Plataforma Aberta, Pipelines Unificados: Por que dbt no Databricks está Acelerando
Execute dbt em um lakehouse aberto e unificado com governança integrada e forte relação custo-benefício
- Fundações abertas evitam o aprisionamento tecnológico. Crie fluxos de trabalho dbt com formatos de tabela abertos e governança de código aberto do Unity Catalog.
- Uma plataforma unificada elimina a proliferação de ferramentas. Execute dbt junto com ingestão e BI em um só lugar com governança e orquestração integradas.
- Obtenha forte desempenho/preço com ajuste mínimo e sobrecarga operacional.
dbt traz estrutura para fluxos de trabalho de transformação de dados. As equipes o utilizam para transformar dados brutos em conjuntos de dados curados que impulsionam o consumo downstream, como dashboards de BI, modelos de IA/ML e relatórios multifuncionais.
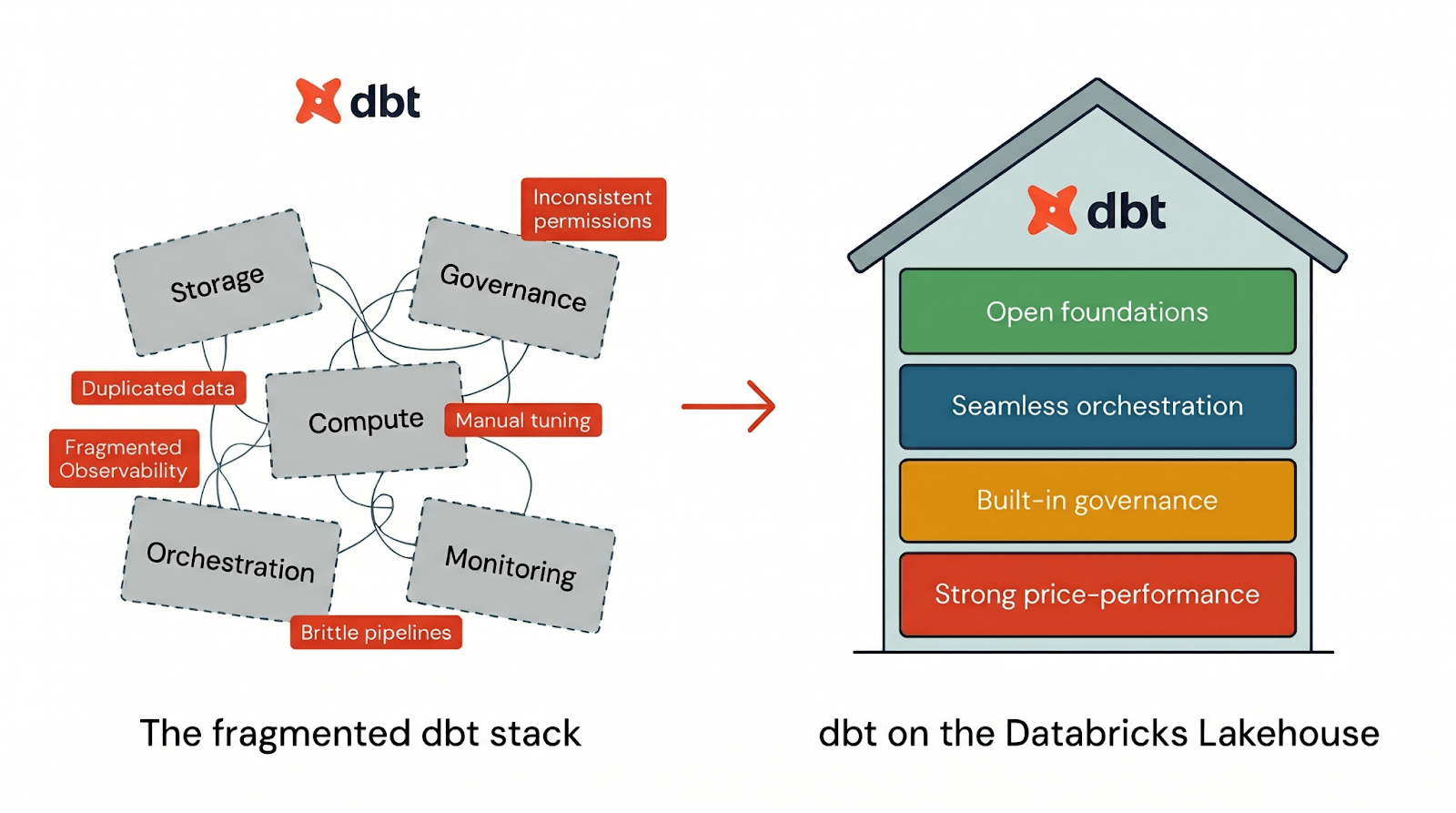
Mas a realidade é: dbt só é tão poderoso quanto a plataforma de dados em que é executado.
A maioria das pilhas de dados força você a juntar armazenamento, computação, governança, orquestração e monitoramento em vários sistemas. O resultado? Dados duplicados, permissões inconsistentes, observabilidade fragmentada e otimização de desempenho que se torna um trabalho de meio período. É por isso que um número crescente de equipes está consolidando seus fluxos de trabalho dbt no Databricks.
Para executar dbt de forma eficaz, uma plataforma precisa de quatro coisas:
- Fundamentos abertos para que seus fluxos de trabalho dbt não fiquem presos a uma pilha proprietária
- Orquestração contínua para executar pipelines dbt de ponta a ponta em um só lugar
- Governança integrada que faz parte do fluxo de trabalho dbt padrão
- Forte relação custo-benefício para que dbt funcione rapidamente desde o primeiro dia, sem ajustes manuais
O Databricks entrega todos os quatro pilares integrados nativamente em uma única plataforma. Quando você executa dbt no Databricks, obtém a experiência do desenvolvedor dbt sobre uma arquitetura de lakehouse projetada para abertura, governança, desempenho e simplicidade operacional desde o primeiro dia. Vamos ver como cada um deles funciona na prática:
Executar dbt no Databricks nos permitiu consolidar um legado disperso de notebooks e mais de 7 sistemas de origem em uma única plataforma de dados governada. Com o Unity Catalog, gerenciamos 341 locatários, múltiplos ambientes e compartilhamento de dados com parceiros externos por meio de isolamento em nível de catálogo. Nossa documentação dbt flui diretamente para o UC, para que os analistas possam autoatender sem gargalos. Ao publicar em formatos abertos e Delta Sharing, parceiros e equipes downstream podem consumir facilmente conjuntos de dados gerados por dbt em diferentes ferramentas e ambientes. É uma plataforma para construir, mas uma plataforma aberta para consumir. —Sohan Chatterjee, Head de Dados e Análise, iSolved
Execute dbt em fundamentos abertos com zero vendor lock-in
O vendor lock-in é um dos riscos estratégicos mais significativos para a estratégia de dados de uma organização. dbt é construído com um framework de adaptador aberto, o que significa que sua lógica de transformação não está presa a uma única plataforma. dbt é aberto por design, e o Databricks fornece uma plataforma aberta para executá-lo. Muitas pilhas de dados modernas se concentram em uma camada de armazenamento proprietária que oferece conveniência de curto prazo, mas introduz atrito de longo prazo. Com o tempo, isso leva a dados duplicados e pipelines de exportação para atender a diferentes consumidores, formatos de armazenamento que limitam a interoperabilidade e custos de troca crescentes à medida que os requisitos da plataforma evoluem.
O Databricks é um lakehouse aberto: uma plataforma unificada onde seus dados residem em formatos de tabela abertos e são acessíveis por meio de interfaces abertas, garantindo que o armazenamento e a governança não estejam vinculados a um único mecanismo de consulta. No Databricks, os modelos dbt se tornam tabelas em formatos abertos, o Delta Lake e o Apache Iceberg, garantindo que seus dados transformados permaneçam acessíveis em toda a paisagem de dados sem exportar ou manter cópias paralelas. Essa abertura é importante especificamente para fluxos de trabalho dbt. Suas tabelas silver e gold cuidadosamente modeladas se tornam produtos de dados reutilizáveis que usuários downstream podem consumir por meio de qualquer mecanismo de consulta, não apenas pela plataforma onde o dbt é executado.
Essa abertura se estende além do armazenamento. O Unity Catalog é construído em torno de padrões abertos de catálogo e acesso que suportam leituras e gravações governadas de mecanismos externos. O Databricks SQL segue os padrões ANSI, garantindo que suas consultas permaneçam portáteis entre plataformas para reduzir regravações específicas do fornecedor. Isso significa que seus fluxos de trabalho dbt são executados em uma pilha projetada para portabilidade, não para lock-in.
Orquestre pipelines dbt de ponta a ponta com Lakeflow Jobs
A orquestração é onde a complexidade operacional se acumula. Emparelhar dbt com um orquestrador externo ao lado do Databricks significa dois sistemas para operar, dois lugares para depurar e interações frágeis entre eles.
O Lakeflow Jobs remove essa complexidade tratando dbt como um tipo de tarefa de primeira classe dentro de um pipeline unificado. Em vez de manter uma camada de orquestração separada, as equipes executam dbt ao lado de ingestão upstream e ações downstream em um único fluxo de trabalho. Por exemplo, você pode ingerir dados brutos com o Auto Loader, transformar dados com modelos dbt e, em seguida, acionar atualizações de dashboard ou retreinamento de ML, tudo em um único pipeline com lógica de repetição e gerenciamento de dependências unificados. dbt no Databricks também permite ingestão diretamente por meio de tabelas de streaming. Para usuários do dbt Platform, a tarefa dbt Platform (em Beta) permite que o Lakeflow acione e gerencie fluxos de trabalho dbt em execução no dbt Platform.
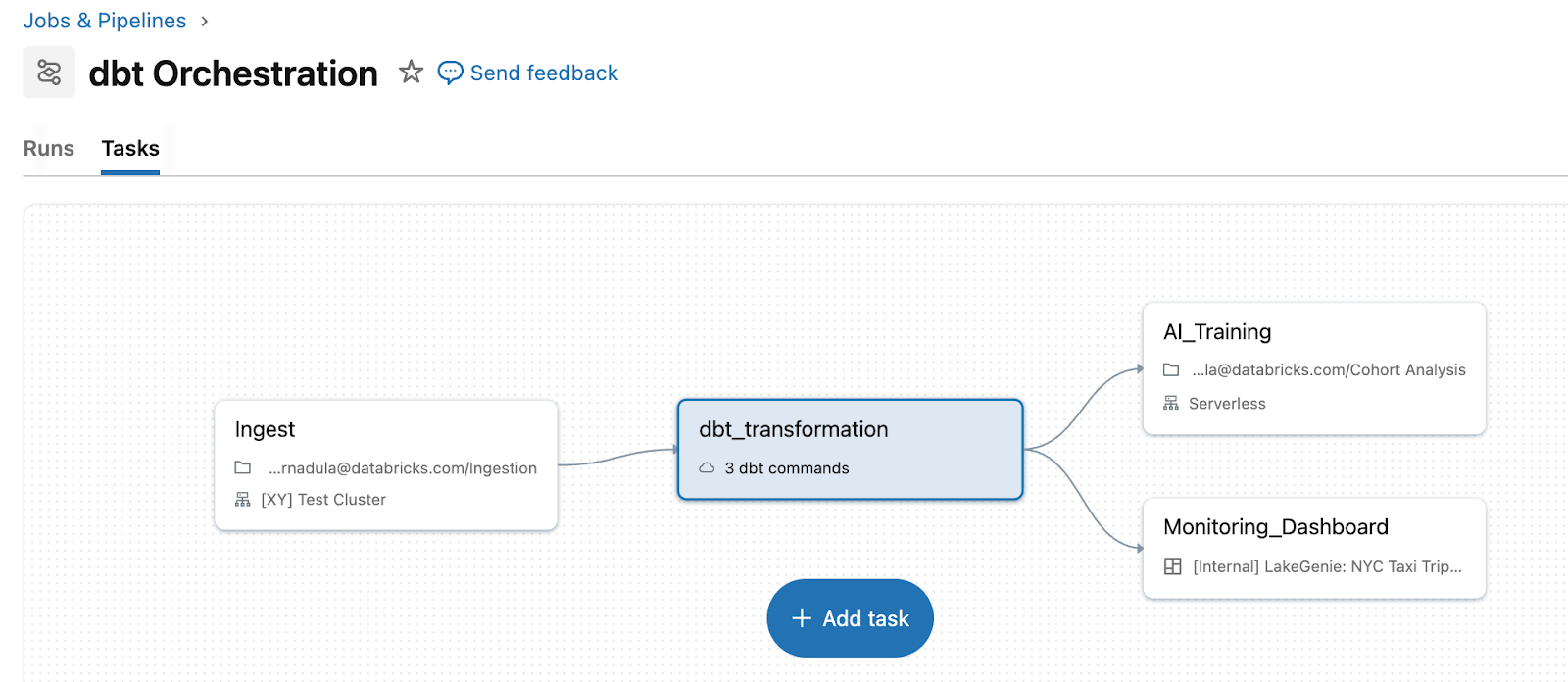
Quando dbt é orquestrado pelo Lakeflow, falhas, repetições e contexto ficam visíveis em um só lugar. Em vez de alternar entre um orquestrador dbt separado e os logs do Databricks, você pode ver a falha, as tarefas downstream afetadas e os dashboards impactados diretamente na mesma visualização de execução do job.
Torne a governança parte do fluxo de trabalho dbt padrão
À medida que os fluxos de trabalho dbt escalam, a governança se torna o gargalo. As equipes precisam de respostas claras sobre o conteúdo das tabelas, propriedade e permissões de acesso. Em pilhas tradicionais, esse contexto é fragmentado entre ferramentas de catálogo separadas, sistemas de permissão e visualizações de linhagem incompletas que não se conectam de ponta a ponta.
O Databricks resolve isso com o Unity Catalog, que unifica controle de acesso, descoberta e linhagem para todo o seu lakehouse – não apenas dentro do dbt, mas em ingestão, BI, ML/AI e além. Com o Unity Catalog, você não precisa executar novamente as instruções de concessão toda vez que o dbt recriar uma tabela. As permissões são gerenciadas no nível do esquema e persistem entre as reconstruções de tabelas. Controles granulares como filtros em nível de linha, máscaras de coluna e controle de acesso baseado em atributos se aplicam consistentemente em dbt, ferramentas de BI e notebooks.
Por exemplo, quando você persiste a documentação dbt no Unity Catalog usando a funcionalidade persist_docs do dbt, as descrições de coluna e o contexto criados no dbt se tornam descobertos onde os dados são consultados e consumidos. O Unity Catalog fornece linhagem de dados em nível de coluna que rastreia o fluxo de dados da ingestão bruta através das transformações dbt até o uso downstream. Quando um esquema de origem muda, você pode ver instantaneamente quais modelos dbt e ativos downstream são afetados. Esse nível de visibilidade é impossível quando os pipelines de dados abrangem sistemas desconectados.
A governança de custos é tão importante quanto a governança de dados. Com as tags de consulta, você pode anexar contexto de negócios às execuções do dbt e rastrear gastos por equipe, projeto ou ambiente por meio das Tabelas do Sistema. As equipes podem finalmente responder "quanto custam nossos pipelines de dbt de análise de marketing?" com dados reais em vez de estimativas. Além disso, o Monitoramento Granular de Custos do DBSQL (em Preview Privado) também fornece monitoramento de custos agregado em todas as cargas de trabalho do dbt.
Execute o dbt com forte desempenho e preço desde o primeiro dia
Otimizar um data warehouse para desempenho geralmente requer trabalho manual contínuo. As equipes frequentemente acabam trocando a velocidade do desenvolvedor pela higiene de desempenho.
O Databricks abstrai essa complexidade combinando um mecanismo de execução de alto desempenho com recursos que funcionam nativamente com o dbt, oferecendo melhorias de velocidade sem sobrecarga manual.
Desempenho integrado
- Photon, o mecanismo, acelera as cargas de trabalho SQL por meio da execução vetorizada, oferecendo até12x melhor desempenho e preço em comparação com data warehouses em nuvem. Os warehouses SQL sem servidor incluem Photon por padrão, para que as equipes obtenham desempenho acelerado sem custo adicional.
- Otimização Preditiva usa IA para monitorar tabelas e automatizar a manutenção, alcançando até20x consultas mais rápidas. Isso reduz a necessidade de post-hooks OPTIMIZE manuais nos quais os engenheiros de dbt confiavam historicamente.
Recursos de desempenho desbloqueados por meio da configuração do dbt
- A integração do dbt com oLiquid Clustering, que substitui estratégias de particionamento rígidas por uma abordagem flexível que se ajusta dinamicamente à medida que o volume de dados cresce, resultando em até 10x velocidades mais rápidas sem ajuste manual
- Visualizações Materializadas no dbt, alimentadas por pipelines declarativos Spark de código aberto, lidam com processamento incremental automaticamente. O Databricks gerencia a complexidade de determinar o que precisa ser atualizado e processa apenas registros novos ou modificados, em vez de recalcular conjuntos de dados inteiros. Isso oferece custos de computação mais baixos em comparação com atualizações em lote agendadas ineficientes.
Com esses recursos, os usuários gastam menos tempo ajustando e mais tempo construindo pipelines que permanecem performáticos à medida que os conjuntos de dados crescem. Somente em 2025, o Databricks SQL alcançou umamelhora de desempenho de 10% em cargas de trabalho ETL (consultas com gravações) sem a necessidade de configurações adicionais.
Comece hoje mesmo
O Databricks reúne armazenamento aberto, governança unificada, forte desempenho e preço e operações integradas em um só lugar para fluxos de trabalho do dbt. Junte-se a mais de 2900 clientes que já executam o dbt no Databricks. Comece seguindo o guia de início rápido.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.