand, Planos de Economia, Instâncias Reservadas) antes da agregação.
- A junção do CUR com os metadados do Databricks exige uma atribuição cuidadosa, pois a cardinalidade pode ser diferente, por exemplo, clusters todo-propósito são representados como uma única linha de uso da AWS, mas podem ser mapeados para vários trabalhos (jobs) em tabelas do sistema.
Simplificando os cálculos de TCO do Databricks
Em ambientes Databricks em escala de produção, as perguntas sobre custos rapidamente vão além dos gastos gerais. As equipes querem entender o custo no contexto: como o uso da infraestrutura e da plataforma se conecta a cargas de trabalho e decisões reais. As perguntas comuns incluem:
- Como o custo total de um job serverless se compara a um job clássico?
- Quais clusters, jobs e warehouses são os maiores consumidores de VMs gerenciadas pela cloud?
- Como as tendências de custo mudam à medida que as cargas de trabalho são escaladas, alteradas ou consolidadas?
Responder a essas perguntas exige reunir dados financeiros de provedores de clouds com metadados operacionais do Databricks. No entanto, conforme descrito acima, as equipes precisam manter pipelines personalizados e uma base de conhecimento detalhada sobre o faturamento da cloud e do Databricks para realizar isso.
Para atender a essa necessidade, o Databricks está apresentando a Cloud Infra Cost Field Solution, uma solução de código aberto que automatiza a ingestão e a análise unificada dos dados de infraestrutura de nuvem e de uso do Databricks, dentro da Databricks Platform.
Ao fornecer uma base unificada para a análise de TCO nos ambientes de computação serverless e clássicos do Databricks, a Field Solution ajuda as organizações a obter uma visibilidade mais clara dos custos e a entender as vantagens e desvantagens da arquitetura. As equipes de engenharia podem acompanhar os gastos e descontos na cloud, enquanto as equipes financeiras podem identificar o contexto de negócios e a propriedade dos principais fatores de custo.
Na próxima seção, vamos explicar como a solução funciona e como começar.
Análise da solução técnica
Embora os componentes possam ter nomes diferentes, a Cloud Infra Cost Field Solution para clientes do Azure e da AWS compartilha os mesmos princípios e pode ser dividida nos seguintes componentes:
- Exportar dados de custo e uso para o armazenamento em nuvem
- Ingerir e modelar dados no Databricks usando Lakeflow Spark Declarative Pipelines
- Visualize o TCO completo (custos do Databricks e do provedor de nuvem relacionado) com painéis de AI/BI
Tanto as Field soluções da AWS quanto as do Azure são excelentes para organizações que operam em uma única cloud, mas também podem ser combinadas para clientes Databricks multicloud usando o Delta Sharing.
Solução de Campo do Azure Databricks
A cloud Infra Cost Field Solution para o Azure Databricks consiste nos seguintes componentes de arquitetura:
Arquitetura de Solução do Azure Databricks
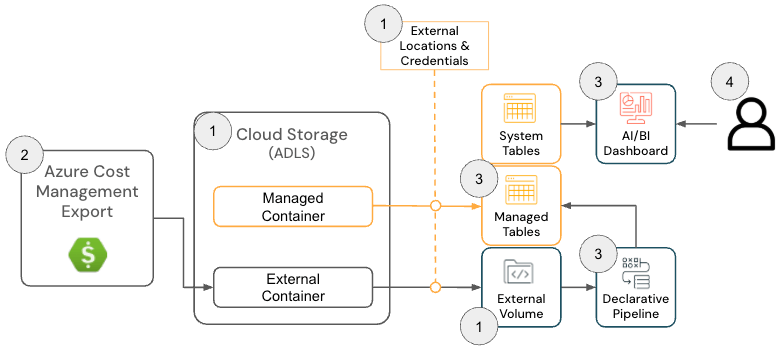
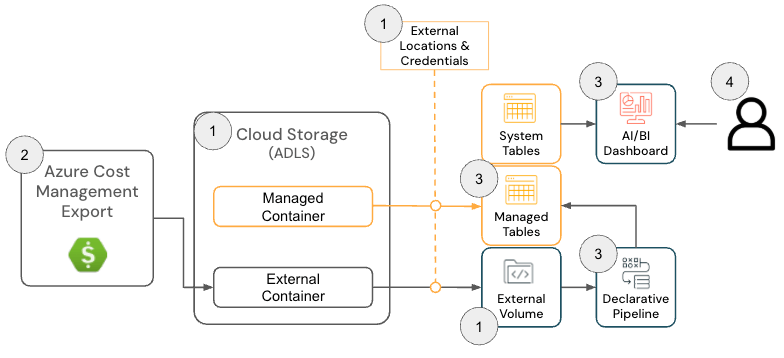{kind=link}
Para implantar esta solução, os administradores devem ter as seguintes permissões no Azure e no Databricks:
- Azure
- Permissões para criar uma Azure Cost Export
- Permissões para criar os seguintes recursos em um Grupo de Recursos:
- Databricks
- Permissão para criar os seguintes recursos:
- Credencial de armazenamento
- Localização externa
- Permissão para criar os seguintes recursos:
O repositório do GitHub fornece instruções de configuração mais detalhadas; no entanto, em alto nível, a solução para o Azure Databricks tem as seguintes etapas:
- [Terraform] Implante o Terraform para configurar os componentes dependentes, incluindo uma Conta de Armazenamento, um Local Externo e um Volume
- O objetivo d'o passo é configurar um local para onde os dados de faturamento do Azure são exportados para que possam ser lidos pelo Databricks. Este passo é opcional se houver um Volume preexistente, pois o local de exportação do Azure Cost Management pode ser configurado no próximo passo.
[Azure] Configure o Azure Cost Management Export para exportar os dados de Faturamento do Azure para a Conta de Armazenamento e confirme que os dados estão sendo exportados com sucesso
- O objetivo d'o passo é usar a funcionalidade de Exportação do Gerenciamento de Custos do Azure para disponibilizar os dados de Faturamento do Azure em um formato fácil de consumir (por exemplo, Parquet).
account de Armazenamento com o Azure Cost Management Export configurado
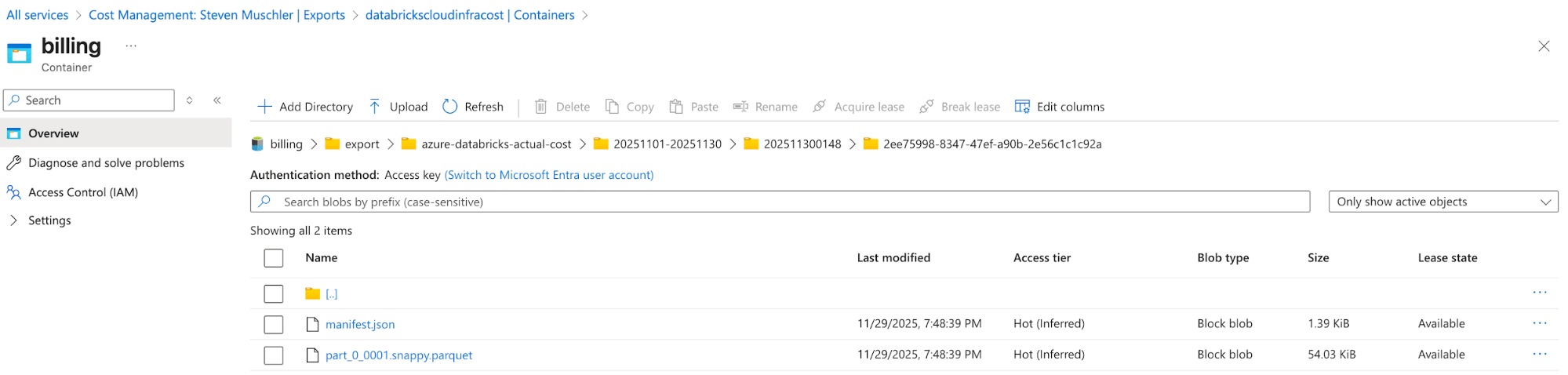
Azure Cost Management Export automatically delivers cost files to this location - [Databricks] Configuração do Databricks Ativo Bundle (DAB) para implantar um Lakeflow Job, um Spark Declarative pipeline e um AI/BI Dashboard
- O objetivo desta etapa é ingerir e modelar os dados de faturamento do Azure para visualização usando um AI/BI dashboard.
- [Databricks] Validar dados no dashboard de AI/BI e validar o Lakeflow Job
- Este passo final é onde o valor se concretiza. Os clientes agora têm um processo automatizado que lhes permite visualizar o TCO de sua arquitetura Lakehouse!
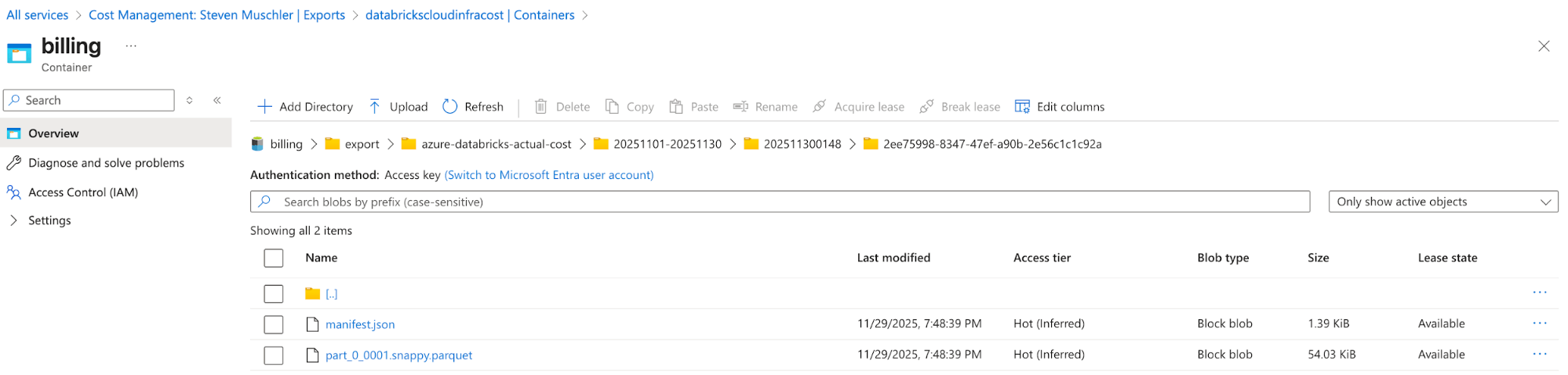{kind=link}
Painel de AI/BI exibindo o TCO do Azure Databricks
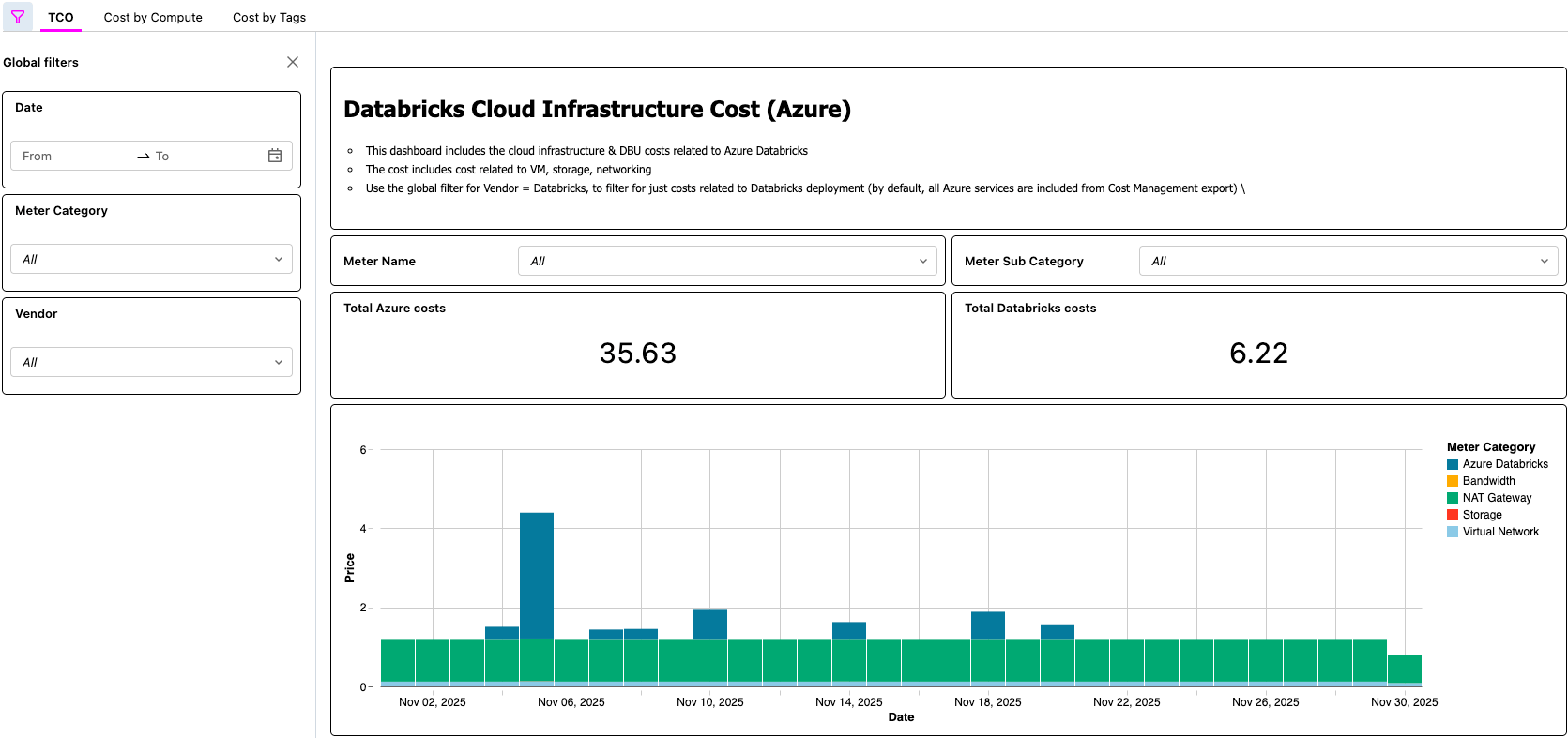
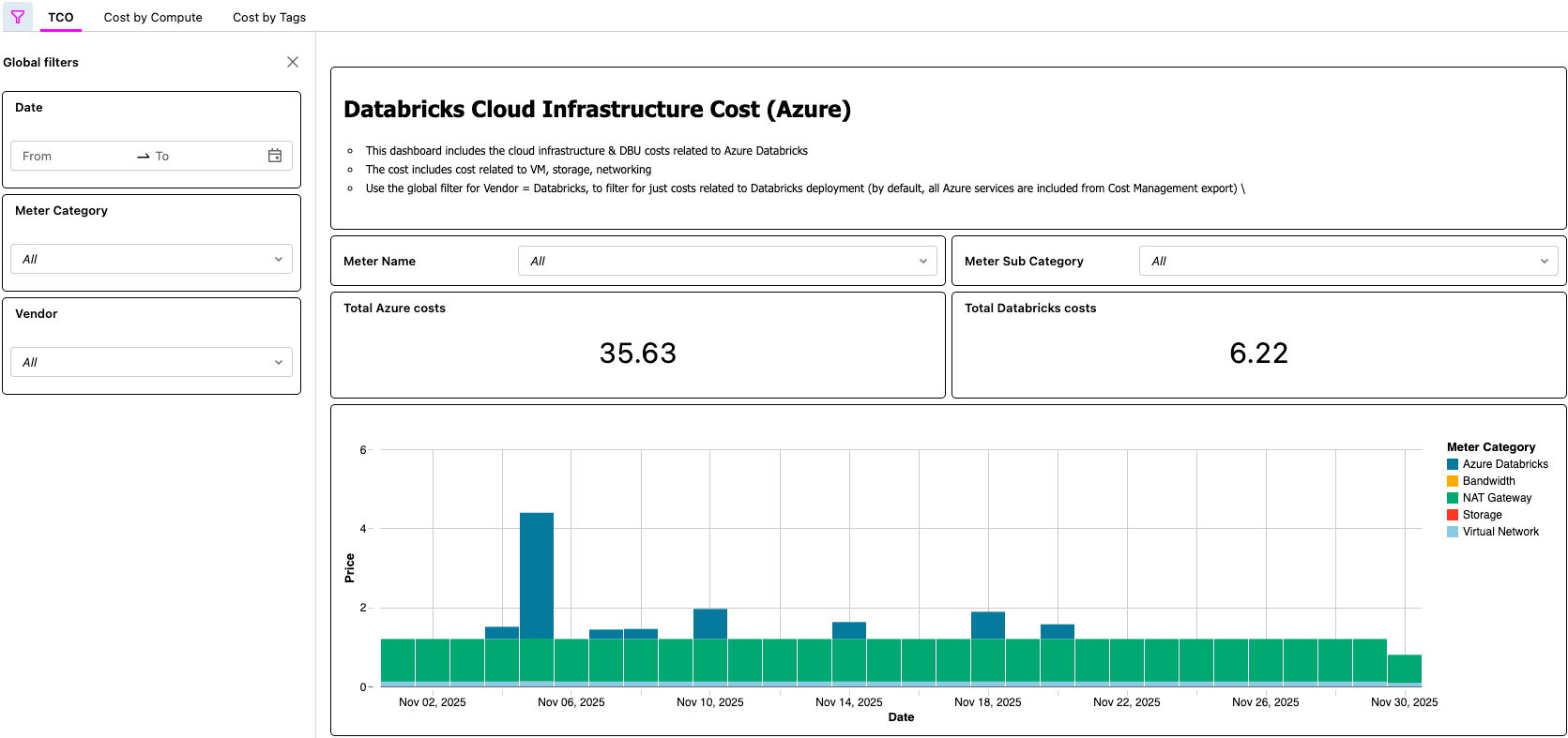{kind=link}
Solução Databricks na AWS
A solução para Databricks on AWS consiste em vários componentes de arquitetura que trabalham juntos para ingerir os dados do Relatório de Custos e Uso (CUR) 2.0 da AWS e persisti-los no Databricks usando a arquitetura medalhão.
Para implantar esta solução, as seguintes permissões e configurações devem estar em vigor na AWS e no Databricks:
- AWS
- Permissões para criar um CUR
- Permissões para criar um bucket do Amazon S3 (ou permissões para implantar o CUR em um bucket atual)
- Observação: a solução requer o AWS CUR 2.0. Se você ainda tiver uma exportação do CUR 1.0, a documentação da AWS fornece os passos necessários para fazer o upgrade.
- Databricks
- Permissão para criar os seguintes recursos:
- Credencial de armazenamento
- Localização externa
- Permissão para criar os seguintes recursos:
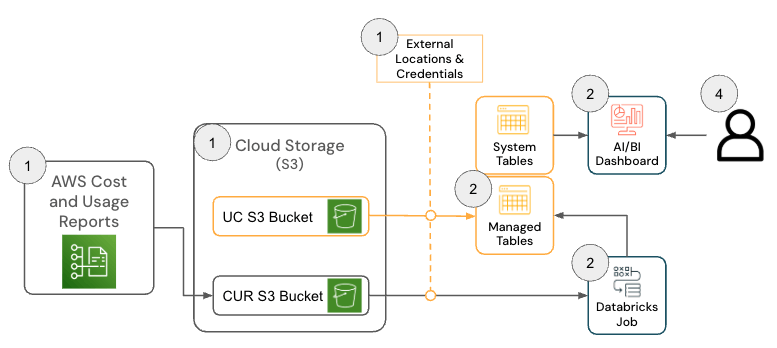
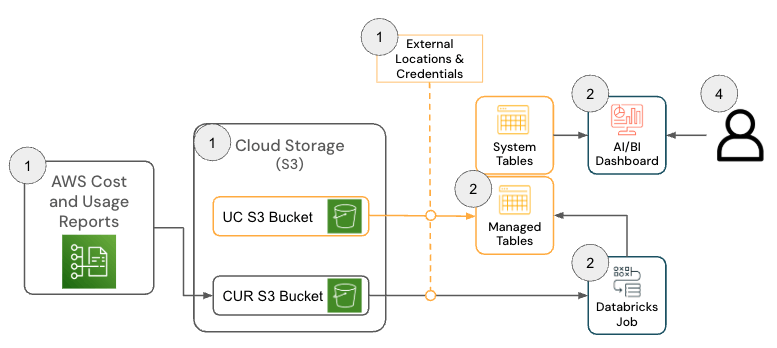{kind=link}
O repositório do GitHub fornece instruções de configuração mais detalhadas; no entanto, em alto nível, a solução para o AWS Databricks tem as seguintes etapas.
- [AWS] Configuração do AWS Cost & Usage Report (CUR) 2.0
- O objetivo d'o passo é aproveitar a funcionalidade do AWS CUR para que os dados de faturamento da AWS estejam disponíveis em um formato fácil de consumir.
- [Databricks] Configuração do Databricks Pacote de Ativos (DAB)
- O objetivo desta etapa é ingerir e modelar os dados de faturamento da AWS para que possam ser visualizados usando um AI/BI dashboard.
- [Databricks] Revise o Dashboard e valide o Lakeflow Job
- Este passo final é onde o valor é concretizado. Os clientes agora têm um processo automatizado que disponibiliza para eles o TCO da arquitetura de lakehouse!
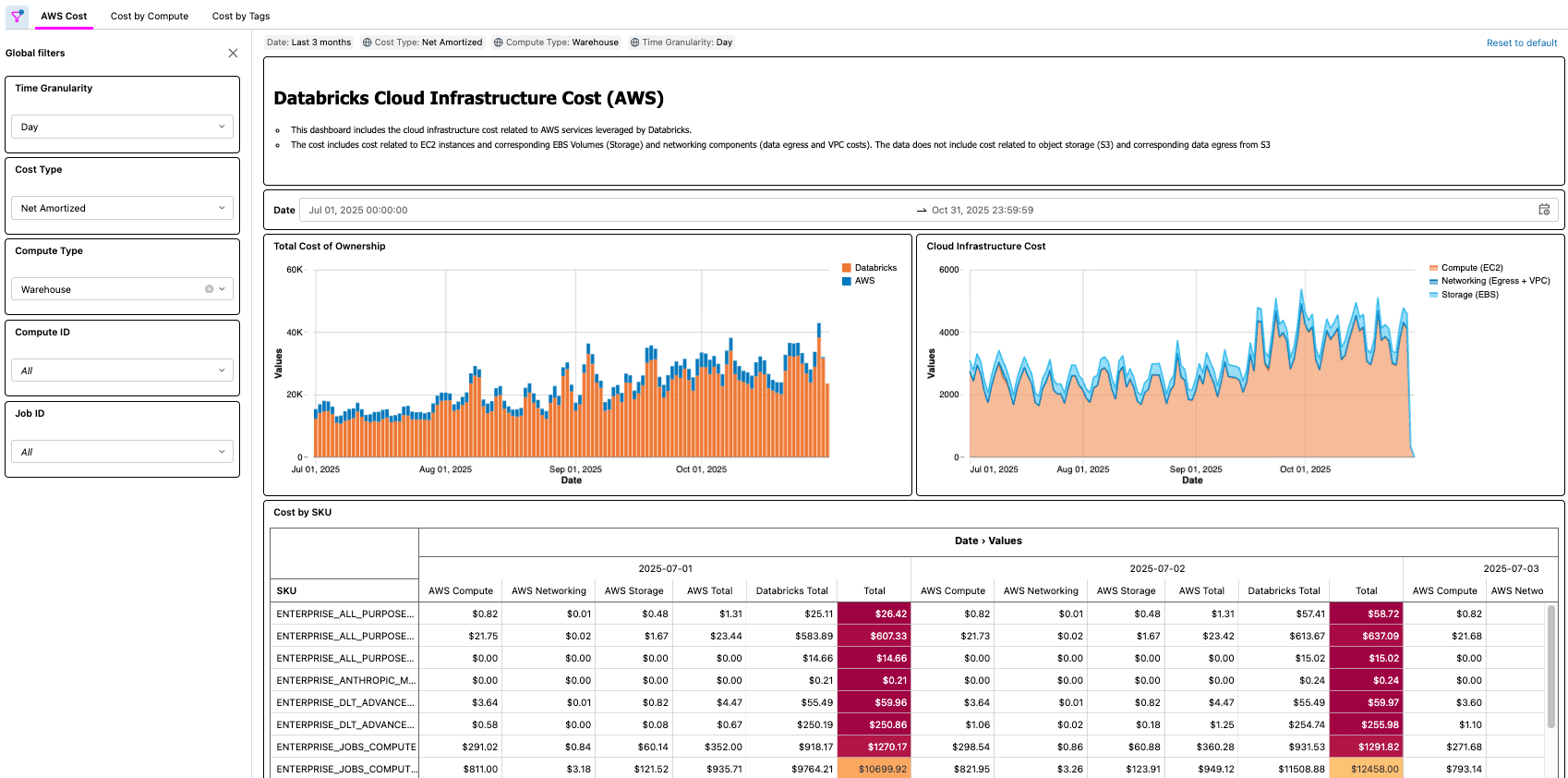
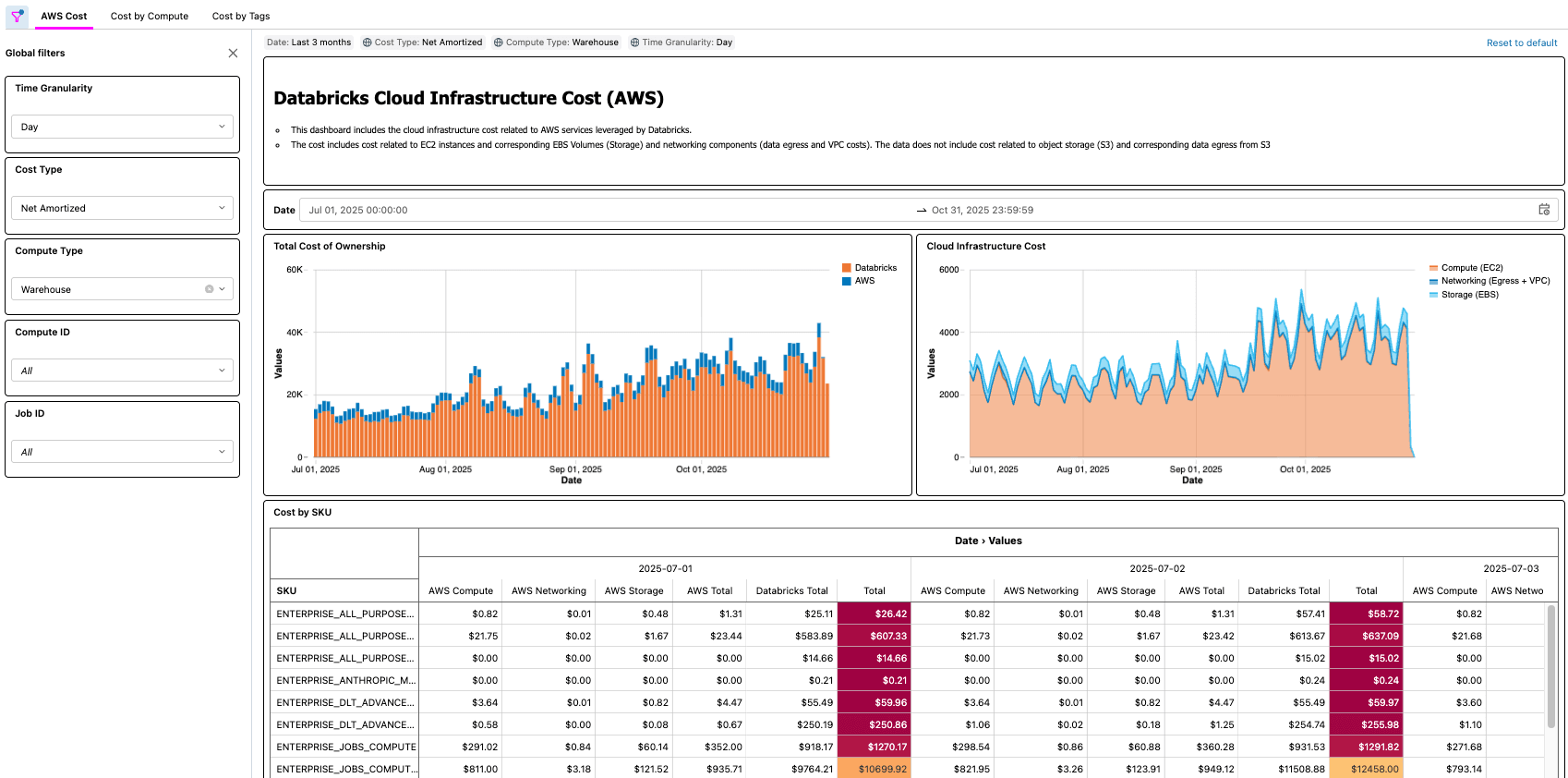{kind=link}
Cenários do mundo real
Conforme demonstrado com as soluções do Azure e da AWS, há muitos exemplos do mundo real que uma solução como essa possibilita, tais como:
- Identificar e calcular a economia total de custos após otimizar um job com baixa utilização de CPU e/ou memória
- Identificar workloads em execução em tipos de VM que não têm uma reserva
- Identificar cargas de trabalho com custos de rede e/ou armazenamento local anormalmente altos
Como exemplo prático, um profissional de FinOps em uma grande organização com milhares de cargas de trabalho pode ter a tarefa de encontrar otimizações fáceis, procurando por cargas de trabalho que custam um determinado valor, mas que também têm baixo uso de CPU e/ou memória. Como as informações de TCO da organização agora são exibidas pela Cloud Infra Cost Field Solution, o profissional pode então join esses dados à Node Timeline System Table (AWS, AZURE, GCP) para exibir essas informações e quantificar com precisão a economia de custos quando as otimizações forem concluídas. As perguntas que mais importam dependerão das necessidades de negócios de cada cliente. Por exemplo, a General Motors usa esse tipo de solução para responder a muitas das perguntas acima e outras para garantir que estão obtendo o máximo valor de sua arquitetura de lakehouse.
Principais pontos
Após implementar a Cloud Infra Cost Field Solution, as organizações obtêm uma única e confiável TCO view que combina os gastos com Databricks e com a cloud infrastructure relacionada, eliminando a necessidade de reconciliação manual de custos entre plataformas. Exemplos de perguntas que você pode responder usando a solução incluem:
- Qual é o detalhamento de custos do meu uso do Databricks no provedor de cloud e no Databricks?
- Qual é o custo total de execução de uma carga de trabalho, incluindo custos de VM, armazenamento local e rede?
- Qual é a diferença no custo total de um workload quando ele é executado em serverless em comparação com a execução em classic compute
As equipes de Plataforma e FinOps podem detalhar os custos totais por workspace, carga de trabalho e unidade de negócios diretamente no Databricks, tornando muito mais fácil alinhar o uso com orçamentos, modelos de responsabilidade e práticas de FinOps. Como todos os dados subjacentes estão disponíveis como tabelas governadas, as equipes podem criar seus próprios aplicativos de custo — dashboards, aplicativos internos ou usar assistentes de IA integrados como o Databricks Genie— acelerando a geração de percepções e transformando o FinOps de um exercício de relatórios periódicos em uma capacidade operacional sempre ativa.
Próximas os passos & recurso
Implante a Cloud Infra Cost Field Solution hoje mesmo no GitHub (link aqui, disponível na AWS e no Azure) e obtenha visibilidade total dos seus gastos totais com o Databricks. Com a visibilidade total implementada, você pode otimizar seus custos do Databricks, incluindo a consideração do serverless para o gerenciamento automatizado da infraestrutura.
O dashboard e o pipeline criados como parte desta solução oferecem uma maneira rápida e eficaz de começar a analisar os gastos do Databricks juntamente com o restante dos seus custos de infraestrutura. No entanto, cada organização aloca e interpreta as cobranças de maneira diferente, portanto, você pode optar por personalizar ainda mais os modelos e as transformações de acordo com suas necessidades. As extensões comuns incluem unir dados de custo de infraestrutura com Tabelas do Sistema do Databricks adicionais (AWS | AZURE | GCP) para melhorar a precisão da atribuição, criar uma lógica para separar ou realocar custos de VM compartilhada ao usar pools de instâncias, modelar as reservas de VM de forma diferente ou incorporar preenchimentos retroativos históricos para dar suporte a tendências de custo de longo prazo. Assim como em qualquer modelo de custo de hiperescala, há espaço substancial para personalizar os pipelines além da implementação default para se alinhar aos relatórios internos, às estratégias de tags e aos requisitos de FinOps.
Os Arquitetos de Soluções de Entrega (DSAs) do Databricks aceleram as iniciativas de dados e IA nas organizações. Eles fornecem liderança de arquitetura, otimizam plataformas para custo e desempenho, melhoram a experiência do desenvolvedor e impulsionam a execução bem-sucedida de projetos. Os DSAs preenchem a lacuna entre a implantação inicial e as soluções de nível de produção, trabalhando em estreita colaboração com várias equipes, incluindo engenharia de dados, líderes técnicos, executivos e outras partes interessadas para garantir soluções personalizadas e um tempo de retorno mais rápido. Para se beneficiar de um plano de execução personalizado, orientação estratégica e suporte durante sua jornada de dados e IA com um DSA, entre em contato com sua equipe de account da Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.