Repensando SQL ETL para plataformas de dados modernas
Reduza custos e complexidade unificando pipelines SQL fragmentados em uma única plataforma
por Matt Jones e Shanelle Roman
- O ETL SQL fragmentado gera custos ocultos, pipelines frágeis e resolução lenta de incidentes.
- Executar ETL em diferentes warehouses, orquestradores e ferramentas cria um atrito operacional que aumenta a cada pipeline.
- Uma plataforma unificada para todo o ETL SQL remove a sobrecarga de coordenação e permite que as equipes entreguem mais rapidamente em um sistema governado.
SQL é a base do trabalho de dados moderno. É como os engenheiros de análise definem transformações, como os engenheiros de data warehouse gerenciam pipelines e como os analistas exploram e refinam dados.
Mas, embora o SQL em si seja padronizado, os sistemas usados para executar o SQL ETL estão longe de ser.
Na maioria das organizações, os pipelines SQL estão espalhados por uma combinação de ferramentas: um data warehouse para execução, um framework de transformação para modelagem, um orquestrador para agendamento e sistemas separados para monitoramento, linhagem e qualidade de dados. Cada camada aborda uma necessidade específica, mas juntas elas criam um ambiente fragmentado que é difícil de operar e cada vez mais difícil de escalar.
À medida que as equipes de dados escalam, essa fragmentação começa a aparecer nas operações diárias. Pipelines falham em múltiplos sistemas, as dependências são difíceis de rastrear e a resolução de problemas frequentemente exige alternar entre ferramentas que nunca foram projetadas para funcionar juntas. Ao mesmo tempo, as expectativas aumentam. As equipes são solicitadas a entregar dados mais recentes, suportar mais casos de uso e agir mais rapidamente, sem adicionar sobrecarga operacional.
É aqui que muitas estratégias de plataforma de dados começam a falhar. Mesmo com as organizações investindo em infraestrutura moderna, o SQL ETL frequentemente permanece distribuído em múltiplos sistemas, carregando a mesma complexidade e as mesmas restrições.
O desafio não é o SQL em si - é como o SQL ETL é implementado.
Se o SQL ETL fosse projetado desde o início para a forma como as equipes realmente trabalham hoje, ele seria muito diferente. Na prática, significaria:
- Uma única plataforma para ETL
- Suporte para todo profissional de SQL
- Pipelines abertos e prontos para o futuro
Juntos, esses princípios definem uma abordagem mais simples e durável para o SQL ETL - uma que reduz a fragmentação hoje, ao mesmo tempo em que suporta a evolução das cargas de trabalho de dados ao longo do tempo.
Execute e opere SQL ETL em uma única plataforma
O desafio no SQL ETL não é escrever transformações - é operar pipelines à medida que eles abrangem múltiplos sistemas.
Na prática, isso significa coordenar a execução no data warehouse, a orquestração em um sistema separado e a observabilidade adicionada posteriormente. Manter os pipelines em execução exige unir essas peças - rastrear dependências, diagnosticar falhas e gerenciar novas tentativas em ferramentas que não compartilham contexto.
À medida que os pipelines crescem em número e importância, essa coordenação se torna uma carga operacional significativa.
Uma plataforma unificada simplifica esse modelo ao reunir essas capacidades. Quando a execução, orquestração, observabilidade e governança fazem parte do mesmo sistema, os pipelines se tornam mais fáceis de gerenciar por design. As dependências são rastreadas automaticamente, e os problemas podem ser identificados e resolvidos mais rapidamente porque o contexto relevante está disponível em um só lugar.
Na Databricks, o SQL ETL é definido e executado dentro de uma única plataforma. Os pipelines são executados com orquestração integrada, enquanto a linhagem e a observabilidade são capturadas automaticamente em cada estágio. As verificações de qualidade de dados e os controles de governança são integrados diretamente na execução do pipeline, em vez de serem gerenciados por meio de ferramentas separadas.
Essa abordagem é ainda mais fortalecida pela infraestrutura serverless e otimização impulsionada por IA. O ajuste de desempenho, o gerenciamento de recursos e o dimensionamento são tratados automaticamente, permitindo que as equipes se concentrem em entregar dados confiáveis, em vez de operar sistemas.
Após a transição de nossos pipelines Databricks para computação serverless, a HP obteve economias na nuvem de mais de 32% e diminuiu o tempo de execução combinado dos trabalhos em 36%. O gerenciamento de infraestrutura sem esforço fornecido pelo serverless tornou essa decisão uma escolha óbvia e estratégica. —Luis Alonso, Head de Estratégia e Engenharia de Dados na HP Marketing
O resultado é uma base mais simplificada e confiável para o SQL ETL - uma que reduz a sobrecarga operacional enquanto melhora o desempenho e a confiabilidade em escala.
Apoie como as equipes realmente constroem pipelines SQL
O SQL ETL é fragmentado não apenas por causa das ferramentas, mas porque as equipes não constroem todos os pipelines da mesma maneira.
Engenheiros de análise - que se concentram em definir a lógica de negócios em SQL - frequentemente desejam uma maneira de construir pipelines sem gerenciar a infraestrutura subjacente, com testes, controle de versão e dependências tratados automaticamente. Engenheiros de data warehouse tendem a confiar em scripts SQL e stored procedures, muitas vezes dentro de ambientes de execução rigidamente controlados. Analistas podem criar transformações diretamente em ferramentas no-code ou interfaces SQL leves.
Muitas plataformas favorecem implicitamente uma dessas abordagens. À medida que as organizações crescem, elas frequentemente introduzem sistemas adicionais para suportar outras personas, resultando em ambientes paralelos que são difíceis de padronizar e manter.
Uma abordagem mais eficaz é padronizar a plataforma em vez da interface.
A Databricks suporta uma variedade de fluxos de trabalho SQL ETL dentro do mesmo ambiente. As equipes podem executar fluxos de trabalho dbt existentes diretamente na plataforma, migrar SQL estilo data warehouse para scripts e stored procedures, acelerar cargas de trabalho de BI com Materialized Views no Databricks SQL, definir pipelines declarativos que simplificam os fluxos de trabalho de produção, ou usar ferramentas no-code para analistas de negócios construídas na mesma plataforma. Embora essas abordagens difiram na forma como os pipelines são criados, elas compartilham o mesmo motor de execução, modelo de governança e framework de observabilidade.

Essa consistência permite que as organizações suportem múltiplos estilos de desenvolvimento sem introduzir fragmentação na forma como os pipelines são executados. As equipes podem trabalhar no nível de abstração que se adapta às suas necessidades, enquanto ainda se beneficiam de linhagem, monitoramento e controles operacionais compartilhados.
Também garante que scripts SQL estilo data warehouse existentes e abordagens mais recentes possam coexistir na mesma base. As equipes não precisam escolher entre manter o que têm e adotar novos padrões — elas podem fazer ambos dentro de um único sistema.
Cada um desses fluxos de trabalho é refletido em uma experiência de autoria dedicada.
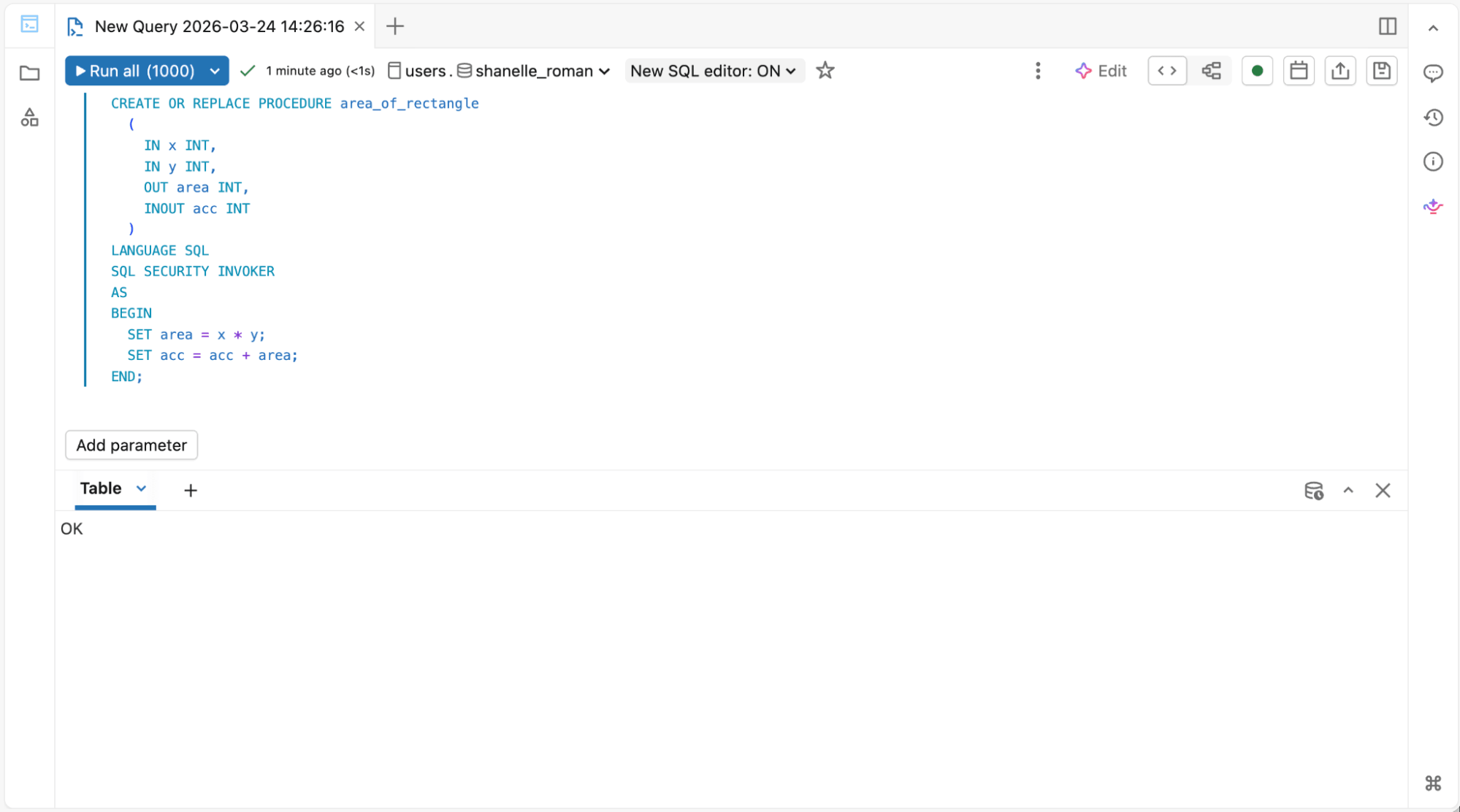
1. Para engenheiros de data warehouse executando scripts SQL e stored procedures:
Editor SQL para Stored Procedures e Materialized Views
{kind=link}
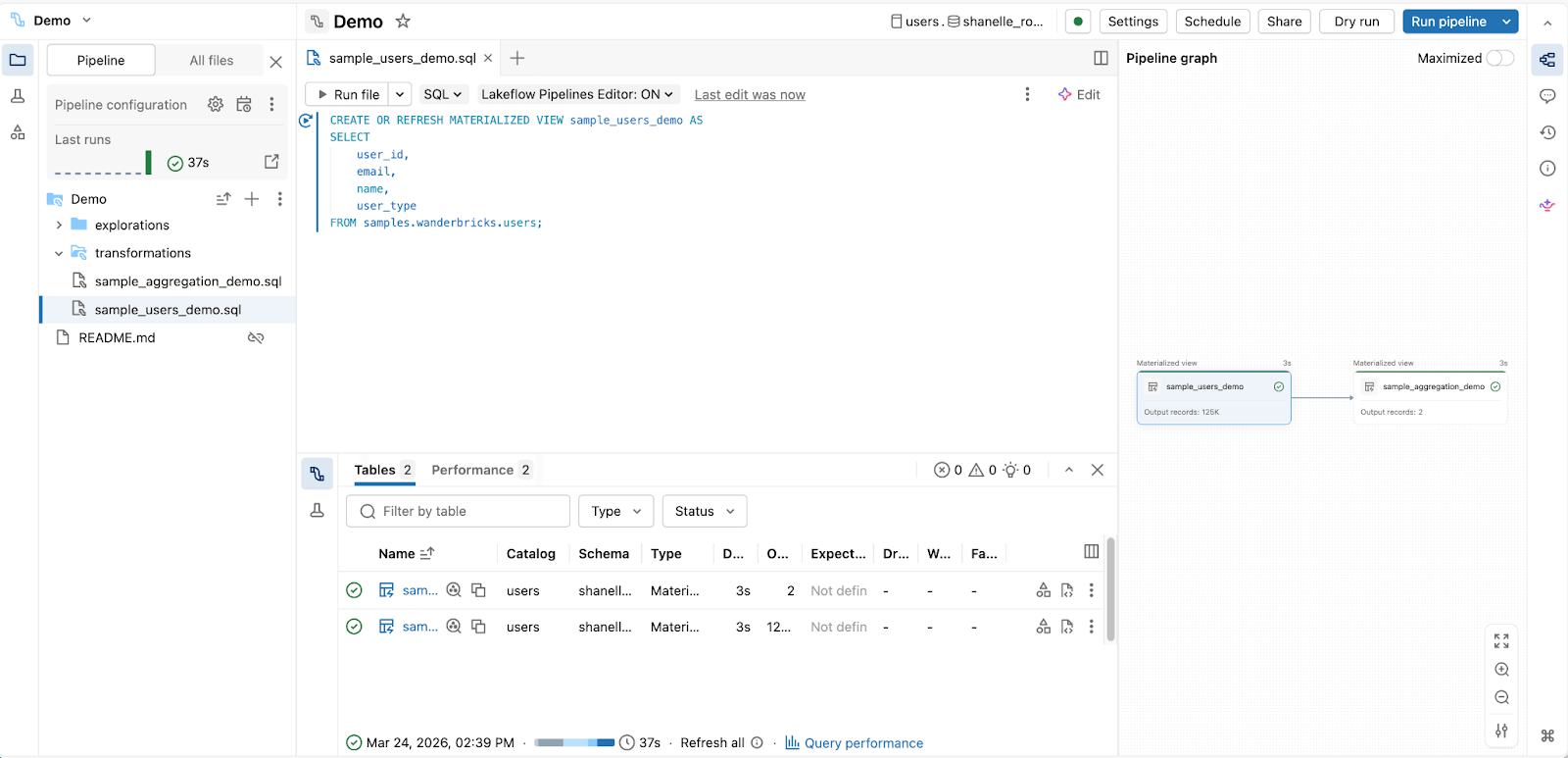
2. Para engenheiros de análise construindo pipelines de produção com SQL:
Editor de Pipelines Declarativos Spark
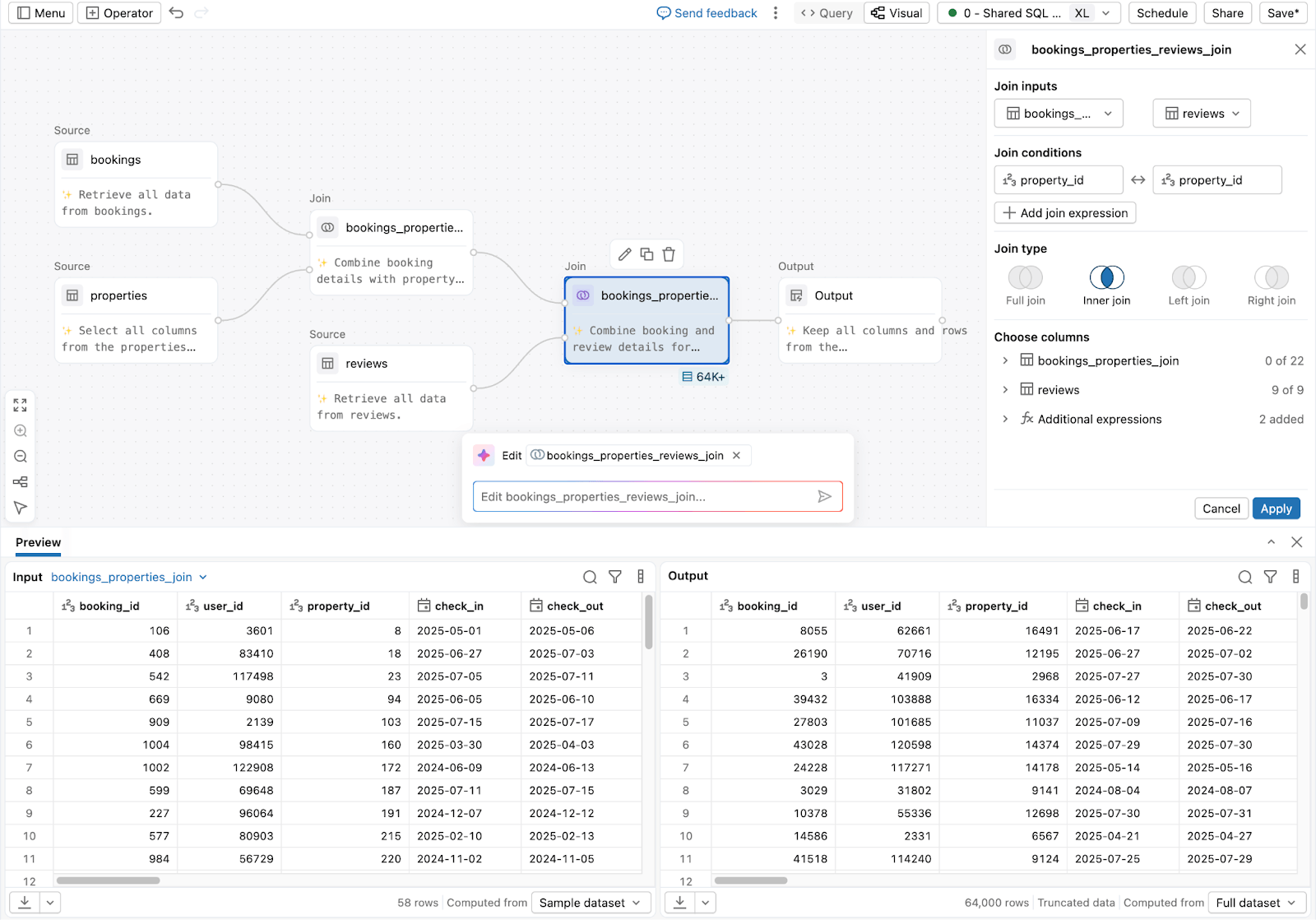
3. Para analistas e usuários de negócios preparando dados sem código:
Lakeflow Designer
O resultado é um ambiente mais coeso para SQL ETL, onde a colaboração melhora e a complexidade operacional não aumenta com a escala.
Construa pipelines SQL que evoluem com suas cargas de trabalho
À medida que novas fontes de dados, casos de uso em tempo real e cargas de trabalho de IA surgem, as equipes são frequentemente forçadas a introduzir sistemas adicionais ou reescrever pipelines existentes - adicionando complexidade e custo ao longo do tempo.
Muitas soluções SQL ETL introduzem essas restrições por meio de formatos proprietários, modelos de execução fortemente acoplados ou suposições sobre como os dados serão processados. Essas restrições podem não ser imediatamente aparentes, mas tendem a surgir à medida que as organizações se expandem para novas cargas de trabalho, exigem dados mais recentes ou suportam um conjunto mais amplo de casos de uso.
Uma abordagem pronta para o futuro para SQL ETL prioriza a abertura e a flexibilidade desde o início.
A Databricks constrói SQL ETL em formatos de tabela abertos e ANSI SQL, ajudando a garantir que os pipelines permaneçam portáteis e interoperáveis entre sistemas. Isso reduz o risco de lock-in e permite que as organizações mantenham o controle sobre seus dados e lógica à medida que sua arquitetura evolui.
Ao mesmo tempo, a Databricks oferece um modelo SQL unificado que suporta casos de uso de análise em lote e em tempo real. Em vez de exigir sistemas separados para diferentes cargas de trabalho, a mesma abordagem baseada em SQL pode ser aplicada em uma ampla gama de casos de uso.
Essa flexibilidade permite que os pipelines evoluam junto com a organização. As equipes podem continuar a executar fluxos de trabalho SQL existentes enquanto adotam padrões mais avançados - como processamento incremental ou pipelines declarativos - quando necessários.
A conversão para Materialized Views resultou em uma melhoria drástica no desempenho das consultas, com o tempo de execução diminuindo de 8 minutos para apenas 3 segundos. Isso permite que nossa equipe trabalhe com mais eficiência e tome decisões mais rápidas com base nos insights obtidos dos dados. Além disso, a economia de custos adicional realmente ajudou. —Karthik Venkatesan, Gerente Sênior de Engenharia de Software de Segurança, Adobe
Ao evitar restrições arquitetônicas rígidas, essa abordagem oferece uma base estável que pode suportar tanto os requisitos atuais quanto as demandas futuras sem exigir mudanças disruptivas.
Por que o SQL ETL deve moldar sua estratégia de plataforma de dados
As discussões sobre plataformas de dados frequentemente se concentram em onde os dados são armazenados e como as consultas são executadas. Na prática, no entanto, a eficácia de uma plataforma depende tanto de como os pipelines de dados são construídos e mantidos, quanto de serem definidos de maneiras abertas e interoperáveis que evitem o aprisionamento (lock-in) a longo prazo.
Se o SQL ETL permanecer fragmentado em vários sistemas, as organizações provavelmente manterão a mesma complexidade operacional e ineficiências, mesmo após a adoção de uma nova plataforma. Com o tempo, isso limita o valor da plataforma e torna mais difícil escalar as operações de dados.
Uma abordagem mais eficaz é avaliar o quão bem uma plataforma suporta o SQL ETL em todo o seu ciclo de vida - do desenvolvimento e execução ao monitoramento e governança. Isso inclui a capacidade de suportar diferentes estilos de trabalho, reduzir a sobrecarga operacional e se adaptar aos requisitos em evolução sem introduzir sistemas adicionais.
Databricks aborda essas necessidades combinando execução SQL, gerenciamento de pipeline, governança e otimização em uma única plataforma. Essa abordagem unificada permite que as equipes construam e operem pipelines SQL com mais eficiência, mantendo a flexibilidade para suportar uma ampla gama de cargas de trabalho.
Conclusão
O SQL continuará a desempenhar um papel central na forma como as organizações trabalham com dados.
Como resultado, a forma como o SQL ETL é implementado tem um impacto direto na eficácia da plataforma de dados geral. Abordagens fragmentadas introduzem complexidade e atrasam as equipes, enquanto abordagens unificadas simplificam as operações e melhoram a escalabilidade.
Para organizações que avaliam como evoluir suas plataformas de dados, o SQL ETL é uma consideração central. Databricks oferece um modelo para SQL ETL unificado e à prova de futuro que reúne execução, gerenciamento de pipeline e governança em uma única plataforma, permanecendo aberto e adaptável à medida que os requisitos evoluem.
Na prática, a maioria das organizações não está começando do zero. A modernização do SQL ETL frequentemente estagna porque o custo e o risco de reescrever pipelines de produção são muito altos. Em vez de forçar uma reconstrução disruptiva, uma abordagem mais eficaz é evoluir incrementalmente - executando pipelines existentes primeiro, consolidando sistemas ao longo do tempo e modernizando passo a passo.
É assim que as equipes podem reduzir a fragmentação hoje, enquanto constroem uma plataforma de dados mais unificada e à prova de futuro ao longo do tempo. Vamos aprofundar essa abordagem em mais detalhes em uma postagem futura. Enquanto isso, você pode ler mais sobre como construir, executar e escalar pipelines SQL em uma plataforma lakehouse unificada neste e-book, Um Guia para Construir Pipelines ETL com SQL.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.