A Próxima Era do Lakehouse Aberto: Apache Iceberg™ v3 em Visualização Pública no Databricks
Desempenho total. Interoperabilidade total. Sem trade-offs.
por Ryan Blue, Daniel Weeks, Jason Reid, Benjamin Mathew e Hao Jiang
• Unity Catalog é o hub central do seu ecossistema Iceberg - não importa quais motores ou catálogos sua equipe use, todas as ferramentas leem os mesmos dados com governança consistente e granular
• Iceberg v3 introduz Row Lineage, Deletion Vectors e VARIANT, permitindo processamento incremental de alto desempenho e cargas de trabalho com dados semiestruturados
• Iceberg v3 encerra o trade-off entre desempenho e interoperabilidade: Deletion Vectors, Row Lineage e VARIANT fazem parte da especificação aberta, portanto, as equipes de dados obtêm esses ganhos de desempenho sem sacrificar a compatibilidade entre motores
Hoje, o suporte do Databricks ao Iceberg v3 entra em Visualização Pública, liberando as inovações mais recentes da comunidade Iceberg nativamente no lakehouse aberto.
O Iceberg v3 marca um grande avanço para formatos de tabela abertos, liberando casos de uso em processamento incremental de dados e análise de dados semiestruturados que anteriormente exigiam soluções alternativas frágeis. Além disso, o Iceberg v3 representa uma inovação tecnológica significativa ao unificar ainda mais a camada de dados do Iceberg e do Delta Lake, eliminando a necessidade de reescrever dados ao construir pipelines interoperáveis.
Veja o que há de novo no Iceberg v3, por que isso importa e por que o Databricks é o melhor lugar para executar seu lakehouse.
O que há de novo no Iceberg v3?
As tabelas Iceberg v3 gerenciadas pelo Unity Catalog suportam Row Lineage, Deletion Vectors e VARIANT, liberando novos casos de uso e benefícios de desempenho significativos. O Databricks também pode interoperar com esses recursos em tabelas Iceberg externas (tabelas Iceberg registradas em outros catálogos), permitindo que os clientes criem agentes e aplicativos de IA contra seus dados, independentemente de onde eles residem.
Processamento Incremental em Escala: Row Lineage e Deletion Vectors
A maioria dos dados chega como um fluxo de alterações (INSERTs, UPDATEs, MERGEs, DELETEs) em vez de em lotes, tipicamente originados de bancos de dados operacionais, fluxos de eventos e APIs de terceiros. Historicamente, o processamento dessas alterações exigia a solução de dois problemas difíceis:
- Identificar quais linhas foram alteradas em conjuntos de dados bronze
- Aplicar essas alterações eficientemente a conjuntos de dados silver/gold
As equipes geralmente recorriam a varreduras completas de tabelas ou sistemas externos de CDC para detectar alterações e reescritas de arquivos caras para aplicá-las. Isso resultou em pipelines lentos, caros de manter e propensos a desvios e silos de dados.
Agora, o row lineage permite que as equipes identifiquem rapidamente quais linhas foram alteradas. Cada linha em uma tabela Iceberg v3 carrega um ID de linha permanente e um número de sequência que reflete quando a linha foi modificada pela última vez.
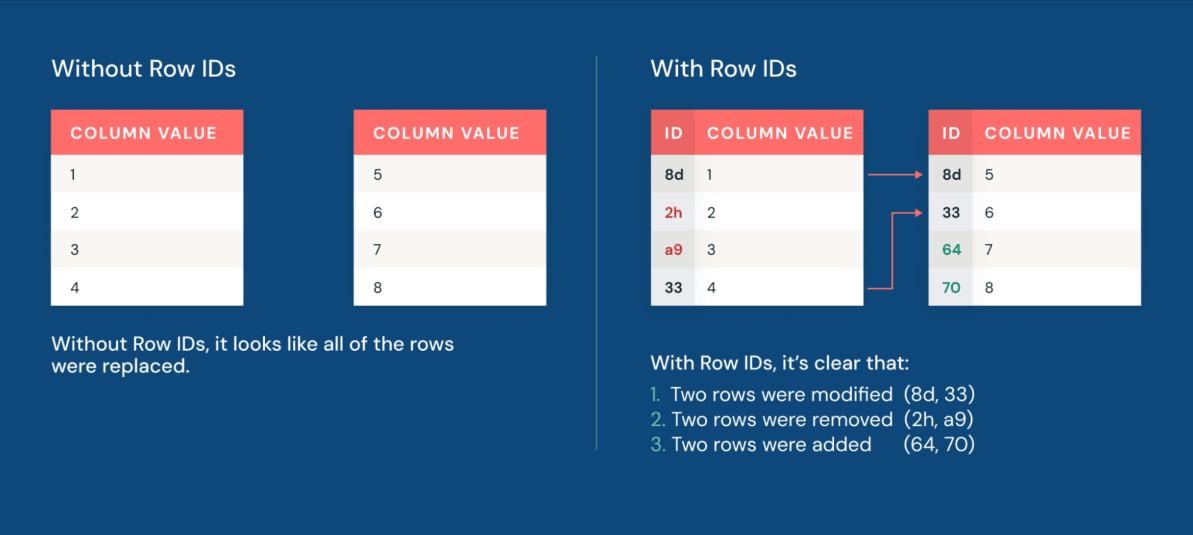
Além disso, os deletion vectors tornam a aplicação de alterações em conjuntos de dados mais performática do que nunca. Os deletion vectors permitem que o Iceberg rastreie quais linhas foram logicamente excluídas sem reescrever imediatamente os arquivos de dados subjacentes. Em vez de excluir fisicamente linhas reescrevendo grandes arquivos Parquet, o mecanismo grava um arquivo de exclusão leve ao lado dos dados. O resultado é um desempenho de manipulação de dados até 10x mais rápido do que a abordagem tradicional de copy-on-write.

Com os Deletion Vectors agora nativos do Iceberg, a Geodis pode construir seu Iceberg Lakehouse no Databricks sem comprometer o desempenho ou a escolha do motor.
“Agora que os Deletion Vectors chegaram ao Iceberg, podemos centralizar nosso parque de dados Iceberg no Unity Catalog, ao mesmo tempo em que aproveitamos o motor de nossa escolha e mantemos o melhor desempenho da categoria.” —Delio Amato, Arquiteto Chefe e Diretor de Dados, Geodis
Juntos, row lineage e deletion vectors tornam o CDC uma propriedade nativa da própria tabela. As equipes podem construir pipelines que se concentram no processamento incremental de apenas o que realmente mudou, reduzindo custos e acelerando o tempo de obtenção de insights para cada analista e cientista de dados a jusante.

Dados Semiestruturados como Cidadãos de Primeira Classe via VARIANT
Logs, respostas de API, clickstreams e cargas úteis de IoT são fontes de dados semiestruturados muito valiosas. À medida que evoluem, os modelos de IA podem se adaptar junto com eles, aprendendo diretamente com os sinais em mudança do mundo real.
No entanto, historicamente, as equipes de dados enfrentavam um trade-off doloroso ao trabalhar com dados semiestruturados. Uma abordagem padrão era impor esquemas rígidos, mas isso levava a pipelines frágeis que quebravam toda vez que os dados upstream evoluíam. Outra solução alternativa canônica era armazenar os dados como dumps de strings brutos, mas isso tornava as consultas muito complexas e lentas. Nenhuma das abordagens era escalável.
O tipo VARIANT do Iceberg v3 resolve esse trade-off. VARIANT é um tipo de coluna nativo que armazena cargas úteis semiestruturadas ao lado de colunas relacionais na mesma tabela Iceberg. Isso não requer nenhum achatamento, armazenamento em um sistema separado ou um pipeline de ETL para normalização. Em vez disso, as equipes de dados podem ingerir dados semiestruturados brutos como estão e consultá-los com SQL padrão.

O Panther usa VARIANT para potencializar a ingestão e análise em larga escala de logs de segurança semiestruturados.
“O Unity Catalog e o Iceberg v3 liberam o poder dos dados semiestruturados por meio do VARIANT. Isso permite interoperabilidade e coleta de logs em escala de petabytes, com bom custo-benefício.” —Russell Leighton, Arquiteto Chefe, Panther
Com VARIANT, seus modelos de IA e pipelines de análise funcionam diretamente contra dados ao vivo e em evolução em uma única tabela governada. Quando novos campos aparecem em respostas de API ou novos tipos de eventos entram em clickstreams, eles são consultáveis imediatamente sem uma migração de esquema. Com otimizações de desempenho como shredding, os clientes podem se beneficiar do desempenho semelhante ao colunar em seus dados semiestruturados, liberando BI de baixa latência, dashboards e pipelines de alerta.
O Unity Catalog oferece interoperabilidade e desempenho para empresas multi-engine e multi-catalog
Empresas modernas dependem de vários motores e catálogos para suportar diversos casos de uso em unidades de negócios e sistemas legados. O Unity Catalog foi projetado para permitir a interoperabilidade e a governança entre catálogos, ao mesmo tempo em que otimiza os layouts de dados com base nos padrões de consulta.
Governança unificada entre catálogos e motores
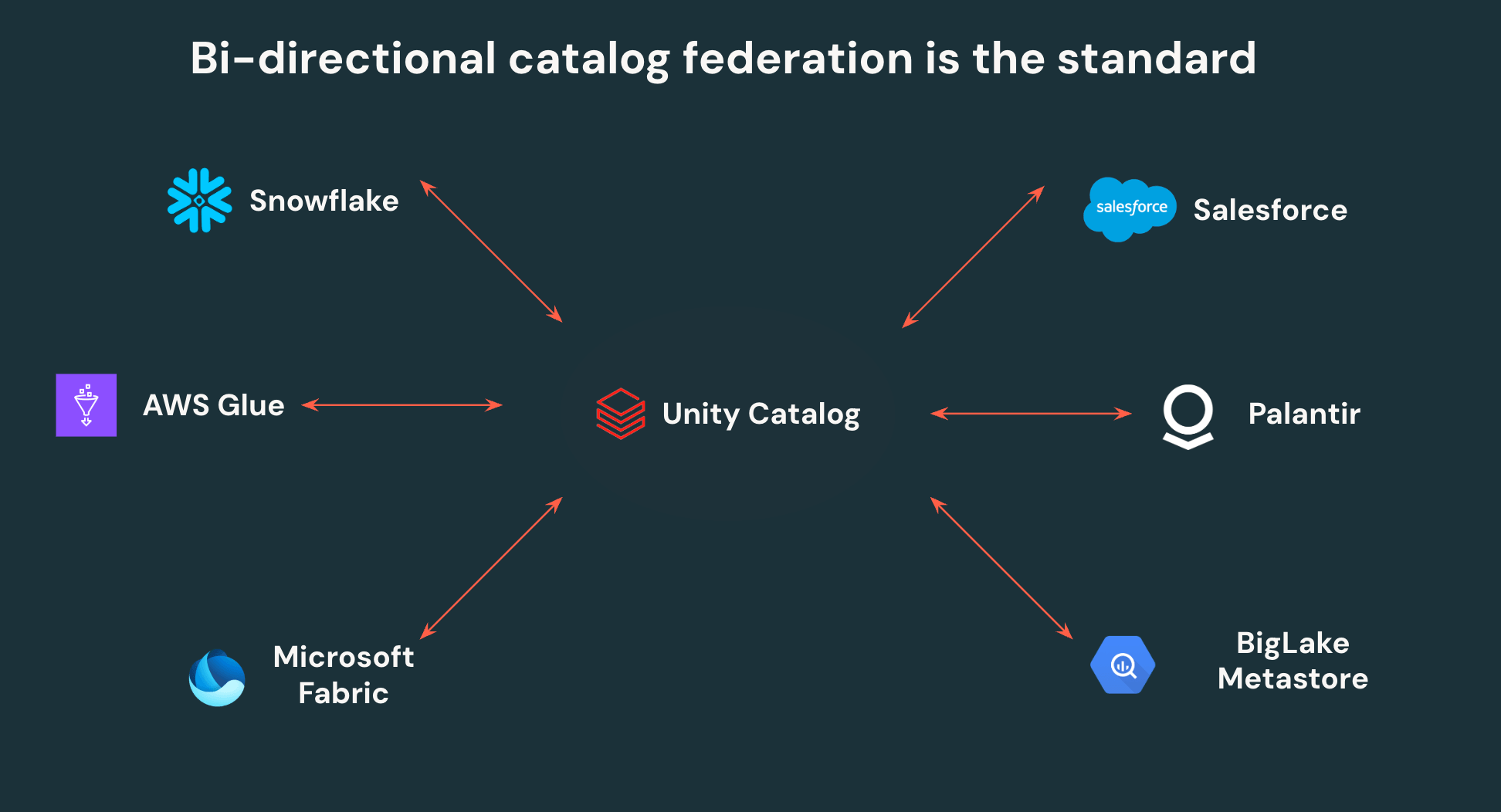
As APIs abertas do Unity Catalog permitem que os clientes escrevam uma vez e leiam em qualquer lugar - sem mais duplicação de dados ou controles de acesso isolados. O UC pode federar para outros catálogos Iceberg, permitindo interoperabilidade bidirecional. Todos os dados Iceberg em Snowflake, AWS Glue, Salesforce e outros catálogos importantes podem ser lidos pelo Unity Catalog, e todos os dados no UC podem ser acessados por essas mesmas plataformas de terceiros por meio de APIs abertas.
Além disso, o Unity Catalog é o primeiro catálogo a suportar controle de acesso granular em motores externos, capacitando as equipes a definir filtros de linha e máscaras de coluna uma vez e tê-los aplicados em todos os lugares onde os dados são acessados. Centralizar a governança no Unity Catalog torna significativamente mais fácil para as equipes de segurança governar e monitorar seu lakehouse, ao mesmo tempo em que dá às equipes de dados autonomia para apontar qualquer ferramenta para seu lakehouse.

Interoperabilidade Delta e Iceberg
O Delta Lake com UniForm libera a interoperabilidade entre os ecossistemas Delta Lake e Iceberg dos clientes: escreva uma vez no Delta Lake e leia como Iceberg do Snowflake, BigQuery, Redshift, Athena, Trino ou qualquer outro motor Iceberg. Com o Iceberg v3 adotando Deletion Vectors, Row Lineage e VARIANT nativamente, os clientes não enfrentam mais um trade-off entre os recursos de desempenho do Delta Lake e a compatibilidade com o Iceberg. O resultado é uma única cópia de dados que atende a todos os motores em sua pilha, sem pipelines de replicação para manter ou risco de desvio. Um provedor líder de serviços financeiros substituiu um serviço caro de replicação de tabela completa pelo UniForm, permitindo que o Snowflake lesse diretamente das tabelas gerenciadas pelo Unity Catalog.
Desempenho e otimização automatizados
Além da interoperabilidade, a Databricks reúne desempenho, otimização de layout e governança em um único sistema para que as equipes não precisem juntar essas capacidades por conta própria. A Databricks combina manutenção inteligente (Otimização Preditiva), otimizações de layout físico baseadas em padrões de consulta (Clusterização Líquida Automática) e governança entre mecanismos (Unity Catalog) em uma única camada, sem necessidade de configuração manual.
Outras ofertas gerenciadas de Iceberg exigem que as equipes gerenciem a manutenção de tabelas, o layout de arquivos e a aplicação de políticas de acesso de forma independente. Na Databricks, essas capacidades são unificadas e automáticas, removendo toda uma classe de sobrecarga operacional e, ao mesmo tempo, preservando a portabilidade total dos dados.
Comece com o Apache Iceberg v3 na Databricks
Iceberg v3 na Databricks está em Preview Público hoje! As equipes agora podem aproveitar os melhores recursos do Delta e do Iceberg sem abrir mão de desempenho ou interoperabilidade.
O Iceberg v3 está disponível no Databricks Runtime 18.0+ com o Unity Catalog habilitado.
Criar uma tabela Iceberg gerenciada pelo Unity Catalog com o v3 habilitado é fácil:
Criar uma tabela Delta gerenciada pelo Unity Catalog com UniForm e v3 habilitado é igualmente simples:
Olhando para o futuro: Iceberg v4
O Iceberg v3 unifica a camada de dados entre Delta e Iceberg em uma base performática e interoperável – a próxima fronteira é a camada de metadados. Engenheiros da Databricks estão impulsionando ativamente várias propostas centrais do Iceberg v4 na comunidade Apache para tornar os metadados mais simples, rápidos e escaláveis. Isso inclui a árvore de metadados adaptativa, que simplifica a estrutura de metadados para que a maioria das operações exija a escrita de apenas um arquivo em vez de vários. Propostas adicionais incluem suporte a caminhos relativos para realocação contínua de tabelas entre ambientes e um modelo de estatísticas modernizado que se estende a tipos de dados mais recentes como VARIANT e GEOMETRY. Juntos, esses avanços significarão ingestão mais rápida, planejamento de consulta mais eficiente e gerenciamento de tabelas mais simples em escala empresarial. Estamos animados para continuar avançando a especificação do Iceberg com a comunidade.
Saiba mais no Data and AI Summit
Comece com o Iceberg v3 e junte-se a nós no próximo Data and AI Summit em São Francisco, de 15 a 18 de junho de 2026, para saber mais sobre nosso roteiro do Iceberg e o trabalho em todo o ecossistema.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.