Processando Milhões de Eventos de Milhares de Aeronaves com Uma Pipeline Declarativa
Construindo Sistemas Escaláveis com Lakeflow Declarative Pipelines e PySpark Custom Data Sources
por Frank Munz
- Transmita dados de voo ADS-B ao vivo com uma fonte de dados personalizada PySpark e tabelas de streaming Lakeflow.
- Pré-agregue métricas com visualizações materializadas e consulte-as instantaneamente em AI/BI Genie ou SQL.
- Aprenda as escolhas de design, armadilhas e verificações de qualidade de dados que permitem que este pipeline funcione em escala de produção - até centenas de milhões de eventos por dia.
A cada segundo, dezenas de milhares de aeronaves geram eventos de IoT em todo o mundo - desde um pequeno Cessna transportando quatro turistas sobre o Grand Canyon até um Airbus A380 partindo de Frankfurt com 570 passageiros, transmitindo localização, altitude e rota de voo em sua rota transatlântica para Nova York.
Assim como os controladores de tráfego aéreo que devem atualizar continuamente rotas de voo complexas à medida que as condições climáticas e de tráfego evoluem, os engenheiros de dados precisam de plataformas que possam lidar com fluxos de dados aviónicos de alta capacidade, baixa latência e missão crítica. Para nenhum desses sistemas críticos para a missão, pausar o processamento é uma opção.
Construir tais pipelines de dados significava lidar com centenas de linhas de código, gerenciar clusters de computação e configurar permissões complexas para fazer o ETL funcionar. Esses dias acabaram. Com Lakeflow Declarative Pipelines, você pode construir pipelines de streaming prontos para produção em minutos usando SQL simples (ou Python, se preferir), rodando em computação serverless com governança unificada e controle de acesso refinado.
Este artigo orienta você através da arquitetura de casos de uso de transporte, logística e frete. Ele demonstra um pipeline que ingere dados de aviação em tempo real de todas as aeronaves atualmente voando sobre a América do Norte, processando atualizações de status de voo ao vivo com apenas algumas linhas de código declarativo.
Transmissão em Tempo Real em Escala
A maioria dos tutoriais de streaming promete exemplos do mundo real, mas entrega conjuntos de dados sintéticos que ignoram o volume, a velocidade e a variedade em escala de produção. A indústria da aviação processa alguns dos fluxos de dados em tempo real mais exigentes do mundo - as posições das aeronaves são atualizadas várias vezes por segundo com requisitos de baixa latência para aplicações críticas de segurança.
A Rede OpenSky, um projeto colaborativo de pesquisadores da Universidade de Oxford e outros institutos de pesquisa, oferece acesso gratuito a dados de aviação ao vivo para uso não comercial. Isso nos permite demonstrar arquiteturas de streaming de nível empresarial com dados genuinamente atraentes.
Embora rastrear voos no seu telefone seja uma diversão casual, o mesmo fluxo de dados alimenta operações logísticas de bilhões de dólares: autoridades portuárias coordenam operações terrestres, serviços de entrega integram horários de voos em notificações, e agentes de carga acompanham movimentos de carga em cadeias de suprimentos globais.
Inovação Arquitetônica: Fontes de Dados Personalizadas como Cidadãos de Primeira Classe
Arquiteturas tradicionais exigem uma quantidade significativa de codificação e sobrecarga de infraestrutura para conectar sistemas externos à sua plataforma de dados. Para ingerir fluxos de dados de terceiros, você normalmente precisa pagar por soluções SaaS de terceiros ou desenvolver conectores personalizados com gerenciamento de autenticação, controle de fluxo e tratamento de erros complexos.
Na Plataforma de Inteligência de Dados, o Lakeflow Connect aborda essa complexidade para sistemas de negócios corporativos como Salesforce, Workday e ServiceNow, fornecendo um número cada vez maior de conectores gerenciados que lidam automaticamente com autenticação, captura de alterações de dados e recuperação de erros.
A fundação OSS do Lakeflow, Apache Spark™, vem com um extenso ecossistema de fontes de dados integradas que podem ler de dezenas de sistemas técnicos: desde formatos de armazenamento em nuvem como Parquet, Iceberg ou Delta.io até barramentos de mensagens como Apache Kafka, Pulsar ou Amazon Kinesis. Por exemplo, você pode facilmente se conectar a um tópico Kafka usando spark.readStream.format("kafka"), e essa sintaxe familiar funciona de maneira consistente em todas as fontes de dados suportadas.
No entanto, há uma lacuna ao acessar sistemas de terceiros por meio de APIs arbitrárias, caindo entre os sistemas corporativos que o Lakeflow Connect cobre e os conectores baseados na tecnologia Spark. Alguns serviços fornecem APIs REST que não se encaixam em nenhuma das categorias, mas as organizações precisam desses dados em seu lakehouse.
Fontes de dados personalizadas PySpark preenchem essa lacuna com uma camada de abstração limpa que torna a integração de API tão simples quanto qualquer outra fonte de dados.
Para este blog, implementei uma fonte de dados personalizada PySpark para a OpenSky Network e a disponibilizei como uma simples instalação pip. A fonte de dados encapsula chamadas de API, autenticação e tratamento de erros. Você simplesmente substitui "kafka" por "opensky" no exemplo acima, e o resto funciona de maneira idêntica:
Usando essa abstração, as equipes podem se concentrar na lógica de negócios em vez de sobrecarga de integração, mantendo a mesma experiência do desenvolvedor em todas as fontes de dados.
O padrão de fonte de dados personalizada é uma solução arquitetônica genérica que funciona perfeitamente para qualquer API externa - dados de mercado financeiro, redes de sensores IoT, fluxos de mídia social ou sistemas de manutenção preditiva. Desenvolvedores podem aproveitar a familiar API DataFrame do Spark sem se preocupar com o agrupamento de conexões HTTP, limitação de taxa, ou tokens de autenticação.
Essa abordagem é particularmente valiosa para sistemas de terceiros onde o esforço de integração justifica a construção de um conector reutilizável, mas não existe uma solução gerenciada de nível empresarial.
Tabelas de Streaming: Ingestão Exata-Uma Vez Feita de Forma Simples
Agora que estabelecemos como as fontes de dados personalizadas lidam com a conectividade da API, vamos examinar como as tabelas de streaming processam esses dados de forma confiável. Os fluxos de dados do IoT apresentam desafios específicos em relação à detecção de duplicatas, eventos que chegam tarde e garantias de processamento. Frameworks de streaming tradicionais requerem coordenação cuidadosa entre vários componentes para alcançar a semântica de apenas uma vez.
Tabelas de streaming em Lakeflow Declarative Pipelines resolvem essa complexidade através de semântica declarativa. Lakeflow se destaca tanto no processamento de baixa latência quanto em aplicações de alto rendimento.
Este pode ser um dos primeiros artigos a mostrar tabelas de streaming alimentadas por fontes de dados personalizadas, mas não será o último. Com pipelines declarativos e fontes de dados PySpark agora de código aberto e amplamente disponíveis no Apache Spark™, essas capacidades estão se tornando acessíveis para desenvolvedores em todos os lugares.
O código acima acessa os dados de aviação como um fluxo de dados. O mesmo código funciona de maneira idêntica para processamento de streaming e em lote. Com o Lakeflow, você pode configurar o modo de execução do pipeline e acionar a execução usando um fluxo de trabalho como o Lakeflow Jobs.
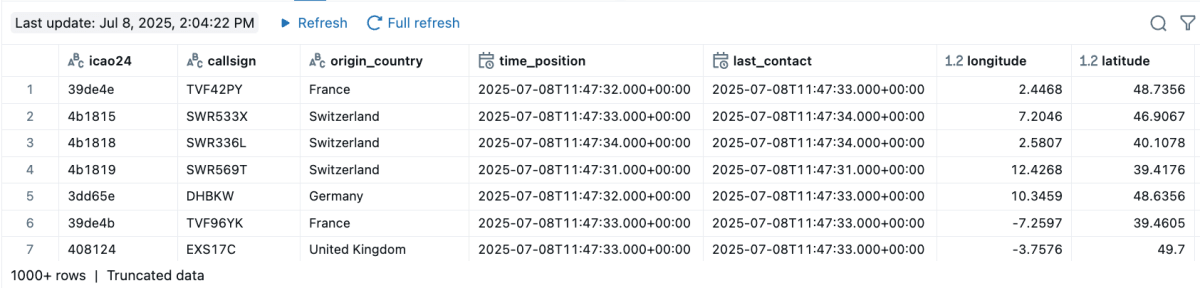
Esta breve implementação demonstra o poder da programação declarativa. O código acima resulta em uma tabela de streaming com dados aviónicos ao vivo continuamente ingeridos - é a implementação completa que transmite dados de cerca de 10.000 aviões atualmente voando sobre os EUA (dependendo da hora do dia). A plataforma cuida de tudo o resto - autenticação, processamento incremental, recuperação de erros e escalonamento.
Cada detalhe, como o sinal de chamada dos aviões, localização atual, altitude, velocidade, direção e destino, é ingerido na tabela de streaming. O exemplo não é um trecho de código, mas uma implementação que fornece dados reais e acionáveis em escala.
O aplicativo completo pode ser facilmente escrito de forma interativa, do zero com o novo Editor de Pipelines Declarativos Lakeflow. O novo editor usa arquivos por padrão, então você pode adicionar o pacote de fonte de dados pyspark-data-sources diretamente no editor em Configurações/Ambientes em vez de executar pip install em um notebook.
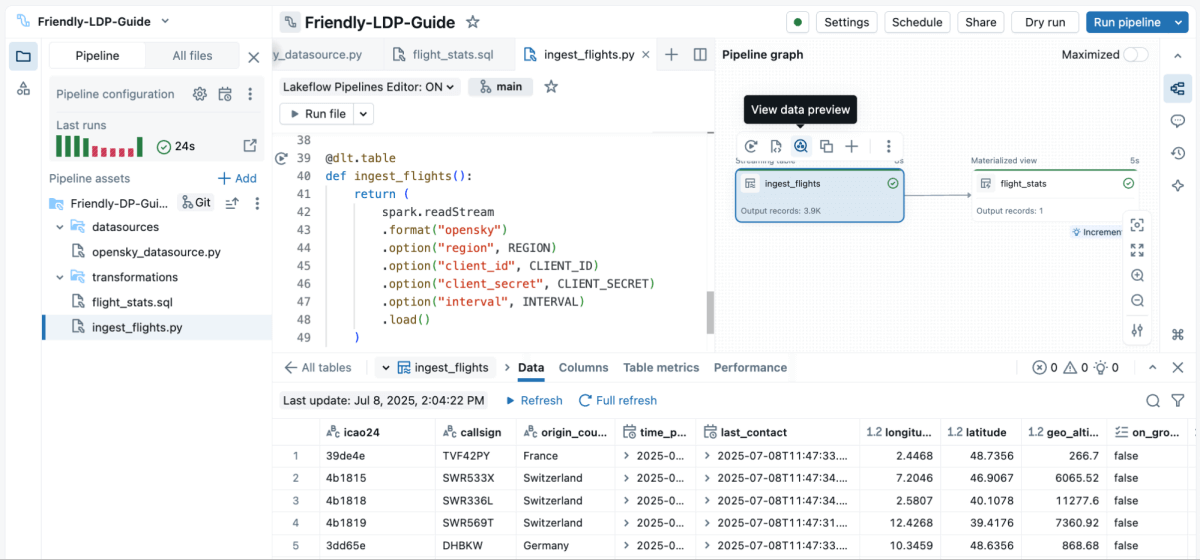
Nos bastidores, o Lakeflow gerencia a infraestrutura de streaming: checkpointing automático garante recuperação de falhas, processamento incremental elimina cálculos redundantes, e garantias de apenas uma vez evitam duplicação de dados. Engenheiros de dados escrevem a lógica de negócios; a plataforma garante excelência operacional.
Configuração Opcional
O exemplo acima funciona de forma independente e está totalmente funcional fora da caixa. No entanto, implantações de produção normalmente requerem configuração adicional. Em cenários do mundo real, os usuários podem precisar especificar a região geográfica para a coleta de dados do OpenSky, habilitar a autenticação para aumentar os limites de taxa da API e impor restrições de qualidade de dados para evitar que dados ruins entrem no sistema.
Regiões Geográficas
Você pode rastrear voos sobre regiões específicas especificando caixas delimitadoras predefinidas para continentes e áreas geográficas maiores. A fonte de dados inclui filtros regionais como ÁFRICA, EUROPA e AMÉRICA DO NORTE, entre outros, além de uma opção global para cobertura mundial. Essas regiões integradas ajudam você a controlar o volume de dados retornados enquanto foca sua análise em áreas geograficamente relevantes para o seu caso de uso específico.
Limitação de Taxa e Autenticação da Rede OpenSky
Autenticação com a Rede OpenSky oferece benefícios significativos para implantações em produção. A API do OpenSky aumenta os limites de taxa de 100 chamadas por dia (anônimas) para 4.000 chamadas por dia (autenticadas), essencial para aplicações de rastreamento de voos em tempo real.
Para autenticar, registre-se para credenciais de API em https://opensky-network.org e forneça seu client_id e client_secret como opções ao configurar a fonte de dados. Essas credenciais devem ser armazenadas como segredos do Databricks em vez de codificadas em seu código por segurança.
Note que você pode aumentar este limite para 8.000 chamadas diárias se alimentar seus dados para a Rede OpenSky. Este projeto divertido envolve colocar uma antena ADS-B na sua varanda para contribuir para esta iniciativa colaborativa.
Qualidade de Dados com Expectativas
A qualidade dos dados é crítica para análises confiáveis. As expectativas de Pipeline Declarativa definem regras para validar automaticamente os dados de streaming, garantindo que apenas registros limpos cheguem às suas tabelas.
Essas expectativas podem detectar valores ausentes, formatos inválidos ou violações de regras de negócios. Você pode descartar registros ruins, colocá-los em quarentena para revisão, ou interromper o pipeline quando a validação falhar. O código na próxima seção demonstra como configurar a seleção de região, autenticação e validação de qualidade de dados para uso em produção.
Exemplo Revisado de Tabela de Streaming
A implementação abaixo mostra um exemplo da tabela de streaming com parâmetros de região e autenticação, demonstrando como a fonte de dados lida com filtragem geográfica e credenciais de API. A validação da qualidade dos dados verifica se o ID da aeronave (gerenciado pela Organização Internacional de Aviação Civil - ICAO) e as coordenadas do avião estão definidas.
Views Materializadas: Resultados pré-calculados para análises
Análises em tempo real em dados de streaming tradicionalmente requerem arquiteturas complexas que combinam motores de processamento de stream, camadas de cache e bancos de dados analíticos. Cada componente introduz sobrecarga operacional, desafios de consistência e modos de falha adicionais.
As visualizações materializadas nas Pipelines Declarativas Lakeflow reduzem essa sobrecarga arquitetônica abstraindo o tempo de execução subjacente com computação sem servidor. Uma simples declaração SQL cria uma visão materializada contendo resultados pré-calculados que se atualizam automaticamente à medida que novos dados chegam. Esses resultados são otimizados para consumo downstream por painéis, aplicativos Databricks ou tarefas analíticas adicionais em um fluxo de trabalho implementado com Lakeflow Jobs.
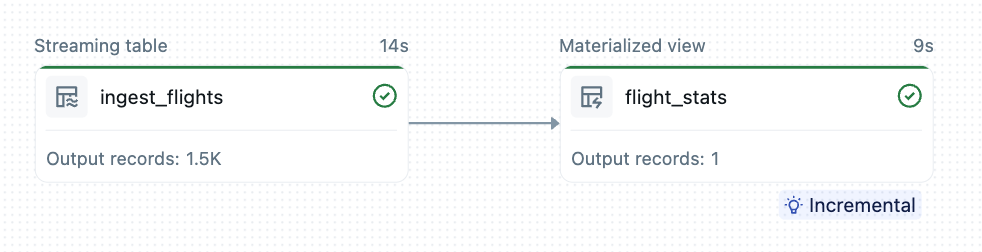
Esta visão materializada agrega atualizações de status de aeronaves da tabela de streaming, gerando estatísticas globais sobre padrões de voo, velocidades e altitudes. À medida que novos eventos de IoT chegam, a visualização é atualizada incrementalmente na plataforma Lakeflow sem servidor. Ao processar apenas algumas milhares de alterações - em vez de recomputar quase um bilhão de eventos todos os dias - o tempo de processamento e os custos são drasticamente reduzidos.
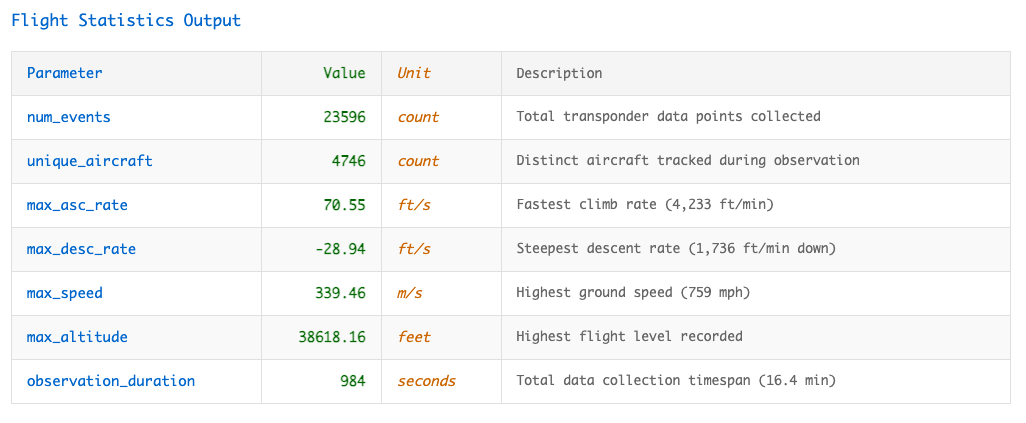
A abordagem declarativa em Lakeflow Declarative Pipelines remove a complexidade tradicional em torno da captura de dados de mudança, cálculo incremental e cache de resultados. Isso permite que os engenheiros de dados se concentrem apenas na lógica analítica ao criar visualizações para painéis, aplicativos Databricks ou qualquer outro caso de uso downstream.
Gênio AI/BI: Linguagem Natural para Insights em Tempo Real
Mais dados geralmente criam novos desafios organizacionais. Apesar da disponibilidade de dados em tempo real, geralmente apenas equipes técnicas de engenharia de dados modificam pipelines, então as equipes de negócios analíticos dependem de recursos de engenharia para análises ad hoc.
AI/BI Genie permite consultas em linguagem natural contra dados em streaming para todos. Usuários não técnicos podem fazer perguntas em inglês simples, e as consultas são automaticamente traduzidas para SQL contra fontes de dados em tempo real. A transparência de poder verificar o SQL gerado fornece salvaguardas cruciais contra alucinações de IA, ao mesmo tempo que mantém o desempenho e os padrões de governança de consultas.
Nos bastidores, o Genie usa raciocínio agente para entender suas perguntas enquanto segue as regras de acesso do Catálogo Unity. Ele pede esclarecimentos quando está incerto e aprende seus termos de negócios através de consultas e instruções de exemplo.
Por exemplo, "Quantos voos únicos estão sendo rastreados atualmente?" é traduzido internamente para SELECT COUNT(DISTINCT icao24) FROM ingest_flights. A mágica é que você não precisa conhecer nenhum nome de coluna em sua solicitação de linguagem natural.
Outro comando, "Trace a altitude vs. velocidade para todas as aeronaves," gera uma visualização mostrando a correlação de velocidade e altitude. E "plotar as localizações de todos os aviões em um mapa" ilustra a distribuição espacial dos eventos aviónicos, com a altitude representada através de codificação de cores.
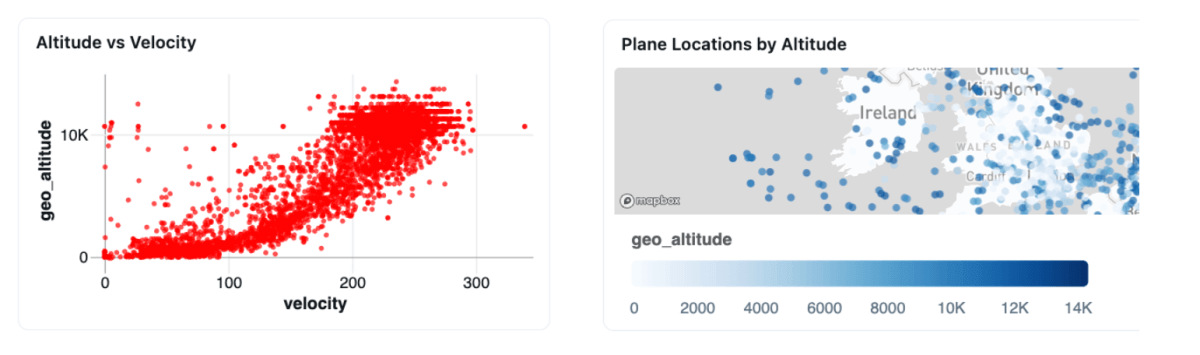
Esta capacidade é convincente para análises em tempo real, onde perguntas de negócios muitas vezes surgem rapidamente à medida que as condições mudam. Em vez de esperar por recursos de engenharia para escrever consultas personalizadas com agregações de janela temporal complexas, os especialistas do domínio exploram os dados de streaming diretamente, descobrindo insights que impulsionam decisões operacionais imediatas.
Visualizar Dados em Tempo Real
Uma vez que seus dados estejam disponíveis como tabelas Delta ou Iceberg, você pode usar praticamente qualquer ferramenta de visualização ou biblioteca gráfica. Por exemplo, a visualização mostrada aqui foi criada usando Dash, rodando como uma Aplicação Lakehouse com efeito de lapso de tempo.
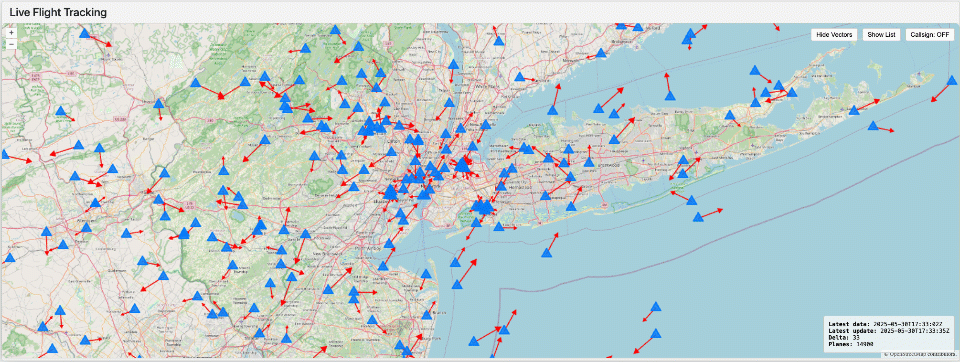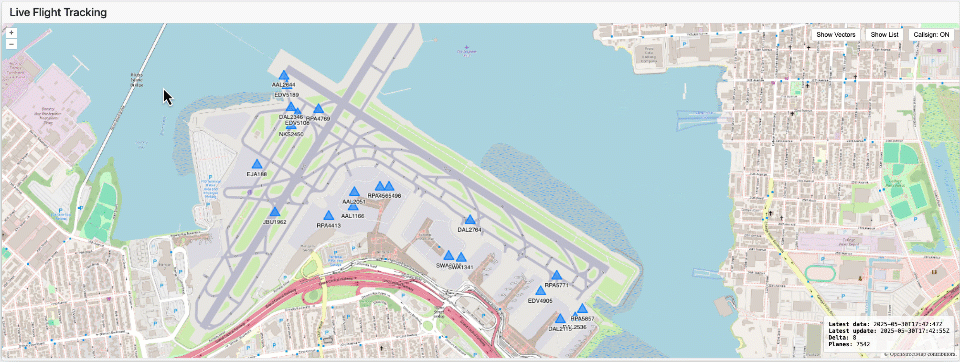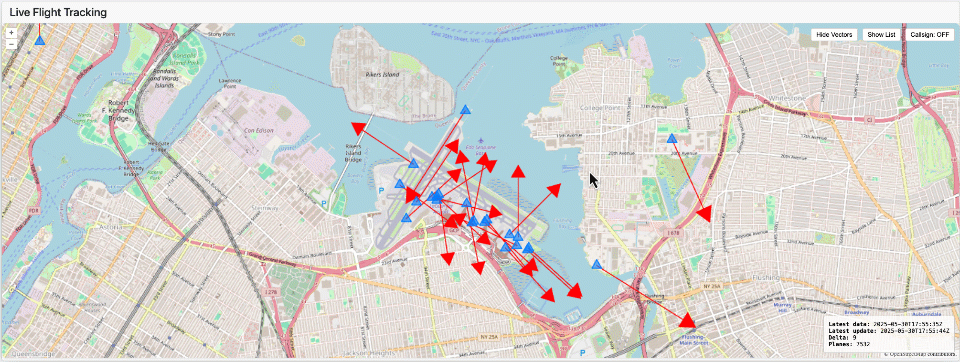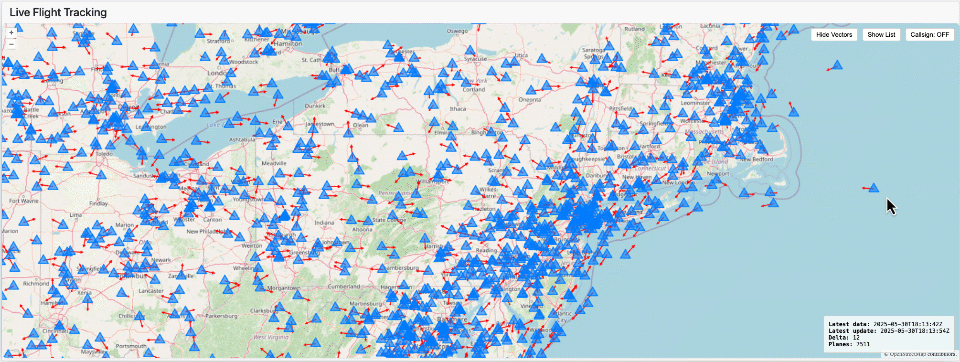
Esta abordagem demonstra como as plataformas de dados modernas não apenas simplificam a engenharia de dados, mas também capacitam as equipes a fornecer insights impactantes visualmente em tempo real.
7 Lições Aprendidas sobre o Futuro da Engenharia de Dados
Implementar este pipeline de aviação em tempo real me ensinou lições fundamentais sobre a arquitetura moderna de dados de streaming.
Esses sete insights se aplicam universalmente: a análise de streaming se torna uma vantagem competitiva quando acessível por meio de linguagem natural, quando os engenheiros de dados se concentram na lógica de negócios em vez de infraestrutura, e quando insights alimentados por IA impulsionam decisões operacionais imediatas.
1. Fontes de Dados PySpark Personalizadas Preenchem a Lacuna
Fontes de dados personalizadas PySpark preenchem a lacuna entre os conectores gerenciados do Lakeflow e a conectividade técnica do Spark. Eles encapsulam a complexidade da API em componentes reutilizáveis que parecem nativos para os desenvolvedores Spark. Embora a implementação desses conectores não seja trivial, o Databricks Assistant e outros ajudantes de IA fornecem orientação valiosa suficiente no processo de desenvolvimento.
Não muitas pessoas têm escrito sobre isso ou mesmo usando, mas as Fontes de Dados Personalizadas PySpark abrem muitas possibilidades, desde melhor benchmarking até testes aprimorados até tutoriais mais abrangentes e palestras de conferências emocionantes.
2. Declarativo Acelera o Desenvolvimento
Usando as novas Pipelines Declarativas com uma fonte de dados PySpark, consegui uma simplicidade notável - o que parece um trecho de código é a implementação completa. Escrever menos linhas de código não é apenas sobre produtividade do desenvolvedor, mas confiabilidade operacional. Pipelines declarativos eliminam classes inteiras de bugs em torno do gerenciamento de estado, checkpointing e recuperação de erros que assolam o código de streaming imperativo.
3. A Arquitetura Lakehouse Simplifica
O Lakehouse reuniu tudo—data lakes, armazéns e todas as ferramentas—em um só lugar.
Durante o desenvolvimento, eu pude alternar rapidamente entre a construção de pipelines de ingestão, executando análises em DBSQL e visualizando resultados com o Gênio AI/BI ou Aplicativos Databricks usando as mesmas tabelas. Meu fluxo de trabalho se tornou contínuo com o Assistente Databricks, que está sempre em todos os lugares, e a capacidade de implantar visualizações em tempo real diretamente na plataforma.
O que começou como uma plataforma de dados se tornou meu ambiente de desenvolvimento completo, sem mais trocas de contexto ou malabarismos com ferramentas.
4. Flexibilidade de Visualização é a Chave
Os dados do Lakehouse estão acessíveis a uma ampla gama de ferramentas e abordagens de visualização—desde notebooks clássicos para exploração rápida, até o Gênio AI/BI para painéis instantâneos, até aplicativos web personalizados para experiências ricas e interativas. Para um exemplo do mundo real, veja como usei o Dash como uma Aplicação Lakehouse anteriormente neste post.
5. Dados de Streaming Tornam-se Conversacionais
Por anos, o acesso a insights em tempo real exigiu profundo conhecimento técnico, linguagens de consulta complexas e ferramentas especializadas que criaram barreiras entre os dados e os tomadores de decisão.
Agora você pode fazer perguntas com o Genie diretamente contra fluxos de dados ao vivo. O Genie transforma a análise de dados de streaming de um desafio técnico em uma conversa simples.
6. Suporte de Ferramentas de IA é um Multiplicador
Ter assistência de IA integrada em todo o lakehouse mudou fundamentalmente a rapidez com que eu poderia trabalhar. O que mais me impressionou foi como o Genie aprendeu com o contexto da plataforma.
As ferramentas suportadas por IA amplificam suas habilidades. Seu verdadeiro poder é desbloqueado quando você tem uma forte base técnica para construir.
7. Abstrações de Infraestrutura e Governança Criam Foco nos Negócios
Quando a plataforma lida com a complexidade operacional automaticamente—desde a escalabilidade até a recuperação de erros—as equipes podem se concentrar em extrair valor dos negócios em vez de lutar contra restrições tecnológicas. Essa mudança do gerenciamento de infraestrutura para a lógica de negócios representa o futuro da engenharia de dados de streaming.
Resumindo, o futuro da engenharia de dados de streaming é suportado por IA, declarativo e focado em resultados de negócios. As organizações que adotam essa mudança arquitetônica se encontrarão fazendo melhores perguntas sobre seus dados e construindo mais soluções mais rapidamente.
Você quer aprender mais?
- Repositório GitHub com um Guia de Início Rápido para este exemplo
- Rede OpenSky
- Matthias Schäfer, Martin Strohmeier, Vincent Lenders, Ivan Martinovic e Matthias Wilhelm. "Trazendo o OpenSky: Uma Rede de Sensores ADS-B em Grande Escala para Pesquisa". Em Anais do 13º Simpósio Internacional IEEE/ACM sobre Processamento de Informações em Redes de Sensores (IPSN), páginas 83-94, abril de 2014.
- Simplifique a Ingestão de Dados Com a Nova API de Fonte de Dados Python
- Honeywell seleciona Pipelines Declarativos Lakeflow para dados de streaming
- Volvo permite visibilidade em tempo real do inventário de peças de reposição com Lakeflow Declarative Pipelines da Databricks
Coloque as Mãos na Massa!
O pipeline completo de rastreamento de voos pode ser executado na Edição Gratuita do Databricks, tornando o Lakeflow acessível a qualquer um com apenas alguns passos simples descritos em nosso repositório GitHub.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.