As 10 principais perguntas que vocês fizeram sobre os Databricks Clean Rooms, respondidas
Colaboração de dados que prioriza a privacidade, simplificada com os Databricks Clean Rooms
- Trabalhe com parceiros em dados sensíveis sem expor registros brutos.
- Use o Delta Sharing para trazer dados externos, como do Snowflake ou do BigQuery, para uma Clean Room.
- Suporta casos de uso, incluindo resolução de identidade, publicidade, saúde e finanças.
A colaboração de dados é a espinha dorsal da inovação moderna em AI, especialmente quando as organizações colaboram com parceiros externos para desbloquear novas percepções. No entanto, a privacidade de dados e a proteção da propriedade intelectual continuam sendo grandes desafios para viabilizar a colaboração e, ao mesmo tempo, proteger dados confidenciais.
Para preencher essa lacuna, clientes de diversas indústrias estão usando as Databricks Clean Rooms para a execução de análises compartilhadas em dados sensíveis e permitir a colaboração com foco na privacidade.
Compilamos abaixo as 10 perguntas mais frequentes sobre Clean Rooms. Eles abordam o que são as Clean Rooms, como elas protegem dados e IP, como funcionam em diferentes clouds e plataformas e o que é necessário para começar. Vamos começar.
1. O que é uma “data clean room”?
Uma clean room de dados é um ambiente seguro onde você e seus parceiros podem trabalhar juntos em dados confidenciais para extrair percepções úteis, sem o compartilhamento dos dados brutos e confidenciais subjacentes.
No Databricks, você cria uma clean room, adiciona os ativos que deseja usar e realiza a execução apenas dos Notebooks aprovados em um ambiente isolado, seguro e governado.

2. Quais são alguns exemplos de casos de uso de Clean Rooms?
Os clean rooms são úteis quando várias partes precisam analisar dados confidenciais sem o compartilhamento de seus dados brutos. Isso geralmente ocorre devido a regulamentações de privacidade, contratos ou à proteção da propriedade intelectual.
Eles são usados em muitas indústrias, incluindo publicidade, saúde, finanças, governo, transporte e monetização de dados.
Alguns exemplos incluem:
Publicidade e marketing: Resolução de identidade sem expor PII, planejamento e mensuração de campanhas, monetização de dados para mídia de varejo e colaboração entre marcas.
- Parceiros como Epsilon, The Trade Desk, Acxiom, LiveRamp e Deloitte utilizam os clean rooms do Databricks para resolução de identidade.
Serviços financeiros: bancos, seguradoras e operadoras de cartão de crédito combinam dados para otimizar operações, detectar fraudes e realizar análises.
- Exemplos: a Mastercard usa Clean Rooms para corresponder e analisar dados PII para detecção de fraudes; a Intuit faz a correspondência segura dos dados de mutuários com os de credores para encontrar mutuários qualificados.
As salas limpas protegem os dados do cliente e, ao mesmo tempo, permitem a colaboração e o enriquecimento de dados.
3. Que tipos de ativos de dados posso compartilhar em uma clean room?
Você pode compartilhar uma ampla variedade de ativos gerenciados pelo Unity Catalog nos Databricks Clean Rooms:
- Tabelas (gerenciadas, externas e estrangeiras): dados estruturados como transações, eventos ou perfis de clientes.
- view: fatias filtradas ou agregadas das suas tabelas.
- Volumes: arquivos como imagens, áudio, documentos ou bibliotecas de código privadas.
- Notebooks: Notebooks SQL ou Python que definem a análise que você quer executar.
Veja como funciona na prática:
- Um varejista, uma marca de CPG e uma empresa de pesquisa de mercado compartilham views anonimizadas, incluindo: IDs de clientes com hash, métricas de ventas agregadas e dados demográficos regionais para analisar em conjunto o alcance da campanha.
- Uma plataforma de transmissão e uma agência de publicidade compartilham tabelas de impressão de campanha e um notebook que compute métricas de público multiplataforma.
- Um banco e um parceiro de fintech compartilham volumes com modelos de ML de risco e fraude e usam um Notebooks para pontuar os modelos em conjunto, mantendo a privacidade dos registros individuais.
4. Qual a comparação disso com o Delta Sharing? Por que eu usaria uma clean room em vez disso?
Pense da seguinte forma: o Delta Sharing é a escolha certa quando uma das partes precisa de acesso somente leitura aos dados em seu próprio ambiente e não há problema que ela veja os registros subjacentes.
Os Clean Rooms adicionam um espaço seguro e controlado para análise multipartidária quando os dados precisam permanecer privados. Os parceiros podem join ativos de dados, executar código mutuamente aprovado e retornar apenas os resultados com os quais todas as partes concordam. Isso é útil quando você precisa cumprir garantias de privacidade rigorosas ou dar suporte a fluxos de trabalho regulamentados. Na verdade, os dados compartilhados nos Clean Rooms ainda usam o protocolo Delta Sharing nos bastidores.
Por exemplo, um varejista pode usar o Delta Sharing para dar a um fornecedor acesso somente leitura a uma tabela de ventas, para que ele possa ver o desempenho de ventas dos produtos. Essa mesma dupla usaria um Clean Room quando precisasse join dados mais detalhados e confidenciais de ambos os lados (como características do cliente ou inventário detalhado), realizar a execução de Notebooks aprovados e compartilhar apenas os resultados agregados, como previsões de demanda ou os principais itens em risco.
5. Como os dados confidenciais e a PI são protegidos no Clean Room?
Os Clean Rooms são criados para que seus parceiros nunca vejam seus dados brutos ou sua PI. Seus dados permanecem em seu próprio Unity Catalog, e você compartilha apenas ativos específicos no Clean Room pelo Delta Sharing, que é controlado por Notebooks aprovados.
Para aplicar estas proteções em uma clean room:
- Os colaboradores só veem esquemas (nomes e tipos de colunas), e não os dados reais no nível da linha.
- Apenas Notebooks que você e seus parceiros aprovam podem ter execução em serverless compute em um ambiente isolado.
- Os Notebooks gravam em tabelas de saída temporárias, para que você controle exatamente o que sai da clean room.
- O tráfego de rede de saída é restrito por meio de controles de saída serverless (SEG).
- Para proteger a PI ou o código proprietário, você pode empacotar sua lógica como uma biblioteca privada, armazená-la em um volume do Unity Catalog e referenciá-la em Notebooks do clean room sem revelar seu código-fonte.
6. Colaboradores em clouds diferentes podem join a mesma clean room?
Sim. Os Clean Rooms são projetados para colaboração multicloud e entre regiões, desde que cada participante tenha um workspace com o Unity Catalog ativado e o Delta Sharing ativado em seu metastore. Isso significa que uma organização que usa o Databricks no Azure pode colaborar em uma clean room com parceiros na AWS ou no GCP.
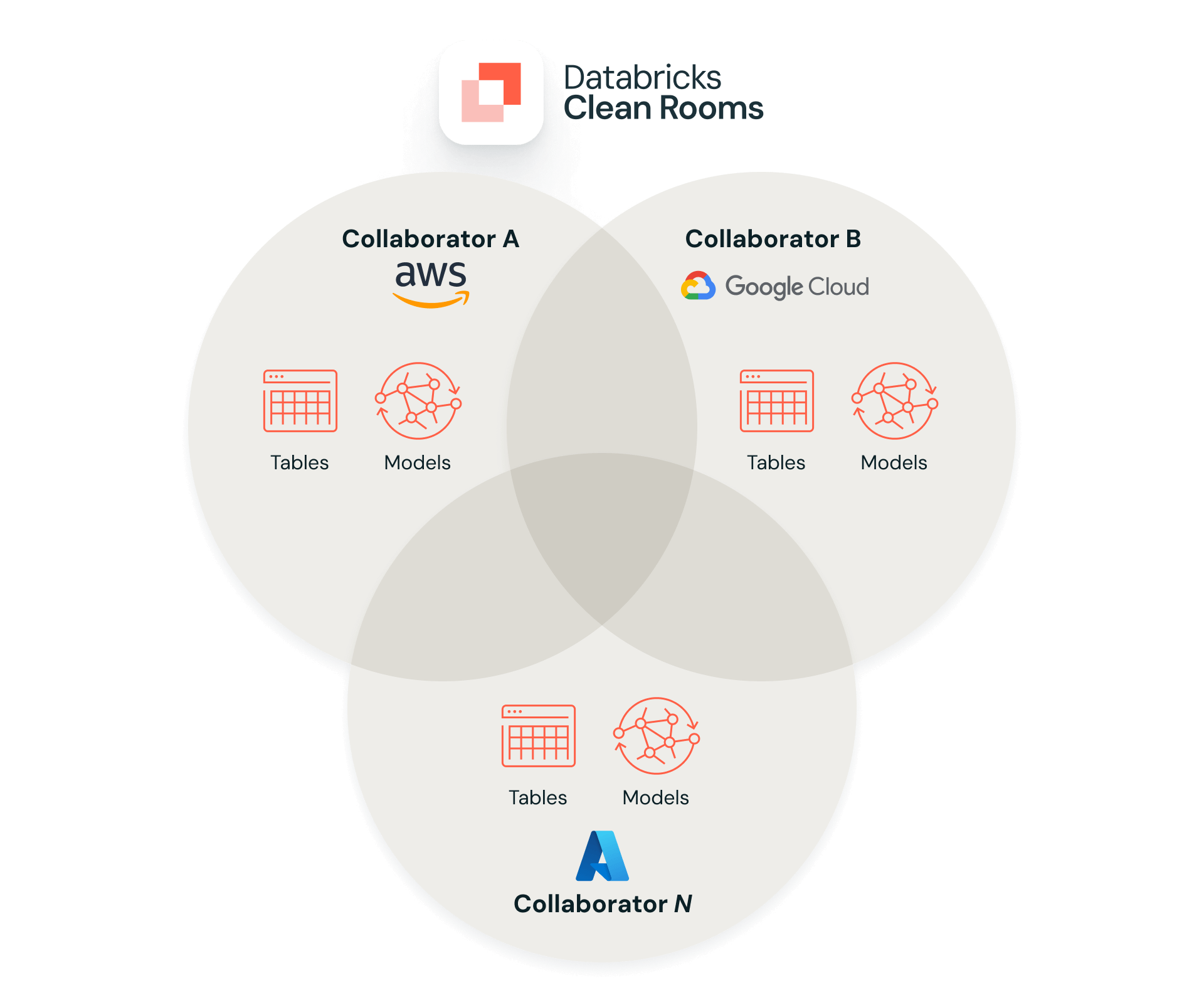
7. Posso trazer dados do Snowflake, do BigQuery ou de outras plataformas para um Clean Room?
Sim, com certeza. Lakehouse Federation expõe sistemas externos como Snowflake, BigQuery e warehouses tradicionais como catálogos estrangeiros no Unity Catalog (UC). Assim que as tabelas externas estiverem disponíveis no UC, você as compartilha na clean room da mesma forma que compartilha qualquer outra tabela ou view.
Veja como funciona em um nível geral: você usa o Lakehouse Federation para criar conexões e catálogos externos que expõem fontes de dados externas no Unity Catalog, sem precisar copiar todos esses dados para o Databricks. Quando essas tabelas externas estiverem disponíveis no Unity Catalog, você pode compartilhá-las em um Clean Room, assim como qualquer outra tabela ou view gerenciada pelo Unity Catalog.
8. Como faço a execução de uma análise personalizada em dados conjuntos?
Dentro de uma clean room, você faz quase tudo por meio de notebooks. Você adiciona um Notebook SQL ou Python que inclui o código para a análise que você deseja, seus parceiros revisam e aprovam o Notebook e, então, pode ser feita a execução.

Um caso simples: você pode ter um notebook SQL que conta IDs com hash sobrepostos entre as compras de um varejista e as impressões de um parceiro de mídia e, depois, gera o alcance, a frequência e a conversão.
Mais avançado: você usa um Notebooks Python para fazer join recursos de ambos os lados, ensinar ou pontuar um modelo nos dados combinados e gravar as previsões em uma tabela de saída. O executor aprovado vê os resultados, mas ninguém vê os registros brutos da outra parte.
9. Como funciona a colaboração multipartidária?
Em um Databricks Clean Room, você pode ter até 10 organizações (você e mais 9 parceiros) trabalhando juntas em um único ambiente seguro, mesmo que estejam em clouds ou plataformas de dados diferentes. Cada equipe mantém seus dados em seu próprio Unity Catalog e compartilha apenas as tabelas, view ou arquivos específicos que desejam usar no clean room.
Depois que todos entram, cada parte pode propor Notebooks em SQL ou Python, e esses Notebooks precisam de aprovação antes da execução, para que todas as partes fiquem confortáveis com a lógica.
10. Certo, tudo isso parece ótimo. Como começar?
Aqui está uma maneira simples de começar:
- Verifique se seu workspace tem o Unity Catalog, o Delta Sharing e o serverless compute habilitados.
- Crie um objeto Clean Room no seu metastore do Unity Catalog e convide seus parceiros com seus identificadores de compartilhamento.
- Cada parte adiciona os ativos de dados e notebooks com que deseja colaborar.
- Depois que todos aprovarem os Notebooks, realize a execução da sua análise e revise os resultados em seu próprio metastore.
Assista a este vídeo para saber mais sobre a criação de Clean Rooms e como começar.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.