Simplifique os testes do PySpark com funções de igualdade de DataFrame
Apresentando as funções de teste de igualdade do PySpark DataFrame, por que elas são importantes e como usá-las.
por Haejoon Lee, Allison Wang e Amanda Liu
As funções de teste de igualdade de DataFrame foram introduzidas no Apache Spark™ 3.5 e no Databricks Runtime 14.2 para simplificar o teste de unidade do PySpark. O conjunto completo de recursos descritos nesta postagem de blog estará disponível a partir do próximo Apache Spark 4.0 e Databricks Runtime 14.3.
Escreva transformações de DataFrame mais confiáveis com funções de teste de igualdade de DataFrame
Trabalhar com dados no PySpark envolve aplicar transformações, agregações e manipulações a DataFrames. À medida que as transformações se acumulam, como você pode ter certeza de que seu código funciona como esperado? As funções de utilitário de teste de igualdade do PySpark fornecem uma maneira eficiente e eficaz de verificar seus dados em relação aos resultados esperados, ajudando você a identificar diferenças inesperadas e detectar erros no início do processo de análise. Além disso, elas retornam informações intuitivas que apontam precisamente as diferenças para que você possa agir imediatamente sem gastar muito tempo depurando.
Usando funções de teste de igualdade de DataFrame
Duas funções de teste de igualdade para DataFrames PySpark foram introduzidas no Apache Spark 3.5: assertDataFrameEqual e assertSchemaEqual. Vamos dar uma olhada em como usar cada uma delas.
assertDataFrameEqual: Essa função permite comparar dois DataFrames PySpark quanto à igualdade com uma única linha de código, verificando se os dados e os esquemas correspondem. Ela retorna informações descritivas quando há diferenças.
Vamos percorrer um exemplo. Primeiro, criaremos dois DataFrames, introduzindo intencionalmente uma diferença na primeira linha:
Em seguida, chamaremos assertDataFrameEqual com os dois DataFrames:
A função retorna uma mensagem descritiva indicando que a primeira linha nos dois DataFrames é diferente. Neste exemplo, os primeiros valores listados para Alfred nesta linha não são os mesmos (esperado: 1500, real: 1200):
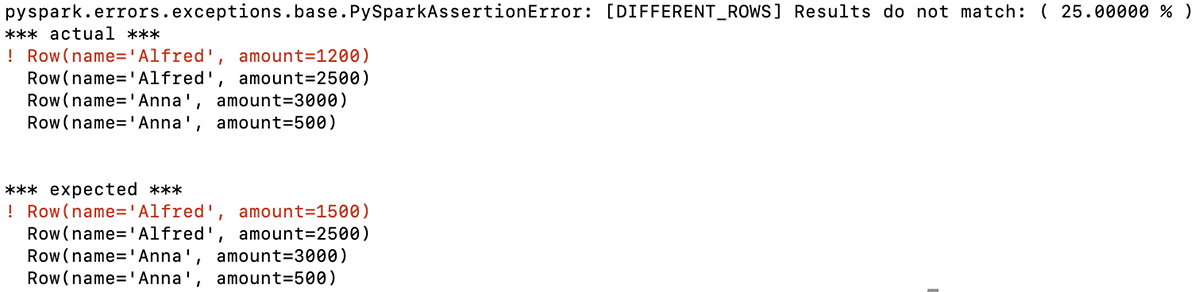
Com essas informações, você sabe imediatamente o problema com o DataFrame que seu código gerou e pode direcionar sua depuração com base nisso.
A função também tem várias opções para controlar a rigidez da comparação de DataFrame para que você possa ajustá-la de acordo com seus casos de uso específicos.
assertSchemaEqual: Essa função compara apenas os esquemas de dois DataFrames; ela não compara os dados da linha. Ela permite validar se os nomes das colunas, os tipos de dados e a propriedade anulável são os mesmos para dois DataFrames diferentes.
Vamos dar uma olhada em um exemplo. Primeiro, criaremos dois DataFrames com esquemas diferentes:
Agora, vamos chamar assertSchemaEqual com esses dois esquemas de DataFrame:
A função determina que os esquemas dos dois DataFrames são diferentes e a saída indica onde eles divergem:

Neste exemplo, existem duas diferenças: o tipo de dados da coluna amount é LONG no DataFrame real, mas DOUBLE no DataFrame esperado e, como criamos o DataFrame esperado sem especificar um esquema, os nomes das colunas também são diferentes.
Ambas as diferenças são destacadas na saída da função, conforme ilustrado aqui.
assertPandasOnSparkEqual não é abordado nesta postagem de blog, pois foi descontinuado do Apache Spark 3.5.1 e está programado para ser removido no próximo Apache Spark 4.0.0. Para testar a API Pandas no Spark, consulte API Pandas nas funções de teste de igualdade do Spark.
Saída estruturada para depurar diferenças em DataFrames PySpark
Embora as funções assertDataFrameEqual e assertSchemaEqual sejam direcionadas principalmente para testes de unidade, onde normalmente você usa conjuntos de dados menores para testar suas funções PySpark, você pode usá-las com DataFrames com mais do que apenas algumas linhas e colunas. Nesses cenários, você pode recuperar facilmente os dados da linha para linhas que são diferentes para facilitar ainda mais a depuração.
Vamos dar uma olhada em como fazer isso. Usaremos os mesmos dados que usamos anteriormente para criar dois DataFrames:
E agora vamos pegar os dados que diferem entre os dois DataFrames dos objetos de erro de declaração após chamar assertDataFrameEqual:
Criar um DataFrame com base nas linhas que são diferentes e mostrá-lo, como fizemos neste exemplo, ilustra como é fácil acessar essas informações:

Como você pode ver, as informações sobre as linhas que são diferentes estão imediatamente disponíveis para análise posterior. Você não precisa mais escrever código para extrair essas informações dos DataFrames reais e esperados para fins de depuração.
Este recurso estará disponível no próximo Apache Spark 4.0 e DBR 14.3.
API Pandas nas funções de teste de igualdade do Spark
Além das funções para testar a igualdade de DataFrames PySpark, os usuários da API Pandas no Spark terão acesso às seguintes funções de teste de igualdade de DataFrame:
assert_frame_equalassert_series_equalassert_index_equal
As funções fornecem opções para controlar a rigidez das comparações e são ótimas para testar a unidade da sua API Pandas em DataFrames Spark. Elas fornecem a mesma API que as funções de utilitário de teste do pandas, para que você possa usá-las sem alterar o código de teste do pandas existente que deseja executar usando a API Pandas no Spark.
Aqui estão alguns exemplos demonstrando o uso de assert_frame_equal com diferentes parâmetros, comparando a API Pandas em DataFrames Spark:
Neste exemplo, os esquemas dos dois DataFrames são diferentes. A saída da função lista as diferenças, conforme mostrado aqui:

Podemos especificar que queremos que a função compare os dados da coluna, mesmo quando as colunas não têm o mesmo tipo de dados usando o argumento check_dtype, como neste exemplo:
Como especificamos que assert_frame_equal deve ignorar os tipos de dados da coluna, agora ele considera os dois DataFrames iguais.
Essas funções também permitem comparações entre a API Pandas em objetos Spark e objetos pandas, facilitando as verificações de compatibilidade entre diferentes bibliotecas DataFrame, conforme ilustrado neste exemplo:
Usar as novas funções de teste de igualdade da API Pandas no Spark e DataFrame PySpark é uma ótima maneira de garantir que seu código PySpark funcione como esperado. Essas funções ajudam você não apenas a detectar erros, mas também a entender exatamente o que deu errado, permitindo que você identifique de forma rápida e fácil onde está o problema. Confira a página Testando PySpark para obter mais informações.
Essas funções estarão disponíveis no próximo Apache Spark 4.0. O DBR 14.2 já oferece suporte a ele.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.