Grandes modelos de linguagem
Acelere a inovação usando modelos de linguagem grandes com a Databricks

O que são modelos de linguagem grandes?
Os grandes modelos de linguagem (LLMs) são modelos de machine learning muito eficazes na realização de tarefas relacionadas ao idioma, como tradução, resposta a perguntas, chat e resumo de conteúdo, assim como geração de conteúdo e código. Os LLMs extraem valor de enormes conjuntos de dados e tornam esse “aprendizado” acessível imediatamente. Os bancos de dados simplificam o acesso a esses LLMs para integração em seus fluxos de trabalho, bem como as capacidades da plataforma para ajustar os LLMs usando seus próprios dados para um melhor desempenho do domínio.

Processamento de linguagem natural com LLMs
A S&P Global usa grandes modelos de linguagem na Databricks para entender melhor as principais diferenças e semelhanças nos registros das empresas, ajudando os gerentes de ativos a construir um portfólio mais diversificado.
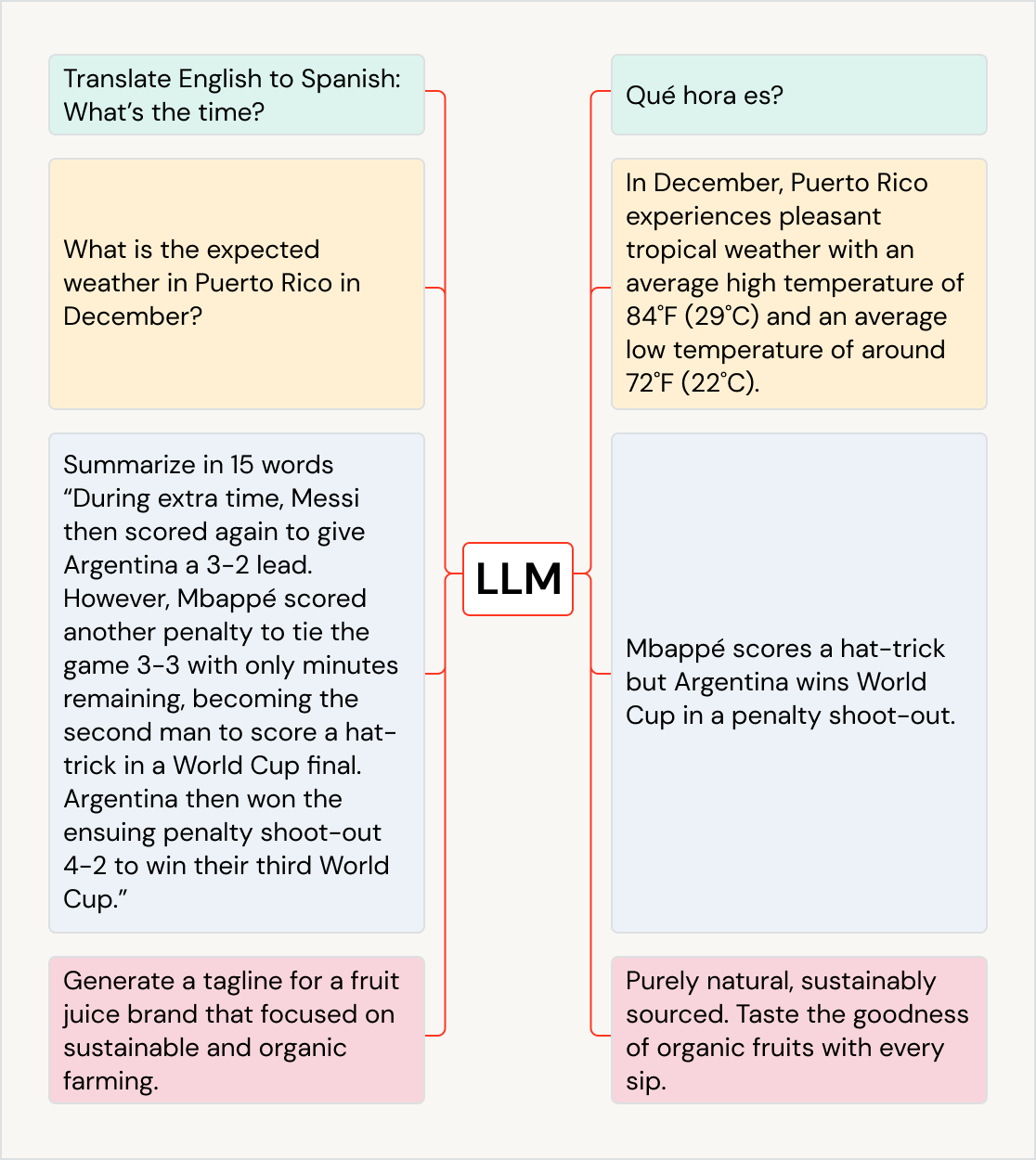
Use LLMs para uma variedade de casos de uso
Os LLMs podem impulsionar o impacto nos negócios em todos os casos de uso e setores — traduzir texto em outros idiomas, melhorar a experiência do cliente com chatbots e assistentes de IA, organizar e classificar o feedback do cliente para os departamentos certos, resumir documentos grandes, como chamadas de ganhos e documentos legais, criar novo conteúdo de marketing e gerar código de software a partir da linguagem natural. Eles podem até ser usados para alimentar outros modelos, como os que geram arte. Alguns LLMs populares são a família de modelos GPT (por exemplo, ChatGPT), BERT, T5 e BLOOM.
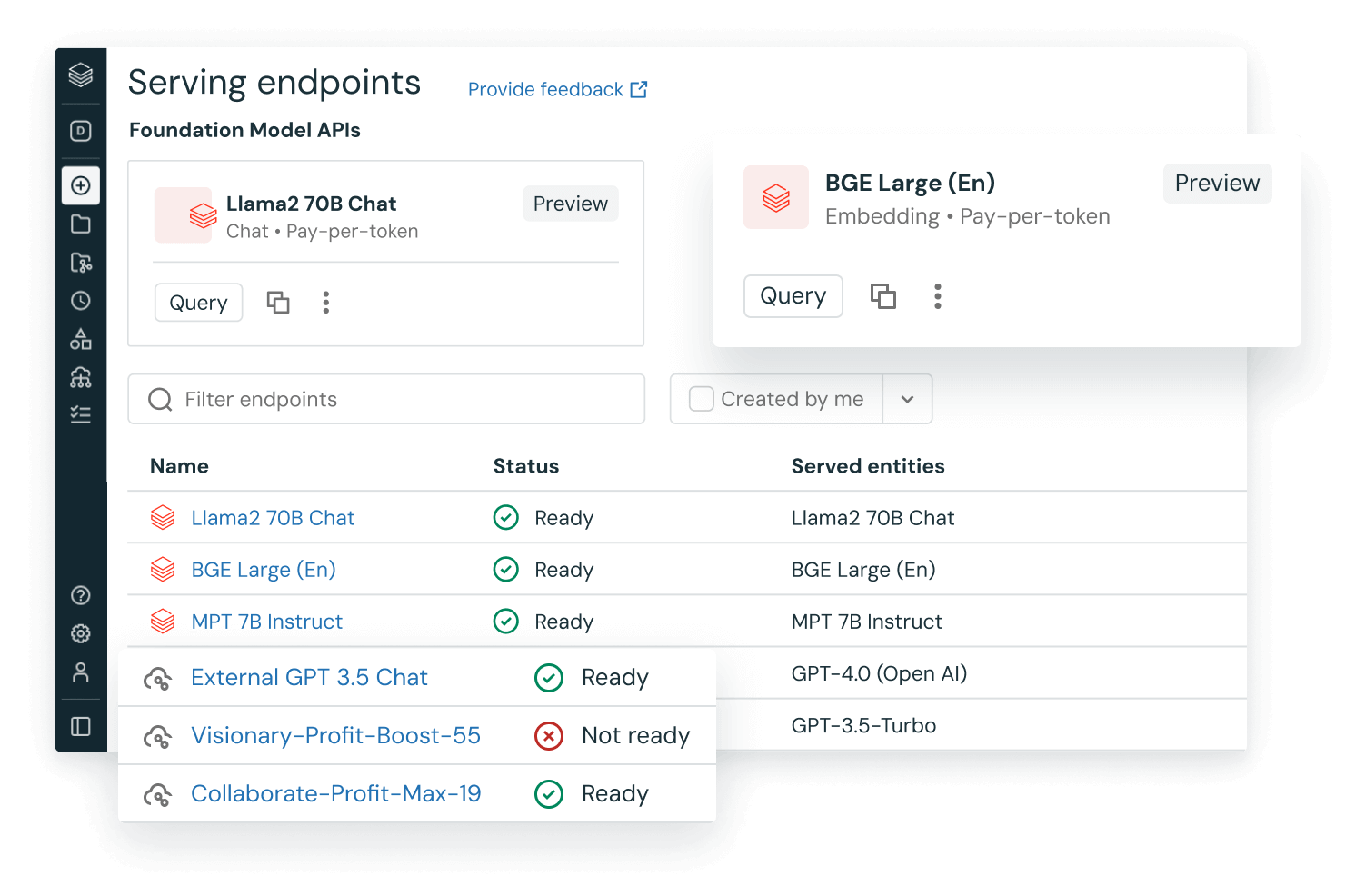
Usando LLMs pré-treinados em seus apps
Integre modelos pré-treinados existentes ao seu fluxo de trabalho, como os da biblioteca de transformadores do Hugging Face ou outras bibliotecas de código aberto. Os pipelines de transformador facilitam o uso de GPUs e permitem o batch de itens enviados para a GPU para melhor throughput.
Com a variante do MLflow para Hugging Face Transformers, você obtém a integração nativa de pipelines, modelos e componentes de processamento do Transformer ao serviço de acompanhamento do MLflow. Você também pode integrar modelos OpenAI ou soluções de parceiros como o John Snow Labs em seus fluxos de trabalho na Databricks.
Com as funções de IA, os analistas de dados do SQL podem acessar facilmente modelos de LLM, inclusive do OpenAI, diretamente em seus pipelines de dados e fluxos de trabalho.
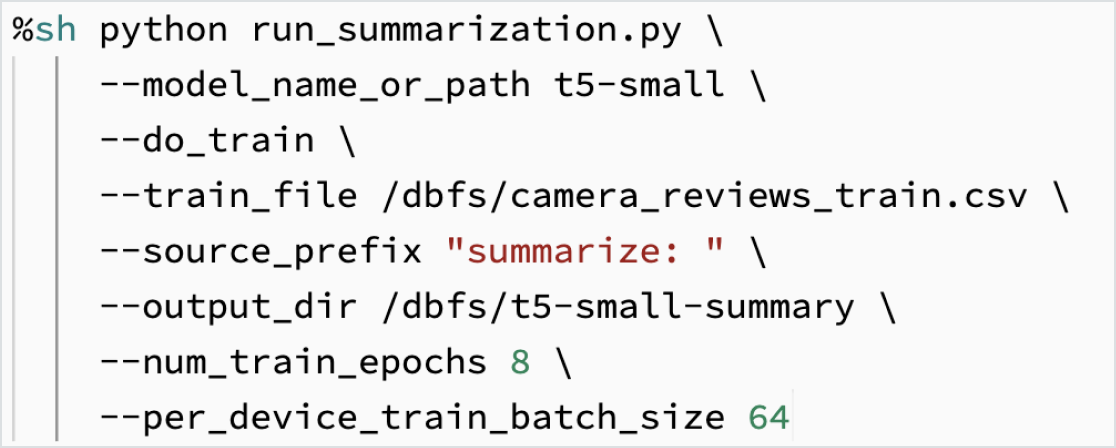
Ajuste de LLMs usando seus dados
Personalize um modelo em seus dados para sua tarefa específica. Com o suporte de ferramentas de código aberto, como Hugging Face e DeepSpeed, você pode pegar uma LLM de fundação com rapidez e eficiência e começar a treinar com seus próprios dados para ter mais precisão para seu domínio e carga de trabalho. Isso também permite controlar os dados usados no treinamento para você ter certeza de que está usando a IA com responsabilidade.

Dolly 2.0 é um grande modelo de linguagem que foi treinado pela Databricks para demonstrar como você pode treinar seu próprio LLM de forma econômica e rápida. O conjunto de dados de alta qualidade gerado por humanos (databricks-dolly-15k) usado para treinar o modelo também tem código aberto. Com o Dolly 2.0, os clientes agora podem possuir, operar e personalizar seu próprio LLM. As empresas podem construir e treinar um LLM com seus próprios dados, sem a necessidade de enviar dados para LLMs proprietários. Para obter o código Dolly 2.0, pesos de modelo ou o conjunto de dados databricks-dolly-15k, visite Hugging Face.
LLMOps integrado (MLOps para LLMs)
Use MLOps integrado e pronto para produção com o Managed MLflow para rastreamento, gerenciamento e implementação de modelos. Assim que o modelo for implementado, você poderá monitorar latência, detalhamento de dados e muito mais, com a capacidade de acionar pipelines de retreinamento — tudo na mesma plataforma unificada Databricks Lakehouse para LLMOps de ponta a ponta.
Dados e modelos em uma plataforma unificada
A maioria dos modelos será treinada mais de uma vez, portanto, ter os dados de treinamento na mesma plataforma de ML se tornará crucial para o desempenho e o custo. O treinamento de LLMs no Lakehouse oferece acesso a ferramentas e computação de primeira linha — dentro de um Lakehouse de dados extremamente econômico — permite continuar a treinar novamente os modelos à medida que seus dados evoluem ao longo do tempo.