2025 in Review: Databricks SQL, faster for every workload
Faster analytics and AI workloads, even as data, governance, and usage scale
by Tad Rosenberg, Jeremy Lewallen, Mostafa Mokhtar, Chris Stevens and Ina Felsheim
- In 2025, Databricks SQL delivered up to 40% faster performance across production workloads, with improvements applied automatically.
- Queries improved across BI, ETL, spatial analytics, and AI, even with governed and shared data in place and at higher concurrency.
- All gains are available today in Databricks SQL Serverless, improving performance and cost efficiency for existing workloads without tuning or rewrites.
For most data teams, performance is no longer about one-time tuning. It’s about analytics getting faster as data, users, and governance scale, without driving up costs.
With Databricks SQL (DBSQL), that expectation is built into the platform. In 2025, average performance across production workloads improved by up to 40%, with no tuning, no query rewrites, and no manual intervention required.
The bigger story goes beyond a single benchmark. Performance improved across the platform, from faster dashboard loads and more efficient pipelines to queries that stay responsive even with governance and shared data in place, while geospatial analytics and AI functions continue to scale without added complexity.
The goal remains simple: make workloads faster and reduce total cost by default. With DBSQL Serverless, Unity Catalog Managed Tables, and Predictive Optimization, improvements apply automatically across your environment, so existing workloads benefit as the engine evolves.
This post breaks down the performance gains delivered in 2025 across the query engine, Unity Catalog, Delta Sharing, storage, Spatial SQL, and AI functions.
Fast query performance across every workload
Databricks SQL measures performance using millions of real customer queries that run repeatedly in production. By tracking how these workloads change over time, we measure the actual impact of the platform improvements and optimizations rather than isolated benchmarks.
In 2025, Databricks SQL delivered consistent performance gains across all major workload types. These improvements apply by default through engine-level optimizations such as Predictive Query Execution and Photon Vectorized Shuffle, without requiring configuration changes.
- Exploratory workloads saw the largest gains, running on average 40% faster and allowing analysts and data scientists to iterate more quickly on large datasets.
- Business intelligence workloads improved by about 20%, resulting in more responsive dashboards and smoother interactive analysis under concurrency.
- ETL workloads also benefited, running roughly 10% faster and shortening pipeline runtimes without rework.
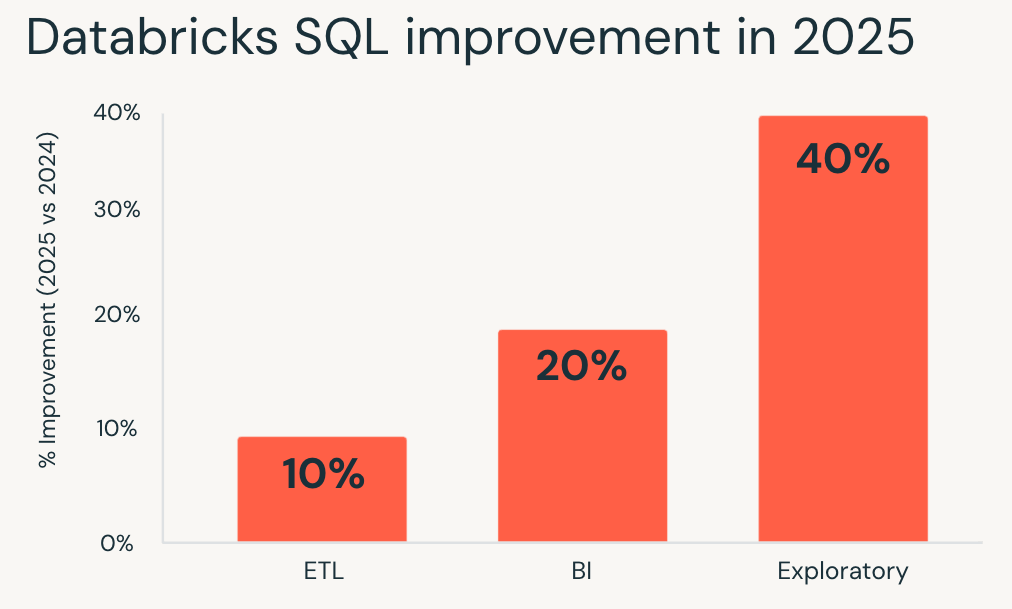
If you last evaluated Databricks SQL a year ago, your existing workloads are already running faster today.
Analytics that stay fast as governance scales with Unity Catalog
As data estates grow, governance often becomes a hidden source of latency. Permission checks, metadata access, and lineage lookups can slow down queries, especially in interactive and high-concurrency environments.
In 2025, Unity Catalog significantly reduced this overhead. End-to-end catalog latency improved by up to 10x, driven by optimizations across the catalog service, networking stack, Databricks Runtime client, and dependent services.
The result is visible where it matters most:
- Dashboards remain responsive even with fine-grained access controls.
- High-concurrency workloads scale without bottlenecks from metadata access.
- Interactive analytics feel faster as users explore governed data at scale.
Teams no longer have to choose between strong governance and performance. With Unity Catalog, analytics stays fast as governance expands across more data and more users.
Delta Sharing, shared data that performs like native data
Sharing data across teams or organizations has traditionally come with a cost. Queries against shared tables often ran more slowly, and optimizations were applied unevenly compared to native data.
In 2025, Databricks SQL closed that gap. Through improvements in query execution and statistics propagation, queries on tables shared through Delta Sharing ran up to 30% faster, bringing shared data performance in line with native tables.

This change matters most in scenarios where external data needs to behave like internal data. Data marketplaces, cross-organization analytics, and partner-driven reporting can now run on shared datasets without sacrificing interactivity or predictability.
With Delta Sharing, teams can share governed data broadly while preserving the performance expectations for modern analytics.
Lower storage cost, automatic optimizations built in
As data volumes grow, storage efficiency becomes a larger part of the total cost. Compression plays a critical role, but choosing formats and managing migrations has traditionally added operational overhead.
In 2025, Databricks made Zstandard compression the default for all new Unity Catalog Managed Tables. Zstandard is an open source compression format that delivers up to 40% storage cost savings compared to older formats, without degrading query performance.

These benefits apply automatically to new tables, and existing tables can also be migrated to Zstandard, with simple migration tooling coming soon. Large fact tables, long-retention datasets, and rapidly growing domains see immediate cost reductions without changes to how queries are written or executed.
The result is lower storage cost by default, delivered without sacrificing performance or adding new tuning steps.
Geospatial analytics without specialized systems
Geospatial analytics places heavy demands on query execution. Spatial joins, range queries, and geometric calculations are compute-intensive, and at scale they often require specialized systems or careful tuning.
In 2025, Databricks SQL significantly improved performance for these workloads. Spatial SQL queries ran up to 17x faster, driven by engine-level optimizations such as R-tree indexing, optimized spatial joins in Photon, and intelligent range join optimization.
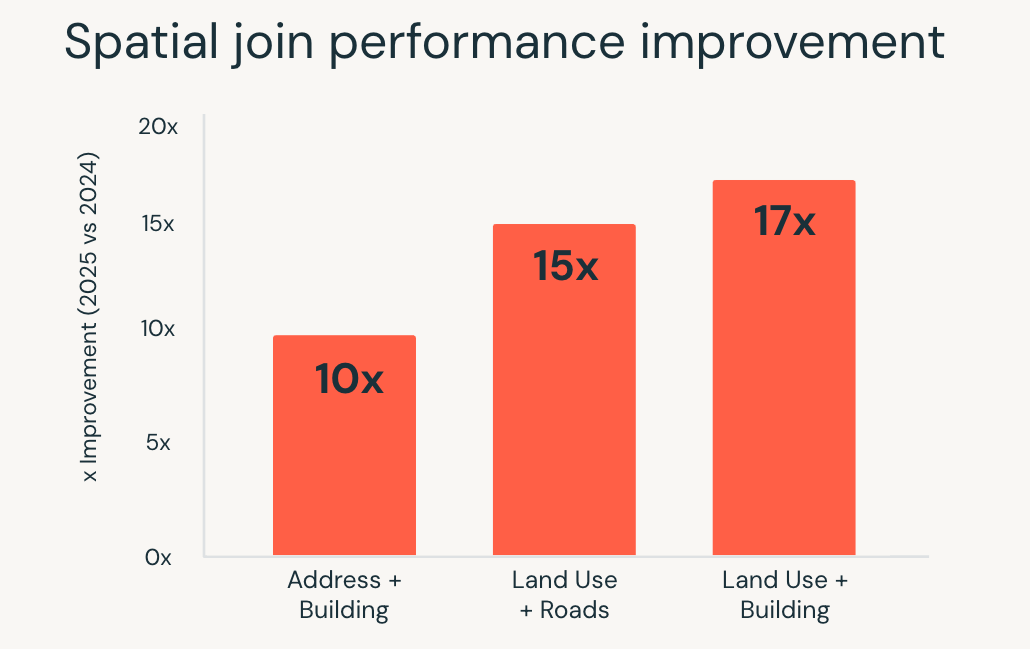
These improvements allow teams to work with location data using standard SQL, while the engine handles execution complexity automatically. Use cases such as real-time location analytics, large-scale geofencing, and geographic enrichment run faster and more consistently as data volumes grow.
Spatial analytics no longer requires separate tooling or manual optimization. Complex geospatial workloads scale directly within Databricks SQL.
AI Functions, scalable AI directly in SQL
Applying AI to data has traditionally required work outside the warehouse. Text classification, document parsing, and translation often meant building separate pipelines, managing model infrastructure, and stitching results back into analytics workflows.
AI Functions simplify that model by bringing AI directly into SQL. In 2025, Databricks SQL significantly expanded the scale and performance of these capabilities. New batch-optimized infrastructure delivered up to 85x faster performance for functions such as ai_classify, ai_summarize, and ai_translate, allowing large batch jobs that once took hours to complete in minutes.
Databricks also introduced ai_parse_document and rapidly optimized it for scale. Purpose-built models for document understanding, hosted on Databricks Model Serving, delivered up to 30x faster performance compared to general-purpose alternatives, making it practical to process large volumes of unstructured content directly within analytics workflows.
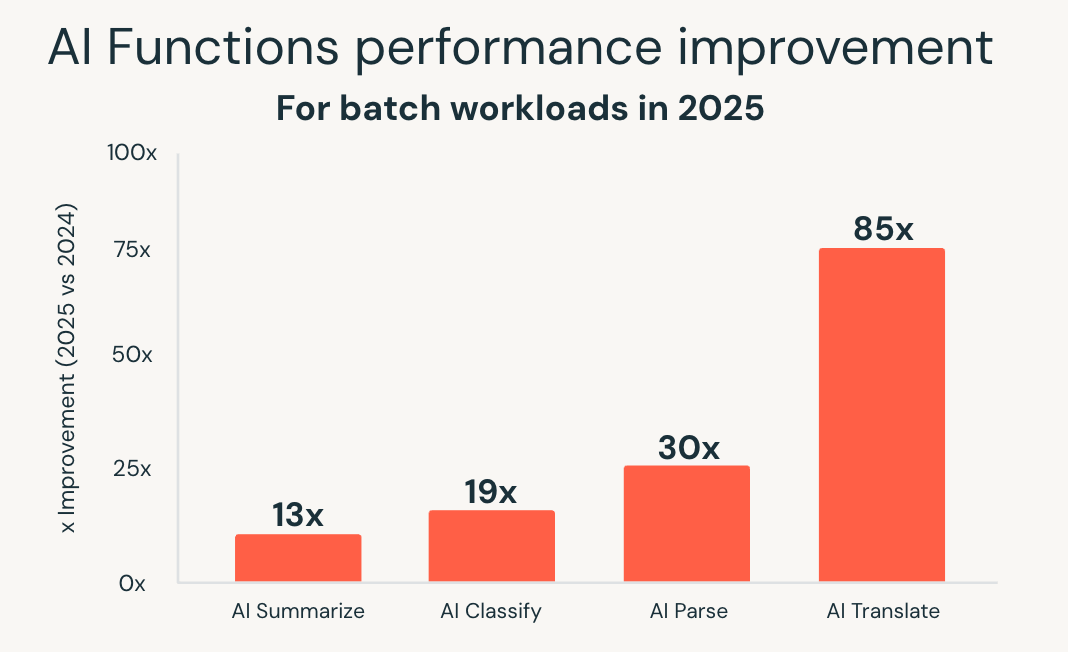
These improvements enable intelligent document processing, extraction of insights from unstructured data, and predictive analytics using familiar SQL interfaces. AI workloads scale alongside analytics workloads, without requiring separate systems or custom pipelines.
With AI Functions, Databricks SQL extends beyond analytics into AI-powered workloads, while preserving the simplicity and performance expectations of the warehouse.
Getting started
All of these improvements are already live in Databricks SQL Serverless, with nothing to enable and no configuration required.
If you haven’t tried DBSQL Serverless, create a serverless warehouse and start querying. Existing workloads benefit immediately, with performance and cost improvements applied automatically as the platform continues to evolve.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.