Do conhecimento tribal a respostas instantâneas: construindo o Reffy no Databricks
- Por que encontrar a referência de cliente certa no momento certo era um desafio persistente nas equipes de ventas e marketing da Databricks.
- Como criamos o Reffy — um aplicativo agêntico full-stack usando RAG, AI Search, AI Functions e Lakebase — para tornar mais de 2.400 histórias de clientes instantaneamente pesquisáveis.
- Desde seu lançamento em dezembro de 2025, mais de 1.800 funcionários da Databricks executaram mais de 7.500 consultas no Reffy.
Encontrar a história de cliente certa no momento certo é surpreendentemente mais difícil do que deveria ser. Para melhorar a produtividade dos funcionários, criamos o Reffy, um aplicativo que permite aos usuários descobrir e analisar mais de 2.400 referências de clientes da Databricks, fornecendo respostas personalizadas, análise cruzada de histórias, citações e muito mais. Nos seus primeiros dois meses, mais de 1.800 pessoas das equipes de ventas e marketing da Databricks executaram mais de 7.500 queries no Reffy. Isso se traduz em um storytelling mais relevante e consistente, execução mais rápida de campanhas e a confiança de que as provas de clientes são usadas em escala. Ao tornar essas histórias fáceis de encontrar e de assimilar, resolvemos o problema do conhecimento tribal em torno das referências de clientes e liberamos o trabalho valioso de tantas pessoas que as coletaram ao longo dos anos.
Neste artigo, abordaremos a motivação por trás do Reffy, a solução completa da Databricks, seu impacto em nossa organização e como planejamos escalar ainda mais internamente.
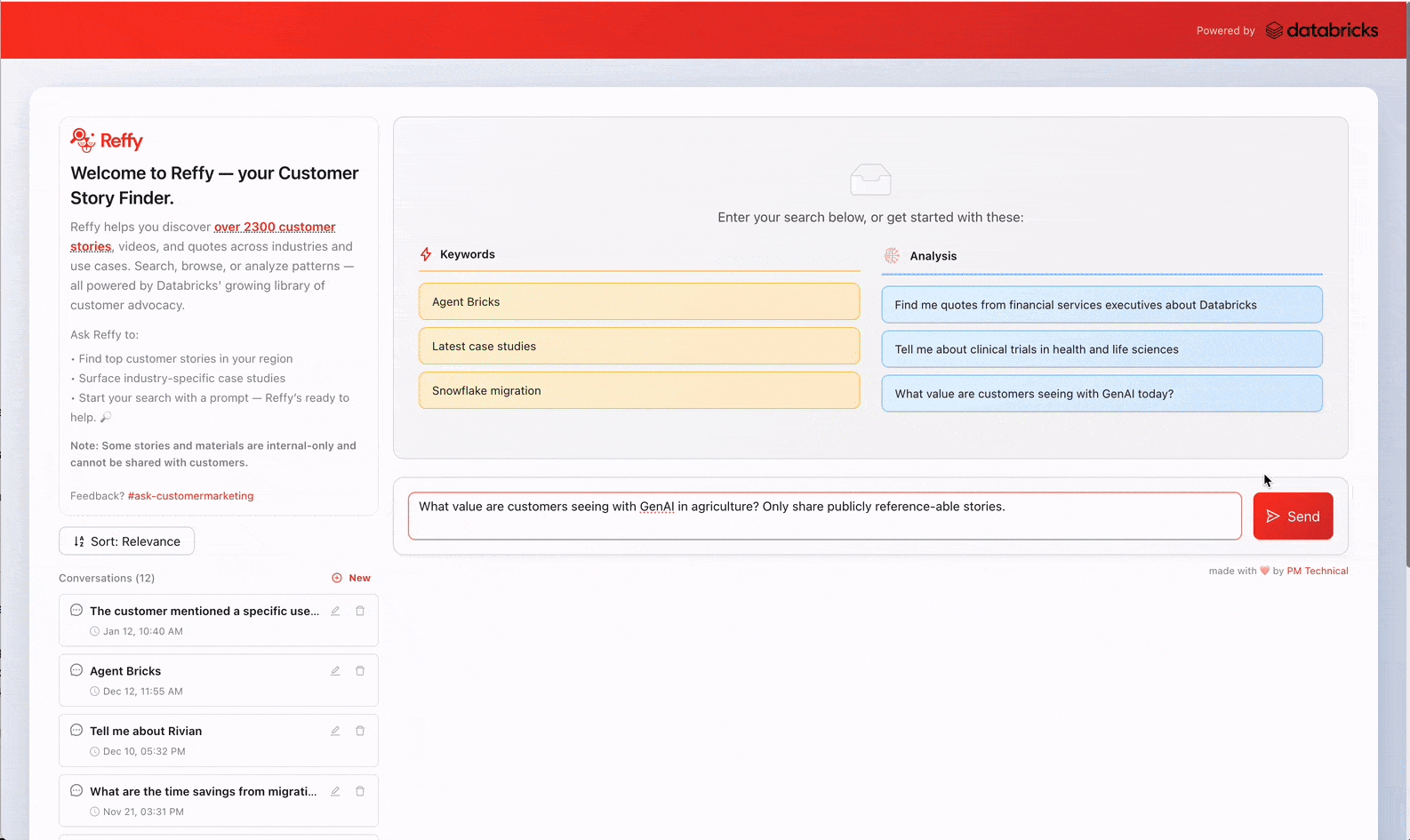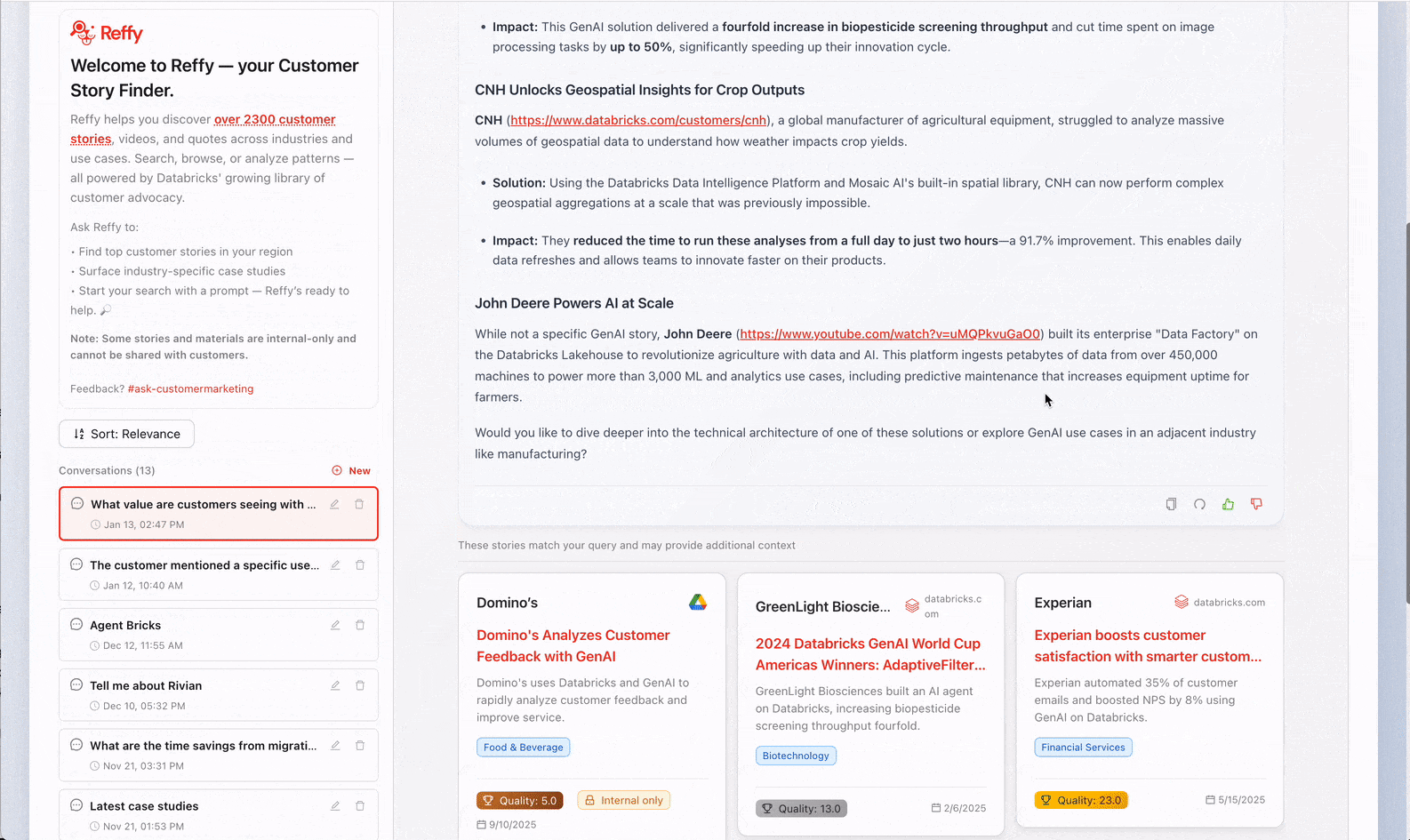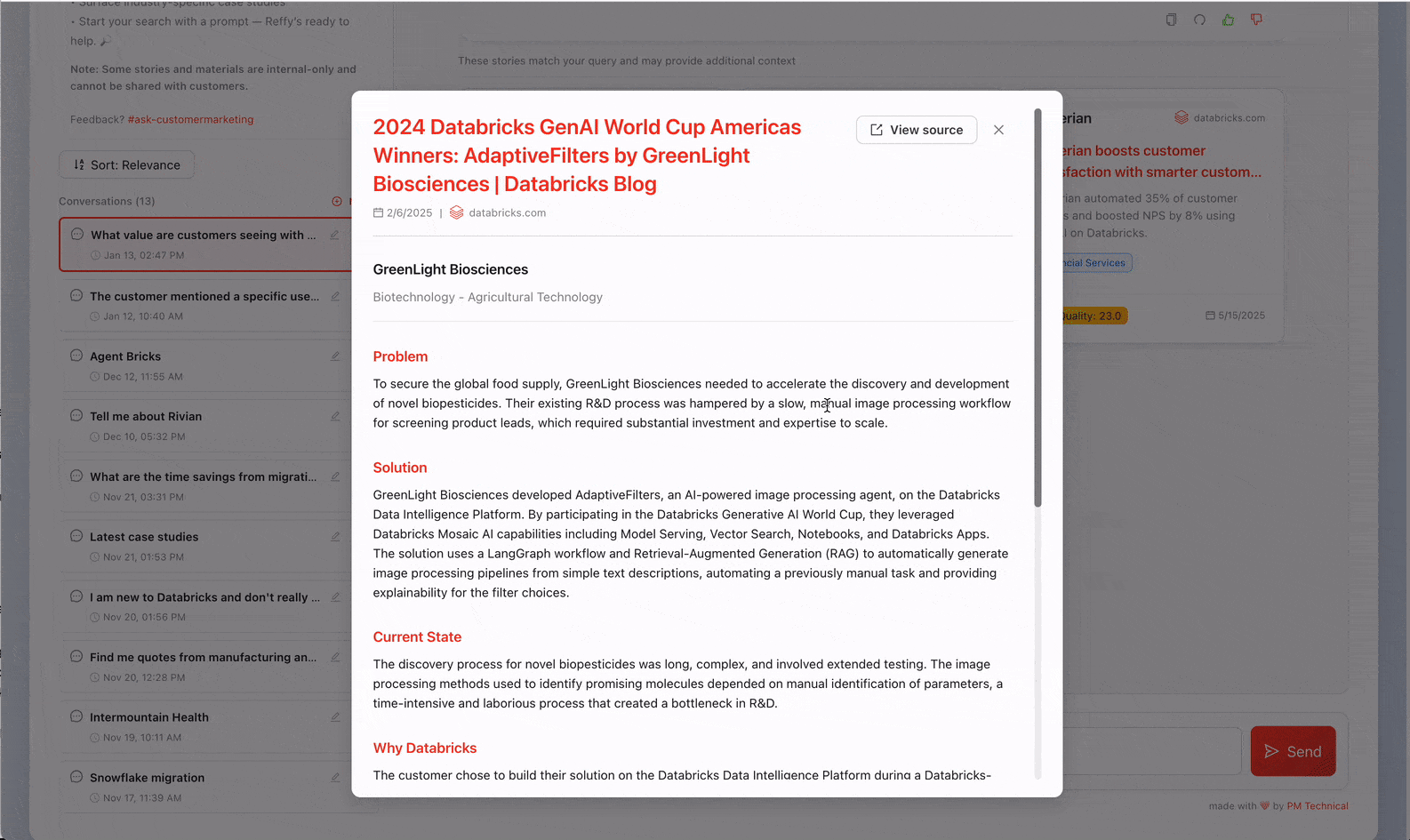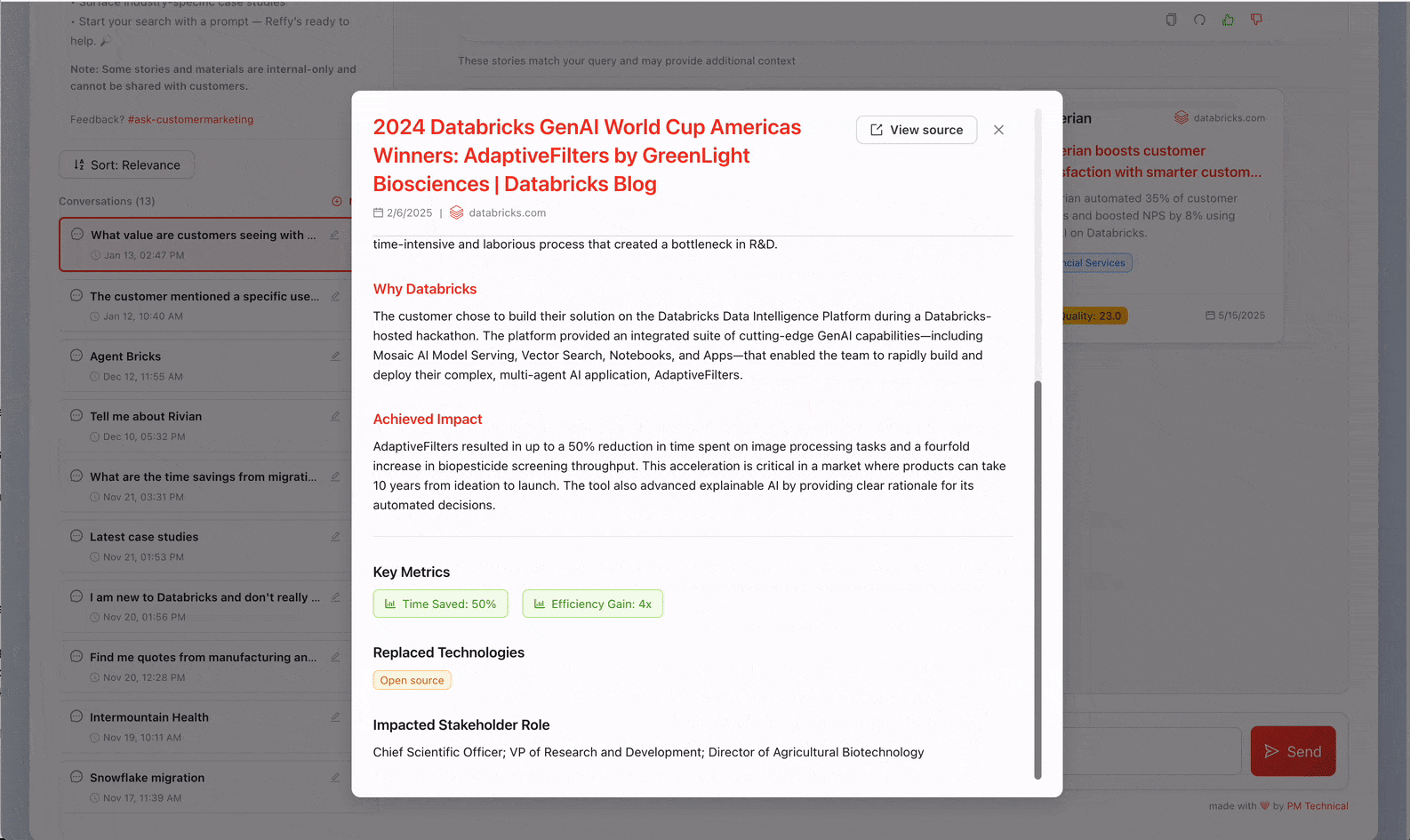
O desafio de democratizar o conhecimento tribal
"Quem mais já fez isso?" é uma pergunta que todo vendedor ouve. Um cliente em potencial fica intrigado com sua apresentação, mas antes de prosseguir, ele quer uma prova: um cliente como ele que já percorreu esse caminho. Deveria ser fácil de responder.
Para nossa equipe de marketing, as histórias de clientes são um insumo essencial para quase todas as ações — campanhas, lançamentos de produtos, publicidade, RP, briefings de analistas e comunicações executivas. Quando essas histórias não são fáceis de encontrar ou avaliar, problemas reais se agravam: referências de alto valor são usadas em excesso, casos de uso ou indústrias mais novas são perdidos e a eficácia do marketing fica limitada pelo conhecimento tribal.
A Databricks tem milhares de palestras no YouTube, estudos de caso no databricks.com, slides internos, artigos do LinkedIn, postagens do Medium. Em algum lugar está a referência perfeita: uma empresa de serviços financeiros no Canadá que faz detecção de fraudes em tempo real, um varejista que substituiu um data warehouse legado, um fabricante escalando GenAI. Mas encontrá-la? É aí que as coisas desandam. As histórias estão espalhadas por uma dúzia de plataformas sem uma busca unificada e, quando você encontra algo, não consegue dizer imediatamente se é forte: tem resultados de negócios críveis ou apenas alegações vagas?
Então, as pessoas fazem o que as pessoas fazem: mandam mensagem para a equipe de marketing no Slack, vasculham pastas de que mal se lembram ou perguntam por aí até que alguém encontre algo útil. Às vezes, eles encontram ouro. Na maioria das vezes, eles se contentam com o "bom o suficiente" ou desistem completamente — sem nunca saber se a história perfeita esteve sempre lá.
Claramente, precisávamos de uma maneira melhor para que vendas e marketing descobrissem as histórias de clientes mais relevantes.
Reffy: uma solução full-stack na Databricks
Para resolver esse problema, consolidamos todas as histórias em uma única tabela, as categorizamos e, em seguida, usamos um agente baseado em RAG para potencializar a pesquisa — tudo apresentado por meio de um aplicativo Databricks com um design personalizado. A arquitetura abrange toda a plataforma Databricks: os Lakeflow Jobs orquestram nossos pipelines de ETL, o Unity Catalog governa nossos dados, o AI Search potencializa a recuperação, o Model Serving hospeda nosso agente, o Lakebase lida com leituras e gravações em tempo real e o Databricks Apps entrega o frontend. Vamos nos aprofundar nos detalhes.
Fontes de dados & ETL
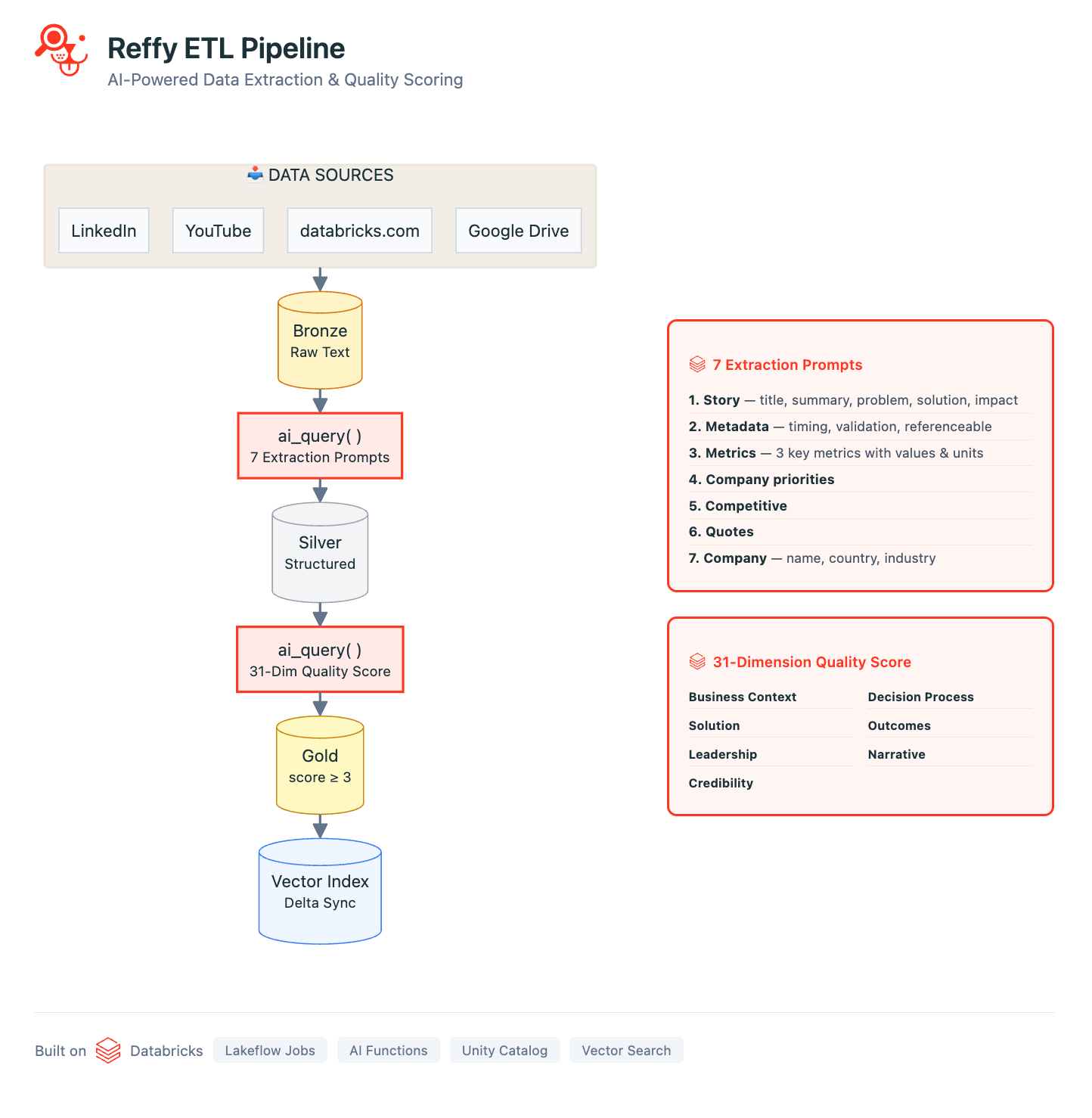
Nosso pipeline é definido em uma série de Databricks Notebooks orquestrados com Lakeflow Jobs. O pipeline começa coletando o texto das histórias de todas as nossas fontes de dados: usamos bibliotecas padrão de webscraping em Python para coletar transcrições do YouTube, artigos do LinkedIn/Medium e todas as histórias de clientes públicas em databricks.com. Usando scripts do Google Apps, também consolidamos o texto de centenas de slides e documentos internos do Google em uma única Planilha Google (Google Sheet). Todas essas fontes são processadas com metadados básicos e salvas em uma tabela 'Bronze' do Delta Lake no Unity Catalog (UC).
Agora temos todas as nossas histórias em um só lugar, mas ainda não temos nenhuma percepção sobre sua qualidade. Para remediar isso, classificamos o texto aplicando um rigoroso sistema de pontuação de 31 pontos (desenvolvido por nossa equipe de Valor) a cada história por meio de AI Functions. Instruímos o Gemini 2.5 para avaliar a qualidade geral da história, identificando o desafio de negócio, a solução, a credibilidade do resultado e por que a Databricks estava em uma posição única para entregar valor. Avaliar histórias dessa forma também nos permite filtrar as de menor qualidade do Reffy. O prompt também extrai metadados importantes como país e setor, produtos usados, concorrência e citações — e classifica as histórias com base em se são compartilháveis publicamente ou apenas para uso interno. Este conjunto de dados enriquecido é salvo em uma tabela 'Silver' no UC.
Os passos finais do ETL incluem a filtragem de histórias de baixa pontuação e a criação de uma nova coluna 'summary' que concatena os componentes essenciais da história. A ideia é simples: sincronizamos esta tabela 'ouro' com um índice do Databricks AI Search, com a coluna de resumo contendo todas as informações essenciais de que um LLM precisaria para corresponder as histórias dos clientes às queries.
IA agêntica
Usando o framework DSPy, definimos um agente de chamada de ferramenta que pode buscar as referências de clientes mais relevantes com pesquisa híbrida de palavras-chave e semântica. Nós adoramos o DSPy! Os agentes criados com ele são fáceis de testar iterativamente em um notebook Databricks sem precisar reimplantar em um endpoint de Model Serving a cada vez, resultando em um ciclo de desenvolvimento mais rápido. A sintaxe é altamente intuitiva em comparação com outros frameworks populares e inclui excelentes componentes de otimização de prompt. Se você ainda não conhece, com certeza vale a pena conferir o DSPy.
Estruturamos nosso agente de histórias de clientes para facilitar uma pesquisa puramente por palavras-chave ultrarrápida e uma resposta mais longa do LLM com raciocínio, dependendo da entrada do usuário: se você fizer uma pergunta, receberá uma resposta cuidadosamente elaborada com fontes, mas se apenas inserir algumas palavras-chave, o Reffy retornará os melhores resultados em menos de dois segundos. Também usamos o reclassificador (re-ranker) da Databricks para o AI Search para melhorar os resultados do RAG.
Para garantir uma resposta equilibrada e profissional, usamos o seguinte prompt de sistema:
O agente é registrado no MLflow e implantado no Databricks Model Serving usando nosso Agent Framework. Como a maior parte do processamento é feita no lado do provedor do modelo, podemos implantar em uma instância pequena de CPU, economizando em custos de infraestrutura em comparação com GPUs.
O aplicativo da Databricks
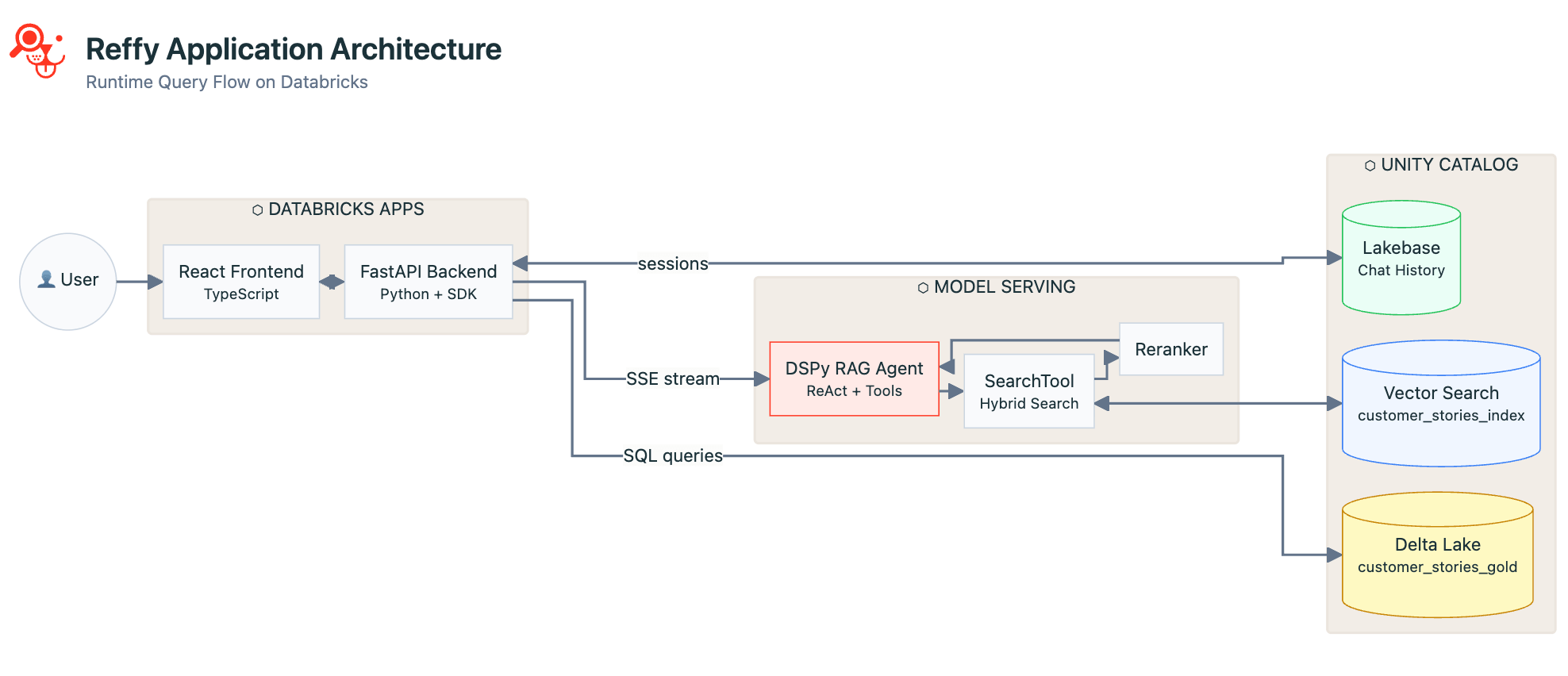
Agora que limpamos e indexamos os dados e o agente está funcionando bem, é hora de criar um aplicativo para unir tudo e torná-lo acessível a usuários não técnicos. Escolhemos um frontend em React com um backend em Python FastAPI. O React é bonito e rápido no navegador e suporta saída de transmissão do nosso endpoint de Model Serving. O FastAPI nos permite aproveitar todos os benefícios do SDK do Databricks Python em nosso aplicativo, a saber:
- Autenticação unificada — sem alterações de código ao autenticar localmente durante o desenvolvimento em comparação com a implantação em Databricks Apps. Os aplicativos têm as mesmas variáveis de ambiente da autenticação local, então o código funciona perfeitamente.
- Ampla cobertura de API — podemos chamar o Model Serving, executar consultas SQL ou qualquer outra coisa que precisarmos de um Databricks Workspace, tudo por meio de um único SDK.
O Reffy é principalmente um aplicativo de chat, por isso usamos o Lakebase para persistir todo o histórico de conversas, logs e identidades de usuários para leituras e escritas rápidas, garantia de qualidade e um acompanhamento atencioso quando os usuários retornam ou iniciam novas conversas.
Monitoramento e métricas contínuos
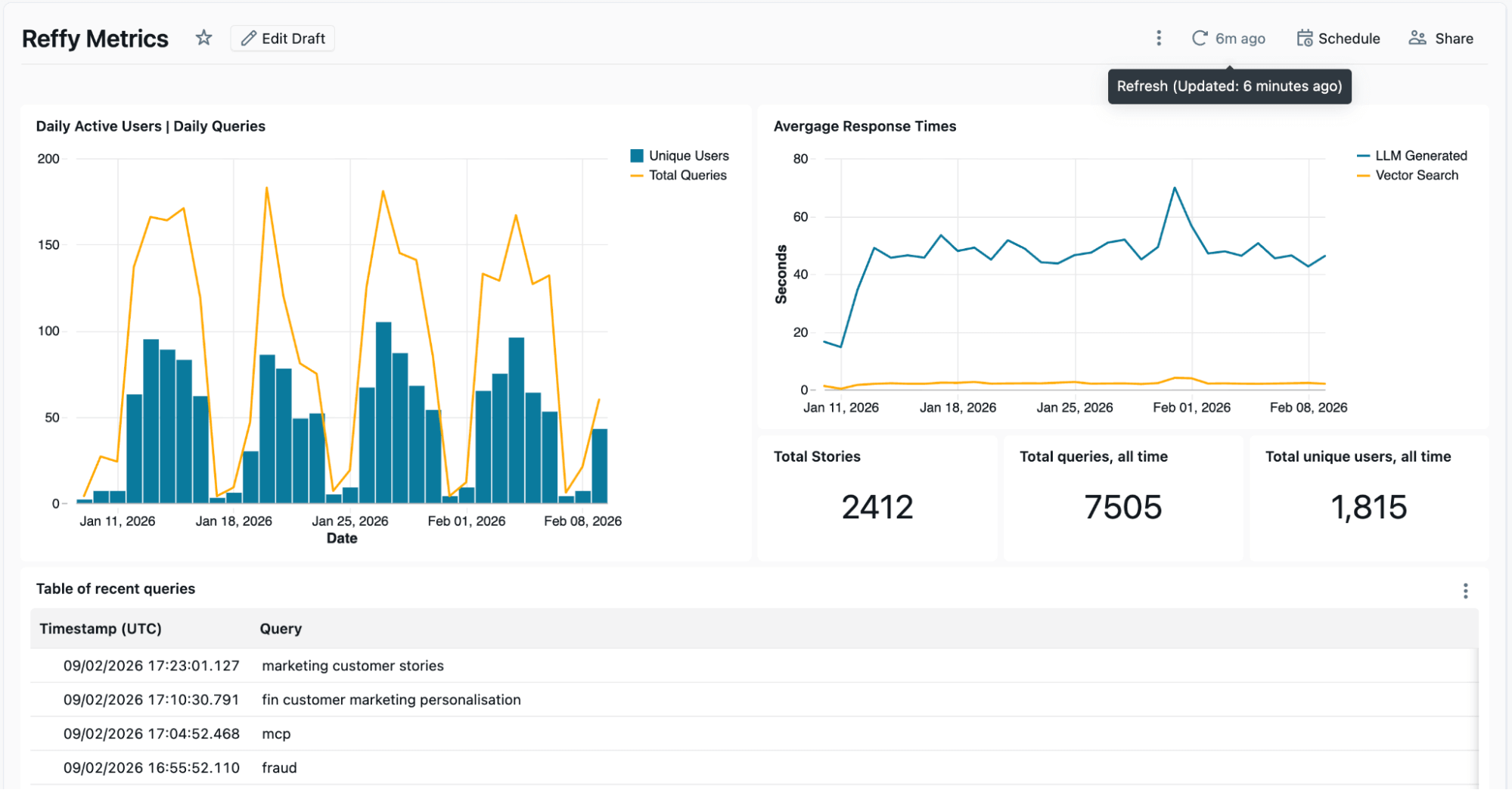
Os logs do Lakebase são processados em um Job do Lakeflow separado para exibir métricas importantes, como usuários ativos diários e tempos médios de resposta, em um Dashboard de AI/BI. Este dashboard também nos mostra entradas e respostas recentes, e damos um passo adiante para aplicar outra AI Function para resumir as entradas e respostas em temas recentes e análise de lacunas. Queremos entender quais histórias de clientes são populares e onde podemos ter lacunas, e os logs que coletamos do Reffy nos ajudam a fazer exatamente isso. Por exemplo, descobrimos que os usuários estavam especialmente ansiosos para encontrar histórias sobre o Agent Bricks e o Lakebase, dois dos mais novos produtos da Databricks.
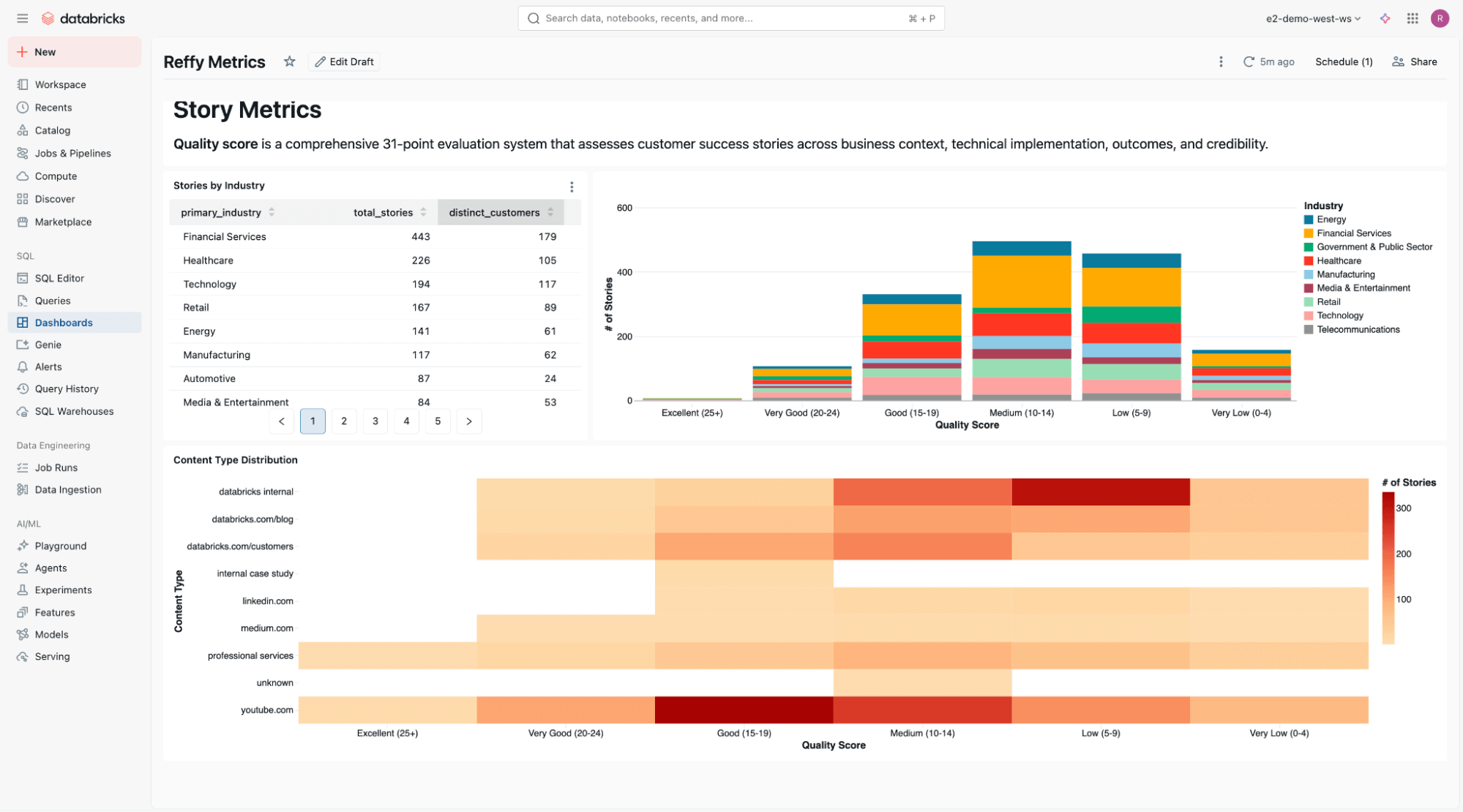
Na parte inferior do dashboard, incluímos uma análise estática da qualidade das histórias em diferentes indústrias e tipos de conteúdo.
Uma observação sobre a configuração de desenvolvimento
A maior parte do desenvolvimento do projeto acontece no Cursor, e, como mencionado anteriormente, a autenticação unificada entre a CLI da Databricks e o SDK simplifica as coisas. Nós fazemos login uma vez pela CLI, e todos os nossos builds locais do Reffy que usam o SDK são autenticados. Quando queremos testar no Databricks Apps, usamos a CLI para sincronizar o código mais recente com nosso Workspace e, em seguida, implantar o aplicativo. O Databricks Apps verifica as mesmas variáveis de ambiente para autenticação que definimos localmente, então nossas chamadas para o Model Serving e SQL Warehouses que dependem do SDK simplesmente funcionam! Nosso ciclo de desenvolvimento iterativo (devloop) se torna:
- Faça login no Workspace via CLI
- Criar código no Cursor
- Testar localmente
- Sincronize o código com o Workspace e implante o aplicativo
- Teste no Databricks Apps
Finalmente, para garantir CI/CD e portabilidade adequados, usamos os Databricks Ativo Bundles para agrupar todo o código e os recursos usados pelo Reffy em um único pacote. Este pacote é então implantado via GitHub Actions em nosso Workspace de produção de destino.
O que aprendemos
Várias equipes no Databricks já haviam resolvido partes desse problema de forma independente, gravitando naturalmente em direção ao trabalho mais empolgante: a camada de IA. No entanto, a engenharia de dados ainda está no centro & acertar o ETL, avaliar a qualidade das histórias e estruturar os dados para uma recuperação eficaz provou ser tão crítico quanto o próprio agente.
A colaboração foi igualmente essencial. As histórias de clientes envolvem quase todos os cantos da organiza�ção: Vendas, Marketing, Engenharia de Campo e RP, todos desempenham um papel. Construir parcerias fortes com esses grupos moldou tanto o produto quanto os dados que o alimentam.
Qual é o próximo passo
Embora o frontend do aplicativo entregue valor imediato, o poder real surgirá da conexão do Reffy com outras soluções na plataforma Databricks. Planejamos fornecer essa conectividade por meio de uma API e um servidor MCP, permitindo que as equipes acessem a inteligência do cliente diretamente em seus fluxos de trabalho e ferramentas existentes.
Com o Databricks e o Lakebase, também podemos entender como milhares de usuários interagem com o Reffy ao longo do tempo. Essas percepções nos permitirão refinar continuamente a ferramenta e moldar cuidadosamente as histórias adicionadas a este ecossistema em crescimento.
Para as equipes da Databricks que hoje lutam com a descoberta de referências de clientes, o Reffy oferece um exemplo concreto do que é possível quando esses recursos são reunidos. Para começar a construir seu próprio aplicativo agêntico na Databricks, saiba mais sobre o Databricks Apps, nosso guia de RAG, o Lakebase e o Agent Bricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.