Um Open Lakehouse em Tempo Real com Redpanda e Databricks
Os investimentos da Redpanda em integração de princípios fundamentais com Iceberg e Unity Catalog criam uma arquitetura sustentável para entregar agilidade de stream-to-table e potencializar um open lakehouse em tempo real
por Matt Schumpert e Jason Reid
- Transforme seus fluxos Kafka em tabelas Iceberg totalmente gerenciadas pelo Unity Catalog em uma única etapa, entregando análises de lakehouse em tempo real sem conectores pesados ou jobs de ETL customizados.
- Execute ingestão de Apache Iceberg™ com streaming sub-10 ms e alto throughput no mesmo cluster Redpanda com Iceberg Topics que lidam com batching parquet, commits exactly-once e otimizações preditivas do Unity, reduzindo custos e esforço operacional.
- Implante em qualquer lugar (SaaS, BYOC ou autogerenciado) e construa sobre padrões abertos com APIs Kafka, Iceberg V2 e REST Catalog; configurações declarativas simples oferecem particionamento customizado, evolução de schema e DLQs integradas de fábrica.
Todo lakehouse deve ser alimentado por streaming
O conceito de ‘open lakehouse’ pioneiro pela Databricks anos atrás foi mais amplamente realizado através do recente surgimento do Apache Iceberg™, impulsionado por investimentos de grandes fornecedores em integração de frameworks, ferramentas, suporte a catálogo e interoperabilidade de dados, comprometendo-se com o Iceberg como um substrato comum para um open lakehouse. Avanços como a capacidade de expor tabelas Delta Lake ao crescente ecossistema Iceberg através do UniForm, o suporte do Unity Catalog para recursos avançados como otimização preditiva e Iceberg REST com tabelas Iceberg Gerenciadas, e a recente unificação da camada de dados Delta/Iceberg no Iceberg V3 significam que as organizações agora podem adotar uma estratégia de dados ‘Iceberg-first’ com confiança, e sem comprometer o uso dos ricos conjuntos de recursos de produtos maduros de lakehouse como Databricks.
Um dos principais jogadores ausentes nesta história de acesso ubíquo a dados residentes na nuvem através da língua franca do Iceberg foram os streams, nomeadamente os tópicos Kafka. Hoje, qualquer dado estruturado em repouso pode ser facilmente carregado nativamente ou ‘decorado’ como Iceberg. Em contraste, dados de alto valor em movimento fluindo através de uma plataforma de streaming que alimenta aplicativos em tempo real ainda precisam ser ‘ETLed’ para o lakehouse de destino através de um job de integração de dados ponto a ponto, por stream, ou executando uma infraestrutura de connector custosa em seu próprio cluster. Ambas as abordagens utilizam um Kafka Consumer pesado, pressionando seus pipelines de entrega de dados em tempo real, e criam um componente de infraestrutura intermediário para escalar, gerenciar e observar com habilidades especializadas em Kafka. Ambas as abordagens equivalem a inserir uma taxa muito cara tanto entre seus ambientes de dados em tempo real e de análise, uma que realmente não precisa existir.
À medida que o uso de armazenamentos de objetos na nuvem para backup de streams amadureceu (Redpanda liderou essa carga vários anos atrás) e à medida que formatos de tabela abertos assumiram o centro do palco em lakehouses, essa união de stream-para-tabela é conveniente e “feita para ser”. Databricks e Redpanda entregam duas plataformas de dados de classe mundial que fazem essa abordagem brilhar intensamente e chamar a atenção. Juntas, elas criam um substrato de dados abrangendo tomada de decisão em tempo real, análise e IA que é difícil de superar. Na prática, essa abordagem mescla streams com tabelas com a facilidade de uma flag de configuração. Ela age como uma barragem com múltiplas câmaras, roteando streams selecionáveis para um data lake unificado sob demanda, entregando insights atualizados e desbloqueando a mesma inclusão arbitrária de dados em novos pipelines de análise que a arquitetura lakehouse nos deu para tabelas, e agora através da abertura ampliada que o ecossistema Iceberg fornece.
Fundir perfeitamente a infraestrutura de dados em tempo real e de análise para tornar um ‘lakehouse alimentado por streaming’ uma tarefa com um clique não só desbloqueia um valor massivo, mas também resolve um problema de engenharia difícil que exige uma abordagem ponderada para abordar adequadamente no caso geral. Como esperamos ilustrar abaixo, não cortamos atalhos para apressar essa capacidade no mercado. Trabalhando com dezenas de parceiros de design (e Databricks) por mais de um ano, estendemos a base de código única da Redpanda de uma forma que preserva as opções de implantação preferidas de nossos clientes (incluindo BYOC em várias nuvens), mantém a compatibilidade total com Kafka (não deixe nenhuma carga de trabalho para trás) e evita a duplicação de artefatos e etapas para os usuários sempre que possível. Esperamos que essa completude de visão transpareça enquanto apresentamos os princípios orientadores para a construção de Redpanda Iceberg Topics, que agora estão disponíveis com Databricks Unity Catalog na AWS e GCP!
Execute sua plataforma de stream-to-lakehouse em qualquer lugar
Nosso primeiro princípio foi manter a escolha e encontrar os usuários onde eles estão. Redpanda já possui ofertas maduras de SaaS, BYOC e auto-gerenciadas multi-cloud, opções de rede soberana privada como BYOVPC, e geralmente nunca força seus clientes a mudar de nuvens, redes, armazenamentos de objetos, IdPs, ou qualquer outra coisa que possa impedir a adoção ou impedir que os proprietários da plataforma posicionem sua implantação de plataforma de streaming (incluindo planos de dados e controle), onde faz mais sentido para eles. Independentemente dessa escolha, os usuários obtêm todos os recursos da plataforma e uma experiência de usuário consistente para desenvolvedores e administradores. Essa estratégia de produto de plataforma única é o que nos permite anunciar que Iceberg Topics para Databricks estão geralmente disponíveis nas nuvens AWS, GCP e Azure hoje, e que as organizações podem implantar com a confiança de saber que, se e quando mudarem de nuvem ou para novos formatos, estarão implantando o mesmo produto com o mesmo motor subjacente, compatibilidade Kafka, modelo de segurança, características de desempenho e ferramentas de gerenciamento. Essa amplitude de flexibilidade e consistência contrasta fortemente com outras opções no mercado.
Unity Catalog, conheça a plataforma de streaming mais unificada
Em segundo lugar, fomos inflexíveis em construir isso como um sistema único, e um que realmente pareça ser. Você simplesmente não pode fundir dois conceitos bem juntos aparafusando duas arquiteturas de software completamente diferentes. Você pode encobrir algumas coisas com uma aparência de SaaS, mas arquiteturas inchadas transparecem nos modelos de precificação, desempenho e TCO, no mínimo, e nos piores casos na experiência do usuário. Fizemos o nosso melhor para evitar isso.
Para desenvolvedores, a sensação de um sistema único significa um ciclo de vida CRUD único e uma experiência do usuário consistente para tópicos como tabelas, e para as coisas que eles precisam para funcionar (ou seja, esquemas). Com os Tópicos Iceberg, você nunca copia entradas ou configurações, nem os cria duas vezes usando uma interface separada. Você gerencia uma entidade como a fonte da verdade para dados e esquemas, sempre usando as mesmas ferramentas. Para nós, isso significa que você faz CRUD através das ferramentas que já usa: qualquer ferramenta do ecossistema Kafka, nossa CLI rpk, as APIs REST da Cloud ou qualquer ferramenta de automação de implantação Redpanda, como nossos CRs do K8s ou o provedor Terraform. Para esquemas, é nosso Schema Registry integrado com sua API amplamente aceita, API, que define o esquema da tabela Iceberg implicitamente ou explicitamente, como preferir. Tudo é orientado por configuração e amigável para DevOps. E com as novas tabelas Iceberg Gerenciadas do Unity Catalog, todos os seus fluxos são descobertos através das ferramentas Databricks como tabelas Iceberg e Delta Lake por padrão.
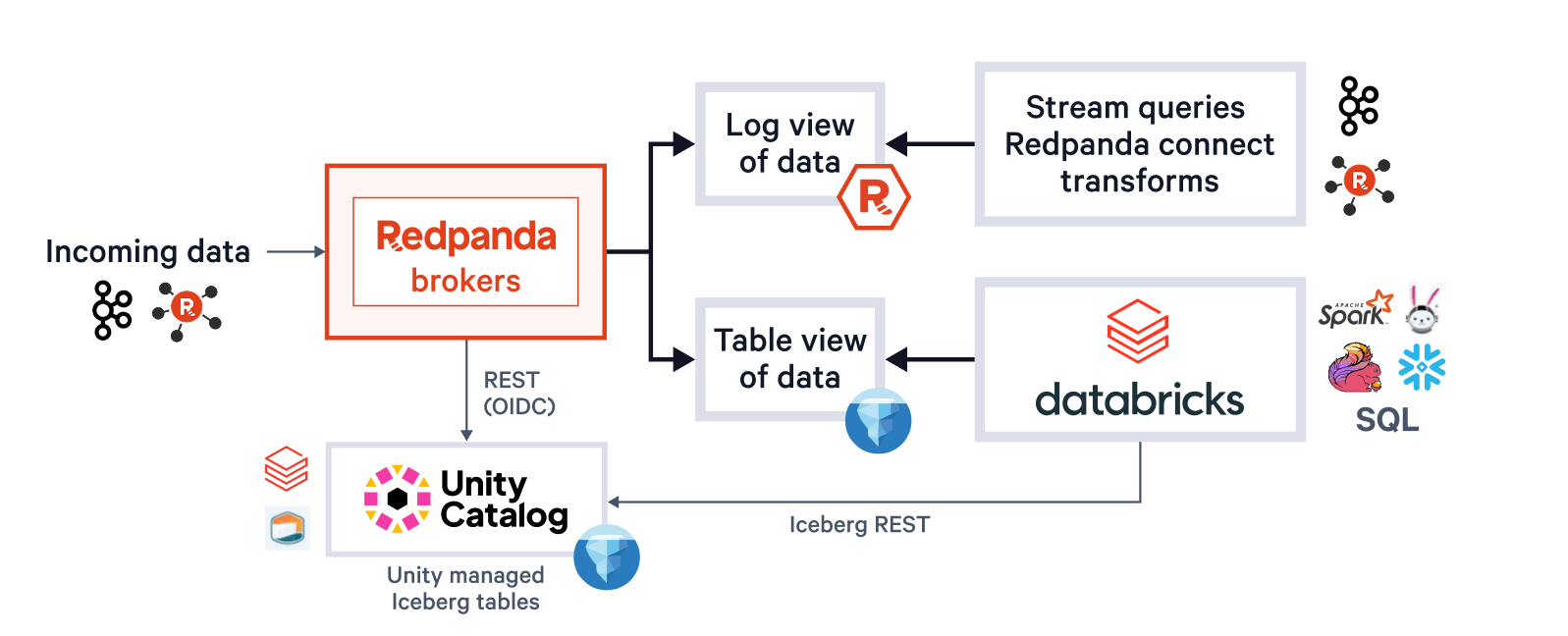
Um sistema único também diz respeito ao operador da plataforma, que não deve se preocupar em gerenciar vários buckets ou catálogos, ajustar tamanhos de arquivos Parquet, tópicos atrasados em relação aos fluxos quando os clusters têm recursos limitados, ou falhas de nós que comprometem a entrega exatamente uma vez. Com os Tópicos Iceberg Redpanda, tudo isso é autônomo. Os operadores se beneficiam de gravações de parquet em lotes dinâmicos e commits transacionais Iceberg que se ajustam aos SLAs de chegada de dados, monitoramento automático de atraso que gera backpressure no Produtor Kafka quando necessário e entrega exatamente uma vez via marcação de snapshot Iceberg (evitando lacunas ou duplicatas após falhas de infraestrutura).
Redpanda gerencia todos os seus dados em um único bucket/contêiner, usa um único catálogo Iceberg no Unity Catalog (que Redpanda monitora para recuperação graciosa) e torna as tabelas facilmente descobertas, expondo o endpoint REST Iceberg do Unity Catalog diretamente na interface do Redpanda Cloud. E agora, com as Tabelas Iceberg Gerenciadas do Unity Catalog, operações de manutenção de tabela como compactação, expiração de dados e Otimização Preditiva são integradas e executadas automaticamente pelo Unity Catalog em segundo plano, enquanto Redpanda assume as operações mínimas de manutenção apropriadas para sua função (atualmente limpeza de snapshot Iceberg e criação/exclusão de tabelas). Administradores Databricks podem então proteger e governar essas tabelas usando todas as permissões normais do Unity Catalog privilégios.
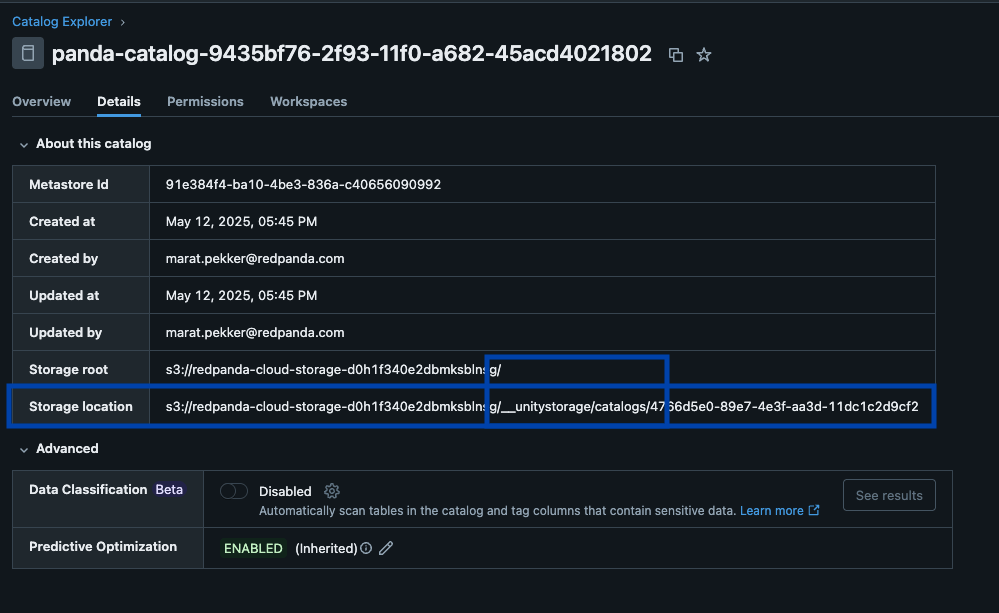
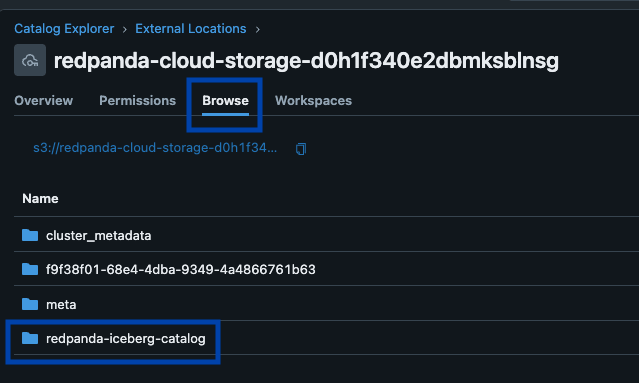
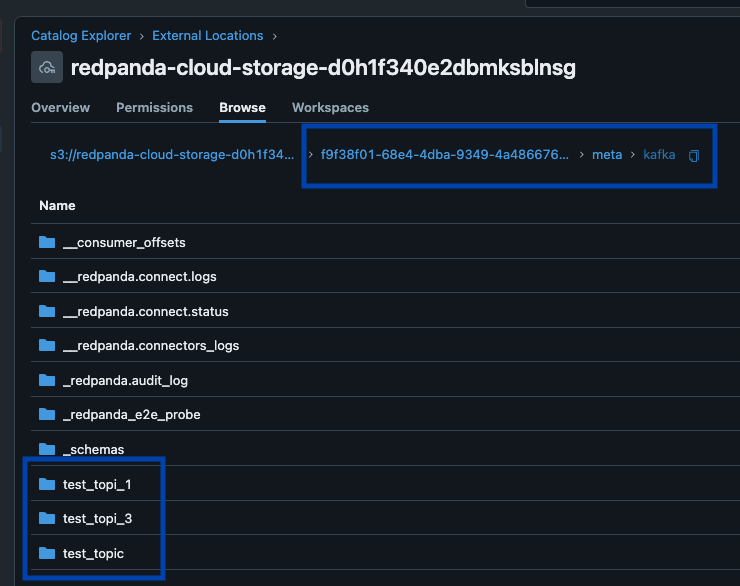
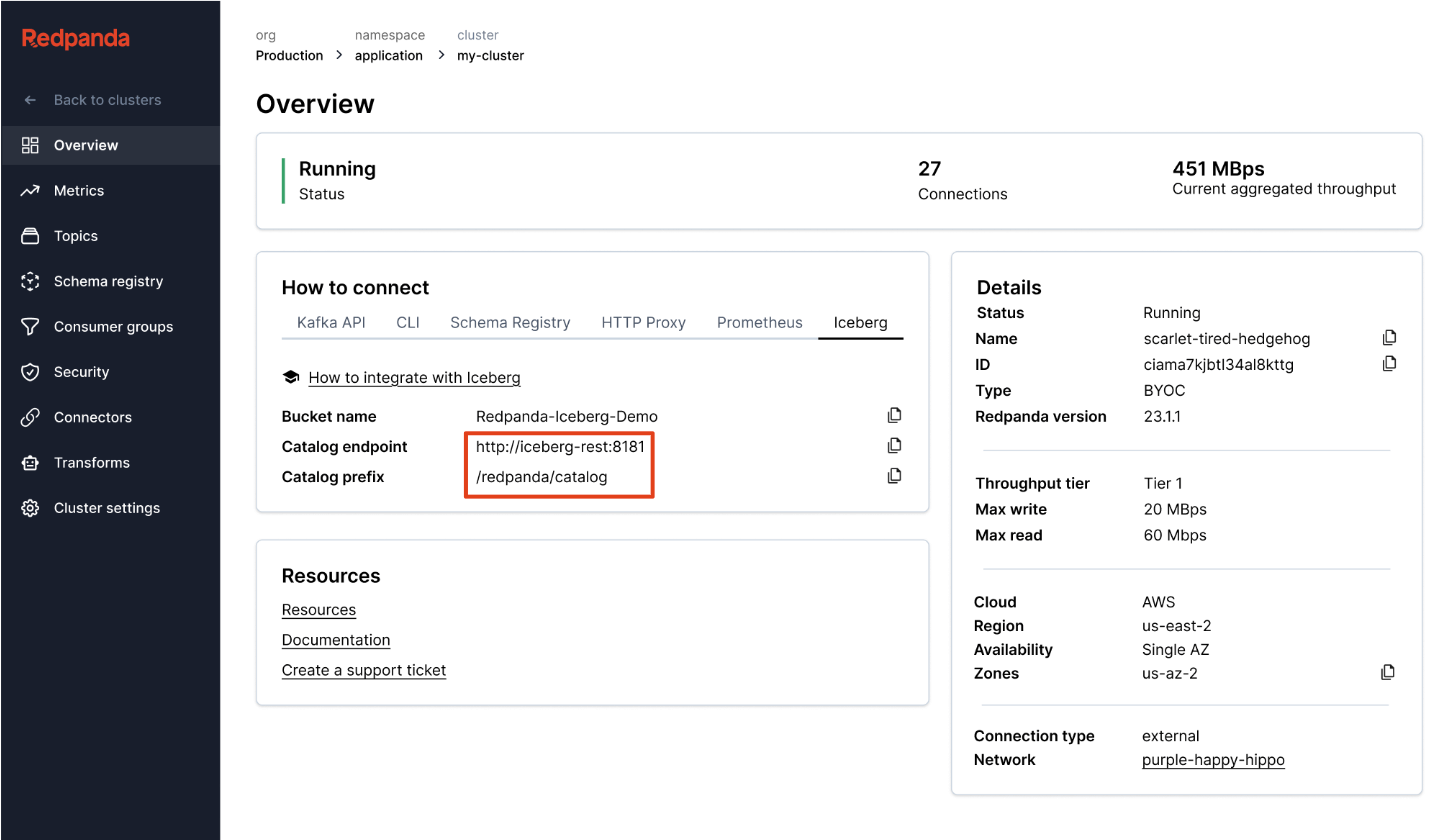
Um cluster para governar todos
Mais importante, graças ao nosso motor de streaming multimodal R1 que usa uma arquitetura thread-por-core e empacota recursos como cache de gravação e balanceamento multinível de dados e cargas de trabalho, os administradores podem executar essa ingestão Iceberg de alta vazão no mesmo cluster, e com os mesmos tópicos que alimentam cargas de trabalho Kafka de baixa latência existentes com SLAs de sub-10ms. Usando operações assíncronas e em pipeline travadas nos mesmos núcleos de CPU que lidam com requisições de Produção/Consumo, lidamos com ambas as cargas de trabalho com eficiência máxima em um único processo. Mais importante, os Tópicos Iceberg podem alavancar todo o conjunto de semânticas Kafka, incluindo transações Kafka e tópicos compactados, onde a camada Iceberg recebe apenas registros de transações confirmadas. Essa combinação de uma arquitetura fundamentalmente eficiente que resolve os problemas difíceis de semânticas sofisticadas rende enormes dividendos na redução de seus custos operacionais porque, bem, um cluster para governar todos. Sem produtos adicionais. Sem clusters separados. Sem pipelines de babá. Implante em qualquer lugar. Mantenha a calma e siga em frente, administradores de plataforma de streaming.
Simplifique
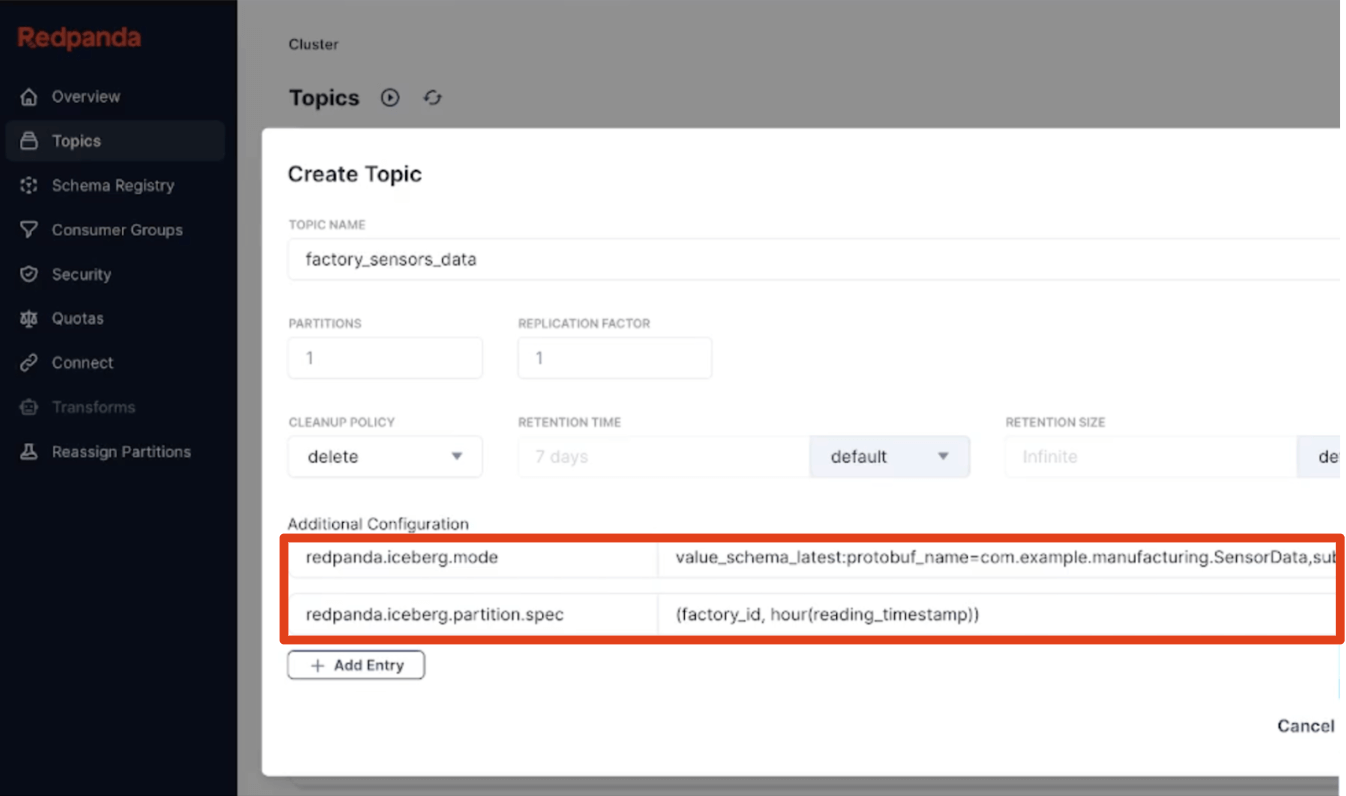
Nosso terceiro princípio foi fazer algumas escolhas opinativas sobre comportamentos padrão, permitindo que os usuários aprendam o sistema gradualmente com a configuração mais inteligente e automática possível que funcione para a maioria dos casos de uso. Isso significa particionamento de tabela integrado por hora (totalmente separado dos esquemas de particionamento de tópicos do Kafka), filas de mensagens mortas sempre ativas para capturar quaisquer dados inválidos, e convenções simples e canônicas como 'versão mais recente' ou 'TopicNameStrategy' para inferência de esquema facilitam a adoção. Também trazemos metadados do Kafka como partições de mensagens, offsets e chaves junto como uma Estrutura Iceberg, para que os desenvolvedores tenham toda a proveniência para validar rapidamente a correção de seus pipelines de streaming em SQL Iceberg.

O simples deve ser simples, é claro, mas o sofisticado também deve ser direto. Portanto, definir particionamento personalizado hierárquico com o conjunto completo de transformações de partição do Iceberg ou extrair um tipo específico de mensagem Protobuf de dentro de um assunto para se tornar o esquema da sua tabela Iceberg são, novamente, apenas propriedades de tópico declarativas de linha única. Esquemas podem evoluir graciosamente à medida que o Redpanda aplica evolução de tabela no local. E se precisar, execute um SMT simples em seu idioma preferido que distribui mensagens complexas de um tópico bruto em tabelas de fatos Iceberg mais simples usando Data Transforms integrados, alimentados por WebAssembly. O objetivo final é pousar os dados prontos para análise em uma única passagem. Pronto, olá camada Bronze.
O pano de fundo para toda essa inovação é, é claro, o projeto Apache Iceberg em rápida evolução e suas especificações, e o compromisso do Redpanda mais geralmente com padrões abertos. Esse compromisso começou com seu suporte inicial ao protocolo Kafka, registro de esquema e APIs de proxy HTTP, e até mesmo outros detalhes como configuração de tópico padrão que permite às organizações migrar perfeitamente um conjunto completo de aplicações Kafka sem alterações. No reino do Iceberg, o Redpanda se destacou como um pioneiro comprometido na comunidade, implementando um cliente Iceberg completo em C++ do zero (algo não disponível em código aberto). Este cliente suporta a especificação completa da tabela Iceberg V2, todas as regras de evolução de esquema e transformações de partição. No lado do catálogo Iceberg, o Redpanda envia um catálogo baseado em arquivos e fala REST Iceberg para operações como criar, confirmar, atualizar e excluir em catálogos remotos como o Unity Catalog, e suporta autenticação OIDC, gerenciando suas credenciais do Unity Catalog criteriosamente como um segredo que é criptografado de forma transparente no gerenciador de segredos do seu provedor de nuvem. O Redpanda também trabalhou em estreita colaboração com a Databricks e outros líderes do Iceberg para explorar como a especificação pode ser estendida para suportar dados de streaming semiestruturados através do tipo Variant, e para tornar o gerenciamento de RBAC de tabelas mais contínuo, sincronizando políticas entre as duas plataformas. Essa padronização e implementação sempre de acordo com a especificação também significa um mínimo de vendor lock-in. As organizações estão sempre livres para trocar qualquer peça do sistema se encontrarem uma opção melhor: a plataforma de streaming, o catálogo Iceberg ou o lakehouse consultando/processando as tabelas.
Se você chegou até aqui, esperamos sinceramente que tenha tido uma ideia do rigor atencioso na abordagem do Redpanda a essa oportunidade de mercado em alta, que decorre de uma forte cultura de engenharia e paixão por construir produtos sólidos. Como tecnólogos por natureza, com históricos sólidos, e com nosso foco no formato BYOC em particular, Redpanda e Databricks estão perfeitamente alinhados para entregar duas plataformas de ponta que agem e parecem uma só, e uma que, para você, resolve bem o problema de streaming para análise de dados.
Experimente Tópicos Iceberg com Unity Catalog usando a oferta exclusiva Bring-Your-Own-Cloud do Redpanda hoje. Ou, comece com um teste gratuito da nossa versão auto-gerenciada, Redpanda Enterprise!: https://cloud.redpanda.com/try-enterprise.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.