Dados estruturados versus não estruturados
- Dados estruturados são organizados em esquemas predefinidos - Armazenados em tabelas com formatos fixos, os dados estruturados permitem queries SQL rápidas, dão suporte a ferramentas de Business Intelligence e servem à analítica tradicional, como relatórios e previsões, mas as alterações de esquema podem ser desafiadoras.
- Dados não estruturados representam de 80 a 90% dos dados corporativos e exigem ferramentas avançadas para extrair percepções de data lakes ou arquiteturas de lakehouse.
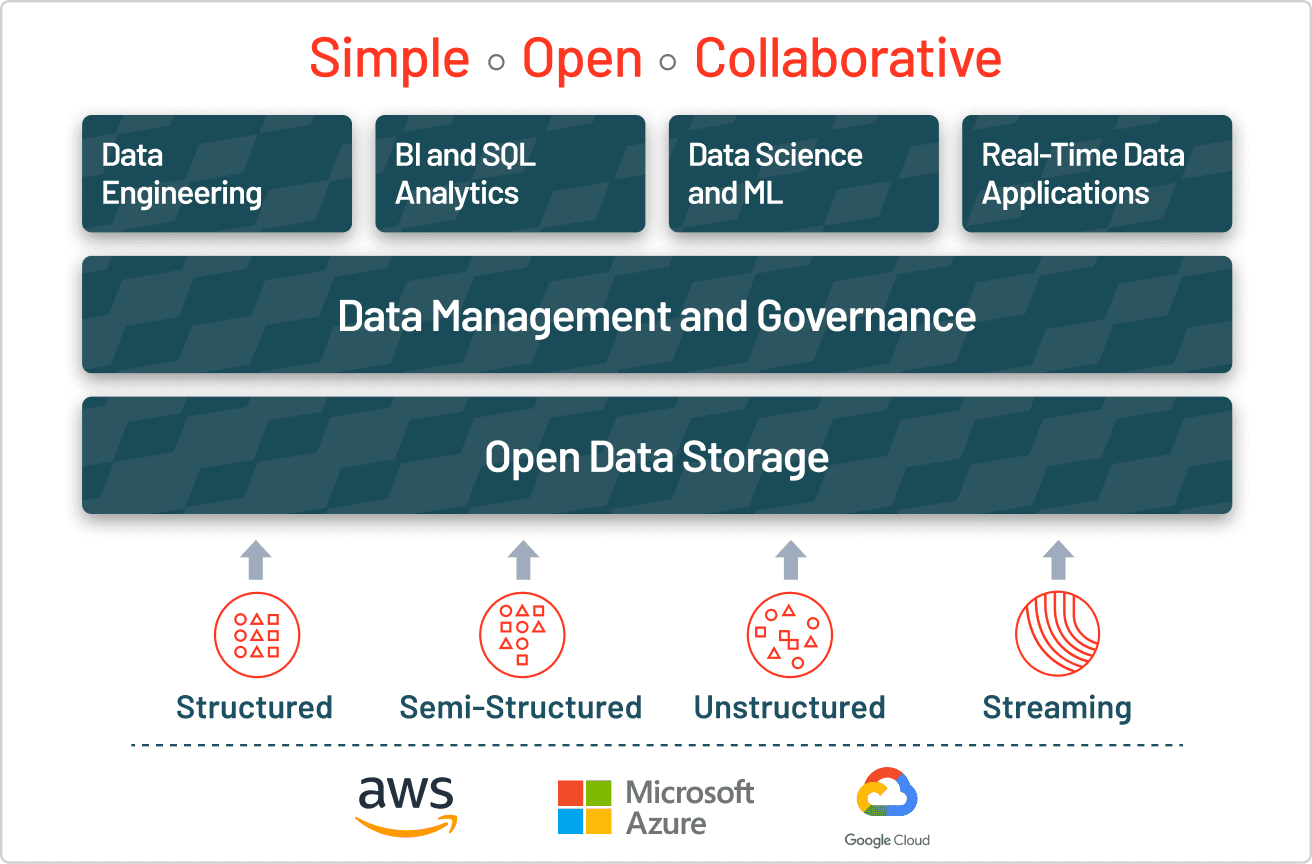
- Empresas modernas precisam de abordagens híbridas que combinem os dois tipos de dados - As arquiteturas de Lakehouse unificam a gestão de dados estruturados e não estruturados, oferecendo a abertura dos data lakes com a confiabilidade dos data warehouses e, ao mesmo tempo, fornecendo governança unificada para todos os tipos de dados.
Dados estruturados e não estruturados são ativos essenciais para as organizações modernas, mas são fundamentalmente diferentes. As organizações devem entender essas diferenças e gerenciar cada tipo de forma eficaz para aproveitar todo o seu valor. Este guia examina as implicações práticas, os casos de uso do mundo real e as considerações estratégicas para escolher o tipo certo de dados. Ele também aborda ferramentas para requisitos de negócios comuns, indo além de comparações genéricas para estruturas de tomada de decisão acionáveis.
Dados estruturados: características e aplicações
Principais características dos dados estruturados
Dados estruturados são informações organizadas em um modelo de dados relacional predefinido, o que significa que os dados são organizados em tabelas com esquemas fixos. Esse modelo especifica a estrutura (linhas e colunas), os tipos de dados e as relações entre as tabelas antes que quaisquer dados sejam armazenados para permitir buscas e análises eficientes. Exemplos comuns de dados estruturados incluem transações financeiras, arquivos do Excel, registros de gerenciamento de relacionamento com o cliente (CRM), níveis de estoque, pedidos de vendas, sistemas de reserva e leituras de sensores.
Dados estruturados são normalmente armazenados em data warehouses. Eles são otimizados para consultas rápidas e confiáveis por meio da Structured Query Language (SQL), usada para cargas de trabalho de dados estruturados.
O formato padronizado também torna os dados estruturados altamente acessíveis. Usuários de negócios podem explorar, analisar e gerar relatórios sobre isso com facilidade, usando ferramentas familiares de business intelligence (BI) e analítica para gerar percepções, sem precisar de conhecimento técnico avançado.
Valor comercial e análise de dados estruturados
Os dados estruturados entregam um valor de negócio significativo porque seu formato consistente e filtrável suporta a análise de dados com pré-processamento mínimo, permitindo que as organizações executem cálculos, criem modelos e comparem tendências com eficiência. Os dados estruturados servem como a espinha dorsal da analítica empresarial, oferecendo consultas rápidas, alta integridade de dados e resultados confiáveis nos quais as organizações podem confiar para o planejamento diário e estratégico. Isso inclui BI tradicional, como relatórios de rotina, previsão, monitoramento de KPI e dashboards interativos que ajudam as organizações a acompanhar o desempenho e a tomar decisões para otimizar as operações.
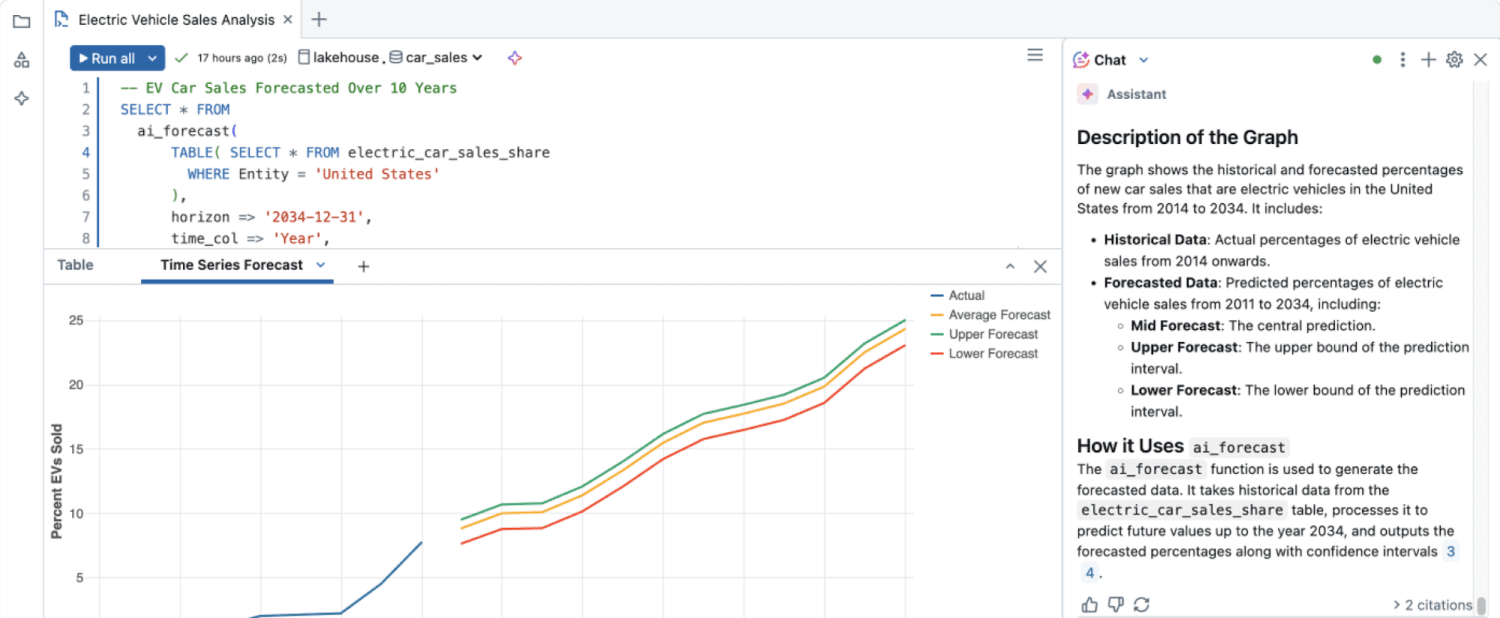
Os dados estruturados também são altamente eficazes para modelos de machine learning (ML) e sistemas automatizados que geram informação avançada, como resumos gerados por IA e avaliação do sentimento do cliente.
Considerações sobre armazenamento e escalabilidade de dados estruturados
Uma grande vantagem dos datasets estruturados é a alta eficiência de armazenamento por meio da compressão colunar. Como os valores na mesma coluna tendem a ser semelhantes, os bancos de dados colunares permitem a compactação e a leitura eficientes de dados, resultando em uma economia significativa de armazenamento e analíticas mais rápidas.
No entanto, alterações de esquema em dados estruturados podem ser desafiadoras. Como os ecossistemas de banco de dados são altamente conectados e têm muitas dependências, alterações como adicionar, modificar ou remover campos podem causar perda de dados, tempo de inatividade de aplicações e falhas em cascata em outras partes do sistema se não forem gerenciadas adequadamente. As organizações devem planejar as migrações cuidadosamente para evitar interrupções.
Dados não estruturados: características, desafios e oportunidades
Características e fontes de dados não estruturados
Dados não estruturados são informações em seu formato nativo. Diferentemente dos dados estruturados, que são organizados em linhas e colunas, os dados não estruturados não têm uma estrutura predefinida, o que torna mais difícil sua pesquisa e análise.
Os dados em sua forma não estruturada podem ser gerados por máquinas, como dados de GPS, arquivos de log e outras informações de telemetria, ou por humanos. Exemplos de dados não estruturados gerados por humanos incluem postagens em redes sociais, arquivos de áudio, arquivos de vídeo, emails, arquivos de multimídia e documentos de texto.
Dados não estruturados representam de 80% a 90% do crescimento dos dados corporativos. Este tipo de dado pode oferecer percepções valiosas em áreas como tendências de mercado, sentimento do cliente e problemas operacionais, mas extrair essas percepções pode ser desafiador em comparação com o trabalho com dados estruturados.
Desafios e soluções da análise de dados não estruturados
As percepções de dados não estruturados permaneceram em grande parte inexploradas até a criação de análises de dados avançadas, como algoritmos de ML, processamento de linguagem natural (NLP) e análise de sentimento, que podem extrair automaticamente significado de grandes volumes de dados não estruturados.
Normalmente, as organizações precisam de cientistas de dados para gerenciar, processar e extrair padrões significativos de dados não estruturados usando técnicas avançadas. Data lakes são comumente usados para consolidar dados não estruturados em seu formato nativo e bruto, oferecendo armazenamento flexível para grandes volumes. Os data lakes permitem que dados brutos sejam transformados em dados estruturados prontos para analítica SQL, ciência de dados e machine learning com baixa latência. Os data lakes também podem reter dados brutos indefinidamente e a baixo custo para uso futuro em ML e analítica.
No entanto, os data lakes podem facilmente degenerar em "pântanos de dados" com problemas de confiabilidade, desempenho e governança. Os data lakes tradicionais por si só não são suficientes para atender às necessidades das empresas que buscam inovar, e é por isso que as empresas geralmente operam em arquiteturas complexas, com dados isolados em diferentes sistemas de armazenamento em toda a empresa.
O armazenamento em Lakehouse unifica o tratamento de dados estruturados e não estruturados para enfrentar os desafios apresentados pelos data lakes. Os lakehouses implementam estruturas semelhantes às de data warehouses e recursos de gerenciamento diretamente no armazenamento de dados de baixo custo de um data lake, combinando a abertura dos data lakes com os recursos de gerenciamento e confiabilidade dos data warehouses. Essa estrutura garante que as empresas possam aproveitar vários tipos de dados para projetos de ciência de dados, ML e analítica de negócios.
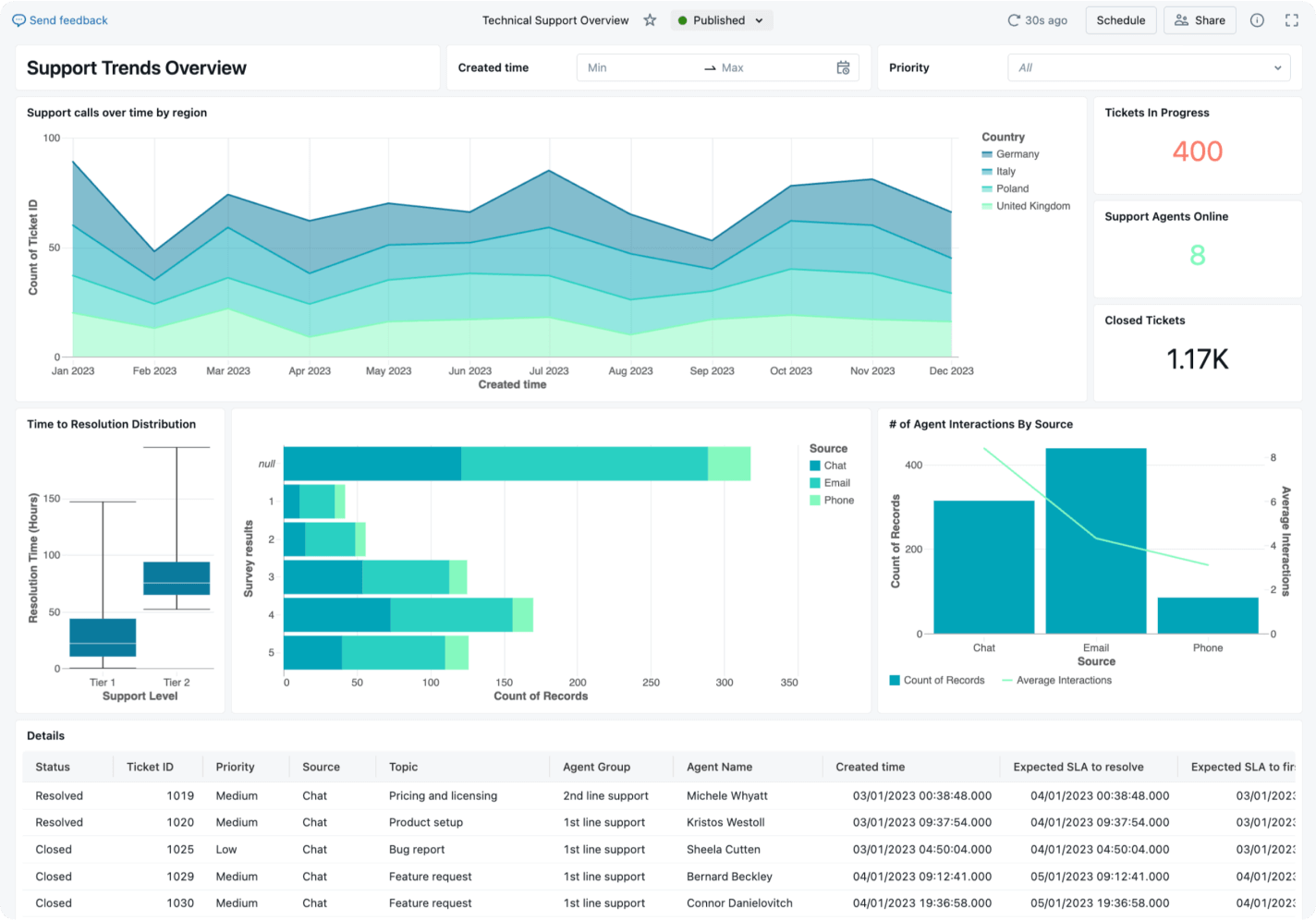
Extraindo valor de negócio de dados não estruturados
Os dados não estruturados contêm informações ricas que as técnicas analíticas tradicionais não conseguem interpretar facilmente. Os recursos de machine learning permitem que o conteúdo não estruturado seja processado em escala, identificando padrões, temas, sentimentos e anomalias que, de outra forma, permaneceriam ocultos. Usando técnicas como NLP e visão computacional, as organizações podem transformar dados qualitativos em percepções acionáveis usadas para embasar decisões.
Por exemplo, para melhorar o atendimento ao cliente, as organizações podem usar IA para analisar diversas fontes, incluindo avaliações de produtos, transcrições de call center, menções em redes sociais e conversas com chatbots. Os padrões identificados podem ser usados para revelar oportunidades de resolver problemas, aumentar a eficiência e estimular a inovação para aprimorar a experiência do cliente.
Principais diferenças entre dados estruturados e não estruturados e estrutura de decisão
Entender as diferenças entre dados estruturados e não estruturados é essencial para projetar arquiteturas de dados eficazes e escolher métodos analíticos apropriados. Cada tipo traz pontos fortes e desafios únicos que devem ser considerados na estratégia de dados de uma organização.
Dimensões críticas de comparação
- Formato de dados: os dados estruturados são organizados em um formato fixo e predefinido. Cada registro usa o mesmo conjunto de campos e tipos de dados para que tudo permaneça consistente. Dados não estruturados são armazenados em sua forma bruta e nativa, sem uma estrutura uniforme, o que os torna mais flexíveis, mas mais difíceis de organizar e analisar.
- Ferramentas de análise: dados estruturados podem ser facilmente consultados com SQL e integrados a ferramentas padrão de Business Intelligence. Os dados não estruturados exigem métodos de analíticas mais avançados, incluindo ML, NLP e visão computacional. Estes são normalmente gerenciados por cientistas de dados ou analistas especializados.
- Armazenamento: dados estruturados se encaixam naturalmente em data warehouses, que são otimizados para consultas relacionais e desempenho. Os dados não estruturados são mais adequados para data lakes, que permitem que as organizações armazenem dados brutos em escala, ou para arquiteturas de lakehouse híbridas.
- Tempo de processamento: como os dados estruturados já estão organizados, eles geralmente podem ser analisados imediatamente com preparação mínima. Dados não estruturados geralmente precisam de um pré-processamento significativo — como limpeza, tokenização, rotulagem e extração de recursos — antes que percepções significativas possam ser geradas.
- Acessibilidade do usuário: dados estruturados são acessíveis a uma ampla gama de usuários, incluindo analistas de negócios e tomadores de decisão, que podem explorá-los por meio de dashboards e ferramentas de relatórios. Dados não estruturados geralmente exigem a especialização de cientistas de dados ou engenheiros para convertê-los em formatos utilizáveis e capturar percepções acionáveis.
Dados semiestruturados e abordagens modernas
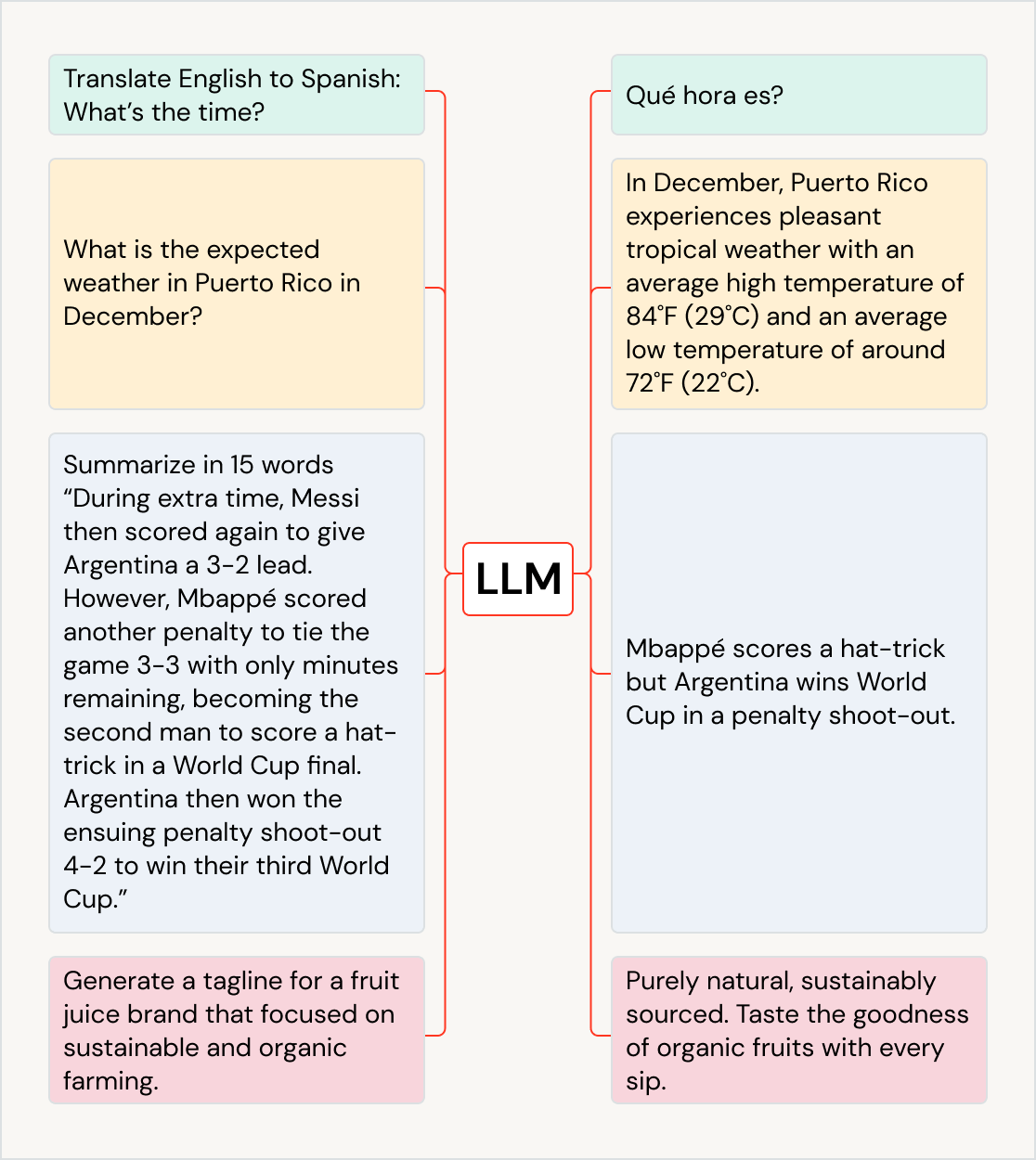
O meio-termo híbrido
Dados estruturados e não estruturados não são os únicos formatos que as organizações precisam gerenciar. Os dados semiestruturados preenchem a lacuna entre os dois, usando tags de metadados para adicionar alguma organização, enquanto ainda permitem campos flexíveis e em evolução. Exemplos comuns incluem arquivos JSON, XML e CSV. As organizações geralmente usam bancos de dados NoSQL e sistemas de arquivos modernos para gerenciar este tipo de dado, porque eles suportam esquemas flexíveis e se adaptam com mais facilidade a mudanças nos formatos de dados.
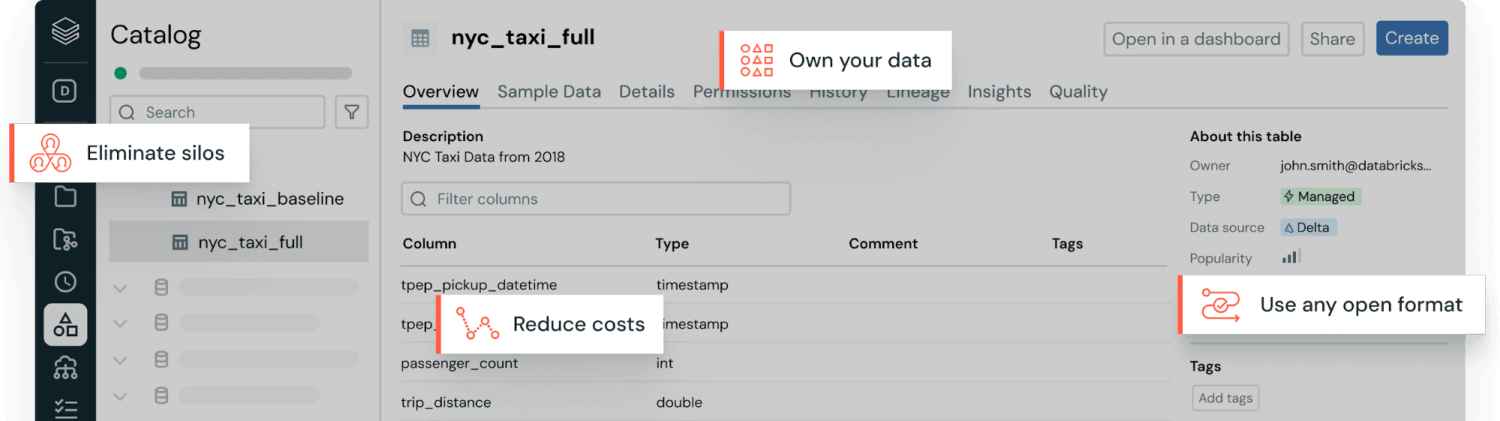
A maioria das empresas precisa de todos os tipos de dados, por isso está adotando estratégias de armazenamento híbrido que combinam os pontos fortes de diferentes abordagens de dados. A arquitetura lakehouse moderna elimina a necessidade de escolher entre data lakes e data warehouses ao combinar seus recursos em uma única plataforma. O Unity Catalog da Databricks oferece governança unificada e aberta para todos os dados estruturados, dados não estruturados, métricas de negócios e modelos de IA em qualquer nuvem. Isso permite que as organizações governem, descubram, monitorem e compartilhem dados, tudo em um só lugar, simplificando a compliance e gerando percepções mais rapidamente.
Conclusão
A estratégia de dados não é uma solução única para todos. Entender a diferença entre dados estruturados, não estruturados e semiestruturados é essencial para construir uma gestão de dados eficaz. As organizações precisam de conhecimento especializado para combinar os tipos de dados com suas necessidades analíticas e requisitos de negócios específicos. Ao alinhar as escolhas de dados com seus casos de uso exclusivos, as empresas podem obter percepções mais profundas, melhorar a tomada de decisões e maximizar o impacto de seus investimentos em dados.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.