Open Platform, Unified Pipelines: Why dbt on Databricks is Accelerating
Run dbt on an open, unified lakehouse with built-in governance and strong price-performance
by Srilekha Dornadula and Ramiz Bozai
- Open foundations prevent vendor lock-in. Build dbt workflows with open table formats and open source Unity Catalog governance.
- A unified platform eliminates tool sprawl. Run dbt alongside ingestion and BI in one place with built-in governance and orchestration.
- Get strong price/performance with minimal tuning and operational overhead.
dbt brings structure to data transformation workflows. Teams use it to turn raw data into curated datasets that power downstream consumption like BI dashboards, AI/ML models, and cross-functional reporting.
But here's the reality: dbt is only as powerful as the data platform it runs on.
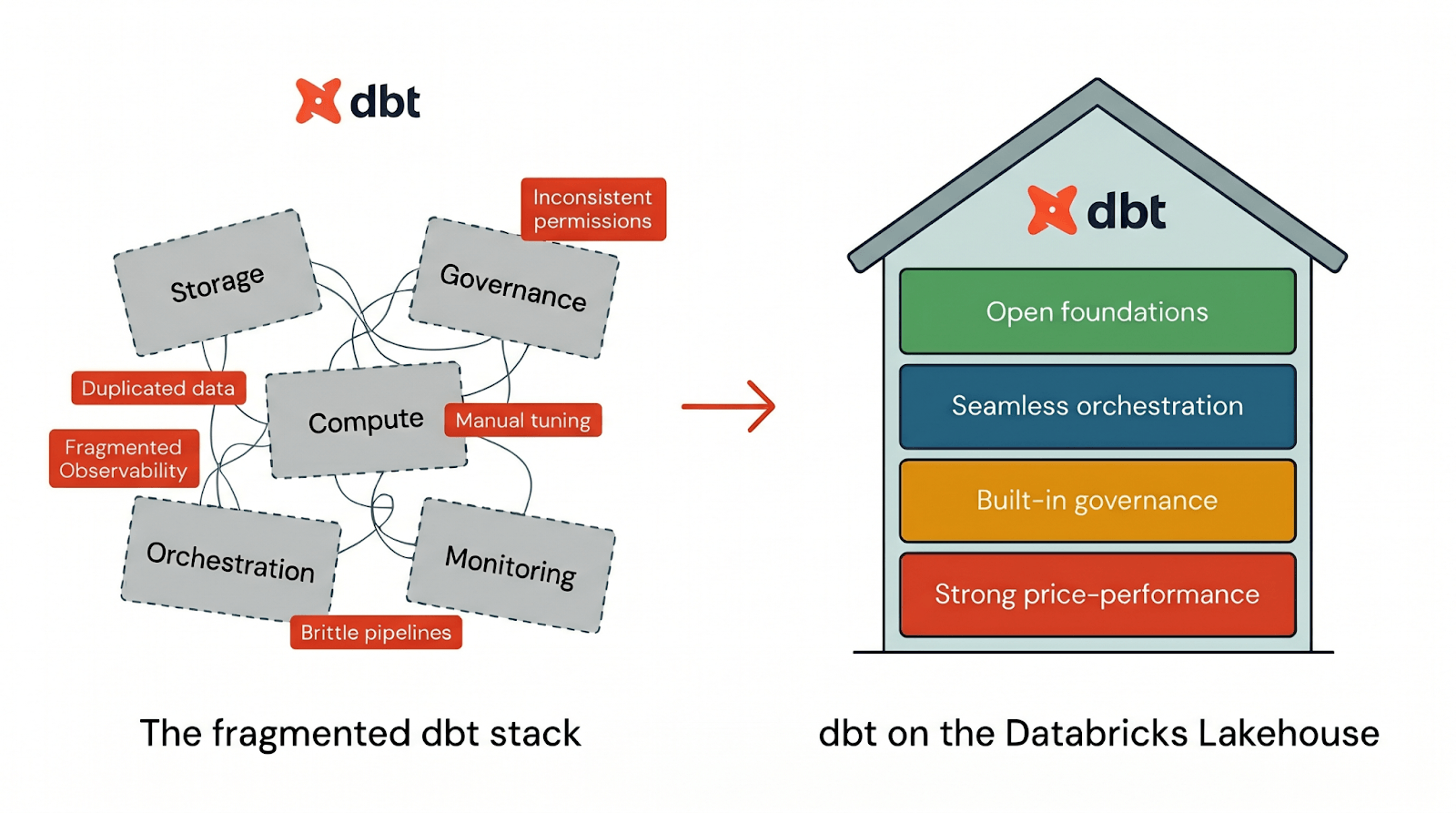
Most data stacks force you to piece together storage, compute, governance, orchestration, and monitoring across multiple systems. The result? Duplicated data, inconsistent permissions, fragmented observability, and performance tuning that becomes a part-time job. It's why a growing number of teams are consolidating their dbt workflows onto Databricks.
To run dbt effectively, a platform needs four things:
- Open foundations so your dbt workflows aren't locked into a proprietary stack
- Seamless orchestration to run dbt pipelines end-to-end in one place
- Built-in governance that's part of the default dbt workflow
- Strong price-performance so dbt runs fast from day one without manual tuning
Databricks delivers all four pillars natively integrated in one platform. When you run dbt on Databricks, you get the dbt developer experience on top of a lakehouse architecture designed for openness, governance, performance, and operational simplicity from day one. Let's look at how each of these works in practice:
Running dbt on Databricks let us consolidate a sprawling legacy of notebooks and 7+ source systems into a single, governed data platform. With Unity Catalog, we manage 341 tenants, multiple environments, and external partner data sharing through catalog-level isolation. Our dbt documentation flows directly into UC, so analysts can self-serve without bottlenecks. By publishing to open formats and Delta Sharing, partners and downstream teams can easily consume dbt-generated datasets across tools and environments. It's one platform for building, but an open platform for consuming. —Sohan Chatterjee, Head of Data and Analytics, iSolved
Run dbt on open foundations with zero vendor lock-in
Vendor lock-in is one of the most significant strategic risks to an organization’s data strategy. dbt is built with an open adapter framework, meaning your transformation logic isn't locked to any single platform. dbt is open by design, and Databricks provides an open platform to run it on. Many modern data stacks center on a proprietary storage layer that offers short-term convenience but introduces long-term friction. Over time, this leads to duplicated data and export pipelines to serve different consumers, storage formats that limit interoperability, and escalating switching costs as platform requirements evolve.
Databricks is an open lakehouse: a unified platform where your data lives in open table formats and is accessible through open interfaces, ensuring storage and governance aren’t tied to a single query engine. On Databricks, dbt models become tables in open formats, Delta Lake and Apache Iceberg, ensuring your transformed data remains accessible across the entire data landscape without exporting or maintaining parallel copies. This openness matters for dbt workflows specifically. Your carefully modeled silver and gold tables become reusable data products that downstream users can consume through any query engine, not just through the platform where dbt runs.
This openness extends beyond storage. Unity Catalog is built around open catalog and access standards that support governed reads and writes from external engines. Databricks SQL follows ANSI standards, ensuring your queries remain portable across platforms to reduce vendor-specific rewrites. That means your dbt workflows run on a stack designed for portability, not lock-in.
Orchestrate dbt pipelines end-to-end with Lakeflow Jobs
Orchestration is where operational complexity accumulates. Pairing dbt with an external orchestrator alongside Databricks means two systems to operate, two places to debug, and brittle handoffs between them.
Lakeflow Jobs removes that complexity by treating dbt as a first-class task type within a unified pipeline. Instead of maintaining a separate orchestration layer, teams run dbt alongside upstream ingestion and downstream actions in a single workflow. For example, you can ingest raw data with Auto Loader, transform data with dbt models, then trigger dashboard refreshes or ML retraining, all in one pipeline with unified retry logic and dependency management. dbt on Databricks also enables ingestion directly through streaming tables. For dbt Platform users, the dbt Platform task (in Beta) enables Lakeflow to trigger and manage dbt workflows running in dbt Platform.
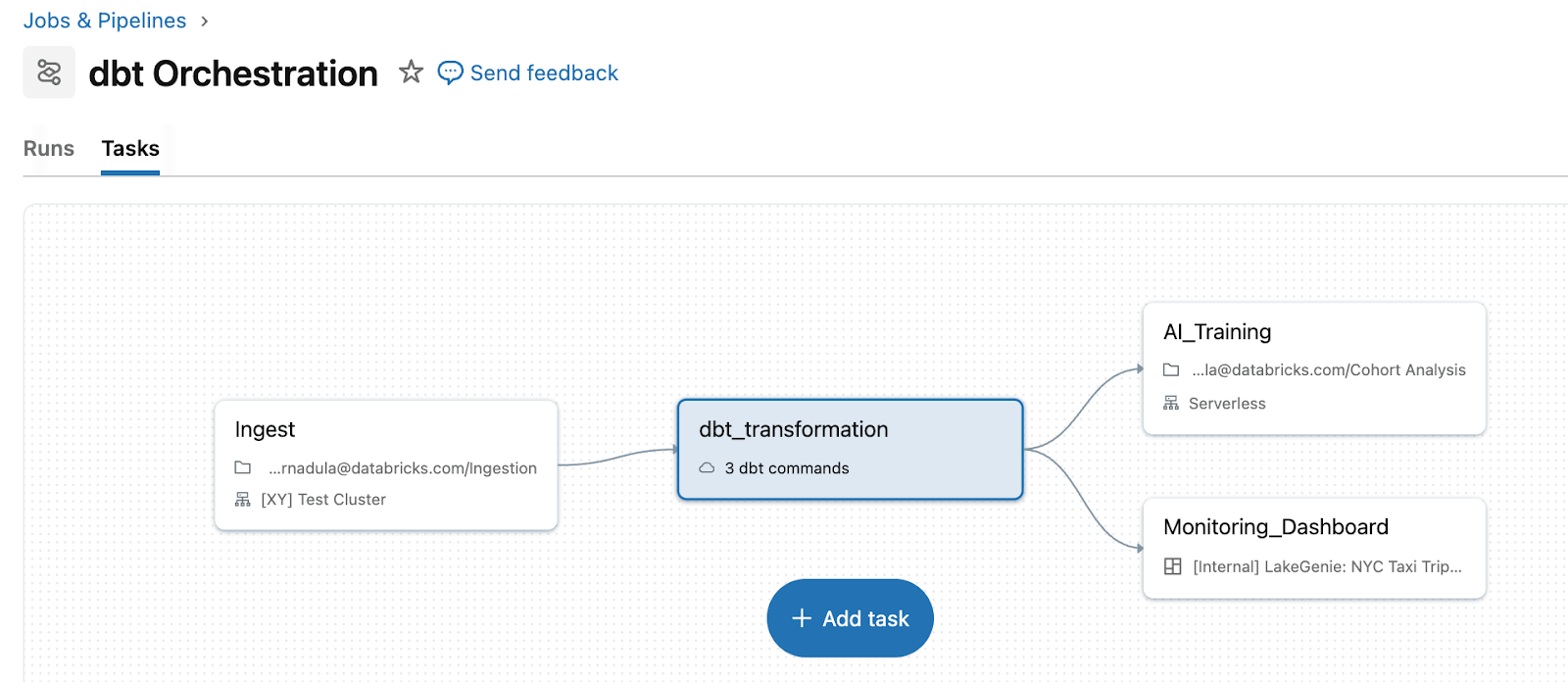
When dbt is orchestrated through Lakeflow, failures, retries, and context are visible in one place. Instead of switching between a separate dbt orchestrator and Databricks logs, you can see the failure, affected downstream tasks, and impacted dashboards directly in the same job run view.
Make governance part of the default dbt workflow
As dbt workflows scale, governance becomes the bottleneck. Teams need clear answers about table contents, ownership, and access permissions. In traditional stacks, this context is fragmented across separate catalog tools, permission systems, and incomplete lineage views that don't connect end to end.
Databricks solves this with Unity Catalog, which unifies access control, discovery, and lineage for your entire lakehouse – not just within dbt, but across ingestion, BI, ML/AI, and beyond. With Unity Catalog, you don't need to re-run grant statements every time dbt recreates a table. Permissions are managed at the schema level and persist across table rebuilds. Fine-grained controls like row-level filters, column masks, and attribute-based access control apply consistently across dbt, BI tools, and notebooks.
For example, when you persist dbt documentation into Unity Catalog using dbt's persist_docs functionality, column descriptions and context authored in dbt become discoverable where data is queried and consumed. Unity Catalog provides column-level data lineage that traces data flow from raw ingestion through dbt transformations to downstream usage. When a source schema changes, you can instantly see which dbt models and downstream assets are affected. This level of visibility is impossible when data pipelines span disconnected systems.
Cost governance matters just as much as data governance. With query tags, you can attach business context to dbt runs and track spend by team, project, or environment through System Tables. Teams can finally answer "how much do our marketing analytics dbt pipelines cost?" with real data instead of estimates. Additionally, DBSQL Granular Cost Monitoring (in Private Preview) also provides aggregated cost monitoring across all dbt workloads.
Run dbt with strong price-performance from day one
Optimizing a data warehouse for performance typically requires ongoing manual work. Teams often end up trading developer velocity for performance hygiene.
Databricks abstracts this complexity by combining a high-performance execution engine with features that work natively with dbt, delivering speed improvements without manual overhead.
Built-in performance
- Photon engine accelerates SQL workloads through vectorized execution, delivering up to 12x better price-performance compared to cloud data warehouses. Serverless SQL warehouses include Photon by default, so teams get accelerated performance without additional cost.
- Predictive Optimization uses AI to monitor tables and automate maintenance, achieving up to 20x faster queries. This reduces the need for manual OPTIMIZE post-hooks that dbt engineers historically relied on.
Performance features unlocked through dbt config
- dbt’s integration with Liquid Clustering which replaces rigid partitioning strategies with a flexible approach that dynamically adjusts as data volume grows, resulting in up to 10x faster speeds without manual tuning
- Materialized Views in dbt, powered by open-source Spark Declarative Pipelines, handle incremental processing automatically. Databricks manages the complexity of determining what needs updating and only processes new or modified records, rather than recomputing entire datasets. This delivers lower compute costs compared to inefficient scheduled batch refreshes.
With these features, users spend less time tuning and more time building pipelines that stay performant as datasets grow. In 2025 alone, Databricks SQL achieved a performance improvement of 10% on ETL workloads (queries with writes) without needing any additional configurations.
Get started today
Databricks brings open storage, unified governance, strong price performance, and integrated operations together in one place for dbt workflows. Join 2900+ customers already running dbt on Databricks. Get started by following the quick start guide.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.