Passando na Verificação de Segurança Vibe: Os Perigos da Codificação Vibe
por Neil Archibald e Caelin Kaplan
- A codificação vibe pode levar a vulnerabilidades críticas, como execução arbitrária de código e corrupção de memória, mesmo quando o código gerado parece funcional.
- Técnicas de prompt como auto-reflexão, prompts específicos de linguagem e prompts de segurança genéricos reduzem significativamente a geração de código inseguro.
- Testes em larga escala com benchmarks como Secure Coding e HumanEval demonstram que o prompt de segurança melhora a segurança do código com mínimas trocas de qualidade.
Introdução
Na Databricks, nossa equipe de IA Red Team explora regularmente como novos paradigmas de software podem introduzir riscos de segurança inesperados. Uma tendência recente que temos acompanhado de perto é a "vibe coding", o uso casual e rápido de IA gerativa para estruturar código. Embora essa abordagem acelere o desenvolvimento, descobrimos que também pode introduzir vulnerabilidades sutis e perigosas que passam despercebidas até que seja tarde demais.
Neste post, exploramos alguns exemplos reais de nossos esforços de equipe vermelha, mostrando como a codificação vibe pode levar a vulnerabilidades sérias. Também demonstramos algumas metodologias para incentivar práticas que podem ajudar a mitigar esses riscos.
Vibração da Codificação Dando Errado: Jogos Multiplayer
Em um de nossos experimentos iniciais explorando os riscos do vibe coding, pedimos ao Claude para criar uma arena de batalha de cobras em terceira pessoa, onde os usuários controlariam a cobra a partir de uma perspectiva de câmera aérea usando o mouse. Consistente com a metodologia de codificação de vibração, permitimos que o modelo tivesse controle substancial sobre a arquitetura do projeto, solicitando incrementalmente que ele gerasse cada componente. Embora a aplicação resultante tenha funcionado conforme o esperado, esse processo introduziu inadvertidamente uma vulnerabilidade de segurança crítica que, se não verificada, poderia ter levado à execução arbitrária de código.
A Vulnerabilidade
A camada de rede do jogo Snake transmite objetos Python serializados e desserializados usando pickle, um módulo conhecido por ser vulnerável a execução remota de código arbitrário (RCE). Como resultado, um cliente ou servidor mal-intencionado poderia criar e enviar cargas úteis que executam código arbitrário em qualquer outra instância do jogo.
O código abaixo, retirado diretamente do código de rede gerado pelo Claude, ilustra claramente o problema: objetos recebidos da rede são diretamente desserializados sem qualquer validação ou verificações de segurança.
Embora esse tipo de vulnerabilidade seja clássico e bem documentado, a natureza da codificação vibe torna fácil ignorar riscos potenciais quando o código gerado parece "simplesmente funcionar".
No entanto, ao incentivar Claude a implementar o código de forma segura, observamos que o modelo identificou e resolveu proativamente os seguintes problemas de segurança:
Como mostrado no trecho de código abaixo, o problema foi resolvido ao mudar de pickle para JSON para serialização de dados. Um limite de tamanho também foi imposto para mitigar ataques de negação de serviço.
ChatGPT e Corrupção de Memória: Análise de Arquivo Binário
Em outro experimento, atribuímos ao ChatGPT a tarefa de gerar um analisador para o formato binário GGUF, amplamente reconhecido como desafiador para analisar de forma segura. Os arquivos GGUF armazenam pesos de modelo para módulos implementados em C e C++, e escolhemos especificamente este formato, pois a Databricks já encontrou várias vulnerabilidades na biblioteca oficial GGUF.
O ChatGPT produziu rapidamente uma implementação funcional que lidou corretamente com a análise de arquivos e a extração de metadados, conforme mostrado no código fonte abaixo.
No entanto, após uma análise mais detalhada, descobrimos falhas de segurança significativas relacionadas ao manuseio inseguro da memória. O código C/C++ gerado incluía leituras de buffer não verificadas e instâncias de confusão de tipo, ambas podendo levar a vulnerabilidades de corrupção de memória se exploradas.
Neste analisador GGUF, existem várias vulnerabilidades de corrupção de memória devido à entrada não verificada e aritmética de ponteiros insegura. Os principais problemas incluíam:
- Verificação de limites insuficiente ao ler inteiros ou strings do arquivo GGUF. Isso pode levar a leituras excessivas de buffer ou estouros de buffer se o arquivo foi truncado ou maliciosamente criado.
- Alocação de memória insegura, como alocar memória para uma chave de metadados usando um comprimento de chave não validado com 1 adicionado a ele. Este cálculo de comprimento pode causar um estouro de inteiro resultando em um estouro de heap.
Um invasor poderia explorar o segundo desses problemas criando um arquivo GGUF com um cabeçalho falso, um comprimento extremamente grande ou negativo para um campo de chave ou valor, e dados de carga útil arbitrários. Por exemplo, um comprimento de chave de 0xFFFFFFFFFFFFFFFF (o valor máximo sem sinal de 64 bits) poderia fazer com que um malloc() não verificado retornasse um pequeno buffer, mas a subsequente memcpy() ainda escreveria além dele, resultando em um estouro de buffer baseado em heap clássico. Da mesma forma, se o analisador assume um comprimento válido de string ou array e o lê na memória sem validar o espaço disponível, ele poderia vazar conteúdos de memória. Essas falhas poderiam potencialmente ser usadas para alcançar a execução arbitrária de código.
Para validar esse problema, pedimos ao ChatGPT para gerar uma prova de conceito que cria um arquivo GGUF malicioso e o passa para o analisador vulnerável. A saída resultante mostra o programa travando dentro da função memmove, que está executando a lógica correspondente à chamada insegura memcpy. A falha ocorre quando o programa chega ao final de uma página de memória mapeada e tenta escrever além dela em uma página não mapeada, acionando uma falha de segmentação devido a um acesso à memória fora dos limites.
Mais uma vez, pedimos sugestões ao ChatGPT sobre como corrigir o código e ele foi capaz de sugerir as seguintes melhorias:
Em seguida, pegamos o código atualizado e passamos o arquivo GGUF de prova de conceito para ele e o código detectou o registro malformado.
Novamente, o problema principal não era a capacidade do ChatGPT de gerar código funcional, mas sim que a abordagem casual inerente à codificação vibe permitia que suposições perigosas passassem despercebidas na implementação gerada.
Solicitação como uma Mitigação de Segurança
Embora não haja substituto para um especialista em segurança revisando seu código para garantir que ele não seja vulnerável, várias estratégias práticas e de baixo esforço podem ajudar a mitigar riscos durante uma sessão de codificação vibe. Nesta seção, descrevemos três métodos simples que podem reduzir significativamente a probabilidade de gerar código inseguro. Cada um dos prompts apresentados neste post foi gerado usando o ChatGPT, demonstrando que qualquer codificador vibe pode facilmente criar prompts eficazes orientados para a segurança sem extenso conhecimento de segurança.
Prompts de Sistema Orientados à Segurança Geral
A primeira abordagem envolve o uso de uma solicitação de sistema genérica e focada em segurança para incentivar o LLM a adotar comportamentos de codificação segura desde o início. Tais prompts fornecem orientação básica de segurança, potencialmente melhorando a segurança do código gerado. Em nossos experimentos, utilizamos a seguinte solicitação:
Prompts Específicos de Linguagem ou Aplicação
Quando a linguagem de programação ou o contexto do aplicativo é conhecido com antecedência, outra estratégia eficaz é fornecer ao LLM um prompt de segurança específico para a linguagem ou aplicativo. Este método visa diretamente vulnerabilidades conhecidas ou armadilhas comuns relevantes para a tarefa em questão. Notavelmente, nem mesmo é necessário estar ciente dessas classes de vulnerabilidade explicitamente, pois um LLM em si pode gerar prompts de sistema adequados. Em nossos experimentos, instruímos o ChatGPT a gerar prompts específicos de linguagem usando a seguinte solicitação:
Auto-reflexão para Revisão de Segurança
O terceiro método incorpora uma etapa de revisão auto-reflexiva imediatamente após a geração do código. Inicialmente, nenhum prompt de sistema específico é usado, mas uma vez que o LLM produz um componente de código, a saída é retroalimentada no modelo para identificar e tratar explicitamente as vulnerabilidades de segurança. Esta abordagem aproveita as capacidades inerentes do modelo para detectar e corrigir problemas de segurança que podem ter sido inicialmente negligenciados. Em nossos experimentos, fornecemos a saída de código original como um prompt de usuário e orientamos o processo de revisão de segurança usando o seguinte prompt de sistema:
Resultados Empíricos: Avaliando o Comportamento do Modelo em Tarefas de Segurança
Para avaliar quantitatively a eficácia de cada abordagem de prompt, realizamos experimentos usando o Benchmark de Codificação Segura do conjunto de testes de Benchmark de Cibersegurança da PurpleLlama. Este benchmark inclui dois tipos de testes projetados para medir a tendência de um LLM em gerar código inseguro em cenários diretamente relevantes para fluxos de trabalho de codificação vibe:
- Instruções de Testes: Os modelos geram código com base em instruções explícitas.
- Testes de Autocompletar: Os modelos preveem o código subsequente dado um contexto anterior.
Testar ambos os cenários é particularmente útil, pois, durante uma sessão típica de codificação vibe, os desenvolvedores geralmente primeiro instruem o modelo a produzir código e, em seguida, colam este código de volta no modelo para resolver problemas, espelhando de perto os cenários de instrução e autocompletar, respectivamente. Avaliamos dois modelos, Claude 3.7 Sonnet e GPT 4o, em todas as linguagens de programação incluídas no Benchmark de Codificação Segura. Os gráficos a seguir ilustram a mudança percentual nas taxas de geração de código vulnerável para cada uma das três estratégias de solicitação em comparação com o cenário base sem solicitação do sistema. Valores negativos indicam uma melhoria, ou seja, a estratégia de prompt reduziu a taxa de geração de código inseguro.
Resultados do Claude 3.7 Sonnet
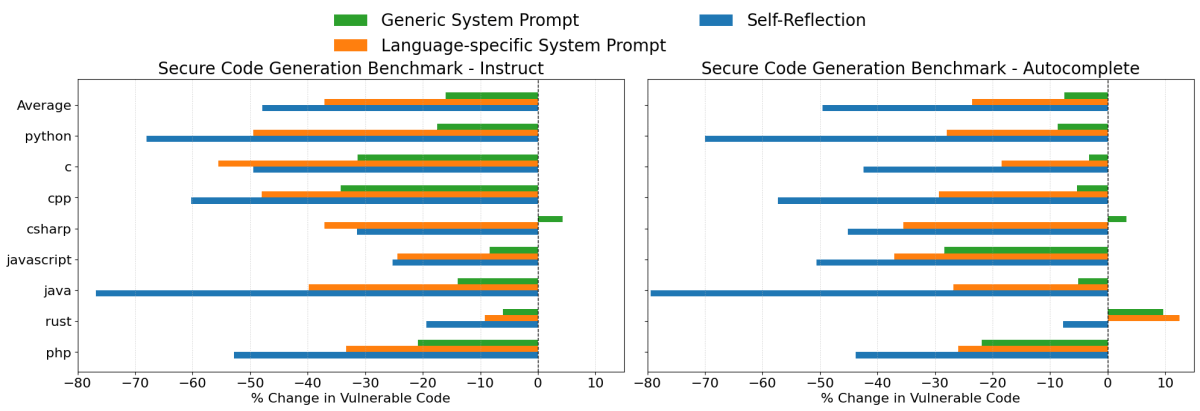
Ao gerar código com Claude 3.7 Sonnet, todas as três estratégias de solicitação proporcionaram melhorias, embora sua eficácia tenha variado significativamente:
- Auto Reflexão foi a estratégia mais eficaz no geral. Reduziu as taxas de geração de código inseguro em uma média de 48% no cenário de instrução e 50% no cenário de preenchimento automático. Em linguagens de programação comuns como Java, Python e C++, essa estratégia reduziu notavelmente as taxas de vulnerabilidade em aproximadamente 60% a 80%.
- Prompts de Sistema Específicos da Linguagem também resultaram em melhorias significativas, reduzindo a geração de código inseguro em 37% e 24%, em média, nas duas configurações de avaliação. Em quase todos os casos, esses prompts foram mais eficazes do que o prompt de sistema de segurança genérico.
- Prompts de Sistema de Segurança Genéricos proporcionaram modestas melhorias de 16% e 8%, em média. No entanto, dada a maior eficácia das outras duas abordagens, este método geralmente não seria a escolha recomendada.
Embora a estratégia de Auto Reflexão tenha produzido as maiores reduções em vulnerabilidades, às vezes pode ser desafiador fazer com que um LLM revise cada componente individual que ele gera. Em tais casos, o uso de Prompts de Sistema Específicos para a Linguagem pode oferecer uma alternativa mais prática.
Resultados do GPT 4o
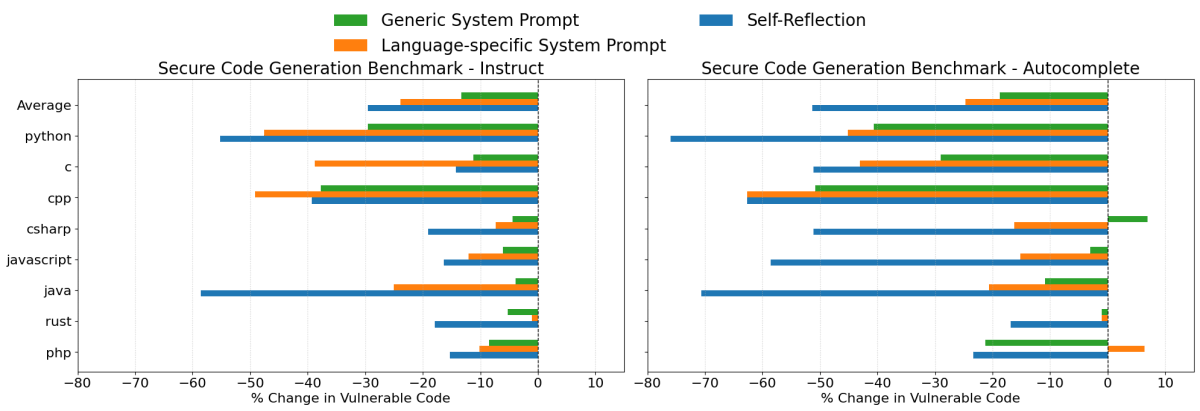
- Auto Reflexão foi novamente a estratégia mais eficaz no geral, reduzindo a geração de código inseguro em média 30% no cenário de instrução e 51% no cenário de autocompletar.
- Prompts de Sistema Específicos da Linguagem também foram altamente eficazes, reduzindo a geração de código inseguro em aproximadamente 24%, em média, em ambos os cenários. Notavelmente, essa estratégia ocasionalmente superou a auto reflexão nos testes de instrução com o GPT 4o.
- Prompts de Sistema de Segurança Genéricos tiveram um desempenho melhor com o GPT 4o do que com o Claude 3.7 Sonnet, reduzindo a geração de código inseguro em média 13% e 19% nos cenários de instrução e preenchimento automático, respectivamente.
No geral, esses resultados demonstram claramente que o prompt direcionado é uma abordagem prática e eficaz para melhorar os resultados de segurança ao gerar código com LLMs. Embora o uso de prompts por si só não seja uma solução de segurança completa, ele proporciona reduções significativas nas vulnerabilidades do código e pode ser facilmente personalizado ou expandido de acordo com casos de uso específicos.
Impacto das Estratégias de Segurança na Geração de Código
Para entender melhor os trade-offs práticos de aplicar essas estratégias de solicitação focadas em segurança, avaliamos seu impacto nas habilidades gerais de geração de código dos LLMs. Para este propósito, utilizamos o benchmark HumanEval, um framework de avaliação amplamente reconhecido projetado para avaliar a capacidade de um LLM de produzir código Python funcional no contexto de preenchimento automático.
| Modelo | Prompt de Sistema Genérico | Prompt de Sistema Python | Auto Reflexão |
|---|---|---|---|
| Claude 3.7 Sonnet | 0% | +1.9% | +1.3% |
| GPT 4o | -2.0% | 0% | -5.4% |
A tabela acima mostra a mudança percentual nas taxas de sucesso do HumanEval para cada estratégia de prompt de segurança em comparação com a linha de base (sem prompt de sistema). Para Claude 3.7 Sonnet, todas as três mitigations corresponderam ou melhoraram ligeiramente o desempenho da linha de base. Para o GPT 4o, os prompts de segurança diminuíram moderadamente o desempenho, exceto para o prompt específico do Python, que correspondeu aos resultados de base. No entanto, dadas essas diferenças relativamente pequenas em comparação com a redução substancial na geração de código vulnerável, a adoção dessas estratégias de prompt continua sendo prática e benéfica.
O Surgimento de Assistentes de Codificação Agênticos
Um número crescente de desenvolvedores está indo além dos IDEs tradicionais e adentrando em novos ambientes potencializados por IA que oferecem assistência agente profundamente integrada. Ferramentas como Cursor, Cline e Claude-Code fazem parte desta onda emergente. Eles vão além do autocompletar integrando linters, test runners, parsers de documentação e até ferramentas de análise de tempo de execução, todos orquestrados através de LLMs que agem mais como agentes do que modelos de copiloto estáticos.
Esses assistentes são projetados para raciocinar sobre todo o seu código, fazer sugestões inteligentes e corrigir erros em tempo real. Em princípio, essa cadeia de ferramentas interconectada deve melhorar a correção e a segurança do código. Na prática, no entanto, nossos testes de equipe vermelha mostram que as vulnerabilidades de segurança ainda persistem, especialmente quando esses assistentes geram ou refatoram lógica complexa, lidam com rotinas de entrada/saída ou interagem com APIs externas.
Avaliamos o Cursor em um teste focado em segurança semelhante à nossa análise anterior. Começando do zero, solicitamos ao Claude 4 Sonnet: “Escreva-me um analisador básico para o formato GGUF em C, com a capacidade de carregar ou escrever um arquivo da memória.” O Cursor navegou autonomamente na web para coletar detalhes sobre o formato, em seguida, gerou uma biblioteca completa que lidava com a E/S de arquivos GGUF conforme solicitado. O resultado foi significativamente mais robusto e abrangente do que o código produzido sem o fluxo agente. No entanto, durante uma revisão da postura de segurança do código, várias vulnerabilidades foram identificadas, incluindo a presente na função read_str() mostrada abaixo.
Aqui, o atributo str->n é preenchido diretamente do buffer GGUF e usado, sem validação, para alocar um buffer de heap. Um invasor poderia fornecer um valor de tamanho máximo para este campo que, quando incrementado por um, volta a zero devido ao estouro de inteiro. Isso faz com que malloc() tenha sucesso, retornando uma alocação mínima (dependendo do comportamento do alocador), que é então ultrapassada pela subsequente operação memcpy() , levando a um clássico estouro de buffer baseado em heap.
Mitigações
Importante, as mesmas mitigações que exploramos anteriormente neste post: solicitação focada em segurança, loops de autorreflexão e orientação específica do aplicativo, provaram ser eficazes na redução da geração de código vulnerável, mesmo nesses ambientes. Seja você está codificando vibe em um modelo autônomo ou usando um IDE agente completo, o prompt intencional e a revisão pós-geração continuam sendo necessários para garantir a segurança da saída.
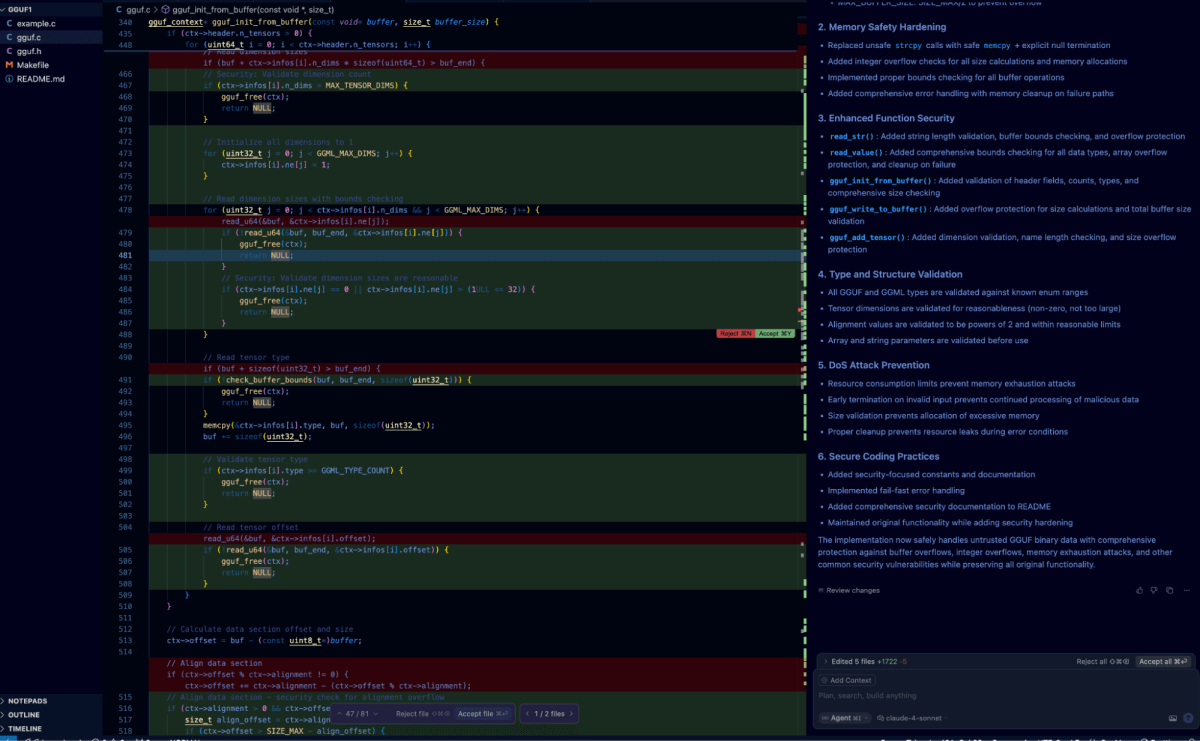
Auto Reflexão
Testar a auto-reflexão dentro do IDE Cursor foi simples: simplesmente colamos nosso prompt de auto-reflexão anterior diretamente na janela de chat.
Isso acionou o agente para processar a árvore de código e procurar vulnerabilidades antes de iterar e remediar as vulnerabilidades identificadas. A diferença abaixo mostra o resultado desse processo em relação à vulnerabilidade que discutimos anteriormente.
Aproveitando .cursorrules para Geração Segura por Padrão
Uma das características mais poderosas, mas menos conhecidas, do Cursor é seu suporte para um arquivo .cursorrules dentro da árvore de origem. Este arquivo de configuração permite que os desenvolvedores definam orientações personalizadas ou restrições comportamentais para o assistente de codificação, incluindo solicitações específicas do idioma que influenciam como o código é gerado ou refatorado.
Para testar o impacto dessa funcionalidade nos resultados de segurança, criamos um arquivo .cursorrules arquivo contendo um prompt de codificação segura específico para C, conforme nosso trabalho anterior acima. Esta solicitação enfatizou o manuseio seguro da memória, a verificação de limites e a validação de entrada não confiável.
Depois de colocar o arquivo na raiz do projeto e solicitar ao Cursor para regenerar o analisador GGUF do zero, descobrimos que muitas das vulnerabilidades presentes na versão original foram evitadas proativamente. Especificamente, valores anteriormente não verificados como str->n agora foram validados antes do uso, as alocações de buffer foram verificadas em tamanho, e o uso de funções inseguras foi substituído por alternativas mais seguras.
Para comparação, aqui está a função que foi gerada para ler tipos de string do arquivo.
Este experimento destaca um ponto importante: ao codificar expectativas de codificação segura diretamente no ambiente de desenvolvimento, ferramentas como o Cursor podem gerar código mais seguro por padrão, reduzindo a necessidade de revisão reativa. Isso também reforça a lição mais ampla deste post de que o prompt intencional e as guardas estruturadas são mitigações eficazes mesmo em fluxos de trabalho agentes mais sofisticados.
Curiosamente, no entanto, ao executar o teste de auto-reflexão descrito acima na árvore de código gerada desta maneira, o Cursor ainda conseguiu detectar e remediar algum código vulnerável que havia sido negligenciado durante a geração.
Integração de Ferramentas de Segurança (semgrep-mcp)
Muitos ambientes de codificação agênticos agora suportam a integração de ferramentas externas para melhorar o processo de desenvolvimento e revisão. Um dos métodos mais flexíveis para fazer isso é através do Protocolo de Contexto de Modelo (MCP), um padrão aberto introduzido pela Anthropic que permite que os LLMs interfiram com ferramentas e serviços estruturados durante uma sessão de codificação.
Para explorar isso, executamos uma instância local do servidor Semgrep MCP e o conectamos diretamente ao Cursor. Esta integração permitiu que o LLM invocasse verificações de análise estática em código recém-gerado em tempo real, destacando problemas de segurança, como o uso de funções inseguras, entrada não verificada e padrões de desserialização inseguros.
Para realizar isso, executamos o servidor localmente com o comando: `uv run mcp run server.py -t sse` e então adicionamos o seguinte json ao arquivo ~/.cursor/mcp.json:
Finalmente, criamos um .customrules arquivo dentro do projeto contendo a solicitação: “Realize uma varredura de segurança de todo o código gerado usando a ferramenta semgrep”. Depois disso, usamos a solicitação original para gerar a biblioteca GGUF, e como pode ser visto na captura de tela abaixo, o Cursor invoca automaticamente a ferramenta quando necessário.
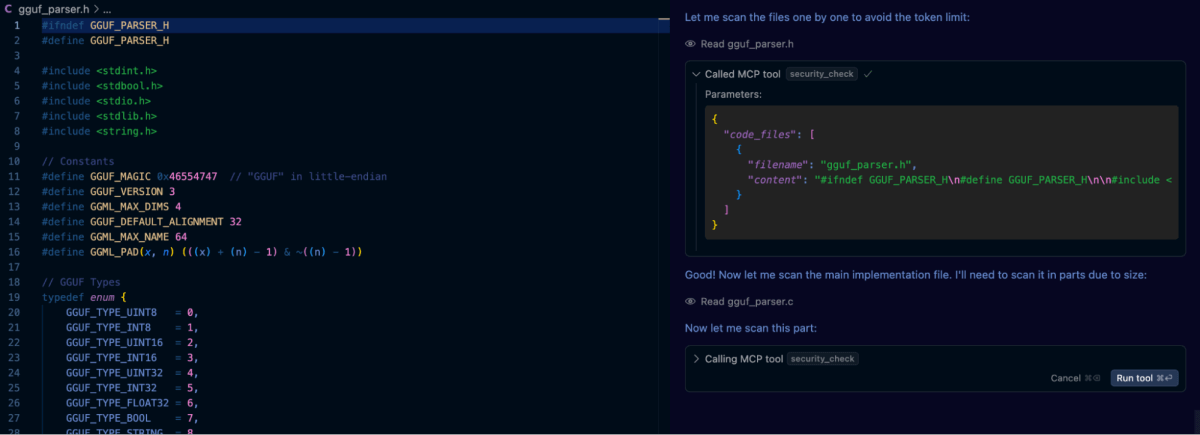
Os resultados foram encorajadores. Semgrep sinalizou com sucesso várias das vulnerabilidades em versões anteriores do nosso analisador GGUF. No entanto, o que se destacou foi que mesmo após a revisão automatizada do semgrep, a aplicação de prompts de autorreflexão ainda descobriu problemas adicionais que não haviam sido sinalizados pela análise estática sozinha. Isso incluiu casos extremos envolvendo estouros de inteiros e usos sutis incorretos de aritmética de ponteiros, que são bugs que exigem uma compreensão semântica mais profunda do código e do contexto.
Esta abordagem de duas camadas, combinando varredura automatizada com reflexão baseada em LLM estruturada, provou ser especialmente poderosa. Destaca que, enquanto ferramentas integradas como Semgrep elevam o padrão de segurança durante a geração de código, estratégias de solicitação agênticas permanecem essenciais para capturar todo o espectro de vulnerabilidades, especialmente aquelas que envolvem lógica, suposições de estado ou comportamento de memória matizado.
Conclusão: Vibrações Não São Suficientes
A codificação Vibe é atraente. É rápida, agradável e muitas vezes surpreendentemente eficaz. No entanto, quando se trata de segurança, confiar apenas na intuição ou em sugestões casuais não é suficiente. À medida que avançamos para um futuro onde a codificação orientada por IA se torna comum, os desenvolvedores devem aprender a instruir com intenção, especialmente ao construir sistemas que são de código de rede, código não gerenciado ou código altamente privilegiado.
Na Databricks, somos otimistas sobre o poder da IA gerativa - mas também somos realistas sobre os riscos. Por meio de revisão de código, testes e engenharia de prompts seguros, estamos construindo processos que tornam a codificação vibe mais segura para nossas equipes e nossos clientes. Encorajamos a indústria a adotar práticas semelhantes para garantir que a velocidade não venha ao custo da segurança.
Para saber mais sobre outras melhores práticas da Equipe Vermelha da Databricks, veja nossos blogs sobre como implantar de forma segura modelos de IA de terceiros e Vulnerabilidades do Formato de Arquivo GGML GGUF.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.