The next era of the open lakehouse: Apache Iceberg™ v3 in Public Preview on Databricks
Full performance. Full interoperability. No tradeoffs.
by Ryan Blue, Daniel Weeks, Jason Reid, Benjamin Mathew and Hao Jiang
• Unity Catalog is the central hub of your Iceberg ecosystem - no matter which engines or catalogs your team uses, every tool reads the same data with consistent, fine-grained governance
• Iceberg v3 introduces Row Lineage, Deletion Vectors, and VARIANT, enabling high-performance incremental processing and semi-structured data workloads
• Iceberg v3 ends the performance vs. interoperability tradeoff: Deletion Vectors, Row Lineage, and VARIANT are part of the open specification, so data teams get these performance gains without sacrificing cross-engine compatibility
Today, Databricks’s support of Iceberg v3 enters Public Preview, unlocking the latest innovations from the Iceberg community natively on the open lakehouse.
Iceberg v3 marks a major step forward for open table formats, unlocking use cases across incremental data processing and semi-structured data analysis which previously required brittle workarounds. Beyond this, Iceberg v3 represents a significant technological innovation by further unifying the data layer of Iceberg and Delta Lake, eliminating the need to rewrite data when building interoperable pipelines.
Here’s what’s new in Iceberg v3, why it matters, and why Databricks is the best place to run your lakehouse.
What’s new in Iceberg v3?
Unity Catalog Managed Iceberg v3 tables support Row Lineage, Deletion Vectors, and VARIANT, unlocking new use cases and significant performance benefits. Databricks can also interoperate with these features on foreign Iceberg tables (Iceberg tables registered in other catalogs), enabling customers to build agents and AI applications against their data, regardless of where it lives.
Incremental Processing at Scale: Row Lineage and Deletion Vectors
Most data arrives as a stream of changes (INSERTs, UPDATEs, MERGEs, DELETEs) rather than in batches, typically sourced from operational databases, event streams, and third-party APIs. Historically, processing these changes required solving two hard problems:
- Identifying which rows changed in bronze datasets
- Applying those changes efficiently to silver/gold datasets
Teams usually resorted to full table scans or external CDC systems to detect changes, and expensive file rewrites to apply them. This resulted in pipelines that were slow, costly to maintain, and prone to drift and data silos.
Now, row lineage allows teams to quickly identify which rows changed. Every row in an Iceberg v3 table carries a permanent row ID and a sequence number reflecting when the row was last modified.
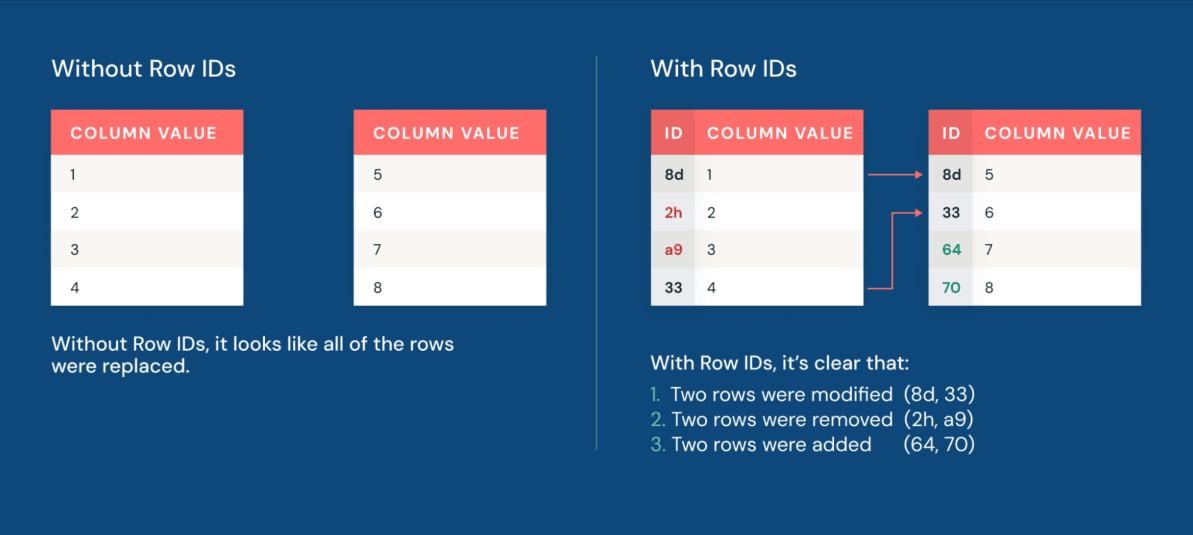
Additionally, deletion vectors make applying changes to datasets more performant than ever. Deletion vectors allow Iceberg to track which rows have been logically deleted without immediately rewriting the underlying data files. Instead of physically deleting rows by rewriting large Parquet files, the engine writes a lightweight delete file alongside the data. The result is data manipulation performance that is up to 10x faster than the traditional copy-on-write approach.

With Deletion Vectors now native to Iceberg, Geodis can build its Iceberg Lakehouse on Databricks without compromising performance or engine choice.
“Now that Deletion Vectors have come to Iceberg, we can centralize our Iceberg data estate in Unity Catalog, while leveraging the engine of our choice and maintaining best-in-class performance.” —Delio Amato, Chief Architect & Data Officer, Geodis
Together, row lineage and deletion vectors make CDC a native property of the table itself. Teams can build pipelines that focus on incrementally processing only what actually changed, cutting costs and driving faster time-to-insight for every analyst and data scientist downstream.

Semi-Structured Data as a First-Class Citizen via VARIANT
Logs, API responses, clickstreams, and IoT payloads are very valuable semi-structured data sources. As they evolve, AI models can adapt alongside them, learning directly from changing real-world signals.
However, historically, data teams faced a painful tradeoff when working with semi-structured data. One standard approach was to enforce rigid schemas, but this led to brittle pipelines that broke every time the upstream data evolved. Another canonical workaround was to store the data as raw string dumps, but this made queries very complex and slow. Neither approach was scalable.
The Iceberg v3 VARIANT type resolves this tradeoff. VARIANT is a native column type that stores semi-structured payloads alongside relational columns in the same Iceberg table. This does not require any flattening, storage in a separate system, or an ETL pipeline for normalization. Rather, data teams can ingest raw semi-structured data as-is and query it with standard SQL.

Panther uses VARIANT to power large-scale ingestion and analytics across semi-structured security logs.
"Unity Catalog and Iceberg v3 unlock the power of semi-structured data through VARIANT. This enables interoperability and cost-effective, petabyte-scale log collection." —Russell Leighton, Chief Architect, Panther
With VARIANT, your AI models and analytics pipelines work directly against live, evolving data in a single governed table. When new fields appear in API responses or new event types enter clickstreams, they are queryable immediately without a schema migration. With performance optimizations like shredding, customers can benefit from columnar-like performance on their semi-structured data, unlocking low-latency BI, dashboards, and alerting pipelines.
Unity Catalog delivers interoperability and performance for multi-engine, multi-catalog enterprises
Modern enterprises rely on multiple engines and catalogs to support diverse use cases across business units and legacy systems. Unity Catalog was designed to enable interoperability and governance across catalogs, while also optimizing data layouts based on query patterns.
Unified governance across catalogs and engines
Unity Catalog's open APIs allow customers to write once and read anywhere - no more data duplication or siloed access controls. UC can federate to other Iceberg catalogs, enabling bi-directional interoperability. All Iceberg data in Snowflake, AWS Glue, Salesforce, and other major catalogs, can be read by Unity Catalog, and all data in UC can be accessed by those same third party platforms via open APIs.
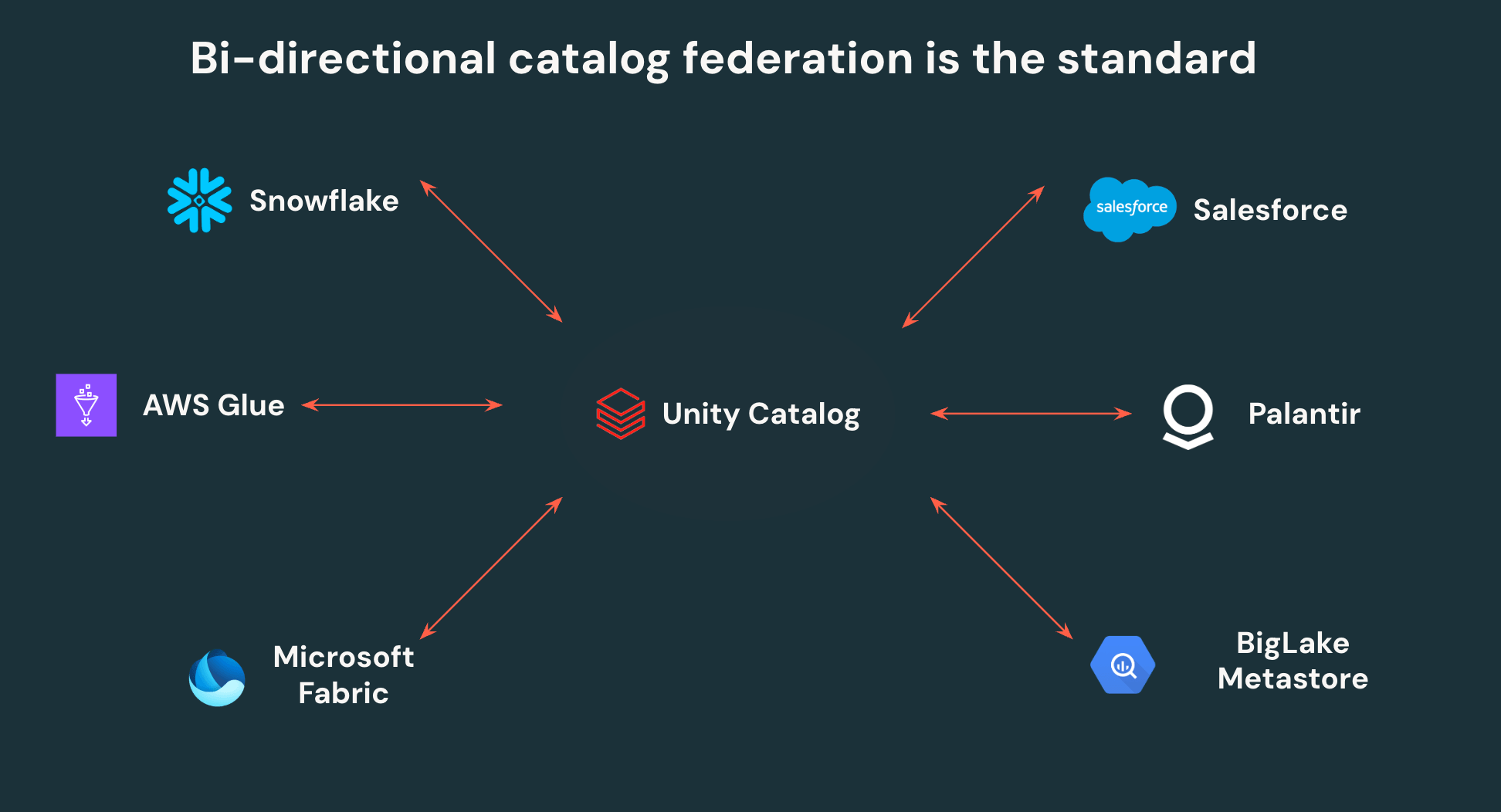
Beyond this, Unity Catalog is the first catalog to support fine-grained access control on external engines, empowering teams to define row filters and column masks once and have them enforced everywhere data is accessed. Centralizing governance on Unity Catalog makes it significantly easier for security teams to govern and monitor their lakehouse, while also giving data teams autonomy to point any tool at their lakehouse.

Delta and Iceberg interoperability
Delta Lake with UniForm unlocks interoperability across customers' Delta Lake and Iceberg ecosystems: write once to Delta Lake, and read as Iceberg from Snowflake, BigQuery, Redshift, Athena, Trino, or any other Iceberg engine. With Iceberg v3 adopting Deletion Vectors, Row Lineage, and VARIANT natively, customers no longer face a tradeoff between Delta Lake performance features and Iceberg compatibility. The result is a single copy of data that serves every engine in your stack, with no replication pipelines to maintain or risk of drift. A leading financial services provider replaced a costly full-table replication service with UniForm, letting Snowflake read directly from Unity Catalog managed tables.
Automated performance and optimization
Beyond interoperability, Databricks brings performance, layout optimization, and governance together in a single system so teams don’t have to stitch these capabilities together themselves. Databricks combines intelligent maintenance (Predictive Optimization), physical layout optimizations based on query patterns (Automatic Liquid Clustering), and cross-engine governance (Unity Catalog) in one layer, with no manual configuration required.
Other managed Iceberg offerings require teams to manage table maintenance, file layout, and access policy enforcement independently. On Databricks, these capabilities are unified and automatic, removing a whole class of operational overhead while also preserving full data portability.
Get Started with Apache Iceberg v3 on Databricks
Iceberg v3 on Databricks is Public Preview today! Teams can now take advantage of the best features across Delta and Iceberg without trading off between performance and interoperability.
Iceberg v3 is available on Databricks Runtime 18.0+ with Unity Catalog enabled.
Creating a Unity Catalog managed Iceberg table with v3 enabled is easy:
Creating a Unity Catalog managed Delta table with UniForm and v3 enabled is just as simple:
Looking ahead: Iceberg v4
Iceberg v3 unifies the data layer across Delta and Iceberg on a performant, interoperable foundation – the next frontier is the metadata layer. Databricks engineers are actively driving several core Iceberg v4 proposals in the Apache community to make metadata simpler, faster and more scalable. These include the adaptive metadata tree, which simplifies the metadata structure so that most operations require writing only a single file instead of several. Additional proposals include relative path support for seamless table relocation across environments and a modernized statistics model that extends to newer data types like VARIANT and GEOMETRY. Together, these advancements will mean faster ingestion, more efficient query planning, and simpler table management at enterprise scale. We're excited to continue advancing the Iceberg specification with the community.
Learn more at Data and AI Summit
Get started with Iceberg v3 and join us at the upcoming Data and AI Summit in San Francisco, June 15-18, 2026, to learn more about our Iceberg roadmap and work across the ecosystem.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.