O Guia Definitivo do Profissional para Registros Escaláveis
Padronize e estruture a produção de logs para trabalhos Spark no Databricks, e obtenha mais de seus logs centralizando logs de cluster para ingestão e análise.
por Zach King
- Práticas recomendadas de nível de produção para registro estruturado e prático em trabalhos Databricks.
- Centralização do armazenamento de registros que escala e simplifica o processamento.
- Criação de um painel de AI/BI para analisar registros.
Introdução: Por que a geração de logs é importante
Escalar de algumas dezenas de trabalhos para centenas é um desafio por várias razões, uma das quais é a observabilidade. Observabilidade é a capacidade de entender o sistema analisando componentes como logs, métricas e rastreamentos. Isso é tão relevante para equipes de dados menores com apenas alguns pipelines para monitorar, e motores de computação distribuída como o Spark podem ser desafiadores para monitorar de forma confiável, depurar e criar procedimentos de escalonamento maduros.
O registro é, sem dúvida, o componente de observabilidade mais simples e impactante. Clicar e rolar pelos logs, uma execução de trabalho por vez, não é escalável. Pode ser demorado, difícil de analisar e muitas vezes requer conhecimento especializado do fluxo de trabalho. Sem a construção de padrões de registro maduros em suas pipelines de dados, a solução de problemas ou falhas de trabalho leva significativamente mais tempo, levando a interrupções custosas, níveis ineficazes de escalonamento e fadiga de alerta.
Neste blog, vamos guiá-lo através:
- Passos para se afastar de instruções de impressão básicas e configurar um framework de logging adequado.
- Quando configurar os logs log4j do Spark para usar o formato JSON.
- Por que centralizar o armazenamento de logs do cluster para facilitar a análise e consulta.
- Como criar um painel central de IA/BI no Databricks que você pode configurar em seu próprio espaço de trabalho para uma análise de log mais personalizada.
Considerações Chave de Arquitetura
As seguintes considerações são importantes para adaptar essas recomendações de registro à sua organização:
Bibliotecas de Logging
- Existem várias bibliotecas de logging para Python e Scala. Nossos exemplos usam Log4j e o módulo padrão de logging do Python.
- A configuração para bibliotecas ou frameworks de logging será diferente, e você deve consultar a documentação respectiva se estiver usando uma ferramenta não padrão.
Tipo de cluster
- Os exemplos neste blog se concentrarão principalmente nos seguintes cálculos:
- No momento desta escrita, os seguintes tipos de computação têm menos suporte para entrega de logs, embora as recomendações para frameworks de logging ainda se apliquem:
- Pipelines Declarativos Lakeflow (anteriormente DLT): Suporta apenas registros de eventos
- Trabalhos Serverless: Não suporta entrega de logs
- Cadernos Serverless: Não suporta entrega de registros
Governança de dados
- A governança de dados deve se estender aos logs do cluster, pois os logs podem acidentalmente expor dados sensíveis. Por exemplo, quando você escreve logs em uma tabela, deve considerar quais usuários têm acesso à tabela e utilizar o design de acesso de menor privilégio.
- Demonstraremos como entregar registros de cluster para volumes do Catálogo Unity para um controle de acesso e linhagem mais simples. A entrega de logs para Volumes está em Visualização Pública e é suportada apenas em computação habilitada para o Catálogo Unity com modo de acesso padrão ou modo de acesso dedicado atribuído a um usuário.
- Este recurso não é suportado em computação com modo de acesso dedicado atribuído a um grupo.
Desmembramento da Solução Técnica
A padronização é a chave para a observabilidade de logs em produção. Idealmente, a solução deve acomodar centenas ou até milhares de trabalhos/pipelines/clusters.
Para a implementação completa desta solução, por favor visite este repositório aqui: https://github.com/databricks-industry-solutions/watchtower
Criando um Volume para entrega central de logs
Primeiro, podemos criar um Volume do Catálogo Unity para ser nosso armazenamento central de registros. Não recomendamos o uso de DBFS, pois ele não oferece o mesmo nível de governança de dados. Recomendamos separar os logs para cada ambiente (por exemplo, dev, stage, prod) em diretórios ou volumes diferentes para que o acesso possa ser controlado de forma mais granular.
Você pode criar isso na interface do usuário, dentro de um pacote de ativos do Databricks (AWS | Azure | GCP), ou no nosso caso, com Terraform:
Por favor, certifique-se de que você tem as permissões de LEITURA DE VOLUME e ESCRITA DE VOLUME no volume (AWS | Azure | GCP).
Configure a entrega de logs do Cluster
Agora que temos um local central para colocar nossos logs, precisamos configurar os clusters para entregar seus logs neste destino. Para fazer isso, configure a entrega de logs de computação (AWS | Azure | GCP) no cluster.
Novamente, use a UI, Terraform, ou outro método preferido; nós usaremos os Pacotes de Ativos Databricks (YAML):
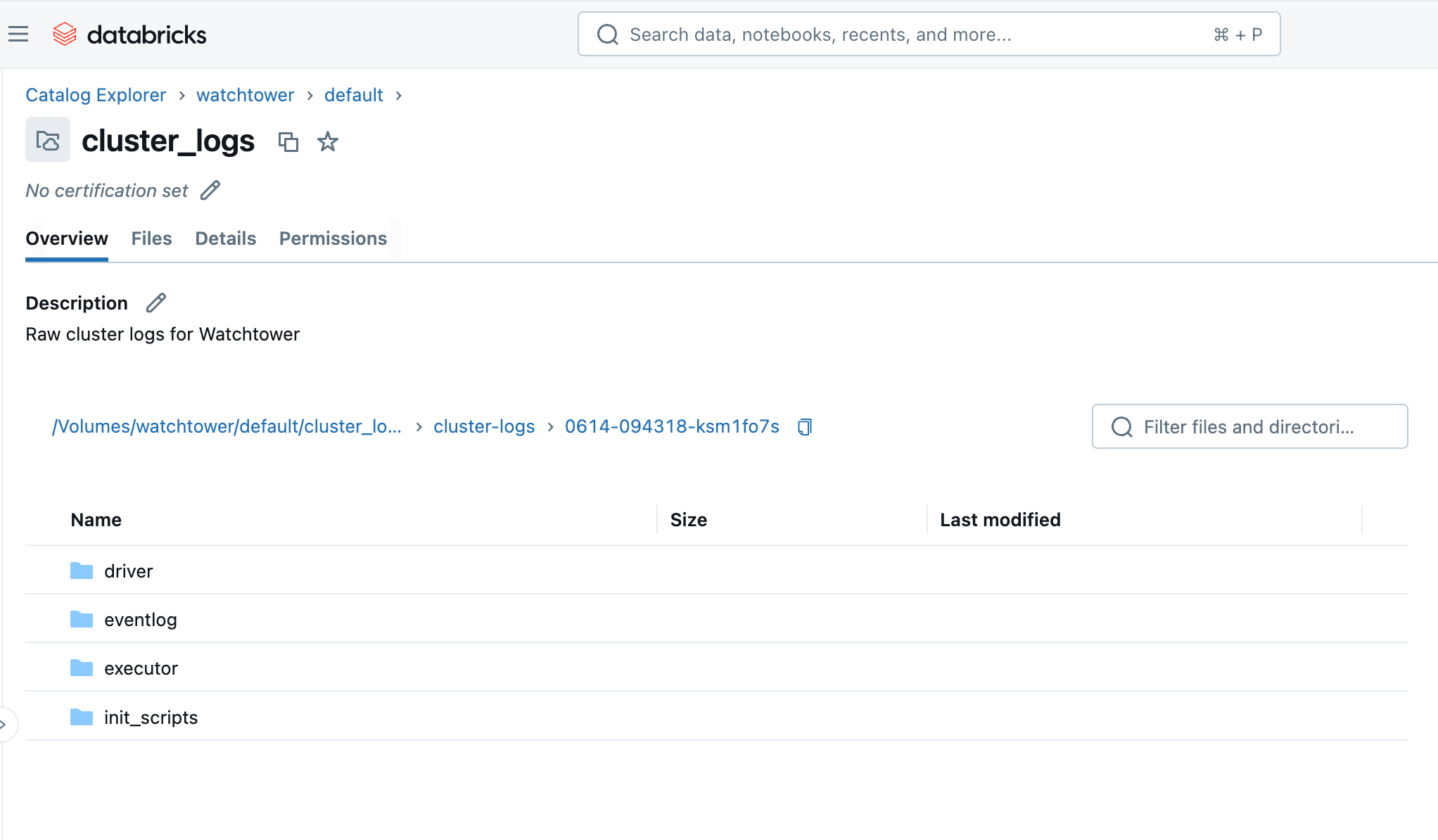
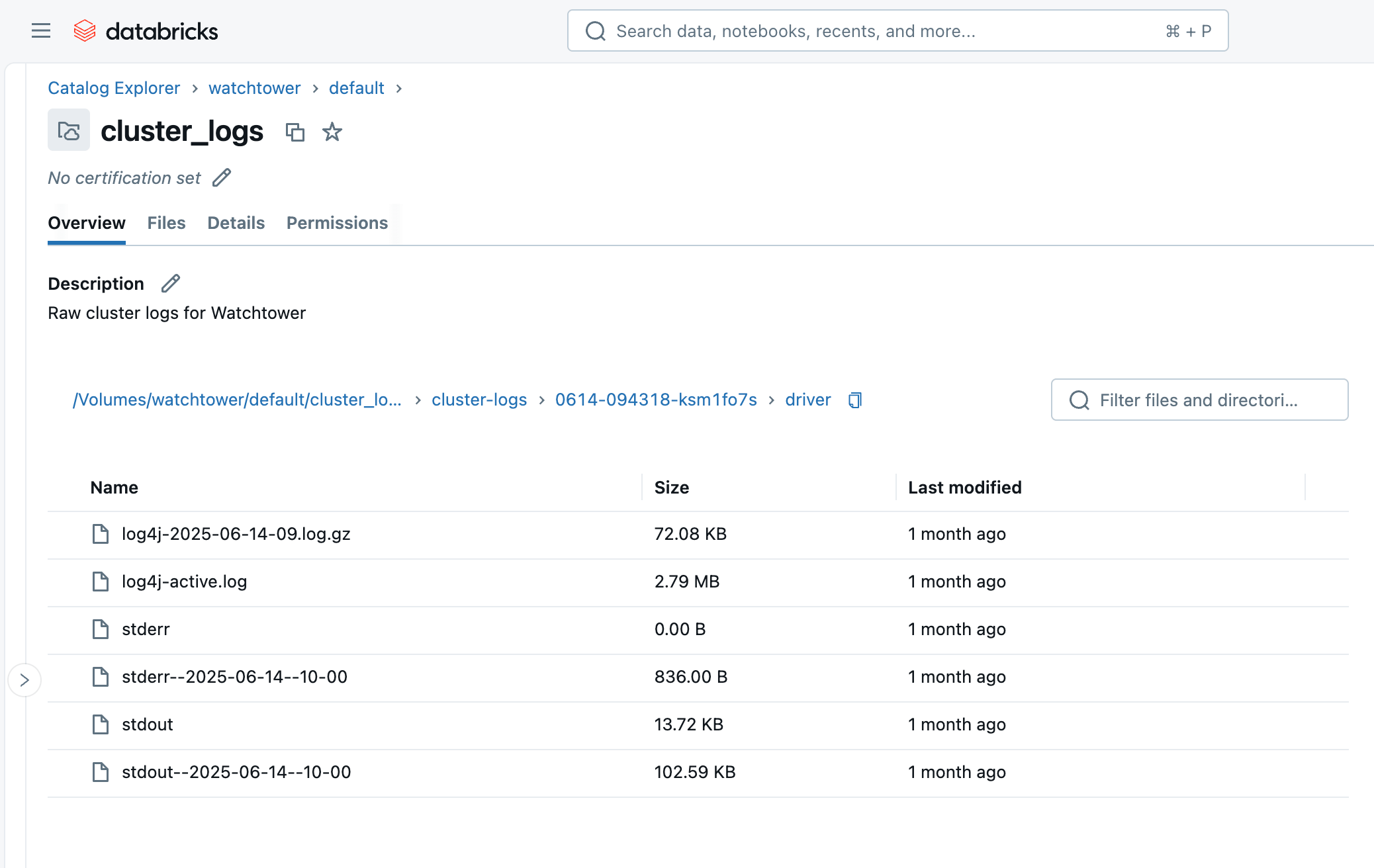
Ao executar o cluster ou o trabalho, em poucos minutos, podemos navegar até o Volume no Catalog Explorer e ver os arquivos chegando. Você verá uma pasta com o ID do cluster (ou seja, 0614-174319-rbzrs7rq), então pastas para cada grupo de registros:
- driver: Registros do nó Driver, que são os que mais nos interessam.
- executor: Registros de cada executor Spark no cluster.
- eventlog: registros de eventos que você pode encontrar na aba "Event Log" do cluster, como início do cluster, término do cluster, redimensionamento, etc.
- init_scripts: Esta pasta é gerada se o cluster tiver scripts de inicialização, como o nosso. Subpastas são criadas para cada nó no cluster, e então os logs stdout e stderr podem ser encontrados para cada script de inicialização que foi executado no nó.
Imposição de Padrões: Política de Cluster
Administradores de espaço de trabalho devem impor configurações padrão sempre que possível. Isso significa restringir o acesso à criação de clusters, e dar aos usuários uma Política de Cluster (AWS | Azure | GCP) com a configuração de log do cluster definida para valores fixos como mostrado abaixo:
Definir esses atributos para um valor “fixo” configura automaticamente o destino correto do Volume e impede que os usuários esqueçam ou alterem a propriedade.
Agora, em vez de configurar explicitamente o cluster_log_conf em seu pacote de ativos YAML, podemos simplesmente especificar o ID da política de cluster a ser usado:
Mais do que apenas um comando print()
Embora as declarações print() possam ser úteis para depuração rápida durante o desenvolvimento, elas são insuficientes em ambientes de produção por vários motivos:
- Falta de estrutura: As declarações print produzem texto não estruturado, tornando difícil analisar, consultar e analisar registros em grande escala.
- Contexto limitado: Eles geralmente carecem de informações contextuais essenciais como timestamps, níveis de log (por exemplo, INFO, WARNING, ERROR), módulo de origem, ou ID do trabalho, que são cruciais para uma solução de problemas eficaz.
- Overhead de desempenho: Declarações print excessivas podem introduzir overhead de desempenho, pois acionam uma avaliação no Spark. As declarações print também escrevem diretamente na saída padrão (stdout) sem buffer ou tratamento otimizado.
- Sem controle sobre a verbosidade: Não há um mecanismo integrado para controlar a verbosidade das instruções de impressão, levando a logs que são muito barulhentos ou insuficientes em detalhes.
Frameworks de registro adequados, como Log4j para Scala/Java (JVM) ou o módulo logging integrado para Python, resolvem todos esses problemas e são preferidos em produção. Esses frameworks nos permitem definir níveis de registro ou verbosidade, formatos de saída amigáveis para máquinas como JSON e definir destinos flexíveis.
Por favor, note também a diferença entre stdout vs. stderr vs. log4j nos registros do driver Spark:
- stdout: Buffer de saída padrão do JVM do nó do driver. É aqui que as declarações
print()e a saída geral são escritas por padrão. - stderr: Buffer de erro padrão do nó driver JVM. Normalmente é onde as exceções/rastreamentos de pilha são escritos, e muitas bibliotecas de log também usam stderr como padrão.
- log4j: Especificamente filtrado para mensagens de registro escritas com um logger log4j. Você pode ver essas mensagens em stderr também.
Python
Em Python, isso envolve importar o módulo de logging padrão, definir um formato JSON, e definir seu nível de log.
A partir do Spark 4, ou Databricks Runtime 17.0+, um logger estruturado simplificado está integrado ao PySpark: https://spark.apache.org/docs/latest/api/python/development/logger.html. O exemplo a seguir pode ser adaptado para PySpark 4 trocando a instância do logger por uma instância pyspark.logger.PySparkLogger.
Grande parte deste código é apenas para formatar nossas mensagens de log Python como JSON. JSON é semi-estruturado e fácil de ler tanto para humanos quanto para máquinas, o que vamos apreciar ao ingerir e consultar esses logs mais tarde neste blog. Se pulássemos esta etapa, você pode se encontrar dependendo de expressões regulares complexas e ineficientes para adivinhar qual parte da mensagem é o nível de log versus um timestamp versus a mensagem, etc.
Claro, isso é bastante verboso para incluir em cada caderno ou pacote Python. Para evitar duplicação, este código padrão pode ser empacotado como código utilitário e carregado em seus trabalhos de algumas maneiras:
- Coloque o código padrão em um módulo Python no espaço de trabalho e use importações de arquivos do espaço de trabalho (AWS | Azure | GCP) para executar o código no início de seus notebooks principais.
- Construa o código padrão em um arquivo de roda Python e carregue-o nos clusters como uma Biblioteca (AWS | Azure | GCP).
Scala
Os mesmos princípios se aplicam ao Scala, mas usaremos o Log4j em vez disso, ou mais especificamente, a abstração SLF4j:
Quando visualizamos os Logs do Driver na UI, podemos encontrar nossas mensagens de log INFO e WARN sob Log4j. Isso ocorre porque o nível de log padrão é INFO, então as mensagens DEBUG e TRACE não são escritas.

Os registros Log4j não estão no formato JSON, no entanto! Veremos como corrigir isso a seguir.
Registro de logs para Spark Structured Streaming
Para capturar informações úteis para trabalhos de streaming, como métricas de fonte e pia de streaming e progresso da consulta, também podemos implementar o StreamingQueryListener do Spark.
Em seguida, registre o ouvinte de consulta com sua sessão Spark:
Ao executar uma consulta de streaming estruturado Spark, você agora verá algo como o seguinte nos logs log4j (nota: usamos uma fonte Delta e sink neste caso; as métricas detalhadas podem variar por fonte/sink):
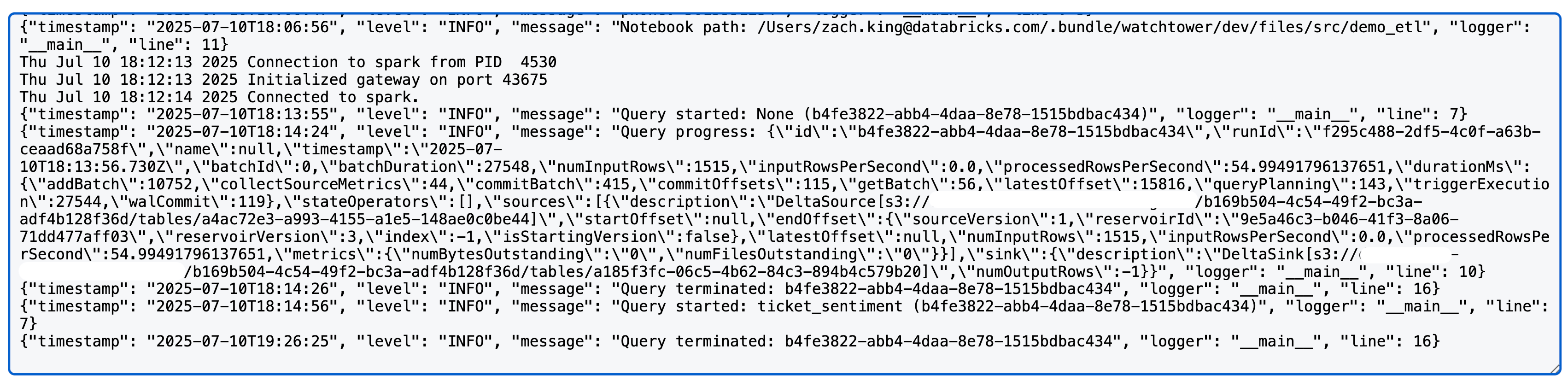
Configurando os Logs Log4j do Spark
Até agora, só afetamos o logging do nosso próprio código. No entanto, olhando para os Logs do Driver do cluster, podemos ver muitos mais logs - a maioria, na verdade - são dos internos do Spark. Quando criamos loggers Python ou Scala em nosso código, isso não influencia os logs internos do Spark.
Agora vamos revisar como configurar os registros Spark para o nó Driver para que eles usem o formato JSON padrão que podemos facilmente analisar.
Log4j usa um arquivo de configuração local para controlar a formatação e os níveis de registro, e podemos modificar essa configuração usando um Script de Inicialização de Cluster (AWS | Azure | GCP). Por favor, note que antes do DBR 11.0, o Log4j v1.x era usado, que usa um Java Properties (log4j.properties) . DBR 11.0+ usa Log4j v2.x que usa um arquivo XML (log4j2.xml) em vez disso.
O arquivo log4j2.xml padrão nos nós do driver Databricks usa um PatternLayout para um formato de log básico:
Vamos mudar isso para o JsonTemplateLayout usando o seguinte script de inicialização:
Este script de inicialização simplesmente troca o PatternLayout pelo JsonTemplateLayout. Observe que os scripts de inicialização são executados em todos os nós do cluster, incluindo nós de trabalho; neste exemplo, estamos apenas configurando os logs do Driver por uma questão de verbosidade e porque só estaremos ingerindo os logs do Driver mais tarde. No entanto, o arquivo de configuração também pode ser encontrado nos nós de trabalho em /home/ubuntu/databricks/spark/dbconf/log4j/executor/log4j.properties.
Você pode adicionar a este script conforme necessário, ou cat $LOG4J2_PATH para visualizar o conteúdo completo do arquivo original para facilitar as modificações.
Em seguida, faremos o upload deste script de inicialização para o Volume do Catálogo Unity. Para organização, criaremos um Volume separado em vez de reutilizar nosso volume de logs brutos de antes, e isso pode ser realizado no Terraform assim:
Isso criará o Volume e automaticamente fará o upload do script de inicialização para ele.
Mas ainda precisamos configurar nosso cluster para usar este script de inicialização. Anteriormente, usamos uma Política de Cluster para impor o destino de Entrega de Log, e podemos fazer o mesmo tipo de imposição para este script de inicialização para garantir que nossos logs Spark sempre tenham a formatação JSON estruturada. Vamos modificar o JSON da política anterior adicionando o seguinte:
Novamente, usar um valor fixo aqui garante que o script de inicialização sempre será definido no cluster.
Agora, se executarmos novamente nosso código Spark de antes, podemos ver que todos os Logs do Driver na seção Log4j estão bem formatados como JSON!
Ingestão dos registros
Neste ponto, abandonamos as instruções de impressão básicas para o logging estruturado, unificamos isso com os logs do Spark e direcionamos nossos logs para um Volume central. Isso já é útil para navegar e baixar os arquivos de log usando o Catalog Explorer ou Databricks CLI: databricks fs cp dbfs:/Volumes/watchtower/default/cluster_logs/cluster-logs/$CLUSTER_ID . --recursive.
No entanto, o verdadeiro valor deste hub de logs é visto quando ingerimos os logs em uma tabela do Catálogo Unity. Isso fecha o ciclo e nos dá uma tabela contra a qual podemos escrever consultas expressivas, realizar agregações e até detectar problemas comuns de desempenho. Tudo isso veremos em breve!
Ingerir os logs é fácil graças aos Pipelines Declarativos Lakeflow, e empregaremos uma arquitetura de medalhão com Auto Loader para carregar incrementalmente os dados.
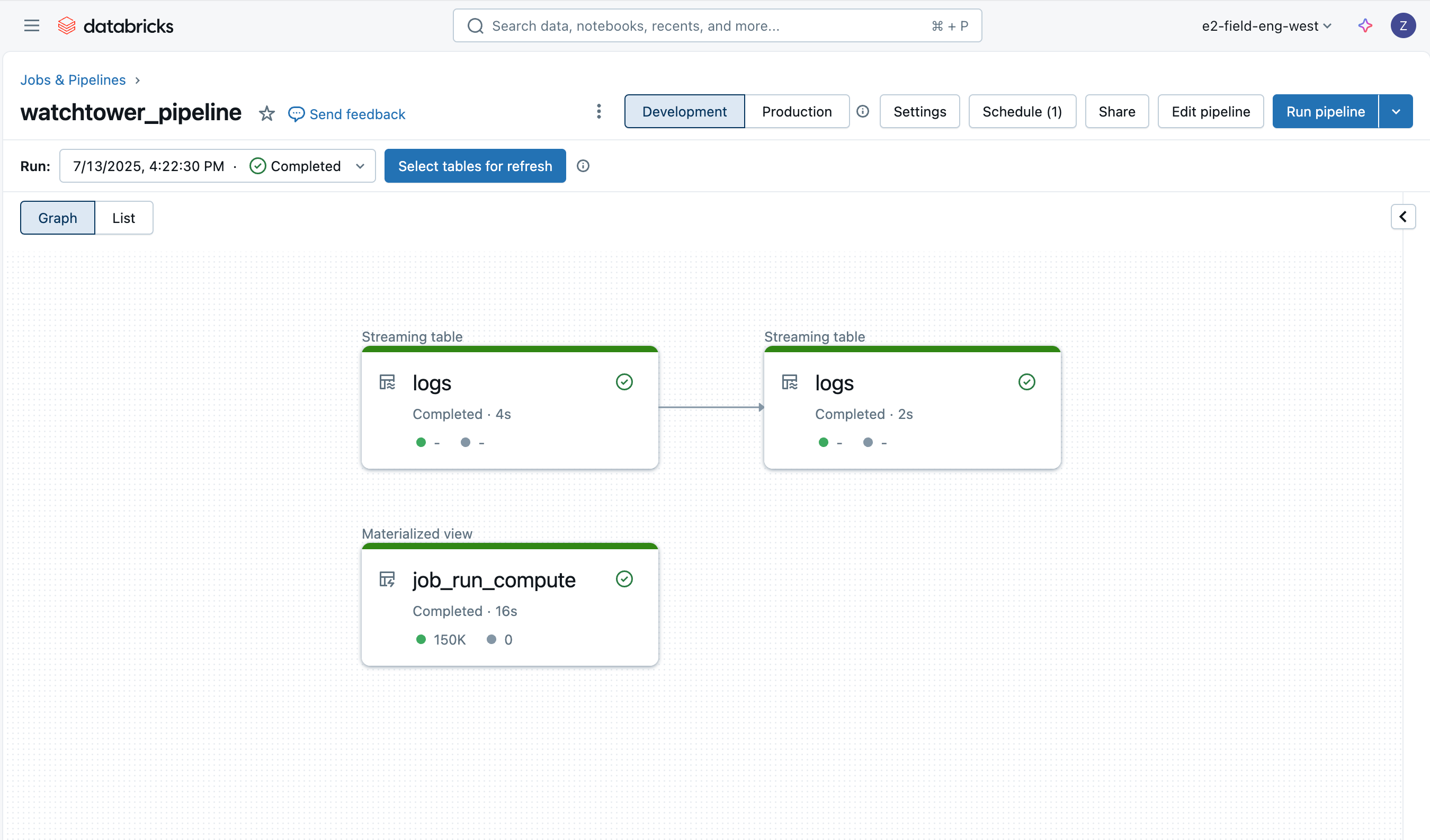
Logs Bronze
A primeira tabela é simplesmente uma tabela bronze para carregar os dados brutos do log do driver, adicionando algumas colunas adicionais como o nome do arquivo, tamanho, caminho e último tempo de modificação.
Usando as expectativas do Pipeline Declarativo Lakeflow (AWS | Azure | GCP), também obtemos monitoramento nativo de qualidade de dados. Veremos mais dessas verificações de qualidade de dados nas outras tabelas.
Logs Prateados
A próxima tabela (prata) é mais crítica; gostaríamos de analisar cada linha de texto dos logs, extraindo informações como o nível de log, timestamp do log, ID do cluster e fonte do log (stdout/stderr/log4j).
Nota: embora tenhamos configurado o registro JSON tanto quanto possível, sempre teremos algum grau de texto bruto em forma não estruturada de outras ferramentas lançadas na inicialização. A maioria desses estará em stdout, e nossa transformação prata demonstra uma maneira de manter a análise flexível, tentando analisar a mensagem como JSON e recorrendo a regex apenas quando necessário.
IDs de Cálculo
A última tabela em nosso pipeline é uma visão materializada construída sobre as Tabelas de Sistema Databricks. Ela armazenará os IDs de computação usados por cada execução de trabalho e simplificará futuras junções quando desejarmos recuperar o ID do trabalho que produziu certos logs. Note que um único trabalho pode ter vários clusters, bem como tarefas SQL que executam em um armazém em vez de um cluster de trabalho, daí a utilidade de pré-computar esta referência.
Implementando o Pipeline
O pipeline pode ser implantado através da UI, Terraform, ou dentro do nosso pacote de ativos. Usaremos o pacote de ativos e forneceremos o seguinte recurso YAML:
Analise Logs com Painel AI/BI
Finalmente, podemos consultar os dados de log em trabalhos, execuções de trabalho, clusters e espaços de trabalho. Graças às otimizações das tabelas gerenciadas pelo Catálogo Unity, essas consultas também serão rápidas e escaláveis. Vamos ver alguns exemplos.
Top N Erros
Esta consulta encontra os erros mais comuns encontrados, ajudando a priorizar e melhorar o tratamento de erros. Também pode ser um indicador útil para escrever manuais que cobrem os problemas mais comuns.
Top N Trabalhos por Erros
Esta consulta classifica os trabalhos pelo número de erros observados, ajudando a encontrar os trabalhos mais problemáticos.
Dashboards de AI/BI
Se colocarmos essas consultas em um painel de AI/BI Databricks, agora temos uma interface central para pesquisar e filtrar todos os logs, detectar problemas comuns e solucionar problemas.
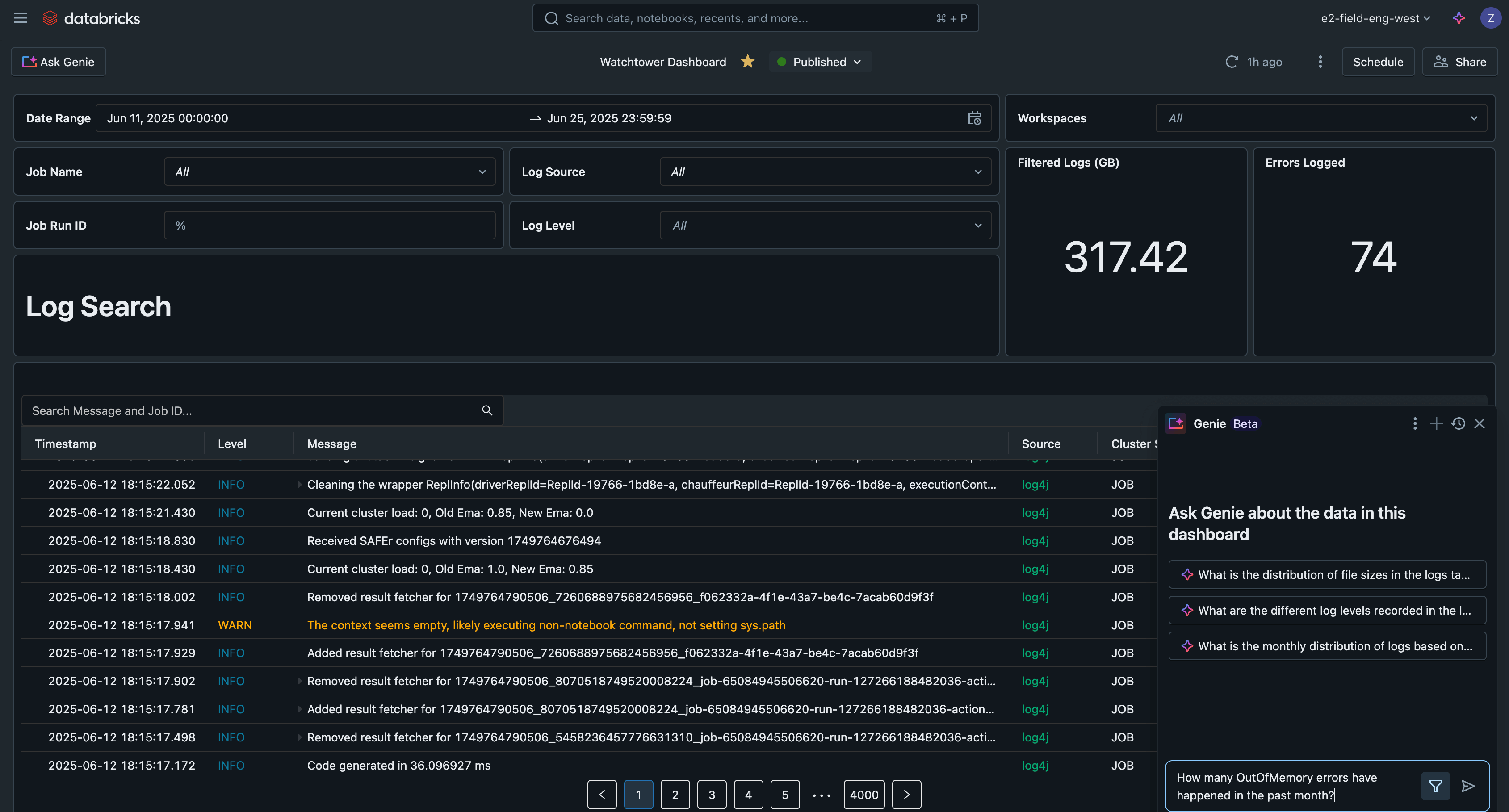
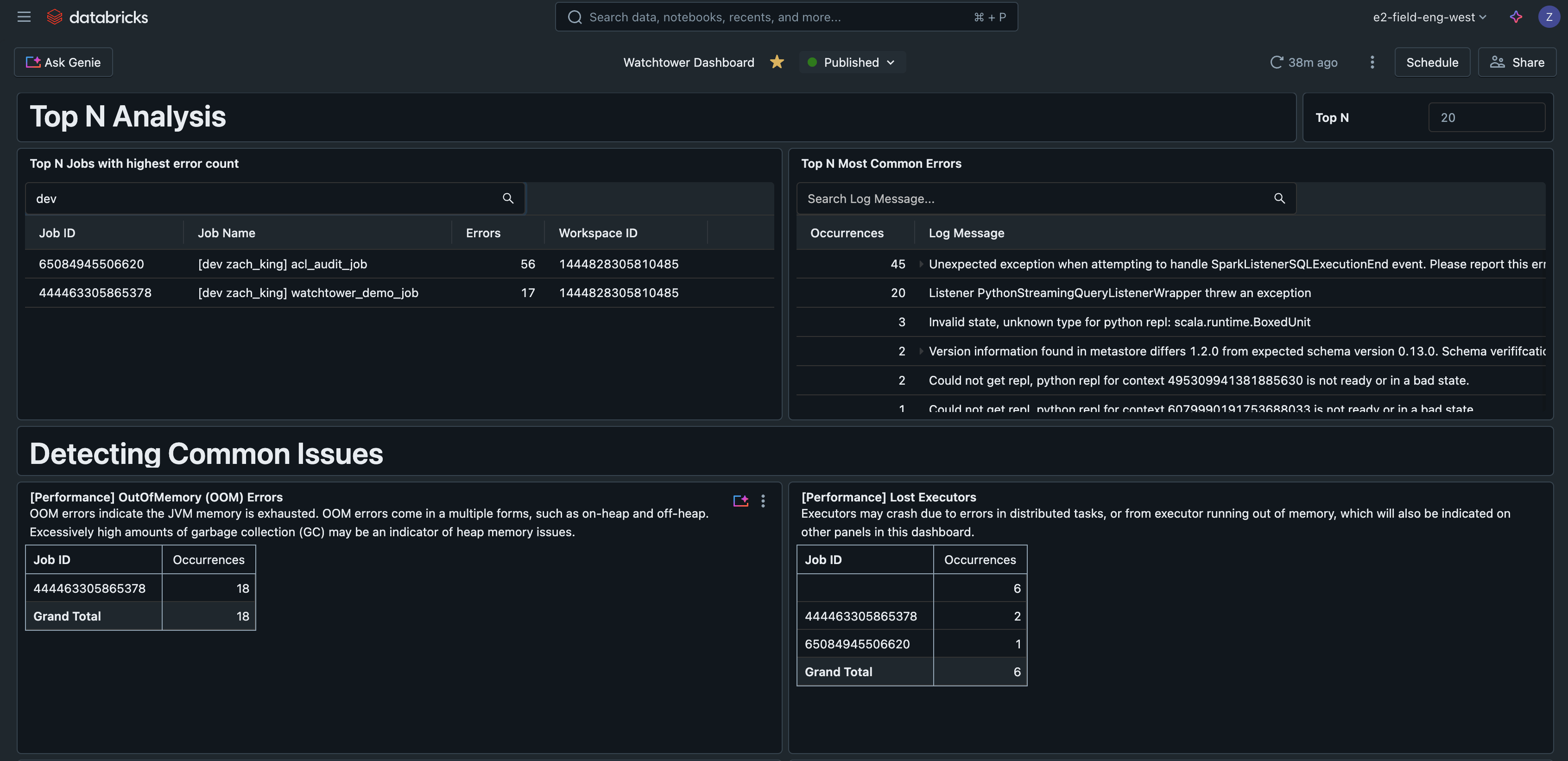
Este exemplo de painel de IA/BI está disponível junto com todo o outro código para esta solução em GitHub.
Cenários do Mundo Real
Como demonstramos no painel de referência, existem muitos casos práticos que uma solução de registro como esta suporta, como:
- Pesquise logs em todas as execuções para um único trabalho
- Pesquisar logs em todos os trabalhos
- Analisando registros para os erros mais comuns
- Encontre trabalhos com o maior número de erros
- Monitoramento de problemas de desempenho ou avisos:
- Sobrecarga do GC
- Derramamento do Spark
- Detectando PII em registros
Em um cenário realista, os profissionais estão pulando manualmente de uma execução de trabalho para a próxima para entender os erros, e não sabem como priorizar os alertas. Ao não apenas estabelecer registros robustos, mas também uma tabela padrão para armazená-los, os profissionais podem simplesmente consultar os registros para o erro mais comum a ser priorizado. Digamos que haja 1 execução de trabalho falhada devido a um erro de OutOfMemory, enquanto há 10 trabalhos falhados devido a um erro de permissão repentino quando SELECT foi revogado sem intenção do principal de serviço; sua equipe de plantão normalmente está fatigada pelo aumento de alertas, mas agora é capaz de perceber rapidamente que o erro de permissão é uma prioridade maior e começa a trabalhar para resolver o problema a fim de restaurar os 10 trabalhos.
Da mesma forma, os profissionais muitas vezes precisam verificar registros para várias execuções do mesmo trabalho para fazer comparações. Um exemplo real é correlacionar carimbos de data/hora de uma mensagem de log específica de cada execução em lote do trabalho, com outra métrica ou gráfico (ou seja, quando “lote concluído” foi registrado vs. um gráfico de taxa de solicitações em uma API que você chamou). Ingerir os logs simplifica isso, então podemos consultar a tabela e filtrar pelo ID do trabalho, e opcionalmente uma lista de IDs de execução de trabalho, sem precisar clicar em cada execução uma de cada vez.
Considerações Operacionais
- Os logs do Cluster são entregues a cada cinco minutos e compactados por hora no seu destino escolhido.
- Lembre-se de usar tabelas gerenciadas pelo Catálogo Unity com Otimização Preditiva e Agrupamento Líquido para obter o melhor desempenho nas tabelas.
- Logs brutos não precisam ser armazenados indefinidamente, que é o comportamento padrão quando a entrega de log do cluster é usada. Em nosso pipeline Declarative Pipelines, use a opção Auto Loader
cloudFiles.cleanSourcepara deletar arquivos após um período de retenção especificado, também definido comocloudFiles.cleanSource.retentionDuration. Você também pode usar regras de ciclo de vida de armazenamento em nuvem. - Os logs do executor também podem ser configurados e ingeridos, mas geralmente não são necessários, pois a maioria dos erros são propagados para o driver de qualquer maneira.
- Considere adicionar Alertas SQL do Databricks (AWS | Azure | GCP) para alertas automatizados com base na tabela de logs ingeridos.
- Os Pipelines Declarativos Lakeflow têm seus próprios logs de eventos, que você pode usar para monitorar e inspecionar a atividade do pipeline. Este log de eventos também pode ser escrito no Catálogo Unity.
Integrando e Trabalhos a serem feitos
Os clientes também podem desejar integrar seus logs com ferramentas de registro populares como Loki, Logstash ou AWS CloudWatch. Embora cada um tenha seus próprios requisitos de autenticação, configuração e conectividade, todos seguiriam um padrão muito semelhante usando o script de inicialização do cluster para configurar e muitas vezes executar um agente de encaminhamento de log.
Principais Conclusões
Para recapitular, as principais lições são:
- Use frameworks de log padronizados, não declarações de impressão, em produção.
- Use scripts de inicialização com escopo de cluster para personalizar a configuração do Log4j.
- Configure a entrega de logs do cluster para centralizar os logs.
- Use tabelas gerenciadas pelo Catálogo Unity com Otimização Preditiva e Agrupamento Líquido para o melhor desempenho da tabela.
- Databricks permite que você ingira e enriqueça logs para uma análise mais aprofundada.
Passos seguintes
Comece a produzir seus logs hoje mesmo, conferindo o repositório GitHub para esta solução completa aqui: https://github.com/databricks-industry-solutions/watchtower!
Databricks Arquitetos de Soluções de Entrega (DSAs) aceleram iniciativas de Dados e IA em organizações. Eles fornecem liderança arquitetônica, otimizam plataformas para custo e desempenho, aprimoram a experiência do desenvolvedor e conduzem a execução bem-sucedida do projeto. DSAs preenchem a lacuna entre a implantação inicial e as soluções de produção, trabalhando de perto com várias equipes, incluindo engenharia de dados, líderes técnicos, executivos e outros stakeholders para garantir soluções personalizadas e um tempo de valor mais rápido. Para se beneficiar de um plano de execução personalizado, orientação estratégica e suporte durante toda a sua jornada de dados e IA de um DSA, por favor, entre em contato com sua Equipe de Contas Databricks.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.