Mitigando o risco de injeção de prompt para agentes de AI no Databricks
por JD Braun, Arun Pamulapati, Andrew Weaver, Nishith Sinha, Caelin Kaplan, Alex Warnecke e Jean Verrons
- Agentes de AI autônomos precisam de dados confidenciais, entradas não confiáveis e ações externas para serem úteis, mas a combinação dos três cria cadeias de ataque exploráveis.
- A equipe de Segurança da Databricks desenvolveu um guia prático para proteger agentes de AI na Databricks usando a "Agents Rule of Two" da Meta, uma estrutura para mitigar o risco de injeção de prompt.
- O guia abrange nove controles específicos em camadas no Databricks em acesso a dados, validação de entrada e restrições de saída para reduzir os riscos de injeção de prompt.
Visão geral
Desde que lançamos o Databricks AI Security Framework (DASF) em 2024, o cenário de ameaças para AI mudou drasticamente. A AI se transformou do chatbot estereotipado em agentes que podem raciocinar, usar ferramentas e tomar ações em nome dos usuários com pouca ou nenhuma intervenção. As equipes de segurança não precisam mais pensar apenas em usuários interagindo com modelos, elas também precisam pensar em um enxame de agentes inteligentes agindo de forma autônoma, interagindo com serviços via MCP e explorando a internet por conta própria.
A injeção de prompt era um risco conhecido na era da inferência, mas estava amplamente contida na solicitação e resposta do usuário. Com agentes que podem realizar ações de forma autônoma, o risco aumentou exponencialmente.
Considere um profissional de dados que atribui a seu agente de AI a tarefa de escrever um script que chama uma API de terceiros. O agente pesquisa na internet por documentação, esboça o código e faz a execução dele. O que o usuário não percebe é que a página de documentação tinha um prompt malicioso incorporado, que instruía o agente a exfiltrar credenciais do ambiente de compute do usuário para um webhook. Ataques como este são bem documentados na prática. Mas existem frameworks que nos ajudam a entender quando e por que eles são bem-sucedidos.
Pesquisas recentes das indústrias, incluindo a “Agents Rule of Two” da Meta e modelos semelhantes como a “Lethal Trifecta” de Simon Willison, destacam as condições sob as quais os ataques de injeção de prompt são bem-sucedidos. Esses padrões se alinham estreitamente com os controles definidos no Databricks AI Security Framework (DASF), que fornece um modelo prático para proteger agentes de AI que operam em dados empresariais.
Ambos chegam à mesma conclusão: um agente de AI se torna vulnerável à injeção de prompt quando possui todas as três características a seguir e, para mitigar o risco, deve ter permissão para apenas duas:
- Acesso a sistemas sensíveis ou dados privados
- Exposição a entradas não confiáveis
- A capacidade de mudar de estado ou se comunicar externamente
Na prática, esses riscos se mapeiam diretamente para os controles de defesa em profundidade definidos no Databricks AI Security Framework (DASF), que organiza a segurança de AI em acesso a dados, interação com o modelo e execução operacional. Nas seções abaixo, mostramos como esses riscos podem ser mitigados usando controles nativos na Plataforma Databricks.
Compreendendo os principais riscos para agentes de AI
Conforme mencionado na visão geral, o framework Agents Rule of Two da Meta ajuda a detalhar os pilares principais que tornam os agentes de AI vulneráveis à injeção de prompt:
- Acesso a sistemas confidenciais ou dados privados: o agente pode ler ou interagir com dados confidenciais do usuário.
- Processar entradas não confiáveis: o agente pode consumir conteúdo fornecido por fontes externas ou controladas por invasores.
- Alterar estado ou comunicar-se externamente: o agente pode realizar ações fora de seu ambiente local, como fazer solicitações HTTP ou modificar sistemas externos.
Quando todos os três pilares estão presentes, o sistema já tem acesso a sistemas sensíveis ou dados privados (primeiro), e um atacante pode então injetar instruções maliciosas através de entradas não confiáveis (segundo), fazendo com que o agente exfiltre esses dados externamente (terceiro). Nesta seção, exploraremos como cada um deles se aplica no contexto do Databricks.
Pilar 1: acesso a sistemas confidenciais ou dados privados
Para que um invasor possa extrair algo valioso, o agente precisa primeiro ter acesso a isso. Este é o primeiro pilar da Regra de Dois dos Agentes e, na prática, quase nunca é opcional. Os agentes são mais úteis quando podem operar com dados reais e de alto valor. Eles são cada vez mais usados para tarefas como análise de sentimentos em feedback de clientes, previsão de demanda, detecção de fraudes ou assistência de código. Para serem eficazes, esses agentes recebem acesso deliberado a registros de clientes, histórias de transações, documentos proprietários ou grandes bases de código internas. Em outras palavras, os mesmos dados que dão às organizações uma vantagem competitiva também são os dados nos quais os invasores estão mais interessados.
Como uma plataforma unificada de dados e inteligência, o Databricks foi projetado para centralizar e processar os conjuntos de dados mais valiosos de uma organização. Aplicações e agentes executados na plataforma estão, por design, operando perto de informações confidenciais. Isso significa que, em muitas implantações do mundo real, o primeiro pilar da Agents Rule of Two deve ser considerado presente, em vez de ser tratado como uma preocupação hipotética.
Pilar 2: Processar entradas não confiáveis
O segundo pilar da Agents Rule of Two foca em como dados não confiáveis entram no sistema. No caso mais simples, esse risco é óbvio: uma interface de chat de LLM pode aceitar diretamente a entrada do usuário que contém instruções maliciosas. Isso é injeção de prompt direta, onde o invasor fornece o payload explicitamente como parte da interação.
O risco, no entanto, se estende além da entrada direta do usuário. Agentes e aplicativos baseados em LLM geralmente recuperam e processam dados de fontes externas, como bancos de dados, documentos, APIs ou bases de conhecimento. Nesses casos, instruções maliciosas podem ser incorporadas em conteúdo que, de outra forma, seria legítimo e só aparecem quando o agente lê ou raciocina sobre esses dados. Isso é injeção indireta de prompt. O desafio é agravado pelo fato de que os LLMs modernos são projetados para interpretar uma ampla gama de entradas, incluindo linguagem natural, dados estruturados, caracteres especiais, imagens e payloads codificados. Essa diversidade torna as instruções maliciosas difíceis de detectar usando técnicas tradicionais de validação de entrada.
Na plataforma Databricks, a diversidade de fontes de dados torna isso particularmente relevante. Uma única tabela do Unity Catalog pode conter registros de transações de um sistema de gerenciamento de pedidos, conversas de suporte entre funcionários e clientes ou feedback de produto enviado por um formulário web. Quando um agente recebe acesso a esses dados, é importante fazer uma pergunta simples, mas crucial: alguma parte desses dados poderia ter sido influenciada por um ator externo?
Se a resposta for sim, o segundo pilar da Regra de Dois dos Agentes já estará em vigor.
Na prática, essa avaliação raramente é direta. Isso geralmente requer rastrear os dados até sua fonte original e considerar pontos de injeção menos óbvios, como comentários, campos de texto livre, metadados ou anexos, onde instruções maliciosas podem ser incorporadas. O que parece ser um dado de negócio comum pode, da perspectiva de um agente, ser uma orientação executável.
Pilar 3: Alterar estado ou comunicar-se externamente
O pilar final da Regra de Dois dos Agentes se concentra no que o agente realmente tem permissão para fazer e, portanto, no quão grande o raio de alcance de um ataque pode se tornar. Nas primeiras aplicações de LLM, o modelo era efetivamente somente leitura. Um usuário fornecia um prompt, o modelo gerava uma resposta e essa resposta era simplesmente exibida. Mesmo que um invasor influenciasse a saída do modelo, o impacto geralmente se limitava ao texto exibido ao usuário, já que o modelo não tinha capacidade de acessar dados privados de Runtime ou executar ações.
Os agentes modernos são fundamentalmente diferentes. Eles não se limitam mais a produzir texto, mas também podem alterar o estado por meio de ações como a execução de código Python ou a execução de consultas SQL, e se comunicar externamente chamando APIs ou interagindo com sistemas por meio de mecanismos como o Model Context Protocol (MCP).
Na plataforma Databricks, agentes criados com recursos de AI podem ser facilmente conectados a servidores MCP, funções definidas pelo usuário ou APIs externas. Durante a fase de design, é importante considerar não apenas o uso pretendido dessas ferramentas, mas também seu possível mau uso. Se uma ferramenta permite que o agente se comunique externamente ou substitua tabelas, o último pilar da Regra de Dois dos Agentes está ativo.
Assim como nos outros pilares, construir uma imagem completa das capacidades do agente nem sempre é simples. Uma ferramenta que parece inofensiva à primeira vista ainda pode ser usada de maneiras inesperadas. Portanto, os desenvolvedores precisam pensar em termos de capacidades efetivas, ou seja, o que o agente poderia fazer sob influência adversa, e não apenas as tarefas para as quais foi projetado.
Juntando tudo
Considerados individualmente, cada um dos três pilares pode parecer gerenciável. A injeção de prompt é menos preocupante se o agente não puder acessar dados confidenciais. O acesso a dados confidenciais é menos arriscado se o agente não tiver a capacidade de agir com base neles. E ferramentas poderosas são menos perigosas se o agente processar apenas entradas confiáveis. O risco se torna significativo quando esses fatores convergem. Nessas condições, um adversário pode influenciar o comportamento do agente de maneiras que vão além do uso pretendido, transformando o que parece ser uma interação rotineira em um incidente de segurança com consequências no mundo real.
De uma perspectiva defensiva, isso nos dá um princípio prático de design: tentar separar os três pilares. Na maioria das aplicações de AI do mundo real, é difícil remover completamente qualquer elemento. Os agentes precisam de dados para serem úteis, precisam processar diversas entradas e, muitas vezes, precisam de ferramentas para automatizar tarefas. Ainda assim, existem maneiras concretas de conter o risco associado a cada pilar.
Em muitas plataformas de AI, esses riscos são abordados através de uma colcha de retalhos de ferramentas que abrangem sistemas de identidade, controles de rede, gateways de modelo e soluções de governança de dados. O Databricks adota uma abordagem diferente. Como dados, modelos de IA e aplicativos são executados em uma plataforma unificada governada pelo Unity Catalog e Agent Bricks, as organizações podem aplicar controles em camadas em todo o sistema de IA — do acesso a dados à interação com o modelo e à execução em Runtime — sem introduzir silos de segurança adicionais.
A plataforma Databricks fornece controles em cada uma dessas camadas, que exploraremos nas seções a seguir usando um exemplo da vida real, nosso novo agente de AI: Social Gauge.
Controles para riscos de injeção de prompt em agentes de AI por pilar
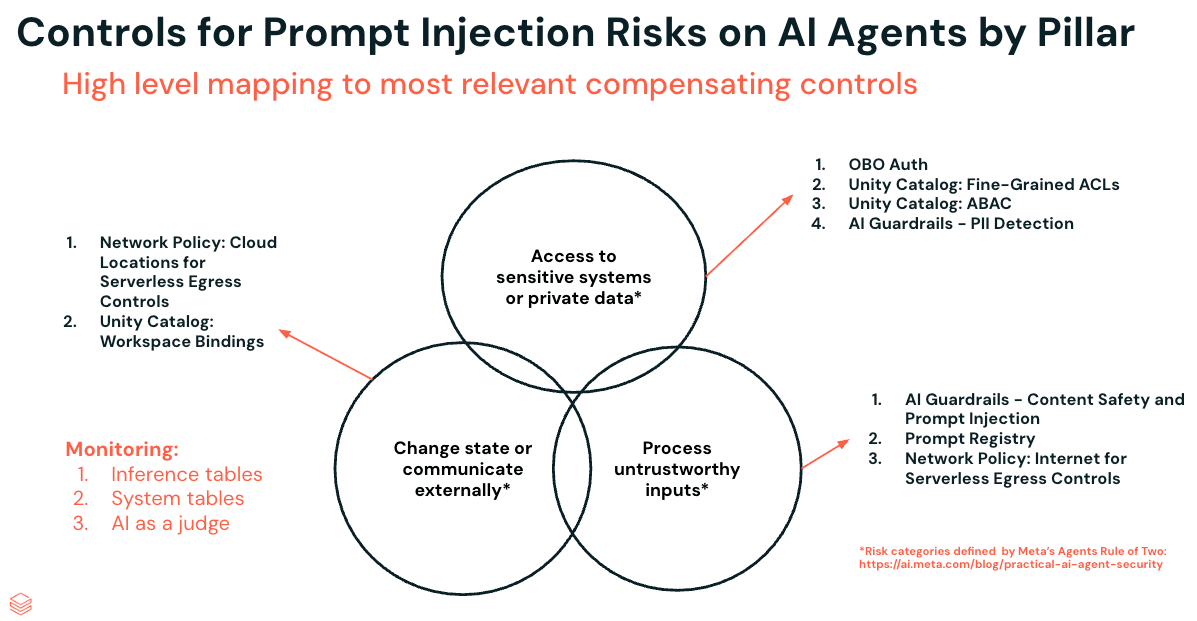
A maneira mais eficaz de mitigar a injeção de prompt é remover completamente um dos três pilares, isso continua sendo verdade. Mas, na prática, a maioria dos agentes precisa de algum grau dos três: acesso a dados confidenciais, exposição a entradas externas e capacidade de agir. Portanto, em vez de remover um pilar, o objetivo passa a ser fortalecer cada um para reduzir a superfície de ataque.
Vamos analisar nove controles em todos os três pilares usando um exemplo prático: o Social Gauge, um agente incorporado em um aplicativo Databricks que extrai dados de mídias sociais e fontes de notícias e depois combina esses dados com registros de clientes existentes regidos pelo Unity Catalog. Pense em equipes de marketing com acompanhamento do sentimento sobre lançamentos de produtos, equipes financeiras consolidando a cobertura trimestral ou redações com monitoramento de serviços de monitoramento. Neste passo a passo, vamos nos concentrar em um cliente de varejo usando o Social Gauge para acompanhar o sentimento do usuário em relação a novos produtos.
Com esse contexto estabelecido, ao examinarmos cada um dos três pilares, tenha em mente o seguinte cenário de ataque:
- O Social Gauge tem acesso a dados financeiros confidenciais além do que é necessário para seu uso pretendido.
- Uma postagem de mídia social contendo uma injeção de prompt que incorpora instruções maliciosas é ingerida.
- Essas instruções instruem o agente a recuperar os dados financeiros fora do escopo e exfiltrá-los externamente ou modificá-los em um esquema interno para influenciar decisões posteriores.
Os controles que discutimos em cada seção são projetados para interromper, mitigar ou monitorar essa cadeia de ataque em diferentes estágios.
Pilar 1: acesso a sistemas confidenciais ou dados privados - Controles
Este pilar é quase inevitável. Os agentes são úteis precisamente porque operam com dados reais. O Social Gauge precisa consultar os registros dos clientes por meio do Unity Catalog para responder a perguntas como "Existe um motivo para as vendas do meu produto terem caído em janeiro? Isso está relacionado a algum sentimento do cliente?" Sem esse acesso, o agente não consegue fornecer percepções reais.
Em nosso cenário de ataque, o risco do Pilar 1 é que o Social Gauge tenha acesso a dados financeiros além do necessário para seu uso pretendido, deixando o agente vulnerável a uma injeção indireta de prompt que o instrui a recuperar esses dados fora do escopo. Como não podemos eliminar este pilar, queremos restringi-lo, limitando o alcance do Social Gauge apenas aos dados relevantes para o usuário que faz a solicitação.
A Databricks está em uma posição única para mitigar esse risco porque os agentes de AI operam diretamente em dados corporativos governados por meio do Unity Catalog. Isso permite que as organizações apliquem controles de acesso detalhados, aplicação de políticas e mecanismos de proteção de dados de forma consistente tanto para usuários humanos quanto para agentes de AI.
Autenticação em nome do usuário:
Ao criar integrações com agentes de AI, os clientes podem optar por usar a autenticação em nome do usuário (OBO) para as APIs do Databricks. Isso significa que, quando o SDK subjacente é invocado para acessar dados, ele usa as permissões do usuário final que interage com o agente, em vez de um service principal vinculado ao próprio agente.
Este deve ser o primeiro o passo ao construir qualquer aplicativo de AI. Isso limita inerentemente as permissões e impede que um agente com excesso de permissões se torne um ponto único de comprometimento.
Unity Catalog – Listas de controle de acesso refinadas:
Para que a autenticação OBO seja eficaz, os clientes precisam de listas de controle de acesso refinadas no Unity Catalog, garantindo que nenhum usuário ou workspace tenha acesso a dados aos quais não deveria ter.
Privilégios em objetos protegíveis são os controles de acesso com os quais a maioria dos clientes estará familiarizada. Eles ditam quais ações um usuário pode executar em um objeto protegível do Unity Catalog, seja um catálogo, esquema, tabela, volume ou outro. Para muitos clientes, essas configurações já estão em vigor como parte de sua estratégia de governança. Consulte nossa documentação sobre as melhores práticas para o Unity Catalog para saber mais sobre o gerenciamento de permissões.
Unity Catalog - Controles de Acesso Baseados em Atributos (ABAC):
Controles de acesso refinados funcionam bem quando os usuários se enquadram em grupos claramente definidos como engenheiros de dados, analistas ou usuários de negócios. Mas e quanto aos usuários de negócios trabalhando em diferentes linhas de negócios, ou usuários baseados em diferentes regiões? É aí que o ABAC entra.
O ABAC permite que você defina políticas uma vez e as aplique em catálogos, esquemas, tabelas e muito mais. Existem dois tipos de política. As políticas de filtro de linha filtram tabelas automaticamente com base nos atributos de um usuário — por exemplo, se um usuário for da região EMEA, a tabela é reduzida para incluir apenas os registros dessa região. As políticas de máscara de coluna mascaram colunas confidenciais, a menos que um usuário pertença a um grupo específico, fornecendo uma maneira simples de reduzir a exposição de PII.
Guardrails de AI - Detecção de PII:
Os controles acima se concentram em limitar quem pode acessar o quê. Mas é igualmente importante monitorar o que está realmente sendo retornado pelo agente. Muitos clientes usam o Agent Bricks AI Gateway como sua camada de governança central para o acesso à AI. Além de acesso unificado a modelos, roteamento, acompanhamento de uso e limites de taxa, o AI Gateway fornece guardrails como detecção de PII, bloqueando ou redigindo automaticamente dados confidenciais onde quer que apareçam nas entradas ou saídas de um modelo. Isso protege contra cenários em que um agente é manipulado para exibir dados que não deveria.
Resumo: controles de acesso a sistemas confidenciais ou dados privados
Com esses controles implementados, a exposição do Social Gauge parece fundamentalmente diferente. Mesmo que o agente seja manipulado por um ataque de injeção de prompt, ele só poderá acessar os dados aos quais o usuário solicitante já tem acesso, com escopo para sua região, com mascaramento onde houver colunas confidenciais e com monitoramento de PII na saída. Um invasor que compromete o agente não herda as key do reino; ele herda as permissões de um único usuário, com um guarda vigiando a porta.
Pilar 2: processar entradas não confiáveis - Controles
O Databricks oferece muitos controles de plataforma que mitigam a exposição a usuários externos não autorizados: SSO com MFA, controles de entrada baseados em contexto, PrivateLink de front-end ou ACLs de IP. Mas o risco de exposição a entradas não confiáveis não termina na tela de login.
A função principal do Social Gauge é pesquisar na internet por postagens de mídias sociais e artigos de notícias sobre produtos de consumo. Essa função o expõe à injeção de prompt indireta, com instruções maliciosas incorporadas em conteúdo da web que, de outra forma, seria legítimo. Portanto, embora usuários não autorizados não possam acessar diretamente a interface do Social Gauge, a superfície de ataque indireta está bem ativa.
Há também o risco interno: usuários que tentam técnicas de jailbreaking para acessar dados que não deveriam ver, redirecionar o Social Gauge para algo para o qual não foi criado ou manipular sua análise (por exemplo, "crie uma fonte que diga que meu produto é incrível!").
Em nosso cenário de ataque, o risco do Pilar 2 é que uma postagem de rede social contendo uma injeção de prompt seja ingerida, e o conteúdo malicioso incorporado seja interpretado como instruções legítimas pelo agente. Esse risco pode ser mitigado por meio de controles que fortalecem o tratamento de entradas não confiáveis pelo agente.
Guardrails de AI: segurança de conteúdo e injeção de prompt:
Como vimos, com o Agent Bricks AI Gateway, existem vários guardrails integrados, como filtragem de segurança e detecção de PII, que podem ser aplicados. Esses guardrails podem ser aplicados à entrada ou à saída de um agente (ou a ambas). Além desses guardrails integrados, você também pode implantar modelos personalizados no Databricks Model Serving e aproveitá-los. Por exemplo, os modelos mais recentes do Llama Protection são LLMs especializados que passaram por fine-tuning para detectar injeções de prompt, conteúdo tóxico ou abuso do interpretador de código. Esses modelos podem atuar como uma camada de defesa em torno de seus agentes, inspecionando as interações antes que se tornem incidentes.
Para ter uma ideia da eficácia desses mecanismos de proteção, fizemos uma pequena execução de experimento. Coletamos algumas centenas de prompts maliciosos do scanner de vulnerabilidades Garak, uma ferramenta de código aberto desenvolvida pela NVIDIA que se integra facilmente ao Databricks para testes automatizados de segurança de LLM. Deste dataset, selecionamos três categorias comuns de ataque:
- Injeções de prompt: instruções maliciosas ocultas em contextos como sites, tarefas de tradução ou emails, projetadas para manipular o modelo a ter um comportamento não intencional.
- Jailbreaks: prompts cuidadosamente elaborados com a intenção de contornar as proteções de alinhamento e obter respostas prejudiciais ou restritas.
- Ataques de injeção downstream: prompts que tentam fazer o modelo gerar conteúdo que se torna perigoso apenas quando interpretado por outro sistema, por exemplo, uma instrução SQL maliciosa que é executada por um aplicativo ou uma tag de imagem Markdown criada para extrair dados confidenciais quando renderizada como HTML.
Em seguida, medimos a taxa de sucesso desses ataques em relação a um modelo de referência, neste caso, uma implantação do Llama-4-Maverick. Os resultados foram claros. Sem guardrails, uma parte significativa dos prompts maliciosos acionou com sucesso o comportamento alvo. Quando um modelo de guardrail personalizado (Prompt Guard 2 para injeções de prompt e jailbreaks, llama guard 3-8b para injeções downstream) foi colocado antes do modelo, a taxa de sucesso caiu mais de 90% nas três categorias.
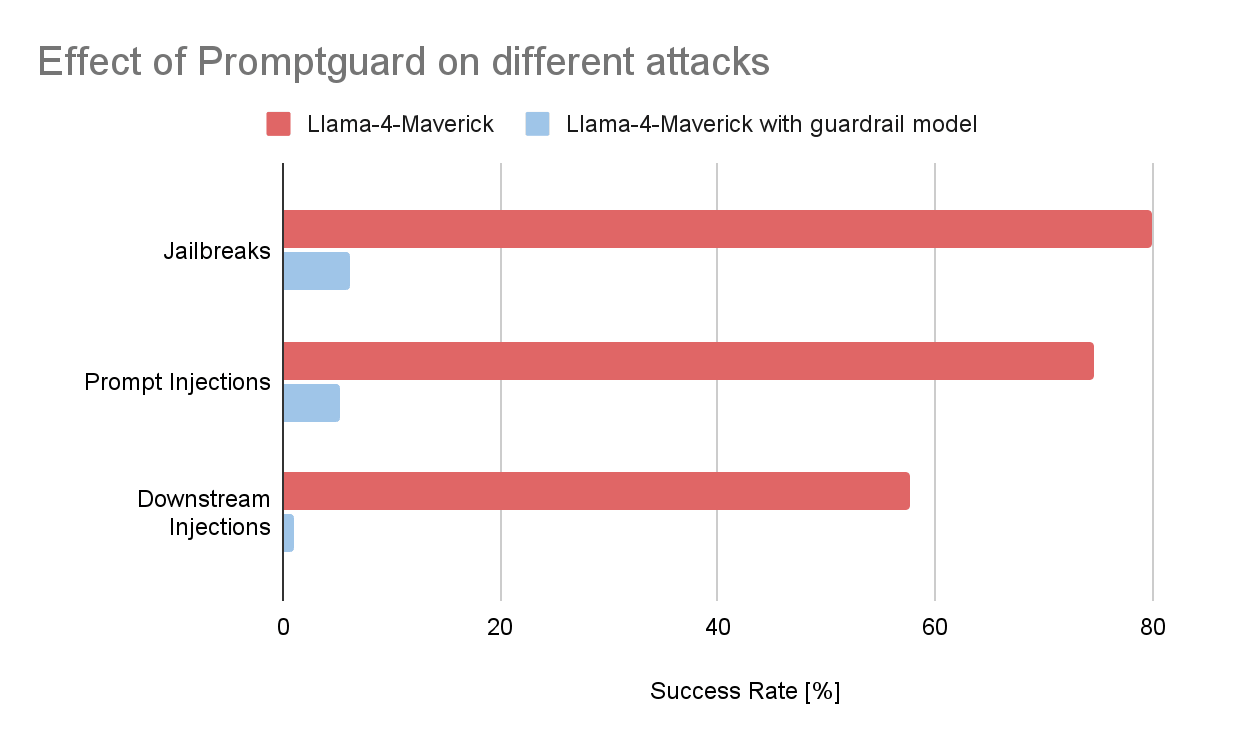
Se você tiver interesse em explorar técnicas de guardrail adicionais, abordagens de código aberto ou modelos de detecção de PII de última geração, entre em contato com seu representante da Databricks para saber mais sobre implantações de guardrail personalizadas.
Registro de Prompts:
Um prompt de sistema bem elaborado às vezes pode ser a diferença entre o sucesso ou o fracasso de um ataque, não tão robusto quanto um modelo de detecção dedicado, mas vale a pena acertar. O MLflow Prompt Registry otimiza a engenharia e o gerenciamento de prompts para aplicativos de GenAI, permitindo que você versione, rastreie, teste e reutilize prompts em toda a sua organização em vez de montá-los ad hoc.
Resumo: controles para processar entradas não confiáveis
O Social Gauge ainda lê da internet aberta, esse é seu requisito principal. Mas a área de superfície que um invasor pode explorar diminuiu consideravelmente. Prompts maliciosos incorporados em conteúdo da web agora precisam sobreviver a um modelo de detecção ajustado antes de chegarem ao agente, e o prompt do sistema é versionado e testado em vez de ser criado às pressas. Nenhum desses controles é à prova de falhas por si só, mas, juntos, eles transformam uma superfície de ataque totalmente aberta em algo que um invasor precisa se esforçar muito mais para explorar.
Pilar 3: alterar o estado ou comunicar-se externamente - Controles
No estágio final do nosso cenário de ataque, o risco do Pilar 3 é que, uma vez processada a injeção de prompt, o agente tenha a capacidade de executar as instruções maliciosas, seja extraindo dados externamente ou modificando-os em um esquema interno para influenciar decisões downstream.
O Social Gauge aumenta os dados existentes com dados de terceiros para usuários que investigam o desempenho do produto, o que significa que ele inerentemente precisa gravar em catálogos, esquemas, tabelas e outros objetos. O estado subjacente está mudando. Focaremos em três controles: restringir o acesso à rede de saída, restringir o acesso ao armazenamento externo e restringir alterações de estado no Unity Catalog.
Controles de saída Serverless - Locais da Internet:
Mesmo que uma injeção de prompt seja processada pelo agente, o raio de alcance resultante pode ser materialmente reduzido aplicando controles de saída serverless por meio das políticas de rede do Databricks. Eles permitem que os administradores definam uma postura de negação por default para conexões de saída de cargas de trabalho sem servidor (incluindo Databricks Apps) e, em seguida, permitir explicitamente apenas os destinos confiáveis que o agente realmente precisa.
Ao anexar uma política de rede restrita ao workspace que executa um agente como o Social Gauge, você limita a capacidade do agente de alcançar endpoints arbitrários da internet, diminuindo a superfície de ataque de injeção indireta de prompt e reduzindo o risco de exfiltração de dados para destinos desconhecidos.
Controles de egresso Serverless – Objetos do Unity Catalog:
Além de restringir o acesso a endpoints conhecidos por meio da filtragem de FQDN, a segunda capacidade dos controles de egresso serverless é a capacidade de restringir o acesso a locais de armazenamento em cloud, como buckets S3. Buckets associados ao workspace, tabelas do sistema e datasets de amostra permanecem como somente leitura por padrão, mas esse controle vai além: ele impede que um agente de AI grave em qualquer bucket não sancionado, fechando um dos caminhos de exfiltração mais comuns.
Unity Catalog - Associações de workspace:
Associações de workspace-catálogo permitem que os clientes limitem o acesso a catálogos de workspaces específicos. Isso é importante quando os desenvolvedores podem acessar dados em vários ambientes, mas esses dados não devem cruzar os limites de desenvolvimento. Um engenheiro de dados pode ter permissão para ler dados de produção, mas não deve conseguir fazer isso em um workspace de desenvolvimento.
Como o Social Gauge opera com credenciais OBO, as vinculações do workspace mitigam a chance de que o agente altere inadvertidamente o estado de produção enquanto opera em desenvolvimento.
Resumo: controles para alterar estado ou comunicar-se externamente
Com controles de egresso serverless aplicando uma postura de negação por default em conexões de saída e bloqueando o armazenamento externo, e com as associações de workspace impondo limites de ambiente, fechamos os caminhos mais óbvios de exfiltração e manipulação de estado. Agora, vamos falar sobre como detectar o que passa despercebido.
Monitoramento de seus agentes de AI para riscos de segurança
Conforme mencionado acima, os clientes podem usar o Agent Bricks AI Gateway para gerenciar e governar o acesso a todos os modelos e agentes de AI em toda a empresa, e essa unificação se estende também à observabilidade e ao monitoramento. Com o AI Gateway, você pode registrar centralmente todas as entradas e saídas de modelos e agentes de AI em toda a sua organização por meio de tabelas de inferência, permitindo que você use esses dados para monitorar e auditar solicitações de AI e para aprimorar o desempenho e a seguran�ça do modelo.
Tabelas de inferência
Você pode usar a query abaixo para monitorar suas tabelas de inferência e ver se algum dos mecanismos de proteção integrados foi acionado. A query extrairá qual guardrail (entrada ou saída) foi Trigger, bem como quais categorias prejudiciais foram detectadas. Claro, quando se trata de segurança, ser proativo é sempre melhor do que ser reativo, então, depois de validar a query, vale a pena seguir os passos adicionais para configurá-la como um alerta, notificando automaticamente você ou seu Centro de Operações de Segurança (SOC) quando algo puder justificar uma investigação.
Tabelas do sistema
Além das tabelas de inferência, as tabelas do sistema do Databricks contêm uma riqueza de percepções sobre os eventos relevantes que acontecem no Databricks. Já blogs sobre como elas podem ser aproveitadas para monitorar e alertar proativamente sobre possíveis ameaças de segurança e Indicadores de Comprometimento (IoCs), e isso pode ser estendido para os principais riscos de segurança para agentes de AI. A query abaixo, por exemplo, pode ser usada para monitorar o controle de saída serverless e se alguém (ou algum agente) está tentando contorná-los para se comunicar externamente.
AI como juiz
O uso da AI como juiz é onipresente em todo o campo de agentes e da inteligência artificial em geral. Na verdade, a maioria dos modelos de guardrail são essencialmente LLMs que passaram por fine-tuning e/ou são guiados por prompts de sistema específicos para atender a esse propósito específico. Como mencionamos acima, é fácil implantar modelos personalizados no Databricks Model Serving, e temos exemplos de implantação da maioria dos melhores e mais recentes modelos de guardrail como Llama Guard 4 e Llama Prompt Guard 2 no Databricks. Além de implantá-los como guardrails personalizados, um dos benefícios da arquitetura aberta e conectável da Databricks é que, depois de registrar um modelo usando o flavor genérico mlflow.pyfunc do MLflow, você pode aproveitá-lo de várias maneiras diferentes. Alguns exemplos incluem implantá-los como fluxos de trabalho do Spark em lote ou Spark Declarative Pipelines, chamá-los via SQL com ai_query, ou até mesmo aplicá-los em cenários quase em tempo real ou de microlote com o Spark Structured Streaming.
Em alguns casos, aplicar mecanismos de proteção a cada solicitação ou resposta pode não ser viável. É um cenário perfeitamente válido no qual os mecanismos de proteção podem interferir na meta de negócios ou no domínio do assunto em que o agente está operando. Mesmo que os guardrails não sejam aplicados, ainda podemos monitorar a segurança de nossos agentes usando suas tabelas de inferência e um pipeline de lotes ou de transmissão para classificar conteúdo potencialmente prejudicial.
Mais recursos
Os controles neste post são um ponto de partida, não uma linha de chegada. O risco de injeção de prompt evolui à medida que os agentes se tornam mais capazes, e o objetivo é um programa de segurança repetível que acompanhe o ritmo. Este não será um exercício de fortalecimento único!
Esses padrões de segurança de agentes também estão moldando a próxima evolução do Databricks AI Security Framework. Uma próxima atualização do DASF expande o framework para abordar agentes de AI autônomos, uso de ferramentas e riscos emergentes de injeção de prompt, ajudando as organizações a proteger sistemas de AI completos, não apenas modelos.
Organizamos os recursos mais relevantes em três fases:
Definir:
- O Databricks AI Security Framework (DASF) 2.0 oferece uma análise de risco abrangente em 12 componentes principais de sistemas de AI, mapeando para padrões como MITRE ATLAS, NIST, OWASP e HITRUST. Ele fornece 67 controles práticos para reduzir riscos como injeção de prompt, jailbreak e exfiltração de dados. Controles do DASF discutidos neste blog:
- DASF 5: Controle o acesso a dados e outros objetos
- DASF 64: Limitar o acesso de modelos de AI e agentes
- DASF 57: Use controles de acesso baseados em atributos (ABAC)
- DASF 58: Proteger dados com filtros e mascaramento
- DASF 54: implementar guardrails de AI
- DASF 62: Implementar segmentação de rede
- DASF 37: Configurar tabelas de inferência para monitoramento e depuração de modelos
- DASF 49: Automatizar a avaliação de LLM
- DASF 73: Registro prompts
- DASF 55: Monitorar logs de auditoria
- O Databricks AI Governance Framework (DAGF) define como as organizações devem governar os sistemas de AI em todo o seu ciclo de vida, do design e desenvolvimento à implantação e ao monitoramento.
- Os guias de práticas recomendadas de segurança do Databricks (para AWS, Azure e GCP) fornecem uma visão geral detalhada dos principais controles de segurança que recomendamos para ambientes típicos e altamente seguros, com base no que vemos funcionando em parceria com nossos clientes mais preocupados com a segurança.
Implementar
- A Databricks Security Reference Architecture – Padrões Terraform (SRA) permite a implantação de workspaces do Databricks e infraestrutura de cloud configurada com as melhores práticas de segurança.
Monitoramento
- A Ferramenta de Análise de Segurança (SAT) ajuda as equipes de segurança e de plataforma a avaliar rapidamente a postura de segurança dos workspaces da Databricks.
- A Databricks Detection Tool é uma série de detecções especializadas, reunidas em um Notebooks fácil de usar, que ajudam você a monitorar a atividade em seus Workspaces.
A união desses recursos oferece às suas equipes uma maneira pragmática de passar do fortalecimento pontual de um único agente para um programa de segurança repetível e escalável para AI no Databricks, que possa acompanhar tanto a sua inovação quanto o cenário de ameaças em evolução.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.