A Real-time Open Lakehouse with Redpanda and Databricks
Redpanda’s investments in first principles integration with Iceberg and Unity Catalog create a sustaining architecture for delivering stream-to-table agility and powering a real-time open lakehouse
by Matt Schumpert and Jason Reid
- Turn your Kafka streams into fully governed Unity Catalog-managed Iceberg tables in one step, delivering real-time lakehouse analytics without heavyweight connectors or custom ETL jobs.
- Run sub-10 ms streaming and high-throughput Apache Iceberg™ ingest on the same Redpanda cluster with Iceberg Topics that handle parquet batching, exactly-once commits and Unity’s predictive optimizations, slashing cost and ops effort.
- Deploy anywhere (SaaS, BYOC or self-managed) and build on open standards with Kafka, Iceberg V2 and REST Catalog APIs; simple declarative configs give you custom partitioning, schema evolution and built-in DLQs out of the box.
Every lakehouse should be ‘stream-fed’
The ‘open lakehouse’ concept pioneered by Databricks years ago has been more broadly realized through the recent rise of Apache Iceberg™, driven by major vendors’ investments in framework integration, tooling, catalog support, and in data interoperability, committing to Iceberg as a common substrate for an open lakehouse. Advances like the ability to expose Delta Lake tables to the growing Iceberg ecosystem through UniForm, Unity Catalog’s support for advanced features like predictive optimization and Iceberg REST with Managed Iceberg tables, and the recent unification of the Delta/Iceberg data layer in Iceberg V3 all mean that organizations can now adopt an ‘Iceberg-forward’ data strategy with confidence, and without compromising their use of the rich feature sets of mature lakehouses products like Databricks.
One of the key missing players in this story of ubiquitous access to cloud-resident data through the lingua franca of Iceberg has been streams, namely Kafka topics. Today, any structured data at rest can be easily landed natively or ‘decorated’ as Iceberg. By contrast, high-value data in motion flowing through a streaming platform that powers real-time apps still needs to be ‘ETLed’ into the target lakehouse through a point-to-point, per-stream data integration job, or by running a costly connector infrastructure on its own cluster. Both approaches utilize a heavyweight Kafka Consumer, putting pressure on your real-time data delivery pipelines, and create a middleman infrastructure component to scale, manage and observe with specialized Kafka skills. Both approaches amount to inserting a very pricey toll both between your real-time and analytics data estates, one that really does not need to exist.
As the use of cloud object stores for backing streams has matured (Redpanda led that charge several years ago) and as open table formats have taken center stage in lakehouses, this marriage of stream-to-table is both convenient and “meant to be”. Databricks and Redpanda deliver two world-class data platforms that make this approach shine brightly and turn heads. Together, they create a data substrate spanning real-time decisioning, analytics and AI that’s hard to beat. Practically, this approach merges streams with tables with the ease of a configuration flag. It acts like a multi-chambered dam, routing selectable streams into a unified data lake on demand, delivering up-to-the-minute insights and unlocking the same arbitrary inclusion of data within new analytics pipelines that the lakehouse architecture gave us for tables, and now through the widened aperture that the Iceberg ecosystem provides.
Seamlessly fusing real-time and analytics data infrastructure to make a ‘stream-fed lakehouse’ a push-button affair not only unlocks massive value, but also solves a hard engineering problem that demands a thoughtful approach to properly address in the general case. As we hope to illustrate below, we didn’t cut corners to rush this capability to market. Working with dozens of design partners (and Databricks) for over a year, we extended Redpanda’s single codebase in a way that preserves our customers’ preferred deployment options (including BYOC on multiple clouds), maintains full Kafka compatibility (leave no workloads behind), and avoids duplication of artifacts and steps for users wherever possible. We hope this completeness of vision comes through as we lay out the guiding principles for building Redpanda Iceberg Topics, which are now available with Databricks Unity Catalog on AWS and GCP!
Run your stream-to-lakehouse platform anywhere
Our first principle was to maintain choice and meet users where they are. Redpanda already has mature multi-cloud SaaS, BYOC and self-managed offerings, private sovereign networking options like BYOVPC, and generally never forces its customers to move clouds, networks, object stores, IdPs, or anything else that would gate adoption or prevent platform owners from positioning their streaming platform deployment (including both data and control planes), where it makes the most sense for them. Regardless of that choice, users get all features of the platform and a consistent UX for both devs and admins. This single-platform product strategy is what allows us to announce that Iceberg Topics for Databricks are generally available in AWS, GCP and Azure clouds today, and that organizations can deploy with the confidence of knowing that if and when they do switch clouds or change to new form factors, they’re deploying the same product with the same underlying engine, Kafka compatibility, security model, performance characteristics and management tools. This breadth of flexibility and consistency contrasts sharply with other options in the market.
Unity Catalog, meet the most unified streaming platform
Secondly, we were adamant about building this as a single system, and one that actually feels like it. You simply can’t fuse two concepts together well by bolting together two completely different software architectures. You can paper over some things with a SaaS veneer, but bloated architectures leak through in pricing models, performance and TCO at a minimum, and in the worst cases into the user experience. We’ve done our best to avoid that.
For developers, the ‘feel’ of a single system means a single CRUD lifecycle and a consistent UX for topics-as-tables, and for the things they require to work (namely, schemas). With Iceberg Topics you never copy entries or conf around, nor create them twice using a separate UI. You manage one entity as the source of truth for both data and schema, always using the same tools. For us, that means you CRUD via the tools you already use: any Kafka ecosystem tool, our rpk CLI, Cloud REST APIs or any Redpanda deployment automation tooling like our K8s CRs or Terraform provider. For schemas, it's our built-in Schema Registry with its widely accepted standard API, which defines the Iceberg table schema implicitly, or explicitly, as you prefer. Everything is configuration-driven and DevOps-friendly. And with Unity Catalog’s new Managed Iceberg tables, all your streams are discoverable through Databricks tooling as both Iceberg and Delta Lake tables by default.
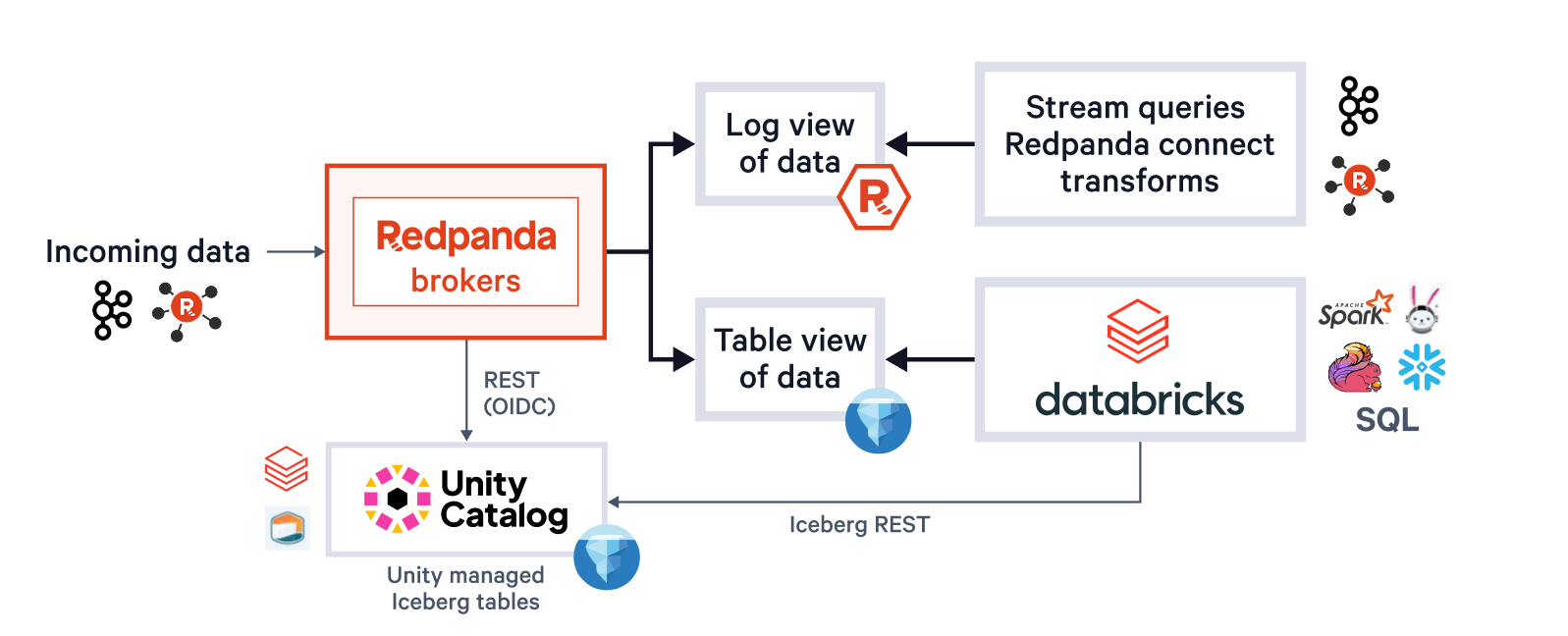
A single system also concerns the platform operator, who shouldn’t need to worry about managing multiple buckets or catalogs, tuning Parquet file sizes, tables lagging streams when clusters are resource-constrained, or node failures compromising exactly-once delivery. With Redpanda Iceberg Topics, all of this is self-driving. Operators benefit from dynamically batched parquet writes and transactional Iceberg commits that adjust to your data arrival SLAs, automatic lag monitoring that generates Kafka Producer backpressure when needed, and exactly-once delivery via Iceberg snapshot tagging (avoiding gaps or dupes after infrastructure failures).
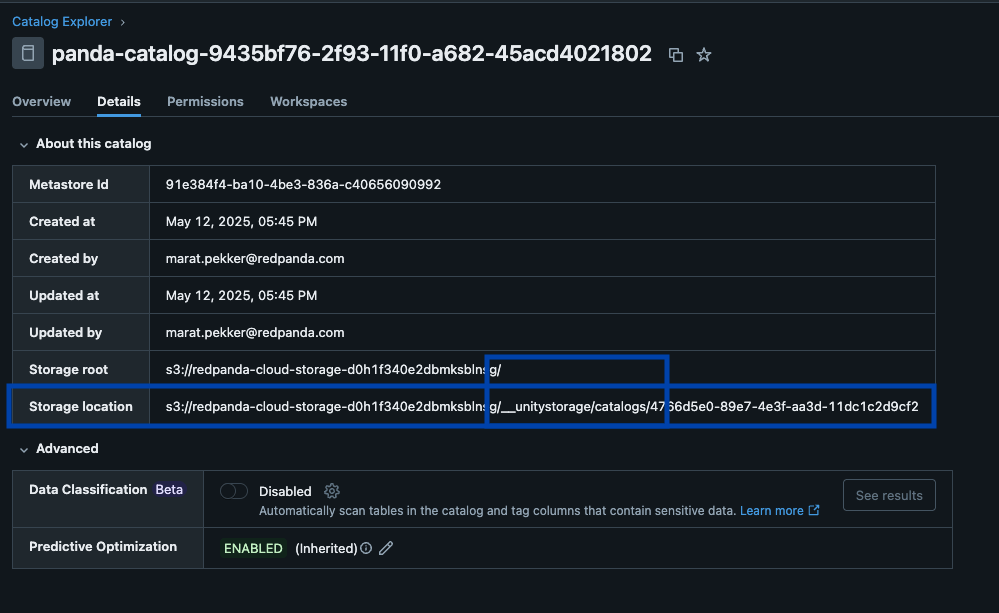
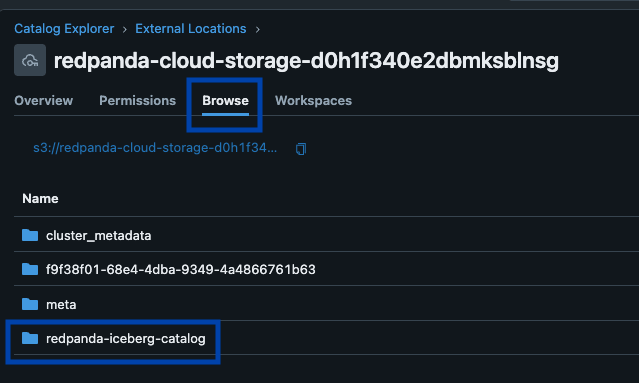
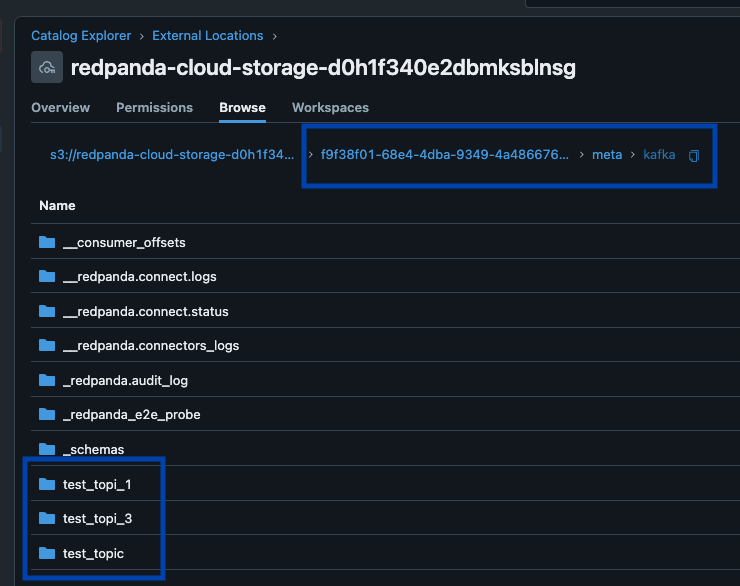
Redpanda manages all your data in a single bucket/container, uses a single Iceberg catalog in Unity Catalog (which Redpanda monitors for graceful recovery), and makes tables easily discoverable by surfacing Unity Catalog’s Iceberg REST endpoint right in Redpanda Cloud’s UI. And now, with Unity Catalog Managed Iceberg Tables, table maintenance operations like compaction, data expiry, and Predictive Optimization are built-in and run automatically by Unity Catalog in the background, while Redpanda takes on the minimal maintenance operations appropriate for its role, (currently Iceberg snapshot cleanup and table creation/deletion). Databricks admins can then secure and govern these tables using all the normal Unity Catalog privileges. �
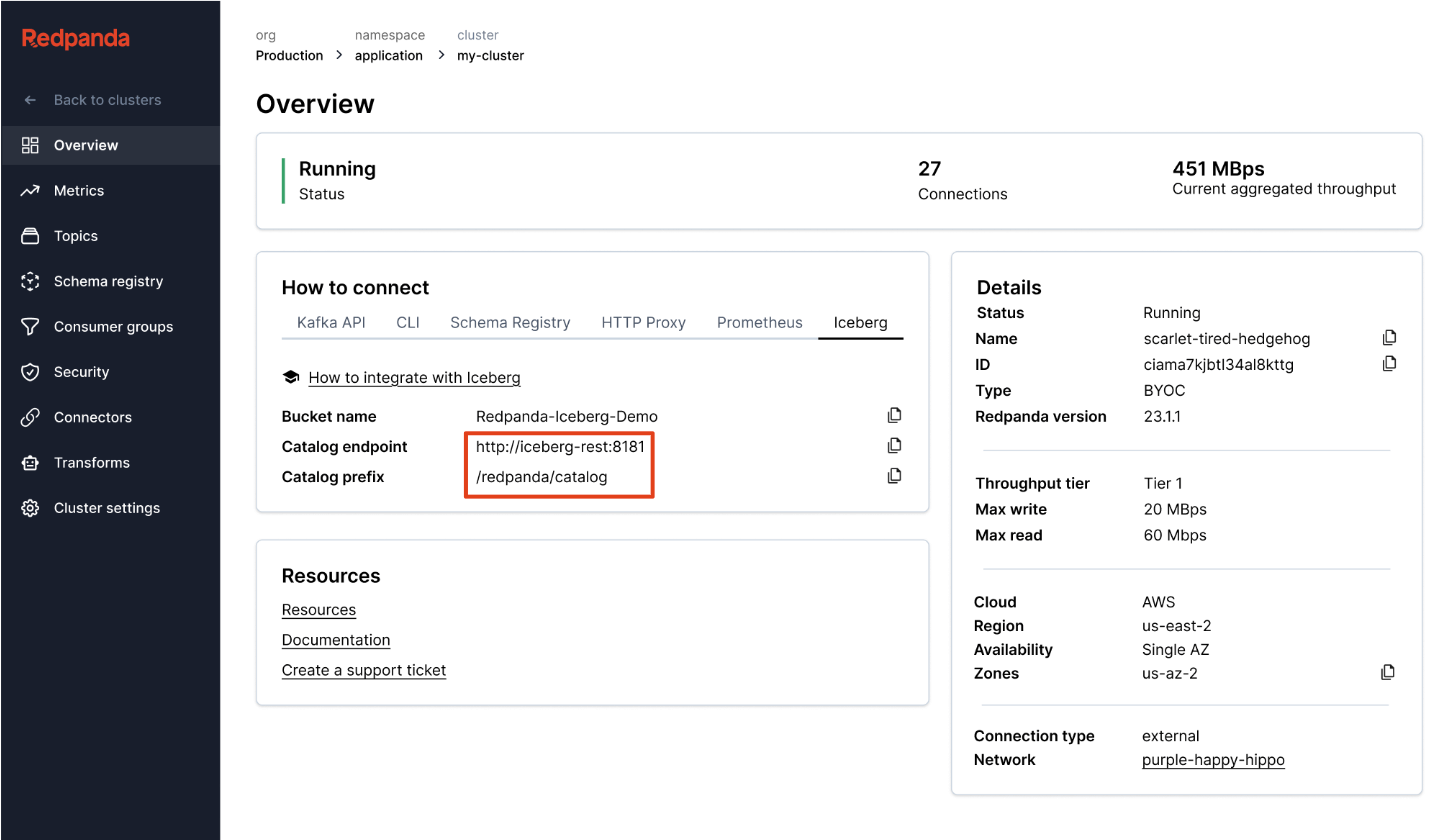
One cluster to rule them all
Most importantly, thanks to our R1 multi-modal streaming engine that uses a thread-per-core architecture and packs features like write caching and multi-level data and workload balancing, admins can run this high-throughput Iceberg ingest in the same cluster, and with the very same topics that power existing low-latency Kafka workloads with sub-10ms SLAs. Using asynchronous, pipelined operations locked to the same CPU cores that handle Produce/Consume requests, we handle both workloads with maximum efficiency in a single process. Most importantly, Iceberg Topics can leverage the full set of Kafka semantics, including Kafka transactions and compacted topics, where the Iceberg layer receives only records from committed transactions. This combination of a fundamentally efficient architecture that solves the hard problems of sophisticated semantics pays huge dividends in slashing your operating costs because, well, one cluster to rule them all. No additional products. No separate clusters. No babysitting pipelines. Deploy anywhere. Keep calm and carry on, streaming platform admins.
Make it simple
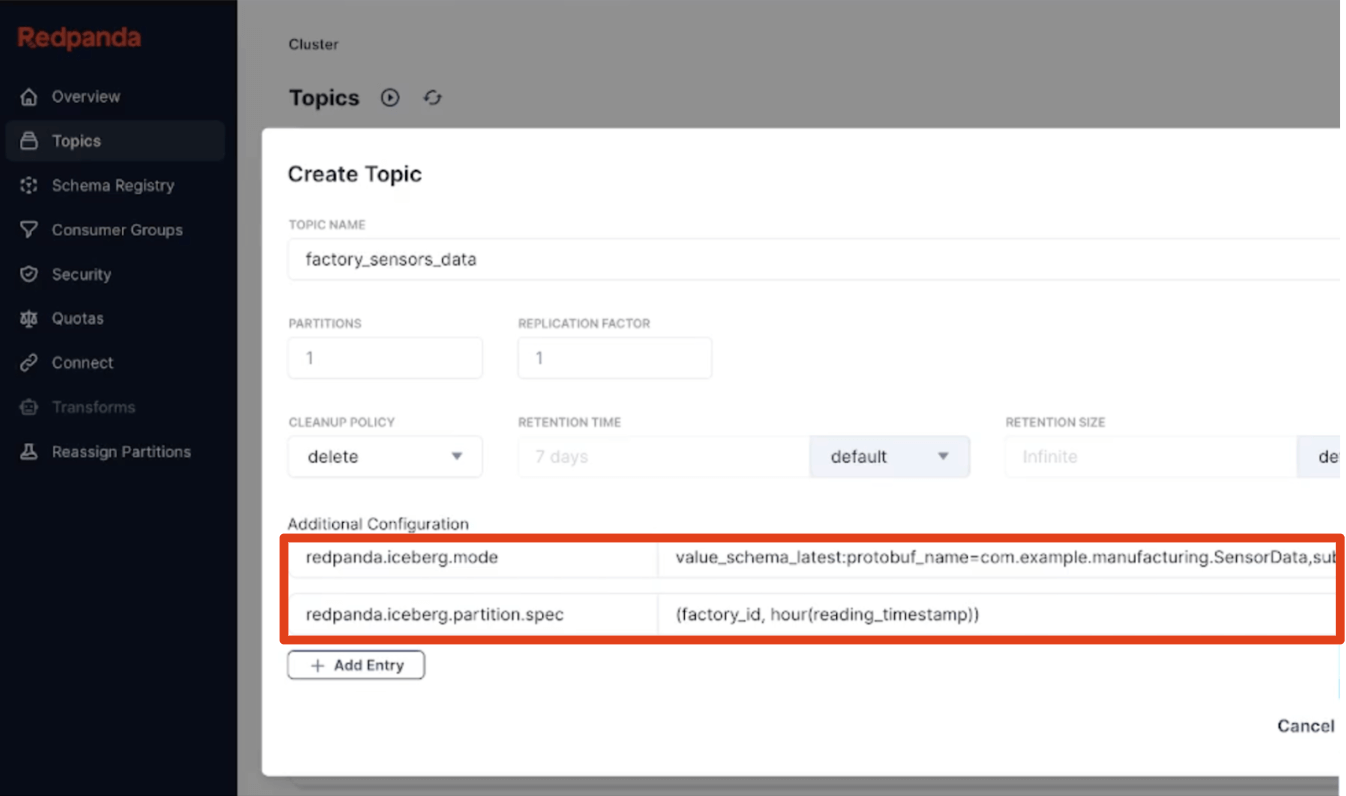
Our third principle was to make some opinionated choices about default behaviors, letting users learn the system gradually with the smartest possible hands-free configuration that works for most use cases. This means built-in hourly table partitioning (fully divorced from Kafka topic partition schemes), always-on dead letter queues as tables to capture any invalid data, and simple, canonical conventions like ‘latest version’ or ‘TopicNameStrategy’ for schema inference make for easy adoption. We also bring Kafka metadata like message partitions, offsets, and keys along for the ride as an Iceberg Struct, so devs have all the provenance to quickly validate the correctness of their streaming pipelines in Iceberg SQL.

The simple should be simple, of course, but the sophisticated should also be straightforward. So defining hierarchical custom partitioning with the full set of Iceberg partition transforms or pulling a specific Protobuf message type from within a subject to become your Iceberg table schema are, again, just declarative single-line topic properties. Schemas can evolve gracefully as Redpanda applies in-place table evolution. And if you need to, run a simple SMT in your favorite language that fans out complex messages from a raw topic into simpler Iceberg fact tables using onboard Data Transforms powered by WebAssembly. The ultimate goal is landing analytics-ready in a single pass. Boom, hello Bronze layer.
The backdrop to all of this innovation is, of course, the fast-evolving Apache Iceberg project and specifications, and Redpanda’s commitment more generally to open standards. That commitment started with its early support of the Kafka protocol, schema registry and HTTP proxy APIs, and even other details like standard topic configuration that allows organizations to seamlessly migrate a whole estate of Kafka applications unchanged. In the Iceberg realm, Redpanda has stepped up as a committed pioneer in the community, implementing a full C++ Iceberg client from the ground up (something not available open source). This client supports the full Iceberg V2 table spec, all schema evolution rules, and partition transforms. On the Iceberg catalog side, repanda both ships a file-based catalog and speaks Iceberg REST for operations like create, commit, update and delete in remote catalogs like Unity Catalog, and supports OIDC authentication, handling your Unity Catalog credentials judiciously as a secret that's transparently encrypted in your cloud provider’s secrets manager. Redpanda has also worked closely with Databricks and other Iceberg leaders to explore how the spec can be extended to support semi-structured stream data through the Variant type, and to make managing table RBAC more seamless by synchronizing policies across the two platforms. This standardization and always implementing to the spec also means minimal vendor lock-in. Organizations are always free to swap out any piece of the system if they find a better option: the streaming platform, the Iceberg catalog or the lakehouse querying/processing the tables.
If you've gotten this far, we sincerely hope you’ve gotten a feel for the thoughtful rigor in Redpanda’s approach to this red-hot market opportunity, one that stems from a strong engineering culture and passion for building rock-solid products. As technologists at heart with solid track records, and with our focus on the BYOC form factor in particular, Redpanda and Databricks are perfectly aligned to deliver two best-of-breed platforms that act and feel like one, and one that, for you, makes the steam-to-table problem well solved.
Try Iceberg Topics with Unity Catalog using Redpanda’s unique Bring-Your-Own-Cloud offering today. Or, start with a free trial of our self-managed flavor, Redpanda Enterprise!: https://cloud.redpanda.com/try-enterprise.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.