Reverse ETL com Lakebase: Ative seus dados do lakehouse para análises operacionais
Forneça dados do lakehouse para aplicações de forma confiável e em escala, sem pipelines personalizados.
por Firas Farah e Yatish Anand
- O Reverse ETL é o processo de tornar os dados curados do lakehouse acionáveis, disponibilizando-os para aplicativos, painéis e sistemas CRM.
- O Lakebase elimina a necessidade de pipelines personalizados, sincronizando dados da camada de ouro diretamente em um banco de dados Postgres totalmente gerenciado.
- O Lakebase suporta casos de uso de baixa latência, como painéis de suporte alimentados por ML, motores de segmentação e experiências de usuário personalizadas, tudo com o poder e a extensibilidade do Postgres.
Introdução: Análise e operações estão convergindo
As aplicações hoje não podem confiar apenas em eventos brutos. Elas precisam de dados curados, contextuais e acionáveis do lakehouse para alimentar personalização, automação e experiências de usuário inteligentes.
Entregar esses dados de forma confiável com baixa latência tem sido um desafio, muitas vezes exigindo pipelines complexos e infraestrutura personalizada.
Lakebase, recentemente anunciado pela Databricks, aborda este problema. Ele combina um banco de dados Postgres de alto desempenho com integração nativa com lakehouse, tornando o ETL reverso simples e confiável.
O que é ETL reverso?
O Reverse ETL sincroniza dados de alta qualidade de um lakehouse nos sistemas operacionais que alimentam as aplicações. Isso garante que conjuntos de dados confiáveis e insights orientados por IA fluam diretamente para aplicações que alimentam personalização, recomendações, detecção de fraude e tomada de decisões em tempo real.
Sem o ETL Reverso, os insights permanecem no lakehouse e não chegam às aplicações que precisam deles. O lakehouse é onde os dados são limpos, enriquecidos e transformados em análises, mas não é construído para interações de aplicativos de baixa latência ou cargas de trabalho transacionais. É aí que o Lakebase entra, entregando dados confiáveis do lakehouse diretamente nas ferramentas onde eles impulsionam a ação, sem pipelines personalizados.
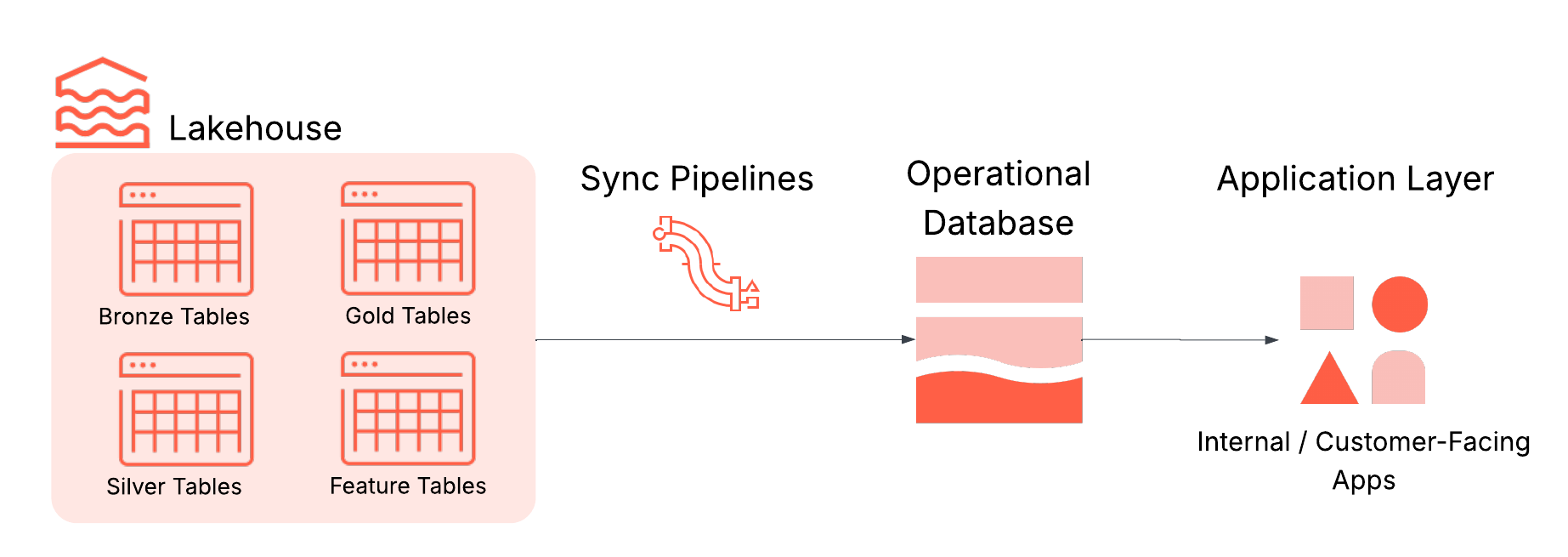
Na prática, o reverse ETL normalmente envolve quatro componentes-chave, todos integrados ao Lakebase:
- Lakehouse: Armazena dados curados de alta qualidade usados para orientar decisões, como tabelas agregadas de nível empresarial (também conhecidas como "tabelas de ouro"), recursos projetados e saídas de inferência de ML.
- Sincronizando pipelines: Mova os dados relevantes para as lojas operacionais com programação, garantias de atualização e monitoramento.
- Banco de dados operacional: Otimizado para alta concorrência, baixa latência e transações ACID.
- Aplicações: O destino final onde os insights se transformam em ação, seja em aplicações voltadas para o cliente, ferramentas internas, APIs ou painéis.
Desafios do reverse ETL hoje
O ETL reverso parece simples, mas na prática, a maioria das equipes enfrenta os mesmos desafios:
- Pipelines ETL personalizados e frágeis: Esses pipelines geralmente requerem infraestrutura de streaming, gerenciamento de esquema, tratamento de erros e orquestração. Eles são frágeis e exigem muitos recursos para manter.
- Sistemas múltiplos e desconectados: Pilhas separadas para análise e operações significam mais infraestrutura para gerenciar, mais camadas de autenticação e mais chances de incompatibilidade de formatos.
- Modelos de governança inconsistentes: Sistemas analíticos e operacionais geralmente vivem em diferentes domínios de política, tornando difícil aplicar controles de qualidade consistentes e políticas de auditoria.
Esses desafios criam atrito tanto para os desenvolvedores quanto para o negócio, retardando os esforços para ativar os dados de forma confiável e entregar aplicações inteligentes em tempo real.
Lakebase: Integrado por padrão para fácil reverse ETL
Lakebase remove essas barreiras e transforma o ETL reverso em um fluxo de trabalho totalmente gerenciado e integrado. Ele combina um motor Postgres de alto desempenho, integração profunda com o lakehouse e sincronização de dados integrada para que insights frescos fluam para as aplicações sem infraestrutura extra.
Essas capacidades do Lakebase são especialmente valiosas para o ETL reverso:
- Integração profunda com o lakehouse: Sincronize dados das tabelas do lakehouse para o Lakebase em uma base de snapshot, agendada ou contínua, sem construir ou gerenciar trabalhos de ETL externos. Isso substitui a complexidade de pipelines personalizados, tentativas de reenvio e monitoramento por uma experiência nativa e gerenciada.
- Postgres totalmente gerenciado: Construído com base no Postgres de código aberto, o Lakebase suporta transações ACID, índices, junções e extensões como PostGIS e pgvector. Você pode se conectar com drivers e ferramentas existentes como pgAdmin ou JDBC, evitando a necessidade de aprender novas tecnologias de banco de dados ou manter infraestrutura OLTP separada.
- Arquitetura escalável e resiliente: O Lakebase separa a computação e o armazenamento para escalonamento independente, entregando latência de consulta inferior a 10 ms e milhares de QPS. Os recursos de nível empresarial incluem alta disponibilidade em várias zonas, recuperação de ponto no tempo e armazenamento criptografado, eliminando os desafios de escalabilidade e resiliência de bancos de dados autogerenciados.
- Segurança e governança integradas: Registre o Lakebase no Catálogo Unity para trazer dados operacionais para o seu framework de governança centralizado, cobrindo auditorias e permissões no nível do catálogo. O acesso via protocolo Postgres ainda usa funções e permissões nativas do Postgres, garantindo segurança transacional autêntica enquanto se encaixa no seu modelo de governança Databricks mais amplo.
- Arquitetura agnóstica em relação à nuvem: Implante o Lakebase ao lado do seu lakehouse no seu ambiente de nuvem preferido sem reestruturar seus fluxos de trabalho.
Com essas capacidades na Plataforma de Inteligência de Dados Databricks, o Lakebase substitui a configuração fragmentada de reverse ETL que depende de pipelines personalizados, sistemas OLTP independentes e governança separada. Ele oferece um serviço integrado, de alto desempenho e seguro, garantindo que insights analíticos fluam para as aplicações mais rapidamente, com menos esforço operacional e com a governança preservada.
Caso de uso de exemplo: Construindo um Portal de Suporte Inteligente com Lakebase
Como exemplo prático, vamos ver como construir um portal de suporte inteligente alimentado pelo Lakebase. Este portal interativo ajuda as equipes de suporte a triar incidentes recebidos usando insights orientados por ML do lakehouse, como risco de escalada previsto e ações recomendadas, permitindo que os usuários atribuam propriedade, acompanhem o status e deixem comentários em cada ticket.
Lakebase torna isso possível sincronizando previsões no Postgres enquanto também armazena atualizações do aplicativo. O resultado é um portal de suporte que combina análises com operações ao vivo. A mesma abordagem se aplica a muitos outros casos de uso, incluindo motores de personalização e painéis orientados por ML.
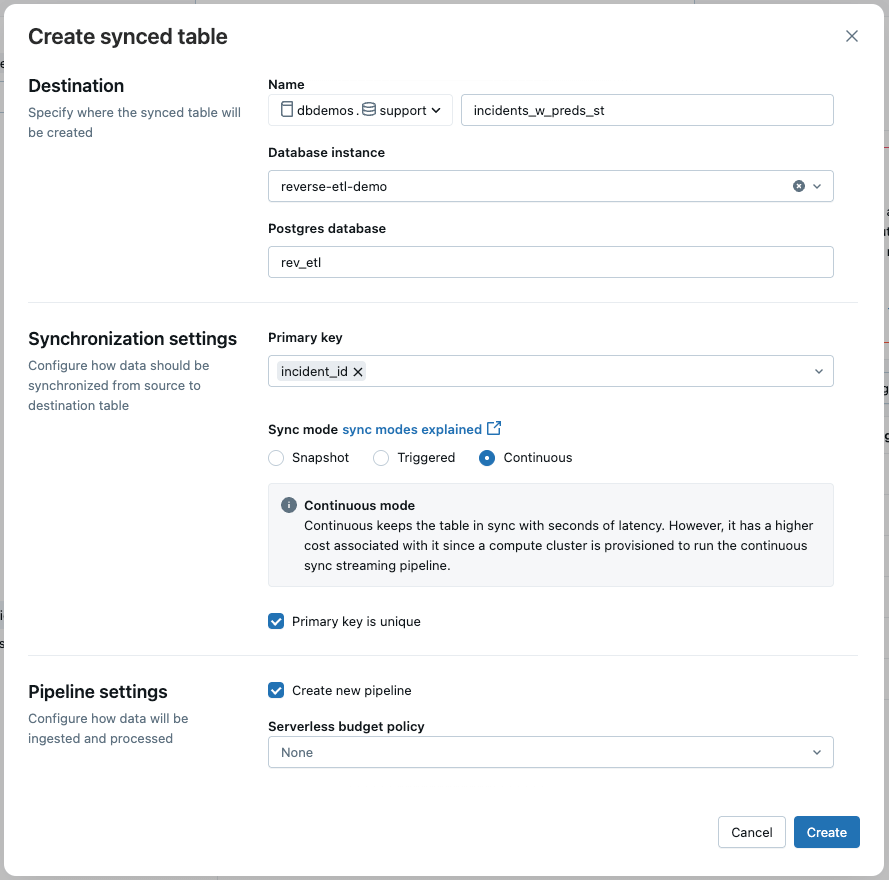
Passo 1: Sincronize as Previsões do Lakehouse para o Lakebase
Os dados do incidente, enriquecidos com previsões de ML, estão em uma tabela Delta e são atualizados em tempo quase real por meio de um pipeline de streaming. Para alimentar o aplicativo de suporte, usamos o reverse ETL do Lakebase para sincronizar continuamente esta tabela Delta com uma tabela Postgres.
Na interface do usuário, selecionamos:
- Modo de sincronização: Contínuo para atualizações de baixa latência
- Chave Primária: incident_id
Isso garante que o aplicativo reflita os dados mais recentes com o mínimo de atraso.
Nota: Você também pode criar o pipeline de sincronização programaticamente usando o SDK Databricks.
Passo 2: Crie uma Tabela de Estado para Entradas do Usuário
O aplicativo de suporte também precisa de uma tabela para armazenar dados inseridos pelo usuário, como propriedade, status e comentários. Como esses dados são escritos a partir do aplicativo, eles devem ir para uma tabela separada no Lakebase (em vez da tabela sincronizada).
Aqui está o esquema:
Este design garante que o reverse ETL permaneça unidirecional (Lakehouse → Lakebase), enquanto ainda permite atualizações interativas através do aplicativo.
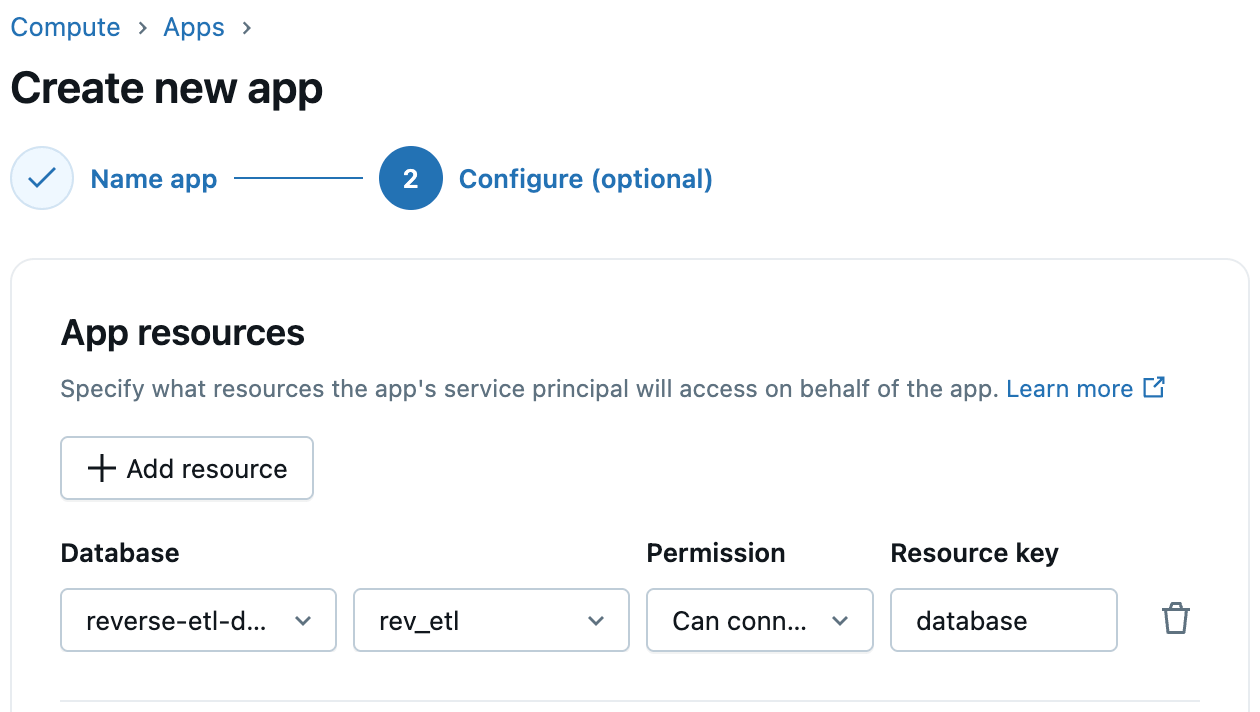
Passo 3: Configure o Acesso ao Lakebase nos Aplicativos Databricks
Os Apps Databricks suportam integração de primeira classe com o Lakebase. Ao criar seu aplicativo, basta adicionar o Lakebase como um recurso do aplicativo e selecionar a instância e o banco de dados do Lakebase. O Databricks provisiona automaticamente uma função Postgres correspondente para o principal de serviço do aplicativo, simplificando a conectividade do aplicativo ao banco de dados. Você pode então conceder a este papel as permissões necessárias de banco de dados, esquema e tabela.
Passo 4: Implemente o Código do Seu Aplicativo
Com seus dados sincronizados e permissões em vigor, agora você pode implementar o aplicativo Flask que alimenta o portal de suporte. O aplicativo se conecta ao Lakebase via Postgres e serve um painel rico com gráficos, filtros e interatividade.
Conclusão
Trazer insights analíticos para aplicações operacionais não precisa mais ser um processo complexo e frágil. Com o Lakebase, o ETL reverso se torna uma capacidade totalmente gerenciada e integrada. Combina o desempenho de um motor Postgres, a confiabilidade de uma arquitetura escalável e a governança da Plataforma Databricks.
Seja você alimentando um portal de suporte inteligente ou construindo outras experiências orientadas por dados em tempo real, o Lakebase reduz a sobrecarga de engenharia e acelera o caminho do insight para a ação.
Para saber mais sobre como criar tabelas sincronizadas no Lakebase, confira nossa documentação e comece hoje mesmo.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.