A Nova Maneira de Construir Pipelines no Databricks: Apresentando o IDE para Engenharia de Dados
Uma nova experiência de desenvolvedor criada especificamente para a criação de Pipelines Declarativas do Spark com Lakeflow
por Adriana Ispas, Lennart Kats, Camiel Steenstra e Monica Alvarez Vicente
- Pipelines Declarativas do Spark agora têm uma experiência de IDE dedicada no Databricks Workspace.
- A nova IDE melhora a produtividade e a depuração com recursos como grafos de dependência, visualizações e insights de execução.
- A IDE suporta integração rápida e casos de uso avançados, como integração com Git, CI/CD e observabilidade.
Na Data + AI Summit deste ano, apresentamos o IDE para Engenharia de Dados: uma nova experiência de desenvolvimento criada especificamente para a criação de pipelines de dados diretamente no Databricks Workspace. Como a nova experiência de desenvolvimento padrão, o IDE reflete nossa abordagem opinativa para engenharia de dados: declarativa por padrão, modular na estrutura, integrada ao Git e assistida por IA.
Em resumo, o IDE para Engenharia de Dados é tudo o que você precisa para criar e testar pipelines de dados - tudo em um só lugar.
Com esta nova experiência de desenvolvimento disponível em Preview Público, gostaríamos de usar este blog para explicar por que os pipelines declarativos se beneficiam de uma experiência de IDE dedicada e destacar os principais recursos que tornam o desenvolvimento de pipelines mais rápido, organizado e fácil de depurar.
Engenharia de dados declarativa ganha uma experiência de desenvolvedor dedicada
Pipelines declarativos simplificam a engenharia de dados, permitindo que você declare o que deseja alcançar em vez de escrever instruções detalhadas passo a passo sobre como construí-lo. Embora a programação declarativa seja uma abordagem extremamente poderosa para construir pipelines de dados, trabalhar com vários conjuntos de dados e gerenciar o ciclo de vida completo do desenvolvimento pode se tornar difícil de lidar sem ferramentas dedicadas.
É por isso que criamos uma experiência completa de IDE para pipelines declarativos diretamente no Databricks Workspace. Disponível como um novo editor para Lakeflow Spark Declarative Pipelines, ele permite que você declare conjuntos de dados e restrições de qualidade em arquivos, organize-os em pastas e visualize as conexões através de um grafo de dependência gerado automaticamente exibido ao lado do seu código. O editor avalia seus arquivos para determinar o plano de execução mais eficiente e permite que você itere rapidamente reexecutando arquivos únicos, um conjunto de conjuntos de dados alterados ou o pipeline inteiro.
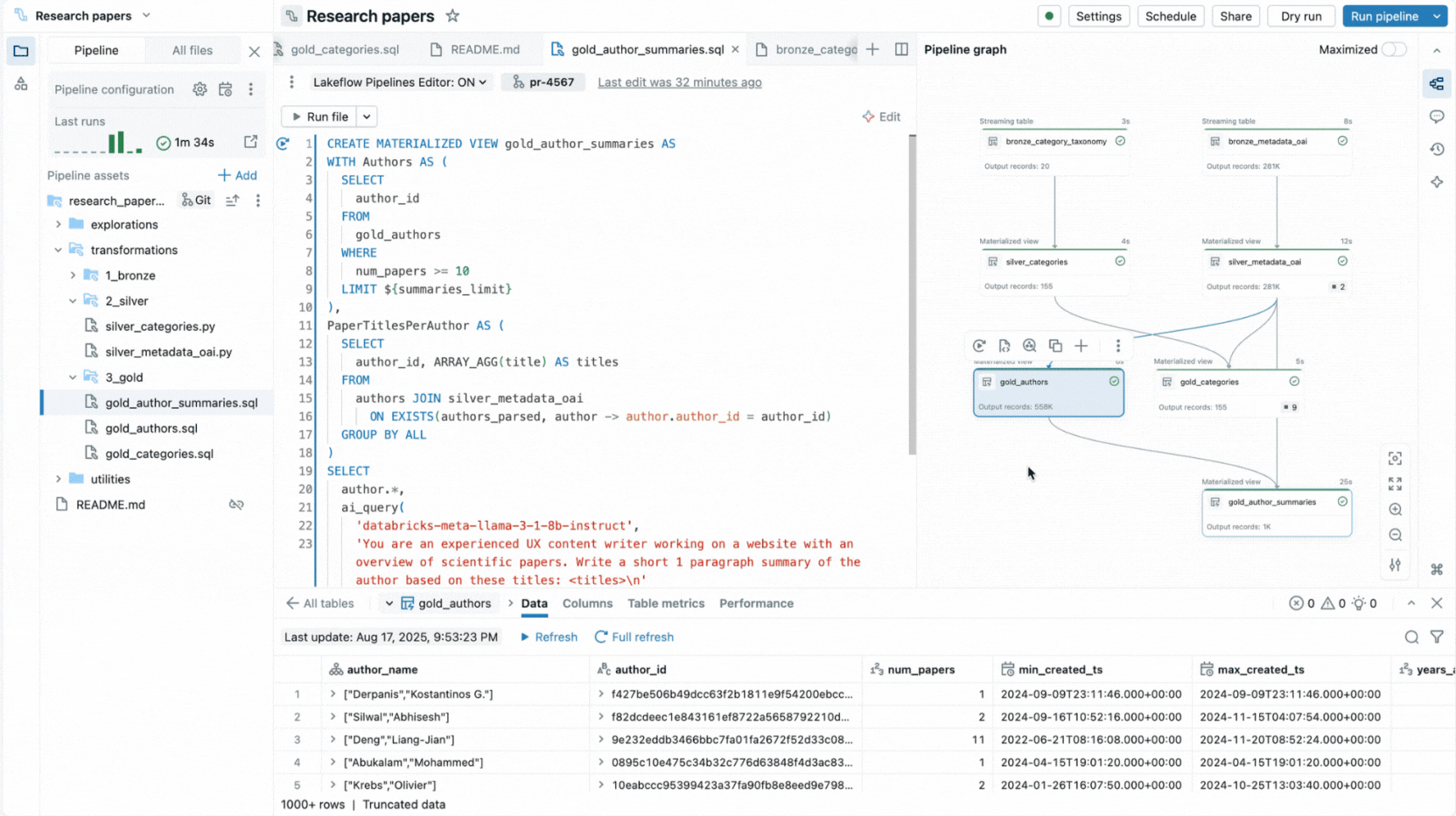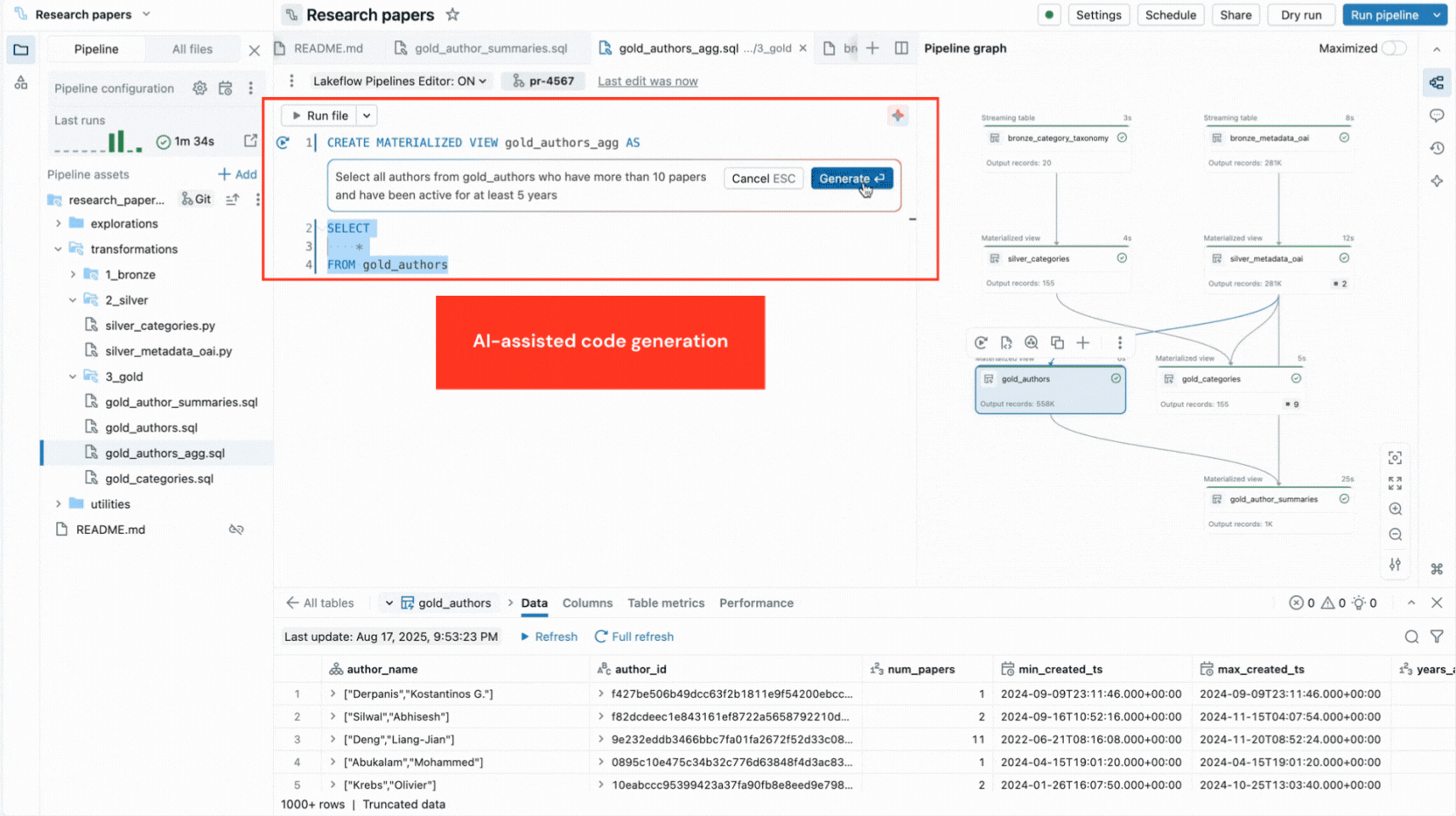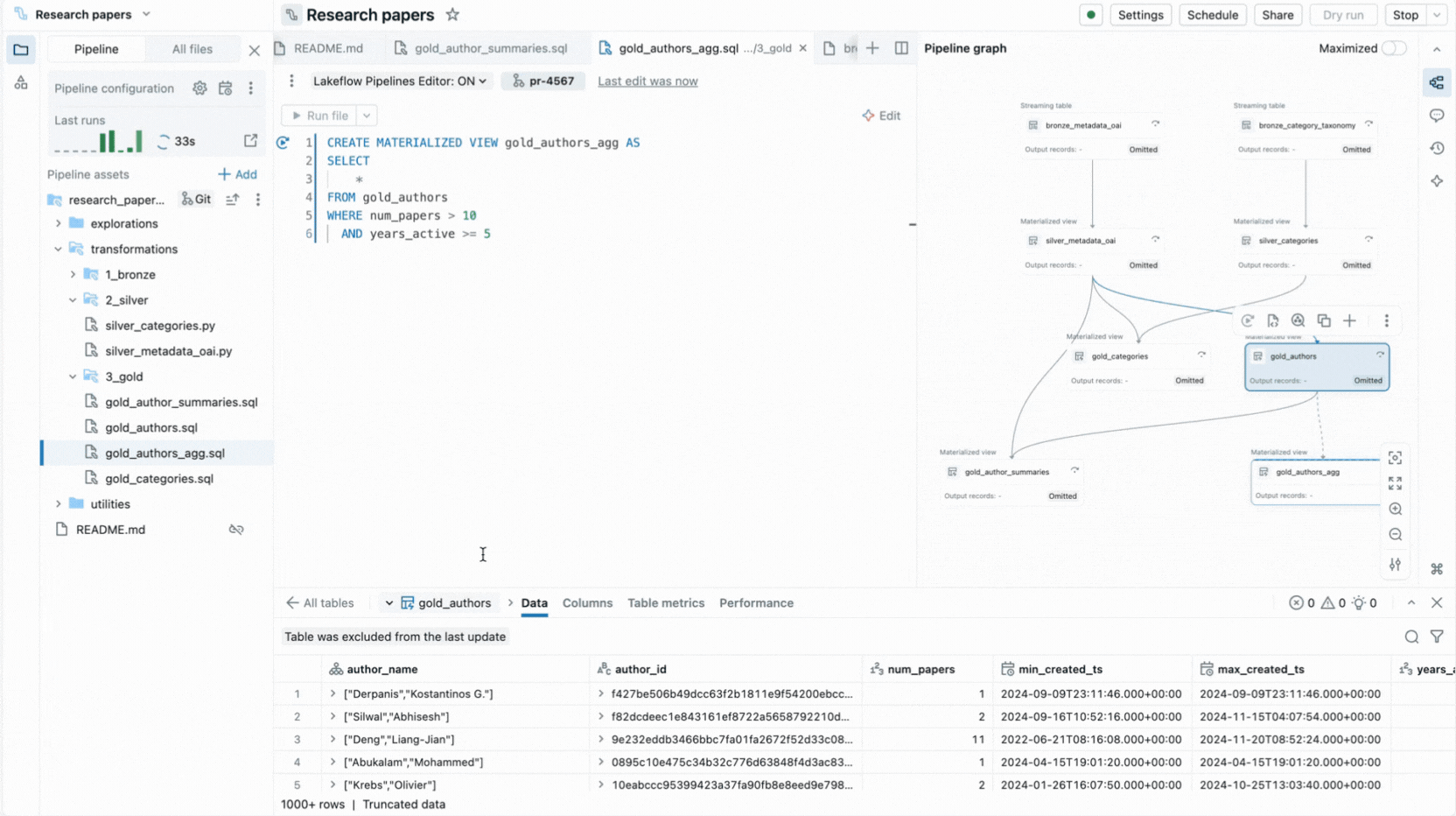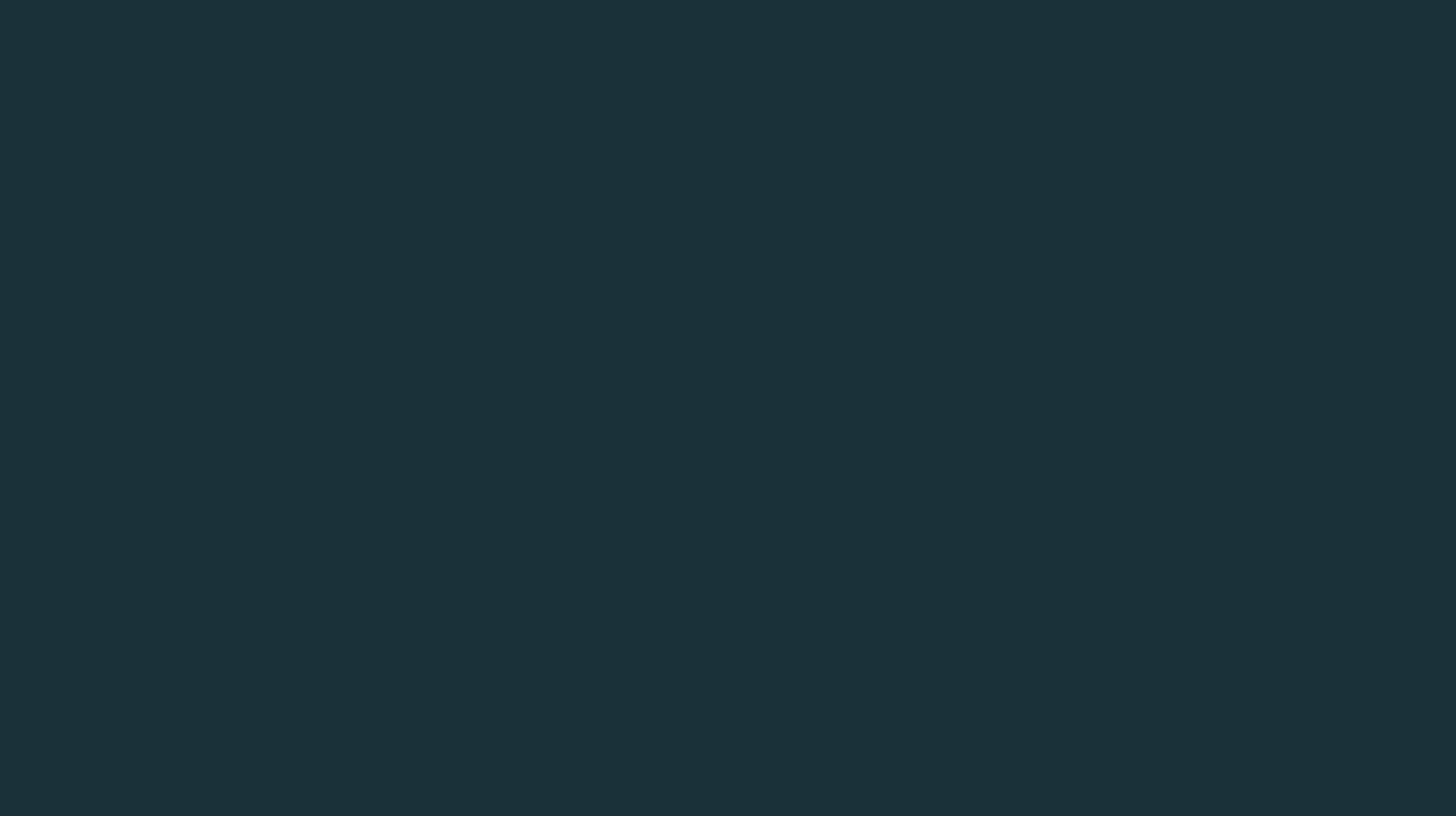
O editor também exibe insights de execução, fornece visualizações de dados integradas e inclui ferramentas de depuração para ajudá-lo a ajustar seu código. Ele também se integra com controle de versão e execução agendada com Lakeflow Jobs. Assim, você pode realizar todas as tarefas relacionadas ao seu pipeline a partir de uma única interface.
Ao consolidar todas essas capacidades em uma única interface semelhante a um IDE, o editor permite as práticas e a produtividade que os engenheiros de dados esperam de um IDE moderno, ao mesmo tempo em que permanece fiel ao paradigma declarativo.
O vídeo incorporado abaixo mostra esses recursos em ação, com mais detalhes abordados nas seções seguintes.
"O novo editor traz tudo para um só lugar - código, grafo do pipeline, resultados, configuração e solução de problemas. Chega de alternar abas do navegador ou perder o contexto. O desenvolvimento parece mais focado e eficiente. Posso ver diretamente o impacto de cada alteração de código. Um clique me leva à linha de erro exata, o que torna a depuração mais rápida. Tudo se conecta - código a dados; código a tabelas; tabelas ao código. Alternar entre pipelines é fácil, e recursos como pastas de utilitários pré-configuradas removem a complexidade. Isso parece a forma como o desenvolvimento de pipelines deveria funcionar."—Chris Sharratt, Engenheiro de Dados, Rolls-Royce
"Na minha opinião, o novo Editor de Pipelines é uma grande melhoria. Acho muito mais fácil gerenciar estruturas de pastas complexas e alternar entre arquivos graças à experiência de abas multi-soft. A visualização DAG integrada realmente me ajuda a acompanhar pipelines intrincados, e o tratamento aprimorado de erros é um divisor de águas - ele me ajuda a identificar problemas rapidamente e otimiza meu fluxo de trabalho de desenvolvimento."—Matt Adams, Desenvolvedor Sênior de Plataformas de Dados, PacificSource Health Plans
Facilidade para começar
Projetamos o editor para que mesmo usuários novos no paradigma declarativo possam construir rapidamente seu primeiro pipeline.
- Configuração guiada permite que novos usuários comecem com código de exemplo, enquanto usuários existentes podem configurar configurações avançadas, como pipelines com CI/CD integrado via Databricks Asset Bundles.
- Estruturas de pastas sugeridas fornecem um ponto de partida para organizar ativos sem impor convenções rígidas, para que as equipes também possam implementar seus próprios padrões organizacionais estabelecidos. Por exemplo, você pode agrupar transformações em pastas para cada estágio do medallion, com um conjunto de dados por arquivo.
- Configurações padrão permitem que os usuários escrevam e executem seu primeiro código sem uma grande sobrecarga de configuração inicial, e ajustem as configurações mais tarde, uma vez que sua carga de trabalho de ponta a ponta seja definida.
Esses recursos ajudam os usuários a se tornarem produtivos rapidamente e a transicionar seu trabalho para pipelines prontos para produção.
Eficiência no loop de desenvolvimento interno
Construir pipelines é um processo iterativo. O editor otimiza esse processo com recursos que simplificam a criação e tornam mais rápido testar e refinar a lógica:
- Geração de código com IA e modelos de código aceleram as definições de conjuntos de dados e restrições de qualidade de dados, e removem etapas repetitivas.
- Execução seletiva permite que você execute uma única tabela, todas as tabelas em um arquivo ou o pipeline inteiro.
- Grafo interativo do pipeline fornece uma visão geral das dependências do conjunto de dados e oferece ações rápidas como visualizações de dados, reexecuções, navegação para o código ou adição de novos conjuntos de dados com boilerplate gerado automaticamente.
- Visualizações de dados integradas permitem inspecionar os dados da tabela sem sair do editor.
- Erros contextuais aparecem ao lado do código relevante, com sugestões de correções do Databricks Assistant.
- Painéis de insights de execução exibem métricas do conjunto de dados, expectativas, desempenho da consulta, com acesso a perfis de consulta para ajuste de desempenho.
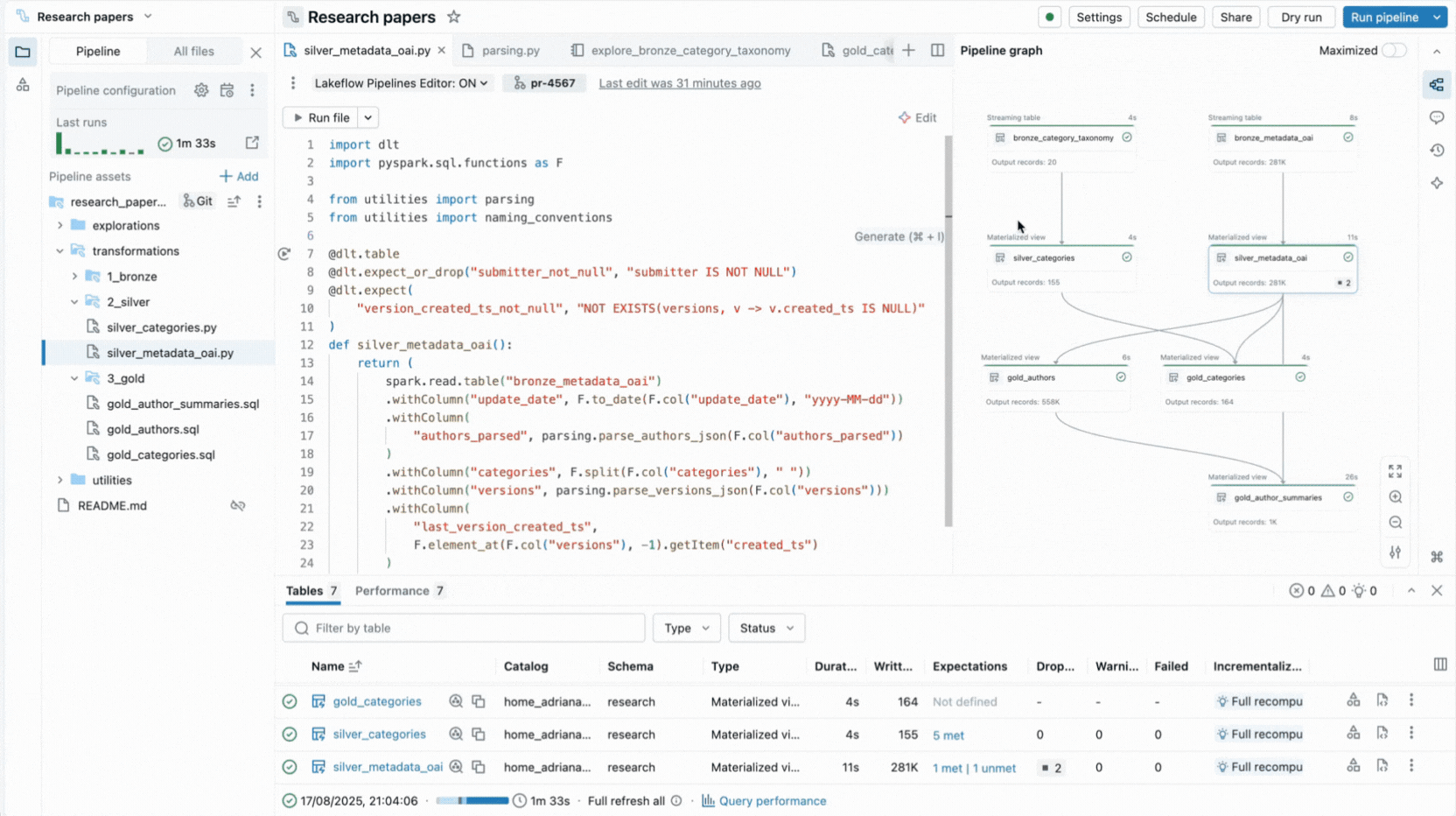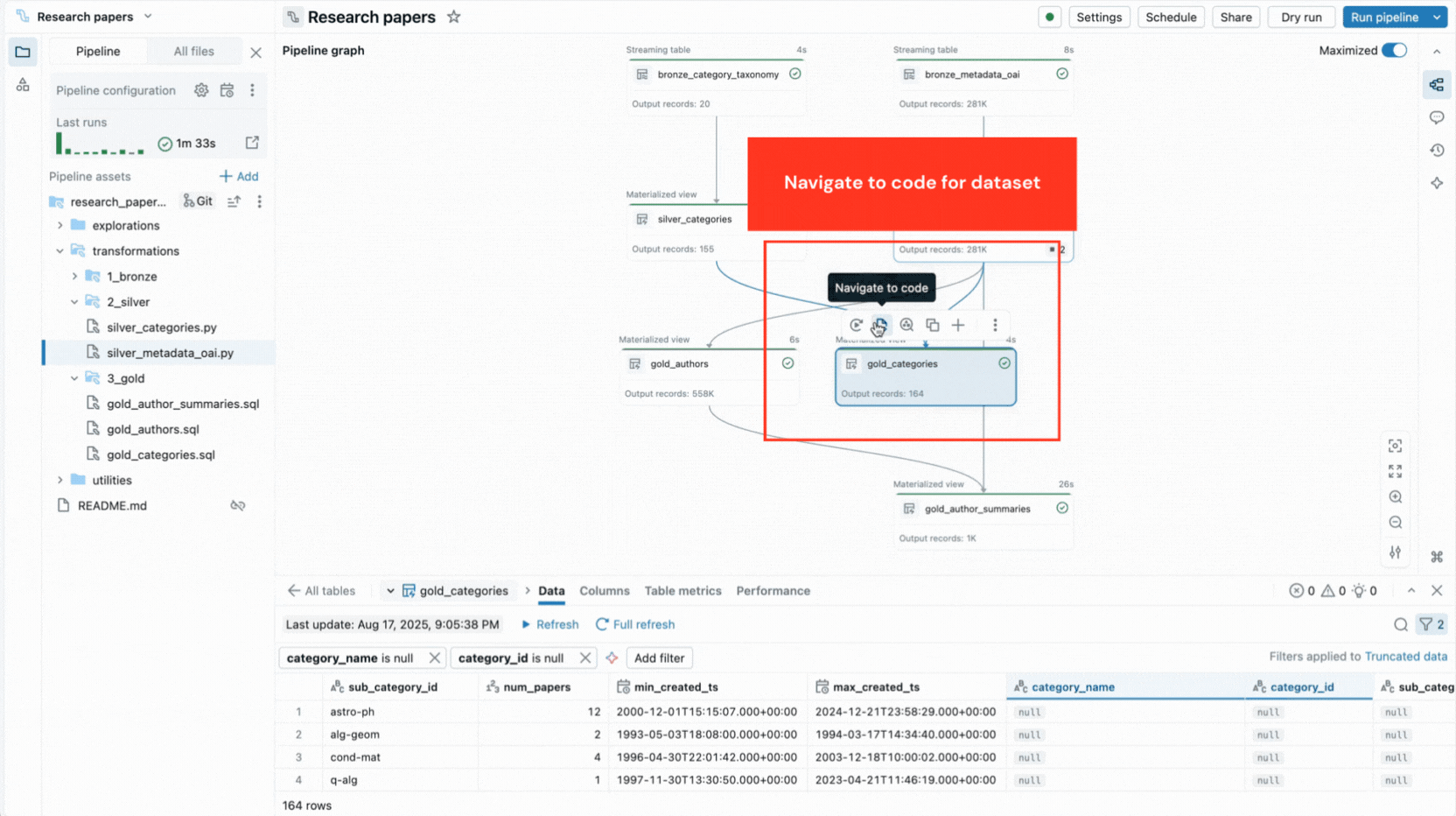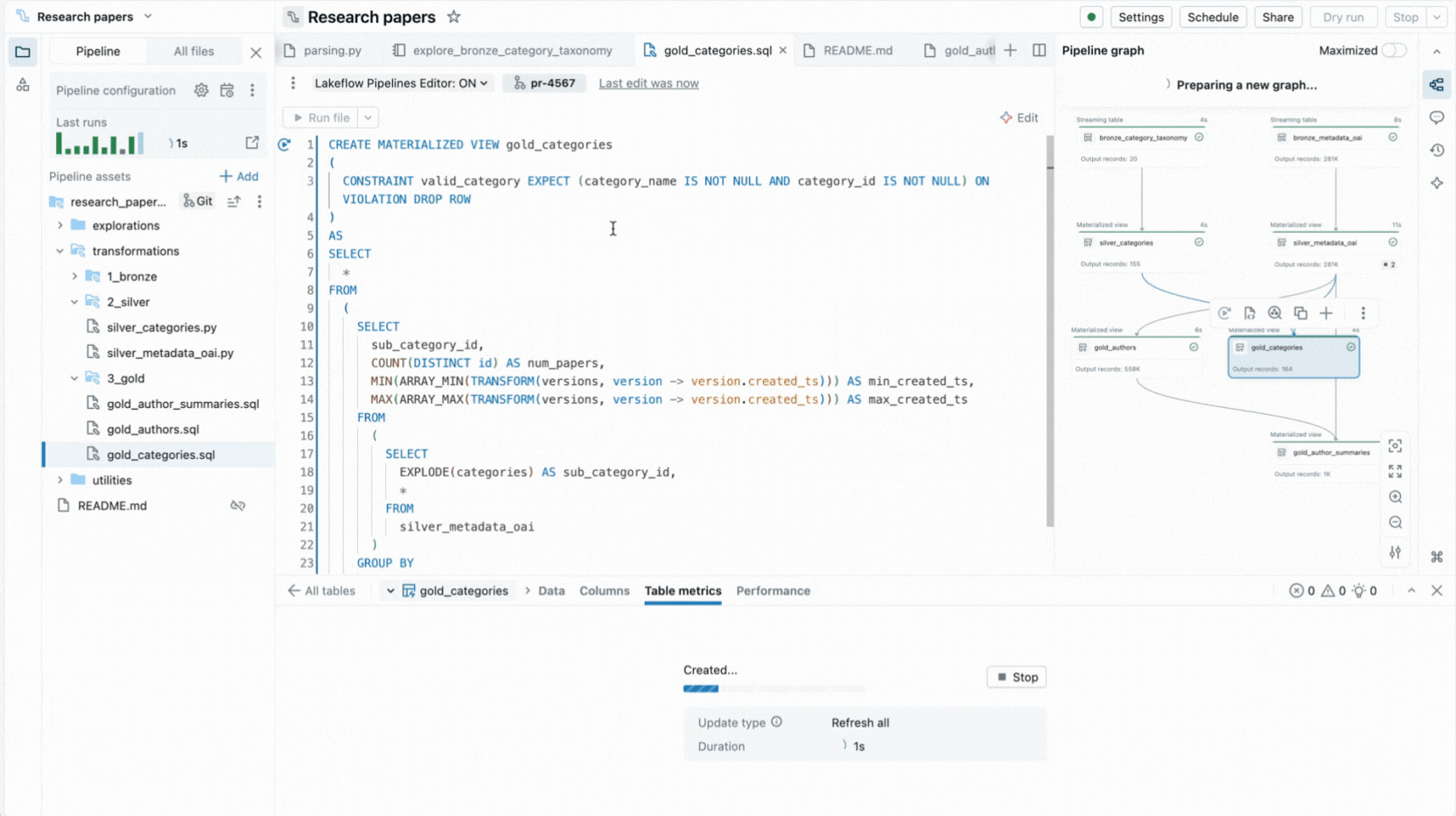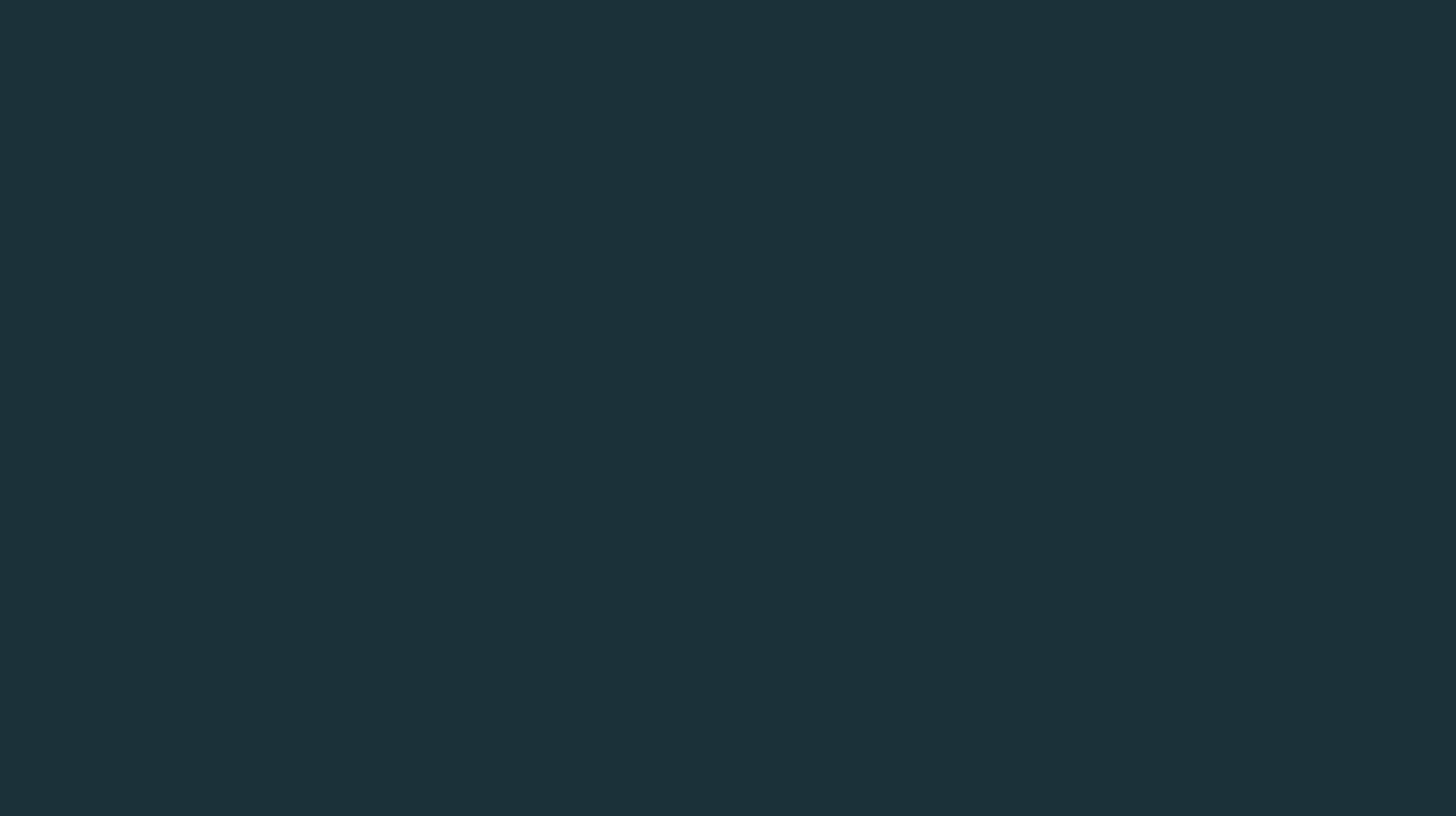
Essas capacidades reduzem a troca de contexto e mantêm os desenvolvedores focados na construção da lógica do pipeline.
Uma única interface para todas as tarefas
O desenvolvimento de pipelines envolve mais do que escrever código. A nova experiência do desenvolvedor traz todas as tarefas relacionadas para uma única interface, desde a modularização do código para manutenibilidade até a configuração de automação e observabilidade:
- Organize código adjacente, como notebooks exploratórios ou módulos Python reutilizáveis, em pastas dedicadas, edite arquivos em várias abas e execute-os separadamente da lógica do pipeline. Isso mantém o código relacionado descoberto e seu pipeline organizado.
- Controle de versão integrado via pastas Git permite trabalho seguro e isolado, revisões de código e pull requests para repositórios compartilhados.
- CI/CD com suporte Databricks Asset Bundles para pipelines conecta o desenvolvimento do loop interno à implantação. Administradores de dados podem impor testes e automatizar a promoção para produção usando modelos e arquivos de configuração, tudo sem adicionar complexidade ao fluxo de trabalho de um praticante de dados.
- Automação e observabilidade integradas permitem a execução agendada de pipelines e fornecem acesso rápido a execuções passadas para monitoramento e solução de problemas.
Ao unificar essas capacidades, o editor otimiza tanto o desenvolvimento diário quanto as operações de pipeline de longo prazo.
Confira o vídeo abaixo para mais detalhes sobre todos esses recursos em ação.
Próximos passos
Não vamos parar por aqui. Aqui está uma prévia do que estamos explorando atualmente:
- Suporte nativo para testes de dados em Lakeflow Spark Declarative Pipelines e test runners no editor
- Geração de testes assistida por IA para acelerar a validação
- Experiência de agente para Lakeflow Spark Declarative Pipelines.
Informe-nos o que mais você gostaria de ver - seu feedback impulsiona o que construímos.
Comece hoje com a nova experiência de desenvolvedor
O IDE para engenharia de dados está disponível em todas as nuvens. Para ativá-lo, abra um arquivo associado a um pipeline existente, clique no banner ‘Lakeflow Pipelines Editor: OFF’ e ative-o. Você também pode ativá-lo durante a criação do pipeline com um alternador semelhante, ou na página Configurações do Usuário.
Saiba mais usando estes recursos:
- Confira a documentação.
- Assista à palestra Authoring Data Pipelines With the New Editor no Data + AI Summit 2025.
- Confira Lakeflow in Production: CI/CD, Testing and Monitoring at Scale no Data + AI Summit 2025.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.