Tags de Consulta: O Contexto Que Suas Consultas de Armazém Tinham Faltando
Atribua custos, rastreie consultas de ferramentas parceiras e rotule cargas de trabalho — com metadados personalizados em cada execução de SQL.
- Atribua custos de warehouse compartilhado por equipe, projeto, dashboard ou qualquer dimensão personalizada
- Monitore ou solucione problemas de consultas de ferramentas parceiras com marcação automática para dbt (nome do modelo), PowerBI (ID do relatório), Tableau (nome da pasta de trabalho) e mais
- Marque consultas de qualquer lugar: Editor SQL, Notebooks, Dashboards, APIs, conectores e drivers
Databricks SQL registra automaticamente atributos importantes de cada consulta: quem a executou, em qual warehouse e de qual ferramenta. Mas isso geralmente não é suficiente.
Quando uma consulta do Power BI está lenta, você sabe que ela veio do Power BI, mas não qual dashboard corrigir. Quando os custos aumentam, você pode ver quais usuários executaram consultas, mas não qual centro de custo ou projeto cobrar. A peça que falta é o contexto personalizado, e é exatamente isso que o Query Tags adiciona.
Hoje, estamos introduzindo o Query Tags em Visualização Pública. O Query Tags permite que você anexe contexto de negócios como pares de chave-valor a cada execução de SQL e consulte tudo por meio de tabelas do sistema com SQL padrão — ou apenas perguntando ao Genie. O Query Tags também é visível na interface do usuário do Perfil da Consulta (a pesquisa de suporte na interface do usuário do Histórico de Consultas está chegando em breve).
O Query Tags já teve forte adoção, com centenas de clientes marcando milhões de consultas semanalmente.
Apenas marque: apresentando o Query Tags
Com o Query Tags, você anexa pares de chave-valor personalizados (por exemplo, “projeto” : “finance_planning”) a cada execução de SQL. Essas tags acompanham a consulta e são registradas na Tabela do Sistema de Histórico de Consultas, tornando-as disponíveis para agrupar, filtrar e analisar cargas de trabalho.
As tags agregam valor em três cenários:
- Ferramentas parceiras: Ao usar dbt, Power BI ou Tableau, propague identificadores como nome do modelo dbt, ID do relatório do Power BI ou nome do livro do Tableau em cada consulta.
- Aplicações personalizadas: Ao criar aplicativos por meio da API de Execução de Instruções SQL ou conectores, anexe metadados como `customerid`, `applicationname` ou `app_version` a cada execução.
- Trabalho ad-hoc na interface do Databricks: Marque consultas com dimensões relevantes para você — ambiente de desenvolvimento vs. produção, centro de custo, nome do experimento ou equipe.
Vamos nos aprofundar nesses cenários.
(1) Rastreie cada consulta de ferramenta parceira até sua origem
Consultas de dbt, Power BI e Tableau fluem para o seu warehouse — mas sem tags, elas são impossíveis de rastrear além de um ID de usuário e da ferramenta de origem. Essas ferramentas resolvem isso injetando Query Tags automaticamente, sem necessidade de marcação manual.
dbt marca automaticamente cada consulta com o nome do modelo, versão principal, versão do adaptador e tipo de materialização. Se um modelo dbt de repente regredir em desempenho, você poderá identificar exatamente qual modelo, qual versão e quando:
Os líderes de engenharia de pessoal Dipesh Bhundia e Dave Couse na ASOS adicionaram:
"Sem ter que configurar nada, podemos mapear cada carga de trabalho SQL para o modelo dbt de onde ela se origina. Com o Query Tags, finalmente podemos dividir com precisão os custos do warehouse pelas equipes que estão executando dbt nele."
Power BI e Tableau suportam Query Tags personalizados no nível da conexão. Defina-os uma vez e cada consulta dessa conexão os carregará automaticamente. Para o Tableau, os clientes acharam útil usar parâmetros como [WorkbookName] como valor da tag, para que a atribuição seja preservada mesmo quando o livro de trabalho é renomeado.
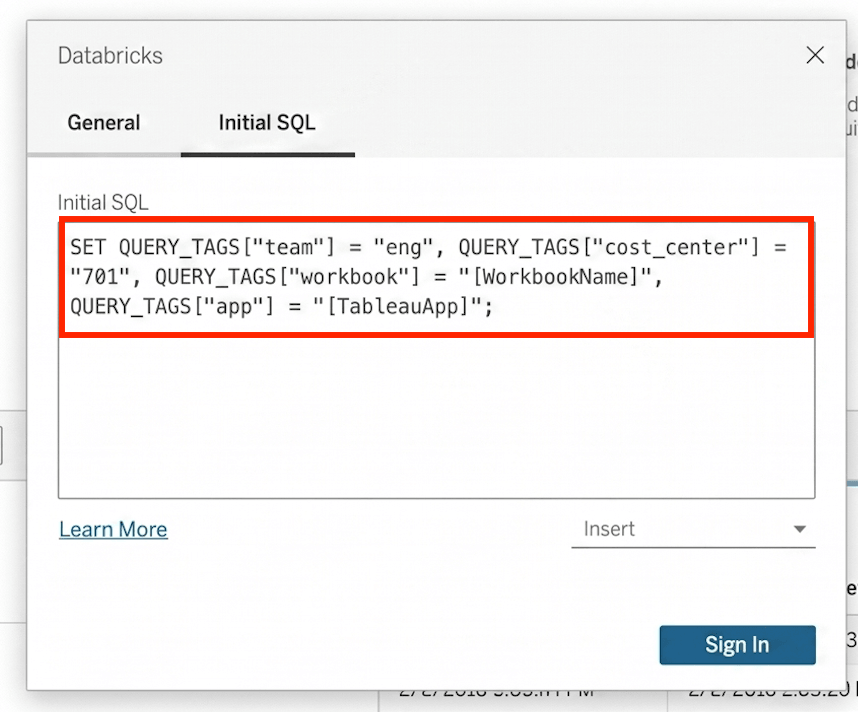
Para uma lista completa de ferramentas parceiras que suportam Query Tags, consulte a documentação. Se sua ferramenta não estiver listada, entre em contato com sua equipe de contas.
(2) Transforme consultas de API anônimas em cargas de trabalho rastreáveis
Aplicações personalizadas acessam seu warehouse por meio de APIs e conectores, mas as consultas que elas geram não carregam nenhum contexto de aplicação — sem nome de aplicativo, sem nome de equipe, sem ID de cliente. O Query Tags permite que você anexe esses metadados no nível da conexão ou da instrução.
A API de Execução de Instruções SQL suporta marcação no nível da instrução. Tags passadas como parâmetro se aplicam a essa execução específica:
O Conector Python suporta marcação em nível de conexão e em nível de instrução. Defina um nome de equipe na conexão; substitua-o por instrução, quando necessário:
Matthew Haber, Engenheiro de DevOps, Unit21 compartilhou:
"Migramos de um warehouse por equipe para warehouses compartilhados para reduzir custos, mas perdemos a visibilidade de qual equipe estava impulsionando os gastos. Com o Query Tags, apenas passamos o nome da equipe do nosso Conector Databricks SQL para cargas de trabalho Python e recuperamos essa atribuição —sem necessidade de dividir os warehouses novamente."
Para a lista completa de suporte a conectores e drivers (Node.js, Go, JDBC, etc.), consulte a documentação.
(3) Rotule seu próprio trabalho para que ele não se perca no ruído
Analistas executam centenas de consultas por semana (exploração, produção, depuração, etc.) e, sem rótulos, todas elas parecem iguais nas tabelas do sistema. O Query Tags permite que os profissionais marquem à medida que avançam com uma linha de SQL, em qualquer lugar onde enviem consultas: Editor SQL, Notebooks, Dashboards e Alertas.
Uma vez definidas, todas as instruções subsequentes na sessão carregam essas tags automaticamente. Não há necessidade de anotar cada consulta individualmente. Por exemplo, adicionar a instrução SET QUERY_TAGS a cada consulta de conjunto de dados em um dashboard de IA/BI marca cada consulta desse dashboard com ‘ambiente: produção’.
Profissionais de dados podem usar isso para:
- Marcar análises ad-hoc por projeto ou equipe
- Identificar experimentos ou testes A/B
- Identificar cargas de trabalho de desenvolvimento vs. produção
- Anexar contexto de depuração ao investigar problemas
De tags a respostas: monitoramento com Tabelas do Sistema
Depois que as consultas são marcadas, as tags são registradas na coluna query_tags da Tabela do Sistema de Histórico de Consultas. Agora, as perguntas difíceis se tornam SQL simples.
Qual equipe está impulsionando os custos do warehouse?
Muitas organizações precisam alocar custos compartilhados de warehouse por equipe ou produto. Com as Query Tags, isso é feito com uma única consulta — sem divisão de warehouse ou adivinhações.
Qual modelo dbt introduziu uma regressão?
Quando um pipeline fica lento, você precisa saber qual modelo, não apenas qual warehouse. Filtre o histórico de consultas do sistema (`system.query.history`) pela tag de nome do modelo dbt injetada automaticamente para isolar o problema.
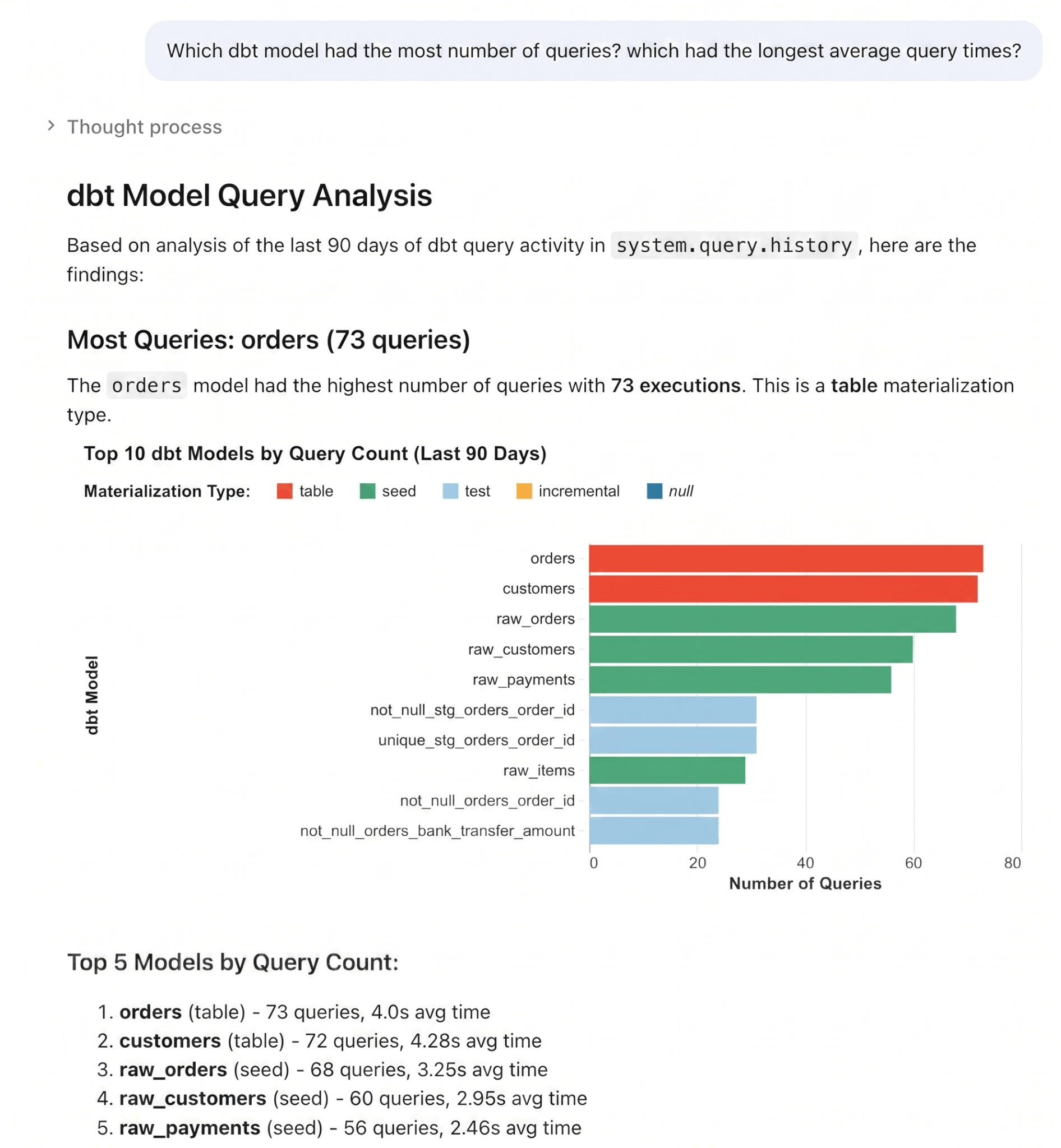
Ou, pule a escrita de SQL inteiramente, perguntando ao Genie. Como as Query Tags armazenam contexto de negócios nas Tabelas do Sistema (`System Tables`), o Genie pode raciocinar sobre os dados de sua carga de trabalho em linguagem natural. Por exemplo: "Qual modelo dbt teve o maior número de consultas? Qual teve os tempos médios de consulta mais longos?”
As Query Tags desbloqueiam muitos outros casos de uso de monitoramento:
- Agrupe por `query_tags['cost_center']` para rateio de custos
- Filtre por `query_tags['@@dbt_model_name']` para monitorar a saúde do pipeline
- Identifique consultas de longa duração por workbook do Tableau
- Compare `query_tags['env']` para separar tráfego de desenvolvimento do de produção
Próximos passos
As Query Tags estão em Preview Público hoje para SQL Warehouses, e já estamos trabalhando para torná-las ainda mais úteis para as experiências de monitoramento de nossos clientes. Por favor, consulte a documentação para atualizações.
- Marcação automática do Power BI: O Power BI anexará automaticamente metadados como DatasetId e ReportId a cada consulta sem nenhuma configuração. Você pode habilitar isso manualmente hoje seguindo as etapas na documentação. A marcação automática estará ativada por padrão na próxima versão do Power BI.
- Suporte mais amplo a conectores: Além de Python, a marcação em nível de instrução agora está disponível para Go e Node.js.
- Pesquisabilidade na interface do usuário: Em breve, suportaremos a pesquisa na interface do Histórico de Consultas (`Query History`), para que você possa pesquisar consultas com uma tag específica (por exemplo, "@@dbt_model_name": "my_model")
- Suporte além dos SQL Warehouses: Estamos trazendo as Query Tags para Notebooks e Jobs Serverless, para que o mesmo modelo de marcação e atribuição se estenda às cargas de trabalho de notebooks.ads.
Experimente as Query Tags hoje
Cada consulta sem marcação é uma oportunidade perdida de atribuição. Se você precisa dividir os custos do warehouse por equipe, rastrear uma consulta lenta até um dashboard específico ou rotular o trabalho do analista por projeto — as Query Tags fornecem o contexto para fazer isso.
Se você usa dbt, já está marcando (verifique a Tabela do Sistema do seu Histórico de Consultas). Para Power BI, Tableau e aplicativos personalizados, a configuração leva minutos. Para trabalho ad-hoc, leva uma linha de SQL.
As Query Tags estão disponíveis hoje em Preview Público em todas as nuvens. Comece com a documentação.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.