LogSentinel: como o Databricks usa o Databricks para detecção e governança de PII com LLMs
Uma análise aprofundada do LogSentinel: como usamos LLMs internamente para automatizar a descoberta e a governança de PII
- Usamos LLMs no Databricks para detectar e classificar automaticamente dados confidenciais em logs e bancos de dados.
- Nosso sistema LogSentinel aplica classificação hierárquica, ciente de residência e de vários modelos para rotulagem precisa – técnicas que estão sendo integradas diretamente no produto Data Classification.
- Ao pré-rotular colunas e detectar continuamente o desvio de rotulagem, o LogSentinel permite a detecção confiável de PII, a aplicação automatizada de políticas e fluxos de trabalho de compliance muito mais rápidos em escala.
A Databricks opera em uma escala em que nossos logs e conjuntos de dados internos estão em constante mudança — os esquemas evoluem, novas colunas aparecem e a semântica dos dados drift. Neste blog, discutimos como nós, no Databricks, usamos o Databricks internamente para manter PII e outros dados confidenciais rotulados corretamente à medida que nossa plataforma muda.
Para fazer isso, criamos o LogSentinel, um sistema de classificação de dados baseado em LLM no Databricks que rastreia a evolução do esquema, detecta o desvio de rotulagem e alimenta nossos controles de governança e segurança com rótulos de alta qualidade. Usamos o MLflow para acompanhar experimentos e monitorar o desempenho ao longo do tempo, e estamos integrando as melhores ideias do LogSentinel de volta ao produto Databricks Data Classification para que os clientes possam se beneficiar da mesma abordagem.
Por que este sistema é importante
Este sistema foi projetado para impulsionar três alavancas de negócios concretas para equipes de plataforma, dados e segurança:
- Ciclos de compliance mais curtos: tarefas de revisão recorrentes que antes levavam semanas do tempo dos analistas agora são concluídas em horas, porque as colunas são pré-rotuladas e pré-triadas antes de serem inspecionadas por humanos.
- Menor risco operacional: o sistema detecta continuamente desvios de rotulagem e alterações de esquema, de modo que campos confidenciais têm menos probabilidade de passar despercebidos com tags incorretas ou ausentes.
- Aplicação mais rigorosa de políticas: rótulos confiáveis agora orientam diretamente o mascaramento, o controle de acesso, a retenção e as regras de residência, transformando o que costumava ser uma "governança de melhor esforço" em uma política executável.
Na prática, as equipes podem conectar novas tabelas a um pipeline padrão, monitorar métricas de desvio e exceções e contar com o sistema para aplicar restrições de PII e residência sem criar um classificador personalizado para cada domínio.
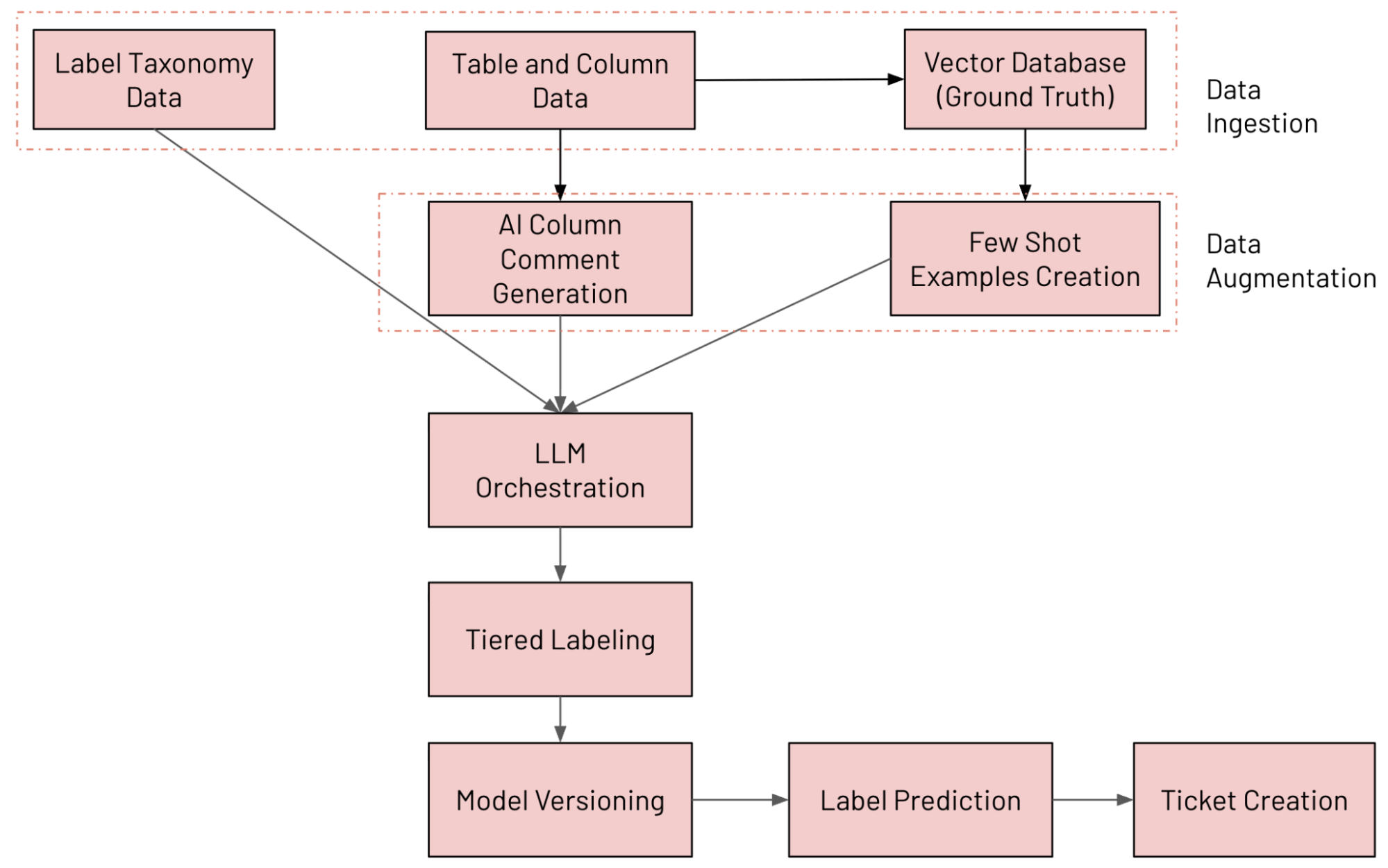
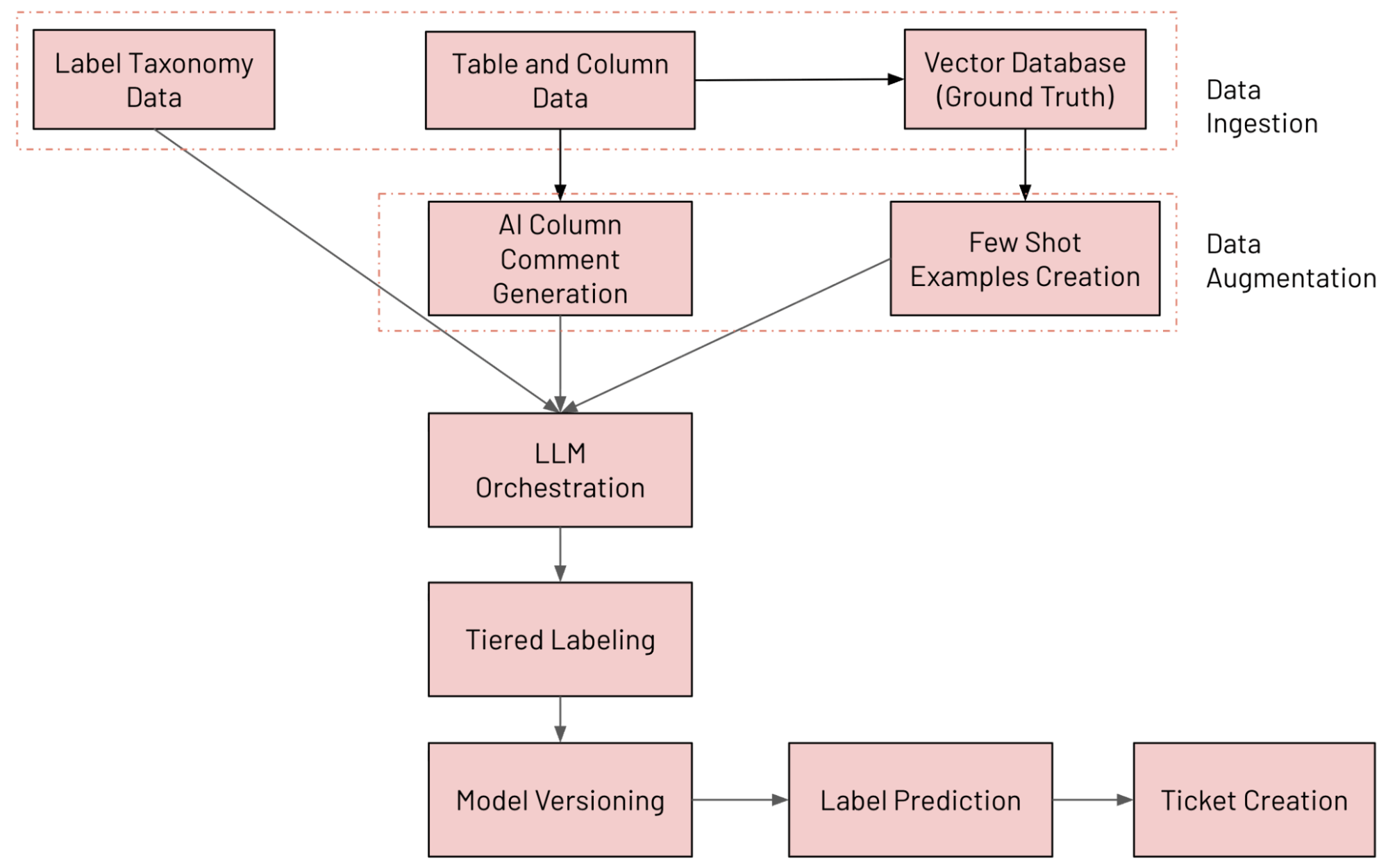
Visão geral da arquitetura do sistema
Desenvolvemos um sistema de classificação de colunas baseado em LLM no Databricks que anota tabelas continuamente usando nossa taxonomia de dados interna, detecta drift de rotulagem e abre tíquetes de remediação quando algo parece errado. Os vários componentes envolvidos no sistema são descritos abaixo (rastreados e avaliados usando o MLFlow):
- Ingestão de dados: ingestão de várias fontes de dados (incluindo dados de coluna do Unity Catalog, dados de taxonomia de rótulos e dados de ground truth)
- Aumento de dados: Aumentando dados com o Databricks AI Search e a geração de comentários por IA
- Orquestração de LLM
- Sistema de Rotulagem em Camadas
- Versionamento de modelo: executando vários modelos em paralelo
- Previsão de Rótulo: Previsão do rótulo final usando a abordagem de Mistura de Especialistas (MoE)
- Criação de tíquetes: detectando violações e gerando tíquetes do JIRA
O fluxo de trabalho de ponta a ponta é mostrado na figura abaixo
{kind=link}
Ingestão de dados
Para cada tipo de log ou dataset a ser anotado, amostramos aleatoriamente valores de cada coluna e enviamos os seguintes metadados para o sistema: nome da tabela, nome da coluna, tipo, comentário existente e uma pequena amostra de valores. Para reduzir o custo do LLM e melhorar a throughput, várias colunas da mesma tabela são agrupadas em lotes em uma única solicitação.
Nossa taxonomia é definida usando Protocol Buffers e atualmente inclui mais de 100 rótulos de dados hierárquicos, com espaço para extensões personalizadas quando as equipes precisam de categorias adicionais. Isso dá aos stakeholders de governança e da plataforma um contrato compartilhado sobre o que “PII” e “sensível” significam, além de um punhado de regexes.
Aumento de dados
Duas estratégias de aumento melhoram significativamente a qualidade da classificação:
- Geração de comentários de coluna por IA: quando os comentários estão ausentes, usamos comentários gerados pela IA do Databricks para sintetizar descrições concisas e legíveis por humanos que ajudam tanto o LLM quanto os futuros consumidores da tabela.
- Geração de exemplos few-shot: mantemos um dataset de referência e usamos exemplos estáticos e dinâmicos recuperados via AI Search; para cada coluna, criamos uma incorporação a partir do nome, tipo, comentário e contexto e, em seguida, recuperamos as K colunas rotuladas mais semelhantes para incluir no prompt.
O prompting estático é melhor durante os estágios iniciais ou quando os dados rotulados são limitados, proporcionando consistência e reprodutibilidade. O prompting dinâmico é mais eficaz em sistemas maduros, usando a busca vetorial para extrair exemplos semelhantes e se adaptar a novos esquemas e domínios de dados em datasets grandes e diversos.
Orquestração de LLM
No núcleo do sistema, há uma camada de orquestração leve que gerencia chamadas de LLM em escala de produção.
Os principais recursos incluem:
- Roteamento multimodelo em LLMs hospedados internamente (por exemplo, modelos baseados em Llama, Claude e GPT) com fallback automático quando um modelo não está disponível.
- Lógica de nova tentativa para falhas transitórias e limites de taxa com recuo exponencial.
- Hooks de validação que detectam rótulos vazios, inválidos ou alucinados e reexecutam esses casos com modelos de backup.
- Processamento em lote que anota várias colunas de uma vez para otimizar o uso de tokens sem perder o contexto.
Sistema de Rotulagem em Camadas
Prevemos três tipos de rótulos por coluna:
- Rótulos granulares, extraídos de um conjunto de mais de 100 opções refinadas que potencializam o mascaramento, a redação e controles de acesso rigorosos.
- Rótulos hierárquicos, que agregam rótulos granulares relacionados em categorias mais amplas, adequadas para monitoramento e relatórios.
- Rótulos de residência, que indicam se os dados devem permanecer na região ou podem ser movidos entre regiões, alimentando diretamente as políticas de movimentação de dados.
Para manter as predições consistentes e reduzir as alucinações, usamos um fluxo de dois estágios: um passo de classificação ampla atribui uma categoria de alto nível, e depois um passo de refinamento escolhe o rótulo exato dentro dessa categoria. Isso espelha como um revisor humano primeiro decidiria “estes são dados do workspace” e depois escolheria o rótulo de identificador de workspace específico.
Versionamento de Modelos e Previsão de Rótulo
Em vez de depender de uma única configuração 'ideal', cada configuração de modelo é tratada como um especialista que compete para rotular uma coluna.
Várias versões de modelo rodam em paralelo com diferenças em:
- Opções de LLM principal e de fallback.
- Uso de comentários gerados vs. metadados brutos.
- Estratégia de prompting (estático vs. dinâmico few-shot).
- Granularidade de rótulos e subconjuntos de taxonomia.
Cada especialista produz um rótulo e uma pontuação de confiança entre 0 e 100. O sistema então seleciona o rótulo do especialista com a maior confiança, uma abordagem no estilo Mixture-of-Experts que melhora a precisão e reduz o impacto de predições ruins ocasionais de qualquer configuração individual.
Este design torna a experimentação segura: novos modelos ou estratégias de prompt podem ser introduzidos, executados junto com os existentes e avaliados com base em métricas e no volume de tickets downstream antes de se tornarem o default.
Criação de tíquetes
O pipeline compara continuamente as anotações de esquema atuais com as previsões do LLM para revelar desvios significativos.
Casos típicos incluem:
- Novas colunas adicionadas sem nenhuma anotação.
- Anotações existentes que não correspondem mais ao conteúdo da coluna.
- Colunas que contêm valores confidenciais rotulados como qualificados para movimentação entre regiões.
Quando o sistema detecta uma violação, ele cria uma entrada de política e abre um ticket no JIRA para a equipe proprietária com contexto sobre a tabela, a coluna, o rótulo proposto e a confiança. Isso transforma os problemas de classificação de dados em um fluxo de trabalho contínuo que as equipes podem acompanhar e resolver da mesma forma que acompanham outros incidentes de produção.
Impacto e Avaliação
O sistema foi avaliado em 2.258 amostras rotuladas, das quais 1.010 continham PII e 1.248 não eram PII. Neste dataset, alcançou até 92% de precisão e 95% de recall para detecção de PII.
Mais importante para as partes interessadas, a implantação produziu os resultados operacionais necessários:
- O esforço de revisão manual caiu de semanas para horas para cada ciclo de auditoria em grande escala, porque os revisores começam com rótulos sugeridos de alta qualidade em vez de esquemas brutos.
- A rotulagem drift agora é detectada continuamente à medida que os esquemas evoluem, em vez de ser descoberta durante uma revisão anual.
- Os alertas sobre dados sensíveis rotulados incorretamente como seguros são mais direcionados, para que as equipes de segurança possam agir rapidamente em vez de fazer a triagem de scanners ruidosos baseados em regras.
- As políticas de mascaramento e residência são aplicadas em escala usando a mesma taxonomia de rótulos que alimenta a analítica e os relatórios.
Precisão e recall atuam como mecanismos de proteção, mas o sistema é ajustado em torno de resultados como tempo de revisão, latência de detecção de drift e o volume de tíquetes acionáveis produzidos por semana.
Conclusão
Ao combinar a rotulagem orientada por taxonomia e uma estrutura de avaliação no estilo MoE, habilitamos os fluxos de trabalho de engenharia e governança existentes no Databricks, com experimentos e implantações gerenciados usando o MLflow. Isso mantém os rótulos atualizados à medida que os esquemas mudam, torna as revisões de compliance mais rápidas e focadas e fornece os hooks de imposição necessários para aplicar regras de mascaramento e residência de forma consistente em toda a plataforma.
A parte mais empolgante deste trabalho é integrar nossos aprendizados internos diretamente no produto Data Classification. À medida que operacionalizamos e validamos essas técnicas dentro do LogSentinel, incorporamos nossas técnicas diretamente no Data Classification da Databricks.
O mesmo padrão — ingerir metadados e amostras, aumentar o contexto, orquestrar múltiplos LLMs e alimentar previsões em sistemas de políticas e tickets — pode ser reutilizado onde quer que seja necessária uma compreensão confiável e evolutiva dos dados. Ao incorporar essas percepções em nossa principal oferta de produtos, estamos capacitando todas as organizações a aproveitarem sua inteligência de dados para compliance e governança com a mesma precisão e escala que usamos na Databricks.
Agradecimentos
Este projeto foi possível graças à colaboração entre várias equipes de engenharia. Agradecimentos a Anirudh Kondaveeti, Sittichai Jiampojamarn, Zefan Xu, Li Yang, Xiaohui Sun, Dibyendu Karmakar, Chenen Liang, Viswesh Periyasamy, Chengzu Ou, Evion Kim, Matthew Hayes, Benjamin Ebanks, Sudeep Srivastava pelo apoio e contribuições.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.