Announcing General Availability of Liquid Clustering
Out-of-the-box, self-tuning data layout that scales with your data
by Cindy Jiang and Terry Kim
We're excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative data management technique that replaces table partitioning and ZORDER so you no longer have to fine-tune your data layout to achieve optimal query performance.
Liquid clustering significantly simplifies data layout-related decisions and provides the flexibility to redefine clustering keys without data rewrites. It allows data layout to evolve alongside analytic needs over time – something you could never do with partitioning on Delta.
Since the Public Preview of Liquid Clustering at the Data and AI Summit last year, we've worked with hundreds of customers who benefited from better query performance with Liquid Clustering. During that time, we have 1000+ active customers, and have written 100+ petabytes to and read nearly 20 exabytes from Liquid clustered tables. Customers have seen Liquid improve read performance by 2-12x compared to traditional methods.
Traditional approaches: hard to manage, minimal flexibility, no one-size-fits-all strategy
Traditionally, customers adopted a combination of Hive-style partitioning + ZORDERing to speed up read queries and enable concurrent writers. This comes with a few issues:
Challenge 1: figuring out the right partitioning strategy for optimal performance is difficult.
Choosing partitioning columns is a complicated process. And when partition columns are poorly chosen, customers experience slower reads and poor query performance due to file sizes being too large, or too small. To address this, many customers resort to even more complex workarounds, such as using generated columns to partition by high-cardinality columns.
Challenge 2: ZORDERing jobs are expensive and require longer write times.
The ZORDER technique results in faster reads than only partitioning, but has significant write amplification, as it is not incremental, and cannot be done on-write. This results in longer running clustering jobs and higher compute costs. To make matters worse, ZORDER does not optimize the data globally across the entire dataset, preventing optimal query performance.
Challenge 3: Partitioning strategies are restricted by the need to concurrently write to the table.
To prevent conflicts, partitions are structured around columns that do not necessarily need partitioning. This leads to ongoing maintenance, adjusting partitions with data rewrites as query patterns evolve with business changes. Moreover, concurrent writes within the same partition aren't possible.
Introducing Liquid Clustering – self-tuning out-of-the-box performance that improves query performance by up to 12x
Liquid Clustering is a breakthrough technique that solves all these challenges by figuring out the right data layout for you, delivering better write and read performance to manually tuned partitioned tables. Liquid is available in Delta Lake and is now generally available in Databricks from DBR 15.2. Within Databricks, as part of the Databricks Data Intelligence Platform, DatabricksIQ uses AI to supercharge Liquid with additional concurrency and performance improvements.
Using Liquid is simple - simply define the columns you want to cluster by:
Benefit 1: Liquid is simple - optimal clustering performance with minimal data layout decisions
Unlike Hive partitioning, Liquid clustering keys can be chosen purely based on query access patterns, with no need to consider cardinality, key order, file size, potential data skew, and how access patterns might change in the future. In the example above, we are using timestamp, a high-cardinality column, as our clustering key. Liquid is self-tuning and skew-resistant, producing consistent file sizes, and avoiding over- and under-partitioning.
Using Delta Lake's innovative Liquid Clustering, we have observed remarkable improvements in query performance compared to the traditional z-order methods. Additionally, Liquid clustered tables have streamlined our data processing by eliminating partitioning bottlenecks, improving scanning, and reducing data skews. —Edward Goo, Director of ETL Engineering, YipitData
Benefit 2: Writing to Liquid clustered tables is fast - optimized data layouts for lower costs
Liquid offers cost-effective incremental clustering with low write amplification. We see that Liquid achieves 7x faster write times than partitioning + Zorder, in our internal benchmarks where we incrementally ingested and clustered data from an industry-standard data warehousing datasets.
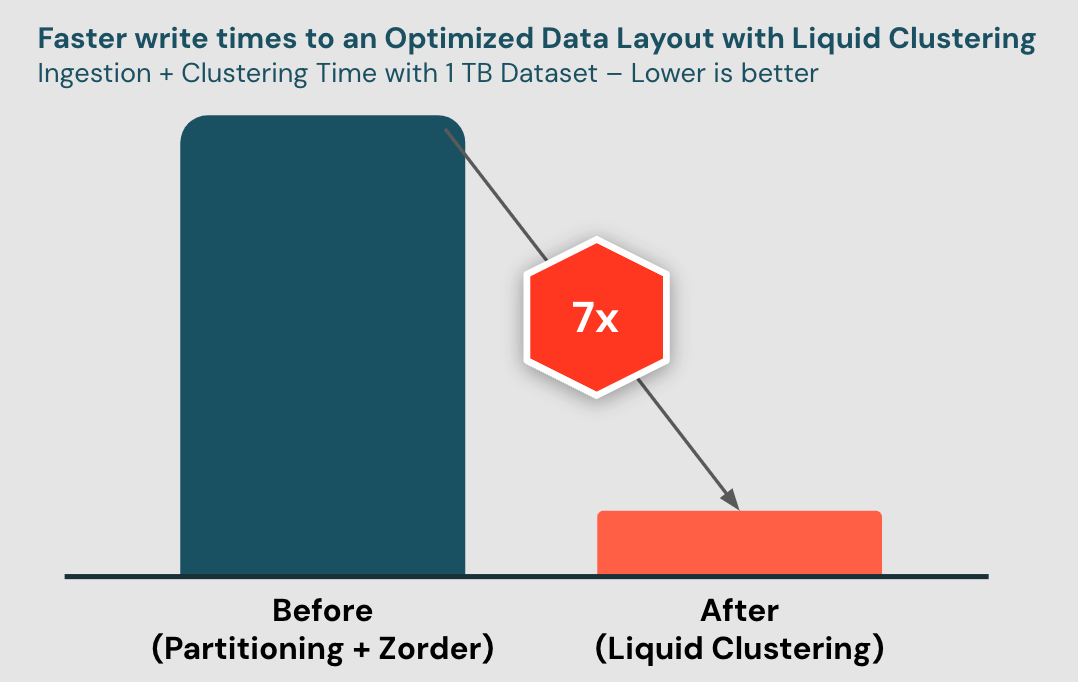
Moreover, using DatabricksIQ, we can apply Liquid Clustering at the write time (clustering-on-write) on new data during ingestion. Clustering-on-write kicks in automatically with no extra configuration. Similar to partitioning, Liquid ensures that data is reasonably well-clustered immediately on write, creating a performant data layout for customers out-of-the-box.
Benefit 3: Concurrency Guarantees – DatabricksIQ provides record-level concurrency support with Liquid clustering
Databricks is the only lakehouse that offers row-level concurrency. Customers no longer have to rely on partitioning for concurrency or design their workloads to avoid conflicts on Liquid clustered tables.
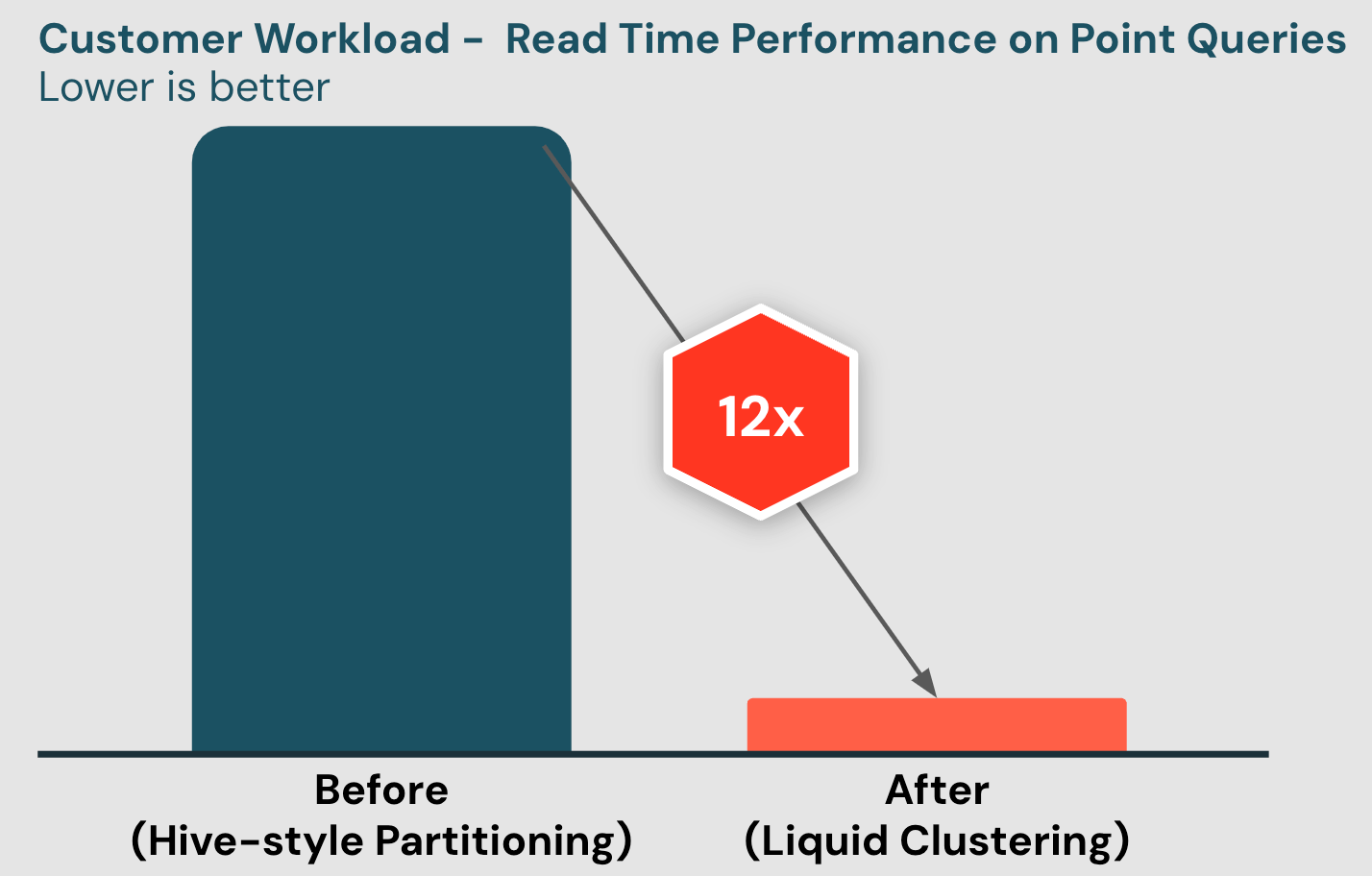
With all these benefits, customers no longer have to fine-tune their data layout just to squeeze out performance. A large manufacturing firm saw Liquid speeding up point queries by 12x, accelerating their use cases of looking up IDs in time series data.
Delta Lake Liquid Clustering improved our time series queries up to 10x and was remarkably simple to implement on our Lakehouse. It allows us to cluster on columns without worrying about cardinality or file size and significantly reduces the amount of data it needs to read - something we have always had to manage ourselves with Delta partitioning and z-order fine-tuning. —Bryce Bartmann, Chief Digital Technology Advisor, Shell
In addition, many customers have praised the capability's simplicity, flexibility, and out-of-the-box performance.
Liquid clustering has greatly improved the ability of our researchers to investigate complex datasets for specific trends and events. We look forward to watching this feature grow and be adopted as a key feature of the Delta ecosystem. —Robert Batts, Big Data Lead, Cisco
Get started today
You can enable Liquid Clustering in seconds on your Delta tables. Liquid Clustering is GA'ed in DBR 15.2. (documentation: AWS | Azure | GCP). For using Liquid Clustering outside of Databricks, please refer to delta.io documentation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.