Open Sourcing Unity Catalog
Creating the industry’s only universal catalog for data and AI
by Matei Zaharia, Ali Ghodsi, Reynold Xin, Arsalan Tavakoli-Shiraji and Patrick Wendell
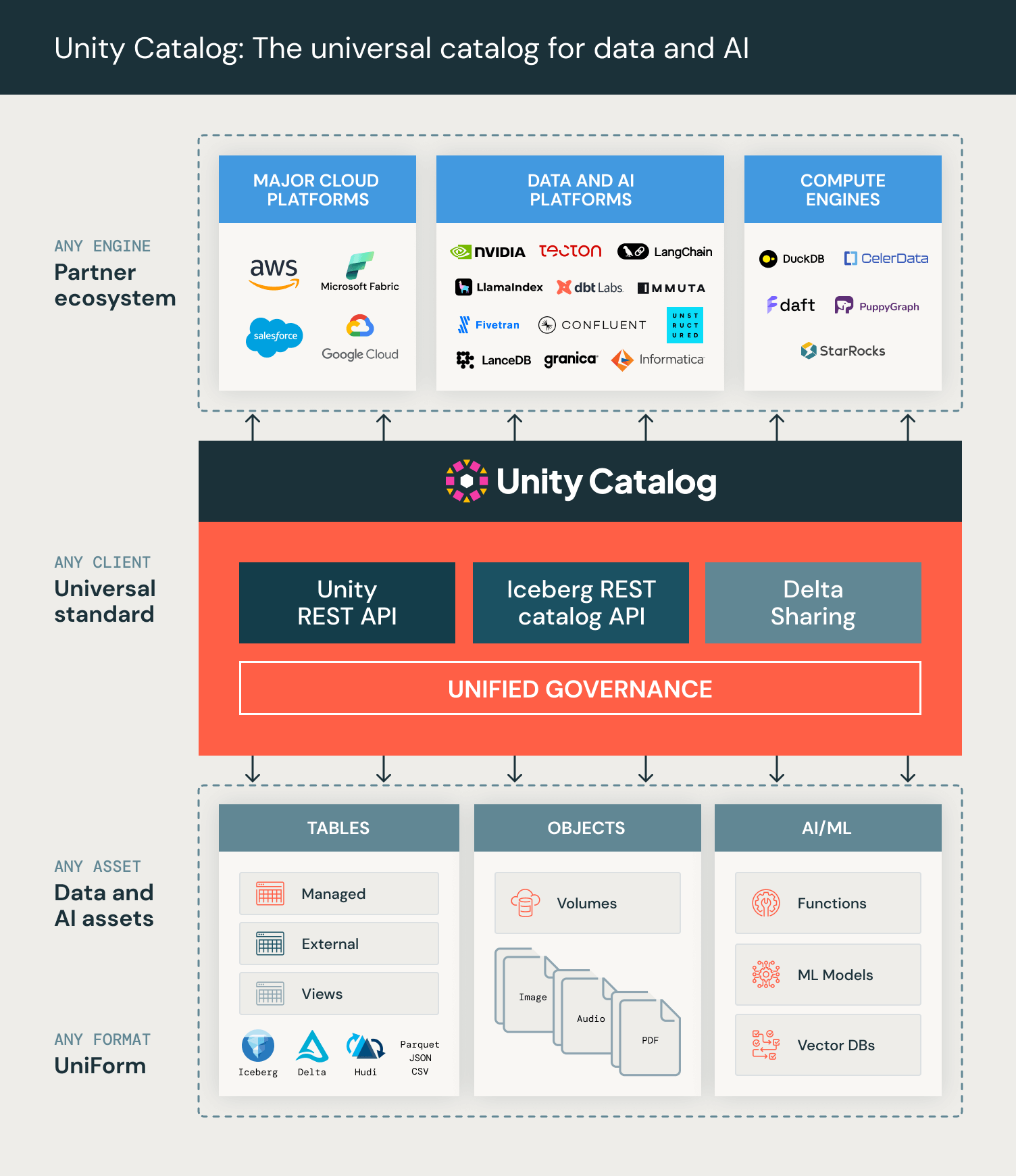
We are excited to announce that we are open sourcing Unity Catalog, the industry’s first open source catalog for data and AI governance across clouds, data formats, and data platforms. Here are the most important pillars of the Unity Catalog vision:
- Open source API and implementation: It is built on OpenAPI spec and an open source server implementation under Apache 2.0 license. It is also compatible with Apache Hive's metastore API and Apache Iceberg's REST catalog API.
- Multi-format support: It is extensible and supports Delta Lake, Apache Iceberg via UniForm, Apache Parquet, CSV, and all the formats out there.
- Multi-engine support: With its open APIs, data cataloged in Unity can be read by virtually all compute engines.
- Multimodal: It supports all your data and AI assets, including tables, files, functions, AI models.
- Vibrant ecosystem: This is a community effort and we are extremely excited to be supported by Amazon Web Services, Microsoft Azure, Google Cloud, Nvidia, Salesforce, DuckDB, LangChain, dbt Labs, Fivetran, Confluent, Unstructured, Onehouse, Immuta, Informatica and many more.
The project is available on GitHub today as the first step in our journey towards bringing the Unity vision into open source. Unity Catalog is hosted at LF AI & Data, an umbrella foundation of the Linux Foundation that supports open source innovation in artificial intelligence (AI) and data, where we are excited to work with the open source communities in the many years to come to realize this vision.
Why open source?
With the widespread adoption of Unity Catalog, you might wonder why we're open sourcing it and why now. It is because we've consistently heard from organizations that they need an open foundation for their data and AI applications, not just for today, but for the innovations of the coming decades.
Unfortunately, most data platforms today are walled gardens. Many cloud data warehouses use "native tables" that are not in open formats. Other platforms require customers to pay for always-on compute even when reading data from external engines. And, many platforms restrict which data formats and clients they support.
This results in siloed data and fragmented governance across assets. And without a multimodal interface across tabular data, let alone AI assets, organizations need to stitch multiple disjoint solutions together. Databricks already took a strong stance in the industry by being the only major platform where all tables are in open formats by default, and by opening up Delta tables to Iceberg clients with UniForm last year. By open-sourcing Unity Catalog, we are giving organizations an open foundation for their current and future workloads.
Why a multimodal data and AI catalog?
In this era of rapid AI advances, every enterprise has realized that it will need to govern data and AI assets together – whether it is managing unstructured data for compound AI systems, or building a catalog of tools for agentic LLM applications. At Databricks, we saw this need for integrated data and AI infrastructure early on, and launched Unity Catalog three years ago to bring these two worlds together into a consistent governance model. Today, we are seeing thousands of customers take advantage of unified governance, including:
- A single namespace for organizing and sharing tables, unstructured data, and AI assets
- Centralized audit logs of all data and AI activities
- Unified lineage across data and AI workloads
- Cross-organization collaboration via the open source Delta Sharing protocol.
Our latest launches in AI, such as the concept of Tool Catalogs for generative AI agents, are also designed to fit into this unified governance model.
Unity Catalog 0.1 Release
Today, we are releasing version 0.1 of open source Unity Catalog. While some of our APIs and features will still be evolving, this release showcases several important capabilities of Unity Catalog:
- Tables, Volumes (unstructured data), and AI Tools/Functions can be managed together.
- Tables can be in multiple formats, including Delta Lake, Iceberg via UniForm, Parquet, CSV, and JSON.
- Unity Catalog implements the Iceberg REST Catalog API for access from the Iceberg engine ecosystem, leveraging expertise from Tabular.
- The API supports credential vending to gate clients' access to the underlying cloud storage for tables and volumes, centralizing governance in the catalog server.
What this means for Databricks customers
If you are already a Databricks customer, there is nothing you need to do differently. Customers' existing Unity Catalog deployments implement the same open APIs – enabling external clients to read from all tables (including managed and external tables), volumes, and functions in hosted Unity Catalog from Day 1, with your existing access controls in place. This change simply means a larger ecosystem of clients will work with your existing catalog.
Unity REST APIs enable our partners and the open source community to build powerful integrations that will enable customers to work on their tables, unstructured data, and AI tools/functions from diverse applications, with no external access fees.
"AT&T is committed to making our data interoperable with our platforms. With the announcement of Unity Catalog's open sourcing, we are encouraged by Databricks' step to make lakehouse governance and metadata management possible through open standards. The flexibility to utilize interoperable tools with our data and AI assets, with consistent governance is core to the AT&T data platform strategy."
— Matt Dugan, Vice President Data Platforms, AT&T
![]()
"Nasdaq is proud to leverage Databricks' Unity Catalog as part of our holistic data management strategy. Databricks' decision to open source Unity Catalog provides a solution that helps eliminate data silos and we look forward to further scaling our platform, enhancing our governance, and modernizing our data applications as we continue to deliver for our clients."
— Lenny Rosenfeld, Vice President, Capital Access Platforms, Nasdaq
![]()
"At Rivian, the adoption of the Databricks Platform has given us the ability to use data and AI in building our next-gen EAVs. We are excited about Databricks open sourcing Unity Catalog and releasing Open APIs to bring interoperability across our data landscape without any concerns of vendor lock-in. Combined with support for all our data assets —structured and unstructured data, ML models, and Gen AI tools — it was an easy decision to standardize on Unity Catalog."
— Jason Shiverick, Director of AI Platforms, Rivian
![]()
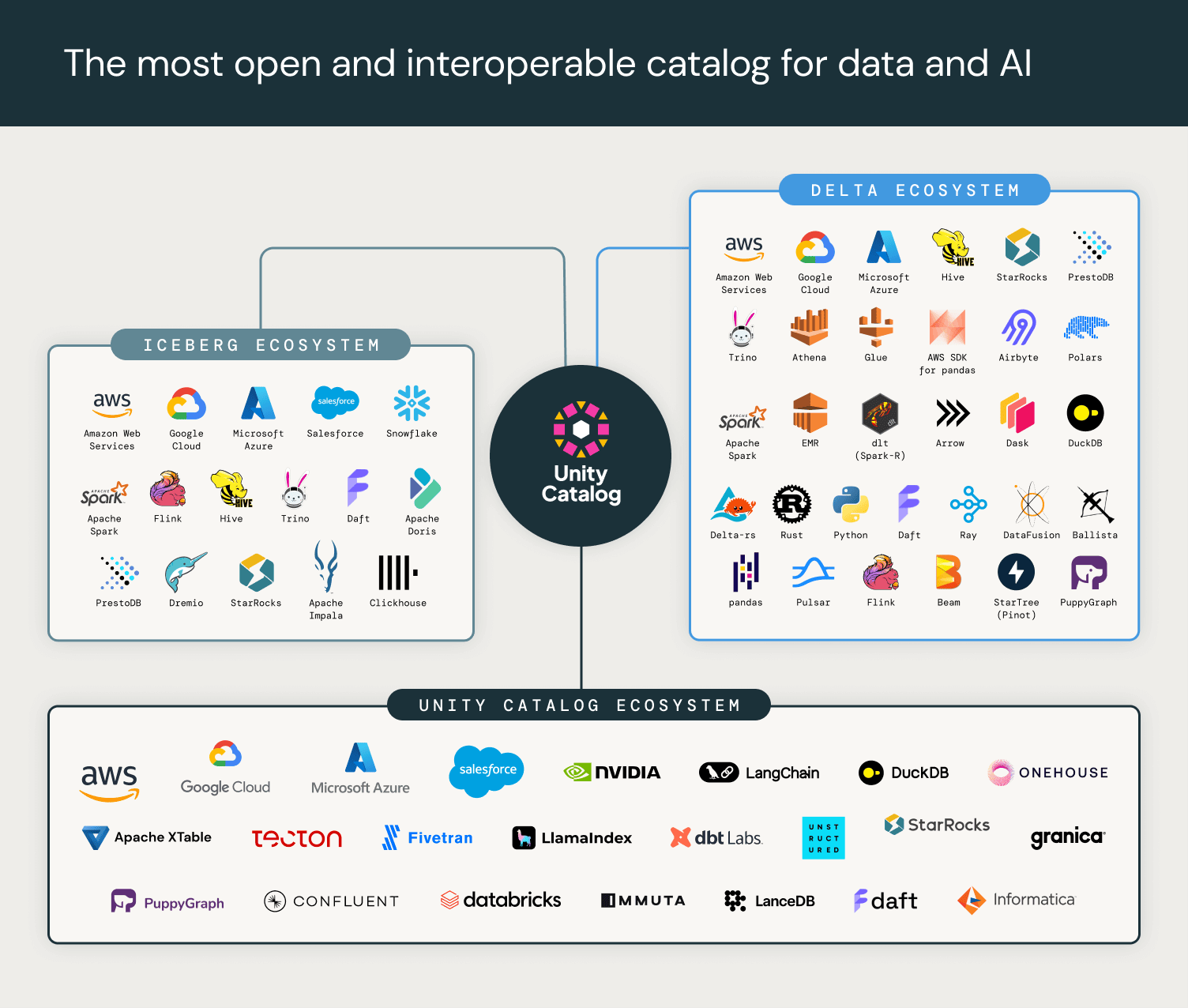
Open Source Ecosystem
We are excited to partner with leading cloud providers, data and AI platforms, and compute engines to advance the Unity Catalog standard in the coming months. They include leading software vendors and open source projects in AI, data analytics, unstructured data, and governance, who will be able to easily connect to Unity Catalog open source servers and to Databricks.
"AWS welcomes Databricks' move to open source Unity Catalog. AWS is committed to working with the industry on open source solutions that enable choice and interoperability for customers."
— Chris Grusz, Managing Director of Technology Partnerships, AWS
![]()
"Microsoft is committed to the open-source community and empowering customers with choice. Databricks has been a strategic partner for years and it's great to see them open-sourcing Unity Catalog. We believe truly open standards with broad industry participation are in customers' best interests. Our collaboration with Databricks continues to elevate Microsoft Azure as the best choice for data and AI workloads."
— Jessica Hawk, CVP Data, AI and Digital Applications, Microsoft
![]()
"Google is committed to open, flexible solutions that empower customers to maximize the value of their data. Databricks' strategy to open up the Unity Catalog standard for data and AI aligns very well with our strategy."
— Ritika Suri, Director, Data and AI Technology Partnerships, Google Cloud
![]()
Roadmap ahead
This is just the starting point for the Unity Catalog open source project. Unity Catalog serves thousands of customers in production and is the product of years of engineering, so we are porting this functionality to the open source project in stages, prioritizing access and client interoperability to start.
In the coming months, we will add enhanced support for the APIs that are critical to your data and AI workloads, including:
- Format-agnostic table write APIs
- Views
- Delta Sharing
- Models (with MLflow integration)
- Remote functions
- Access Control APIs
- And more
Get started today
You can join the Unity Catalog open source community at unitycatalog.io. For Databricks customers, stay tuned for the rapidly advancing ecosystem of data and AI tools integrating with Unity Catalog.
"Salesforce Data Cloud is built from the ground up on Open Standards with Apache Parquet and Apache Iceberg. Our zero copy innovations enable customers to unlock data, derive insights and orchestrate actions across the Customer 360. Databricks' embrace of Apache Iceberg via UniForm and Unity Catalog addresses key interoperability challenges between Delta Lake and Iceberg. We are excited to have Databricks as a member of our Zero Copy Partner Network and look forward to joint innovations with the new open Unity Catalog, delivering compelling customer value in structured data, unstructured data and AI models."
— Ravi Loganathan, Executive Vice President of Software Engineering, Salesforce
![]()
"Enterprise data is essential to developing accurate generative AI applications. NVIDIA works closely with our partner ecosystem to support open-source offerings like Unity Catalog, which can help customers curate efficient and powerful development pipelines."
— Pat Lee, VP of Strategic Enterprise Partnerships, NVIDIA
![]()
"Delta Kernel has greatly simplified building the DuckDB Delta Extension, enabling easy access to Delta Lake from DuckDB. We are thrilled to partner with Databricks on Delta Kernel and the Unity Catalog open standard for data and AI. This collaboration represents a significant step forward in open source innovation and the development of open data lakehouses."
— Hannes Mühleisen, CEO, DuckDB Labs
![]()
"Databricks's decision to open source Unity Catalog is an exciting development for the data and AI community. We're excited to partner with Databricks to integrate Unity Catalog with LangChain, which allows our shared users to build advanced agents using Unity Catalog functions as tools."
— Harrison Chase, CEO & Founder, LangChain
![]()
"Unstructured is the leading unstructured data ETL solution for LLMs - helping organizations transform their data from raw to RAG-ready. Our integration with Unity Catalog makes perfect sense, as we break down data silos and accelerate AI/ML development in enterprises. We are excited to partner with Databricks to develop this open standard for AI use cases and to standardize metadata for unstructured data – helping our customers operate at the cutting edge of AI."
— Brian Raymond, CEO & Founder, UnstructuredIO
![]()
"At Eventual, we have built Daft, the leading open source distributed query engine for multimodal data. We believe that unifying compute for tabular and unstructured data is not enough and that a multimodal catalog is crucial to build GenAI data lakehouses. We are excited to partner with Databricks and other AI innovators to develop the Unity Catalog open standard for modern data+AI workloads."
— Sammy Sidhu, CEO & Founder, Eventual Computing
![]()
"At Granica, we champion data democratization and freedom from vendor lock-in. Our Safe Room technology ensures privacy, trust, and safety in generative AI workflows while supporting open standards like Unity Catalog, Delta Lake, and Apache Iceberg. Unity Catalog's vendor-neutral architecture and robust governance solutions align with our vision of providing customers with flexibility and control over their data. We are excited to contribute to this open ecosystem, driving innovation and enabling customers to seamlessly work with their data across best-of-breed platforms."
— Rahul Ponnala, CEO & Co-Founder, Granica
![]()
"Open sourcing Unity Catalog is a pivotal step towards a more collaborative and innovative data ecosystem. By making this technology accessible, Databricks is fostering an environment where the entire community can contribute to and benefit from enhanced data governance and management capabilities. This move aligns with our vision at Onehouse and Apache XTable (Incubating) to support open format interoperability that drives progress and innovation for all."
— Vinoth Chandar, CEO & Co-Founder, Onehouse
![]()
"Confluent's mission is to set data in motion and enable organizations to take advantage of their data everywhere. We're excited to see Databricks make a significant contribution to an open data ecosystem with Unity Catalog becoming open sourced. Tableflow on Confluent Cloud will enable easy delivery of real-time data to places like a data lake by turning data streams into Iceberg tables with a single click. By combining our industry-leading streaming capabilities with Databricks' robust data management solutions, customers will be able to put their data to work more effectively than ever."
— Shaun Clowes, CPO, Confluent
![]()
"Together, Databricks and dbt Cloud help users break down data silos to collaborate effectively, simplify ETL to lower TCO with Delta Lake, and unify governance with Unity Catalog. We are thrilled to announce our support for Unity Catalog and the open APIs. This partnership underscores our commitment to providing a unified data experience, empowering our community to achieve greater insights and drive innovation."
— Mark Porter, CTO dbt Labs
![]()
"We are thrilled to see Databricks open source Unity Catalog as an open standard for data and AI. This move will provide our customers with greater choice and flexibility in their data ecosystem, ensuring seamless integration and maximizing interoperability with Fivetran's platform as they ingest critical data to Databricks."
— Anjan Kundavaram, CPO, Fivetran
![]()
"The exposure of native access patterns within Unity Catalog has transformed how our business is able to streamline access to data and apply governance rules at scale - with no performance impact. Databricks continued investment in a community to accelerate services to make data controls easier to build allows our customers to govern with greater ease and manage the massive volume of new data consumers being onboarded in the age of AI."
— Matthew Carroll, CEO, Immuta
![]()
"We are excited to see the opportunity for our joint customers as Databricks open-sources Unity Catalog as an open standard for data and AI. With Unity Catalog and the Informatica intelligent Data Management Cloud, customers can gain greater choice, flexibility and interoperability in their data ecosystems."
— Brett Roscoe, GM and SVP Cloud Data Governance and Cloud Operations, Informatica
![]()
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.