Pare de Codificar Manualmente Pipelines de Captura de Dados de Alteração
Como o AutoCDC Automatiza CDC e Dimensões de Mudança Lenta
por Matt Jones, Zoé Durand, Phoebe Weiser, Bilal Aslam e Ray Zhu
- Por que pipelines de CDC e SCD codificados manualmente são frágeis, complexos e caros para operar em escala
- Como o AutoCDC automatiza declarativamente os padrões SCD Tipo 1, SCD Tipo 2 e CDC baseados em snapshot
- Ganhos reais em correção, desempenho e custo de cargas de trabalho de AutoCDC em produção
Eu experimentei o AutoCDC a partir de Snapshots em Python e fiquei impressionado com o quão 4 linhas de código puderam substituir o que eu fazia em 1.500 linhas de código antes. —Engenheiro de Dados Sênior, Empresa Fortune 500 de Aeroespacial e Defesa
Captura de dados de alteração (CDC) e dimensões de mudança lenta (SCD) são fundamentais para cargas de trabalho modernas de análise e IA. As equipes dependem delas para manter as tabelas downstream precisas à medida que os dados operacionais mudam - seja isso manter uma visão atual do negócio ou preservar o contexto histórico completo.
No entanto, na prática, os pipelines de CDC são frequentemente alguns dos pipelines mais difíceis de construir e operar. As equipes criam manualmente lógica complexa de MERGE para lidar com atualizações, exclusões e dados que chegam atrasados: adicionando tabelas de staging, funções de janela e suposições de sequenciamento que são difíceis de raciocinar e ainda mais difíceis de manter à medida que os pipelines evoluem.
Neste post, vamos detalhar os padrões de CDC e SCD que engenheiros de dados e praticantes de SQL encontram todos os dias, por que esses padrões são difíceis de implementar manualmente e como o AutoCDC no Lakeflow Spark Declarative Pipelines os automatiza declarativamente - ao mesmo tempo que oferece melhorias significativas em preço e desempenho.
CDC e SCD ainda são difíceis para engenheiros de dados
Mesmo para equipes que entendem bem esses padrões, acertá-los e mantê-los corretos ao longo do tempo é onde as coisas dão errado. À medida que os volumes de dados crescem e os casos de uso se expandem, os pipelines se tornam frágeis; problemas de correção surgem tarde; e até mesmo pequenas alterações exigem reescritas cuidadosas para evitar a corrupção de tabelas downstream.
Mantendo tabelas SCD Tipo 1
Tabelas SCD Tipo 1 sobrescrevem linhas existentes para refletir o estado mais recente. Mesmo este caso “simples” rapidamente encontra desafios:
- Atualizações chegam fora de ordem
- Eventos duplicados devem ser consistentemente deduplicados
- Exclusões devem ser aplicadas corretamente
- A lógica deve permanecer idempotente em retentativas e reprocessamento
O que muitas vezes começa como um simples MERGE INTO evolui para lógica aninhada profunda com tabelas de staging, funções de janela e suposições de sequenciamento que são difíceis de raciocinar (ou mudar com segurança). Com o tempo, as equipes ficam relutantes em tocar nesses pipelines.
Mantendo o histórico SCD Tipo 2
SCD Tipo 2 introduz complexidade adicional:
- Rastreamento de versões de linha e janelas de validade
- Lidar com atualizações que chegam atrasadas sem corromper o histórico
- Garantir que exista exatamente uma versão “atual” a qualquer momento
Erros aqui nem sempre falham de forma explícita. Eles muitas vezes surgem semanas depois como desvios sutis de métricas, ou a necessidade de reconstruir tabelas históricas inteiras.
Extraindo dados de alteração de diferentes fontes
Nem todos os sistemas emitem logs de CDC limpos. Alguns sistemas emitem feeds de dados de alteração nativos, enquanto outros não - muitas vezes porque a equipe que consome os dados não controla o banco de dados upstream - forçando as equipes a reconstruir as alterações comparando snapshots sucessivos de uma tabela de origem.
Suportar ambos geralmente significa lógica de ingestão e processamento separadas; suposições de correção diferentes; e mais caminhos de código para manter e depurar.
Operando pipelines de CDC ao longo do tempo
Mesmo depois que um pipeline de CDC está correto, ele ainda precisa sobreviver a reprocessamento e preenchimentos retroativos, evolução de esquema, falhas e reinícios. A lógica de CDC criada manualmente tende a se tornar mais frágil com o tempo à medida que essas realidades se acumulam, aumentando o risco operacional e o custo de manutenção.
Automatizando padrões complexos de CDC com engenharia de dados declarativa
O AutoCDC foi projetado para padronizar esses padrões comuns de CDC e SCD por trás de uma abstração declarativa. Em vez de codificar manualmente *como* as alterações devem ser aplicadas, as equipes declaram *quais semânticas* elas desejam, e a plataforma gerencia o ordenamento, o estado e o processamento incremental.
| Carga de trabalho de CDC | AutoCDC | Lógica de MERGE / Snapshot Manual |
|---|---|---|
| Manutenção de tabelas de estado atual (SCD Tipo 1) | Definição declarativa de pipeline lida automaticamente com sequenciamento, deduplicação e exclusões | Lógica MERGE personalizada com funções de janela e regras de sequenciamento |
| Manutenção de tabelas históricas (SCD Tipo 2) | Gerenciamento automático de versão com rastreamento de histórico integrado | Lógica MERGE de várias etapas para fechar e inserir versões de registro |
| Inferindo alterações de fontes de snapshot | Suporte integrado para CDC de snapshot | Pipelines manuais de diff de snapshot com joins e comparações |
| Operando pipelines de forma confiável ao longo do tempo (dados atrasados, retentativas, reprocessamento) | Ordenamento automático e execução idempotente | Requer salvaguardas personalizadas e lógica adicional |
| Pegada de código e complexidade operacional | ~6–10 linhas de definição de pipeline declarativa | 40–200+ linhas de lógica de pipeline personalizada |
Isso oferece às equipes uma maneira consistente e repetível de implementar CDC e SCD em todos os pipelines, em vez de reinventar o padrão a cada vez (que é realmente o valor principal da programação declarativa em geral, e do Spark Declarative Pipelines especificamente).
Ao processar registros de alteração de um feed de dados de alteração (CDF), o AutoCDC lida automaticamente com registros fora de sequência e aplica atualizações corretamente com base em uma coluna de sequenciamento declarada. Para mostrar como isso funciona na prática, vamos considerar o feed de CDC de exemplo abaixo:
| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | INSERT | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
Lembre-se, você deve escolher SCD Tipo 1 para manter apenas os dados mais recentes, ou escolher SCD Tipo 2 para manter os dados históricos. Vamos começar com o Tipo 1.
Automatizando a manutenção de SCD Tipo 1 (fontes de feed de dados de alteração)
Neste exemplo, um feed de dados de alteração contém inserções, atualizações e exclusões para uma tabela de usuários. O objetivo é manter uma visão atual de cada registro, onde novas atualizações sobrescrevem valores mais antigos.
Tabela de saída para SCD Tipo 1
| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
O usuário 123 (Isabel) foi excluído, portanto, não aparece na saída. O usuário 125 (Mercedes) mostra apenas a cidade mais recente (Guadalajara) porque o SCD Tipo 1 sobrescreve valores anteriores.
Com uma abordagem tradicional, isso requer lógica MERGE personalizada para deduplicar eventos, impor ordenação, aplicar exclusões e garantir que o pipeline permaneça correto em retentativas ou dados que chegam atrasados. O AutoCDC substitui essa lógica frágil por uma definição de pipeline declarativa que lida automaticamente com sequenciamento, deduplicação, dados que chegam atrasados e processamento incremental - eliminando dezenas de linhas de lógica de merge personalizada.
Veja o exemplo de código completo no apêndice
Automatizando o histórico SCD Tipo 2 (fontes de feed de dados de alteração)
Em muitos sistemas analíticos, manter apenas o estado mais recente não é suficiente - as equipes precisam de um histórico completo de como os registros mudam ao longo do tempo. Este é o padrão SCD Tipo 2, onde cada versão de um registro é armazenada com janelas de validade indicando quando estava ativa.
Tabela de saída para SCD tipo 2:
| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
A tabela preserva o histórico completo. O usuário 123 tem duas versões (encerradas na sequência 6 quando excluído). O usuário 125 tem três versões mostrando alterações de cidade. Registros com __END_AT = NULL estão atualmente ativos.
Implementar isso manualmente requer lógica MERGE de várias etapas para encerrar registros anteriores, inserir novas versões e garantir que apenas uma versão permaneça ativa por vez. O AutoCDC automatiza essas transições de forma declarativa, gerenciando colunas de histórico e lógica de versionamento automaticamente, garantindo a correção mesmo quando as atualizações chegam fora de ordem.
Veja o exemplo de código completo em apêndice
Inferindo CDC de fontes de snapshot
Nem todos os sistemas de origem emitem logs de alteração. Em muitos casos, as equipes recebem snapshots periódicos de uma tabela de origem e precisam inferir o que mudou entre as execuções.
Tradicionalmente, isso requer a comparação manual de snapshots para detectar inserções, atualizações e exclusões antes de aplicar essas alterações com a lógica MERGE. O AutoCDC trata o CDC baseado em snapshot como um padrão de primeira classe, detectando automaticamente alterações em nível de linha entre snapshots e aplicando-as incrementalmente sem exigir lógica de diff personalizada ou gerenciamento de estado.
Implementar isso manualmente requer a detecção de alterações em nível de linha entre snapshots, o encerramento de registros ativos anteriores e a inserção de novas versões com janelas de validade atualizadas. O AutoCDC deriva automaticamente essas alterações e aplica a semântica do SCD Tipo 2, mantendo o histórico de versões sem exigir lógica de merge de várias etapas ou rastreamento de estado de snapshot personalizado.
Gerenciando ordenação, estado e reprocessamento
Lakeflow Spark Declarative Pipelines rastreia automaticamente o progresso incremental e lida com dados fora de sequência. Os pipelines podem se recuperar de falhas, reprocessar dados históricos e evoluir ao longo do tempo sem aplicar em duplicidade ou perder alterações.
Na prática, isso remove a necessidade de as equipes gerenciarem a lógica de sequenciamento, o registro de marca d'água ou a segurança de reprocessamento por conta própria - a plataforma cuida disso.
Novidades: grandes ganhos de preço e desempenho
Além de simplificar a lógica do pipeline, melhorias recentes no Databricks Runtime proporcionaram ganhos substanciais tanto em desempenho quanto em eficiência de custo para cargas de trabalho AutoCDC - desde novembro de 2025:
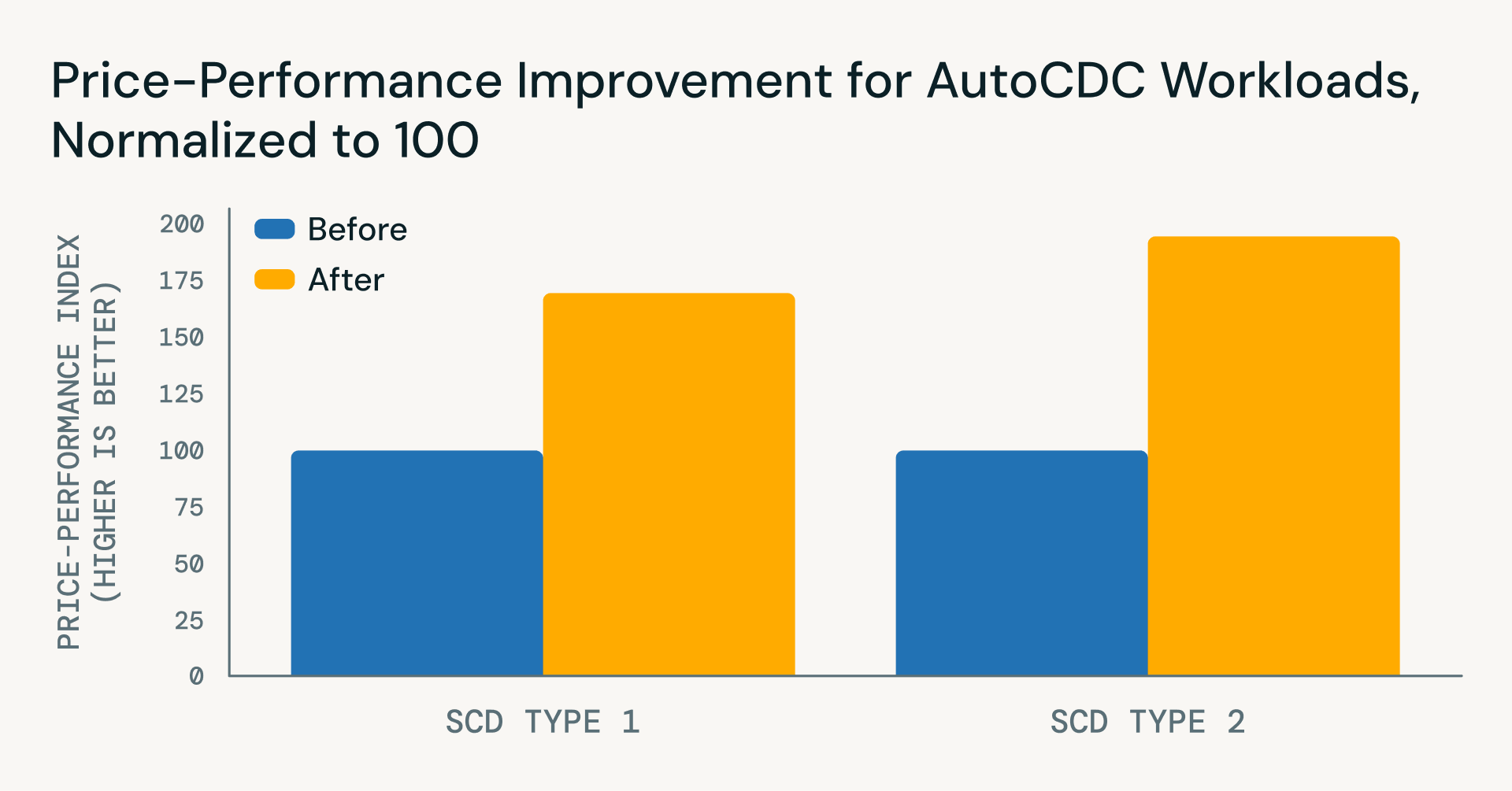
- SCD Tipo 1
- ~22% de melhoria na latência
- ~40% de redução no custo
- ~71% de benefício líquido de preço-desempenho
- SCD Tipo 2
- ~45% de redução na latência
- ~35% de redução no custo para atualizações incrementais
- ~96% de benefício líquido de preço-desempenho
Esses ganhos são importantes para pipelines do mundo real que rodam continuamente em escala. Embora MERGE INTO permaneça um primitivo fundamental do Spark, o AutoCDC se baseia nele para lidar com dados fora de sequência e processamento incremental de forma mais eficiente à medida que os volumes de dados crescem.
Sucesso do cliente com AutoCDC
Equipes que executam pipelines CDC e SCD em produção citaram explicitamente o AutoCDC como um fornecedor de valor significativo:
A Navy Federal Credit Union usa o AutoCDC no Lakeflow Spark Declarative Pipelines para potencializar o processamento de eventos em tempo real em larga escala — lidando com bilhões de eventos de aplicativos continuamente, eliminando código CDC personalizado e manutenção contínua do pipeline.
A simplicidade do modelo de programação Spark Declarative Pipelines, combinada com seus recursos de serviço, resultou em um tempo de resposta incrivelmente rápido. —Jian (Miracle) Zhou, Gerente Sênior de Engenharia, Navy Federal Credit Union
A Block usa o AutoCDC no Lakeflow Spark Declarative Pipelines para simplificar a captura de dados de alteração e pipelines de streaming em tempo real no Delta Lake, substituindo o CDC codificado manualmente e a lógica de merge por uma abordagem declarativa que é rápida de implementar e fácil de operar.
Com a adoção do Spark Declarative Pipelines, o tempo necessário para definir e desenvolver um pipeline de streaming passou de dias para horas. —Yue Zhang, Engenheiro de Software Sênior, Data Foundations, Block
A Valora Group, uma provedora líder suíça de "foodvenience", usa o AutoCDC no Lakeflow Spark Declarative Pipelines para otimizar a captura de dados de alteração para dados mestre e análise de varejo em tempo real, substituindo o código CDC personalizado por uma abordagem declarativa que é fácil de implementar, repetir e escalar entre equipes.
Ganhamos muito ao fazer CDC em SDP, porque você não escreve nenhum código - tudo é abstraído em segundo plano. O AutoCDC minimiza o número de linhas... é muito fácil de fazer. —Alexane Rose, Arquiteta de Dados e IA, Valora Holding
Comece
O AutoCDC está disponível como parte do Lakeflow Spark Declarative Pipelines no Databricks.
Para saber mais:
- Revise a documentação do AutoCDC (SQL e Python)
- Explore exemplos para SCD Tipo 1, SCD Tipo 2 e CDC baseado em snapshot
Experimente o AutoCDC em seus próprios pipelines e elimine a lógica CDC escrita manualmente!
Apêndice
Exemplo de SCD Tipo 1
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Apply SCD Type 1: upsert updates, delete deletions
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(updates.alias("s"), "s.userId = t.userId")
.whenMatchedDelete(condition="s.operation = 'DELETE'")
.whenMatchedUpdate(
condition="s.sequenceNum > t.sequenceNum",
set={"name": "s.name", "city": "s.city", "sequenceNum": "s.sequenceNum"}
)
.whenNotMatchedInsertAll(condition="s.operation != 'DELETE'")
.execute())
| from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr
@dp.view
def users():
return spark.readStream.table("cdc_data.users")
dp.create_streaming_table("target")
dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=1
)
|
Exemplo de SCD Tipo 2
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import col, lit, max_by, struct
# Deduplicate: keep latest record per userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Step 1: close out active rows for records being updated or deleted
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(
updates.alias("s"),
"s.userId = t.userId AND t.__END_AT IS NULL AND s.sequenceNum > t.__START_AT"
)
.whenMatchedUpdate(set={"__END_AT": "s.sequenceNum"})
.execute())
# Step 2: insert new rows for inserts and updates (not deletes)
new_rows = (updates
.filter("operation != 'DELETE'")
.withColumn("__START_AT", col("sequenceNum"))
.withColumn("__END_AT", lit(None).cast("long"))
.drop("operation"))
new_rows.write.mode("append").saveAsTable("target")
| dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=2
)
|
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.