Tutorial: 3 Projetos Gratuitos de Análise de Dados no Databricks Que Você Pode Fazer em Uma Tarde
Uma introdução prática ao Databricks Free Edition através de três projetos de análise reais e prontos para portfólio — completos com dados, dashboards, SQL e insights com IA.
por Noah Sommerfeld
- Três projetos de análise amigáveis para iniciantes que você pode concluir em uma tarde usando o Databricks Free Edition, sem necessidade de cartão de crédito.
- Como importar e analisar conjuntos de dados públicos usando dashboards de IA/BI, consultas em linguagem natural, funções de IA e previsão de ML leve.
- Exemplos práticos e prontos para portfólio (dashboards + código) que ajudam estudantes, candidatos a emprego e usuários de BI a construir artefatos de análise reais que podem apresentar.
Quer um projeto real de análise que você possa compartilhar publicamente, discutir em entrevistas ou adicionar ao seu currículo ou portfólio, tudo isso sem precisar de cartão de crédito?
A Databricks Free Edition oferece a estudantes, jovens profissionais e curiosos de IA acesso às mesmas ferramentas de dados+IA usadas em empresas líderes, com a quantidade certa de computação para projetos pessoais, e as ferramentas de painel e análise de IA/BI da Databricks são um ótimo ponto de partida. Este blog irá guiá-lo através da importação de alguns conjuntos de dados públicos para fatiar e picar, construir um painel polido e contar uma história clara sobre as tendências e insights ocultos.
Seja você um usuário avançado de planilhas querendo aprimorar suas habilidades com SQL e Python, ou um engenheiro de BI experiente experimentando análises impulsionadas por IA, esses projetos são projetados para ajudá-lo a construir algo tangível, rapidamente. Se você quiser se aprofundar, pode explorar o treinamento gratuito de IA/BI de autoatendimento da Databricks, cursos aprofundados de autores de IA/BI, ou participar de uma sessão de integração gratuita ao vivo. Você também pode acessar dezenas de outras demonstrações públicas instaláveis aqui.
Configuração
Se você ainda não tem uma conta, pode se inscrever na Databricks Free Edition aqui, sem necessidade de cartão de crédito ou número de telefone. Você obtém acesso à Databricks gratuitamente, perpetuamente, para experimentação e aprendizado com a Databricks Free Edition. Nota: A Free Edition é para uso pessoal, não para uso em produção ou comercial. Se você estiver procurando por uma plataforma de dados pronta para produção e totalmente suportada para o seu negócio, entre em contato com a Databricks aqui.
Uma última dica antes de começar: se você encontrar erros ou ficar preso em qualquer ponto, o Databricks Assistant (o diamante roxo no canto superior direito) é incrivelmente útil para depuração, geração de SQL e explicação de conceitos conforme você avança.
Com a configuração resolvida, vamos mergulhar!
1. Analise uma (simulada) Fábrica de Biscoitos
Começaremos com um aquecimento fácil. Para uma pequena empresa, acompanhar as operações e tendências é fundamental para o sucesso. O proprietário de uma pequena empresa pode estar procurando insights como encontrar o produto mais vendido, quais são as localizações com melhor desempenho ou prever como serão as vendas no próximo ano.
Cada workspace Databricks vem com um conjunto pré-instalado de dados de exemplo no catálogo 'samples', que é um ótimo ponto de partida para experimentar novos recursos. O conjunto de dados simulado 'bakehouse' de fornecedores, avaliações e transações é um bom lugar para praticar a contagem de uma história sobre o desempenho da 'nossa' pequena empresa. Você pode encontrar o conjunto de dados na parte 'catalog' na barra lateral do menu esquerdo do Databricks, que é o núcleo de todo workspace e permite explorar os conjuntos de dados disponíveis para análise.
Neste caso, você pode expandir o catálogo 'samples' e o esquema 'bakehouse' para encontrar os dados.
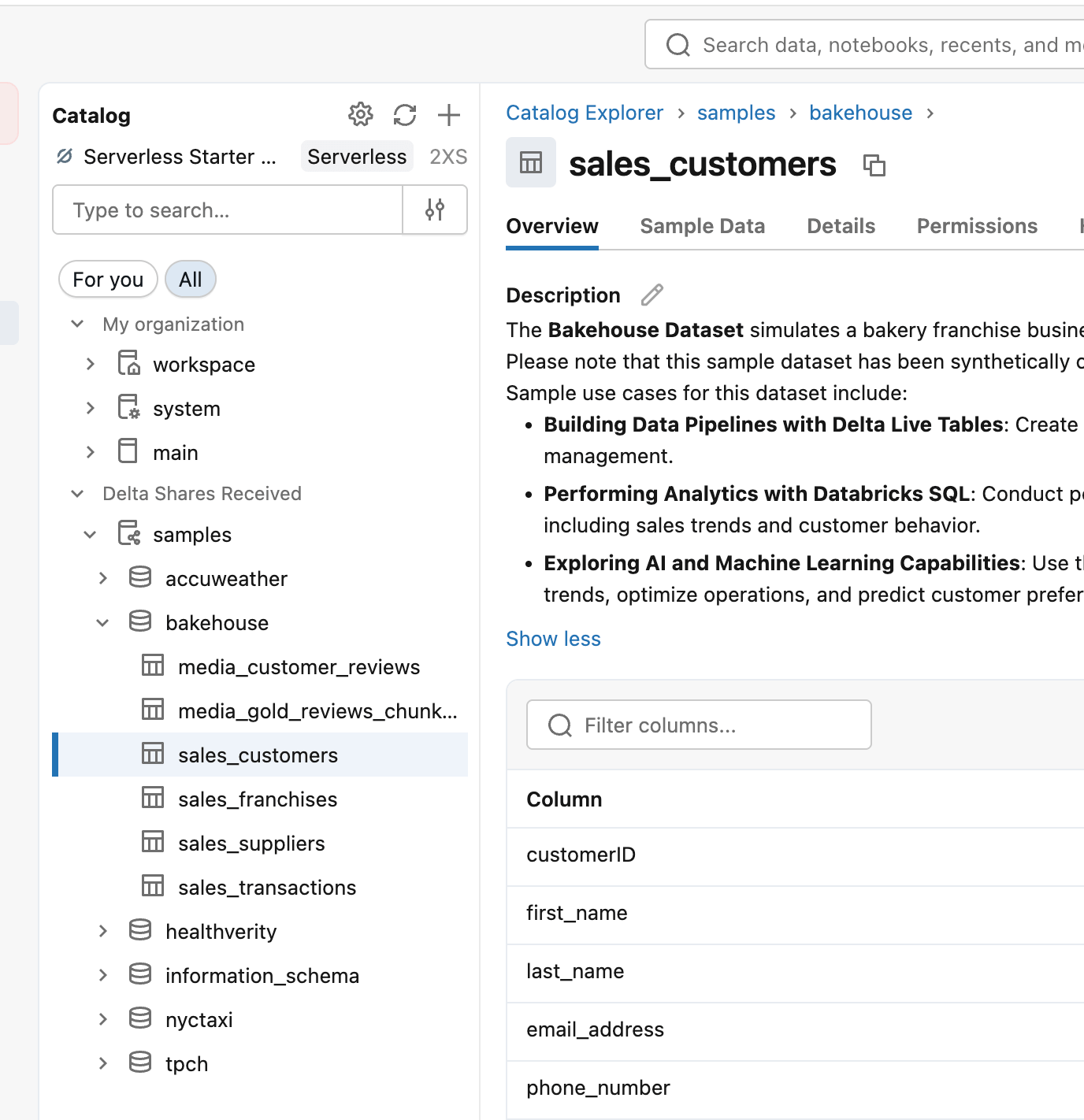
Para começar, crie um novo painel clicando em 'new->Dashboard' no canto superior esquerdo do workspace, em seguida, na aba 'data' do painel, selecione uma das tabelas usando SQL como abaixo (ou escolha na seleção de tabelas da UI):
Na tela do painel, adicione visualizações e textos que ajudem a contar uma história clara. Por exemplo, você pode usar gráficos de pizza para composição (como mix de produtos), gráficos de linha para tendências (como vendas ao longo do tempo) e contadores para destacar números importantes, como transações totais ou receita.
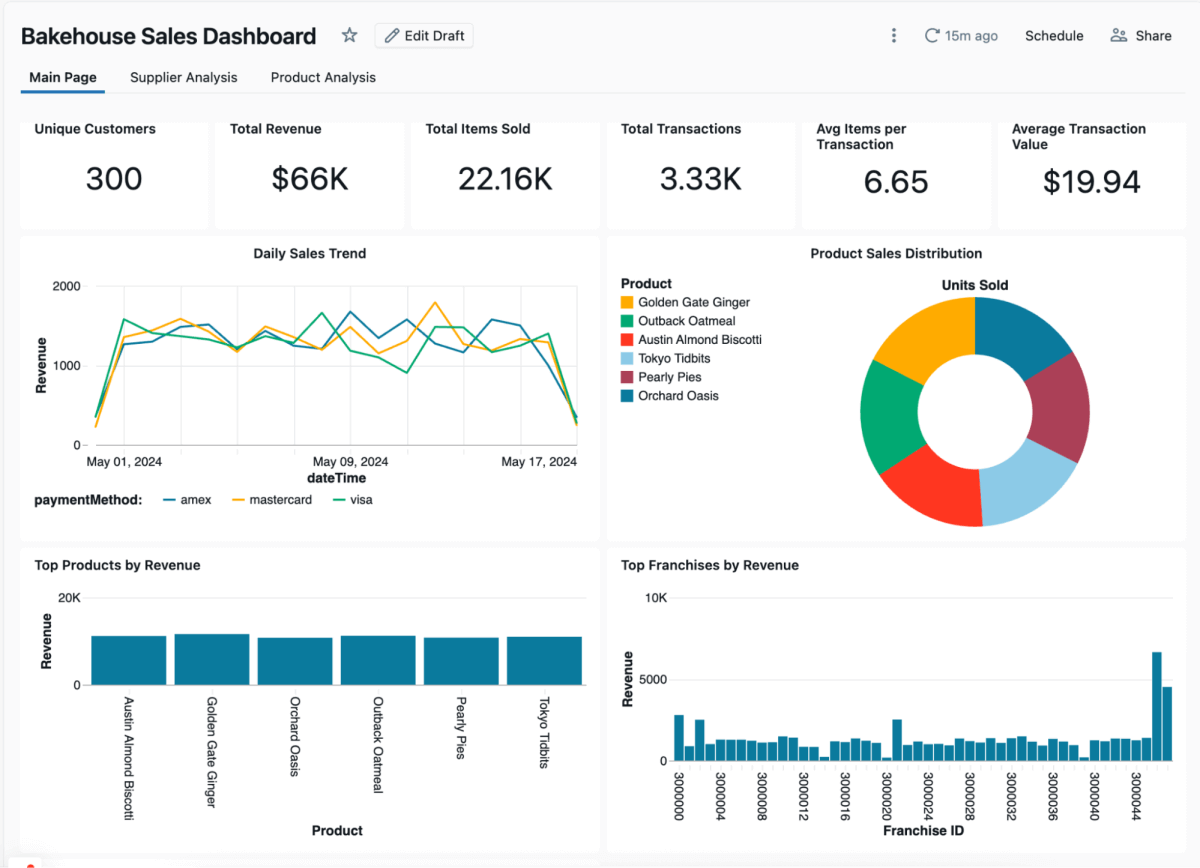
O conjunto de dados Bakehouse também inclui avaliações de clientes simuladas, o que o torna um ótimo lugar para experimentar análises assistidas por IA usando a função AI_Query(). Isso cria um novo conjunto de dados aplicando um modelo de IA diretamente aos seus dados — neste caso, classificando cada avaliação como positiva, negativa ou neutra. Você também pode modificar o prompt para gerar uma resposta automática para cada avaliação (e pode querer experimentar pedindo diferentes tons de voz).
Desafio de Próximo Nível: Você consegue encontrar uma maneira de aplicar outra função de IA como ai_classify() ou ai_gen()? Você consegue ajustar o prompt AI_Query() para gerar comentários de painel para você? Ou respostas automáticas para as avaliações? Você consegue ir além e construir um agente para gerar automaticamente cópias de marketing com base nas melhores avaliações, como Kasey Uhlenhuth fez no Data & AI Summit 2024?
2. Preveja Seu Aluguel
Dados de habitação são frequentemente um ótimo lugar para esticar seu músculo de análise — existem muitas correlações fortes para encontrar, como clima e taxas de juros, e há uma plétora de dados de alta qualidade divulgados por fontes oficiais (muitas vezes governamentais). Para alguns exemplos, os conjuntos de dados abertos da Zillow Research oferecem ótimos dados de habitação dos EUA, enquanto o Office for National Statistics do governo do Reino Unido fornece dados de censo de alta qualidade. Perguntas comuns de análise são coisas como 'Qual estado/província tem as maiores taxas de crescimento?', 'Onde está a maior parte da nova construção?' ou 'Qual é a relação entre custos de habitação e taxas de juros?'
Meu favorito pessoal é um conjunto de dados de 'preços de aluguel anunciados' do portal Open Government do Governo do Canadá, que contém um conjunto de aluguéis anunciados com atributos como ano, área metropolitana, número de quartos, etc. Acho que a forma como os anos estão dispostos como linhas individuais facilita a filtragem e análise.
Para trazer os dados para o seu workspace, baixe o conjunto de dados do portal, extraia o arquivo de dados do zip ('46100092.csv'), em seguida, clique no botão 'upload data' na página inicial do seu workspace para passar por um pequeno assistente na análise do formato CSV em uma tabela.
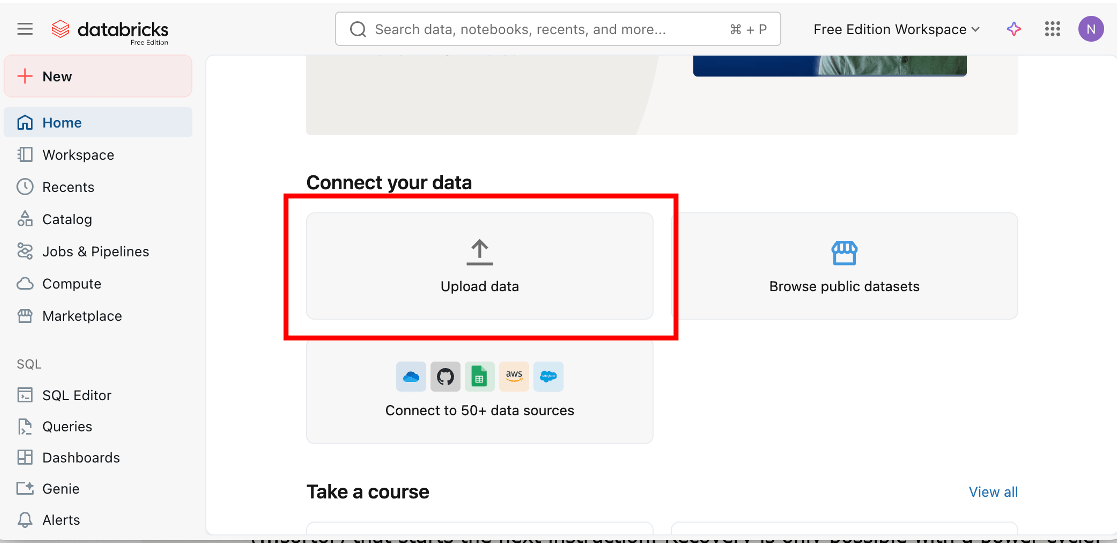
Por padrão, ele nomeará a tabela resultante com o mesmo nome do arquivo tecnicamente nomeado, então fique atento a uma chance de renomeá-la para algo significativo como 'Housing_data'. Assim que for criada, use a seção 'catalog' do workspace para encontrá-la e, em seguida, crie um painel usando o botão 'create' para obter um pré-preenchido com um esqueleto em torno do conjunto de dados.
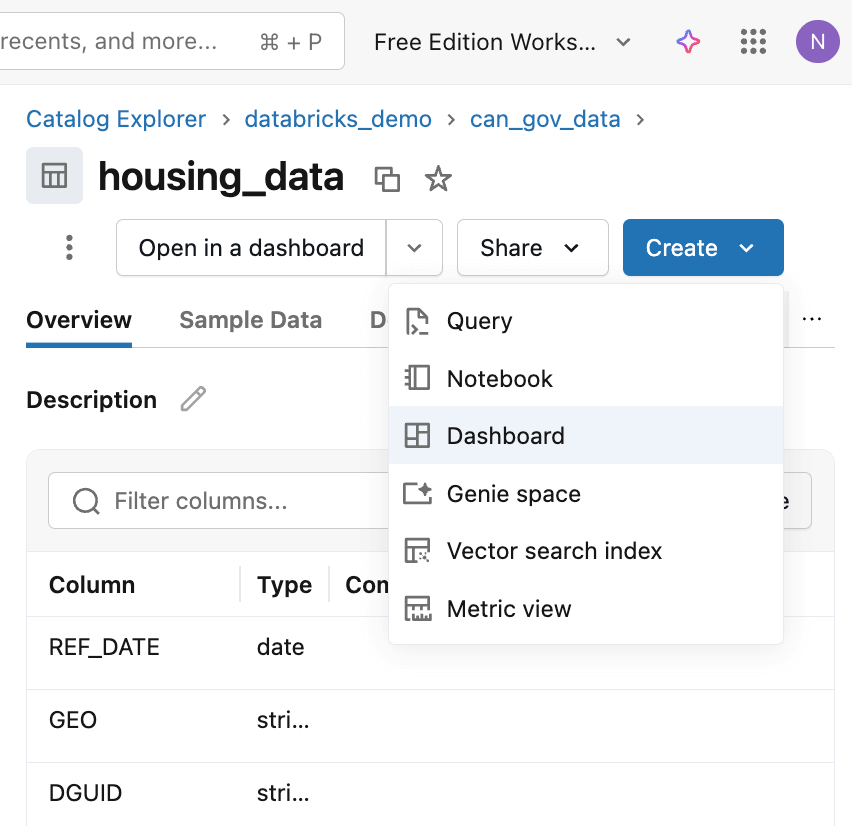
Para aprimorar o painel inicial, você pode adicionar outras fatias e comparações que adicionam contexto e cor à análise. Você pode considerar comparar aluguéis médios ou crescimento em outras cidades, ou examinar a proporção de unidades de um quarto para outros tipos de moradia. Qual é a cidade mais cara? Lembre-se também de adicionar filtros para que os usuários possam focar em suas cidades ou tipos de unidade específicos de interesse.
Em alguns casos, você pode precisar escrever uma consulta SQL diferente ou incorporar outros dados; lembre-se que o Databricks Assistant (diamante roxo no canto superior direito) pode ser útil. No meu exemplo, pedi ao Assistant para adicionar latitude/longitude para as cidades para que eu pudesse construir a visualização de mapa.
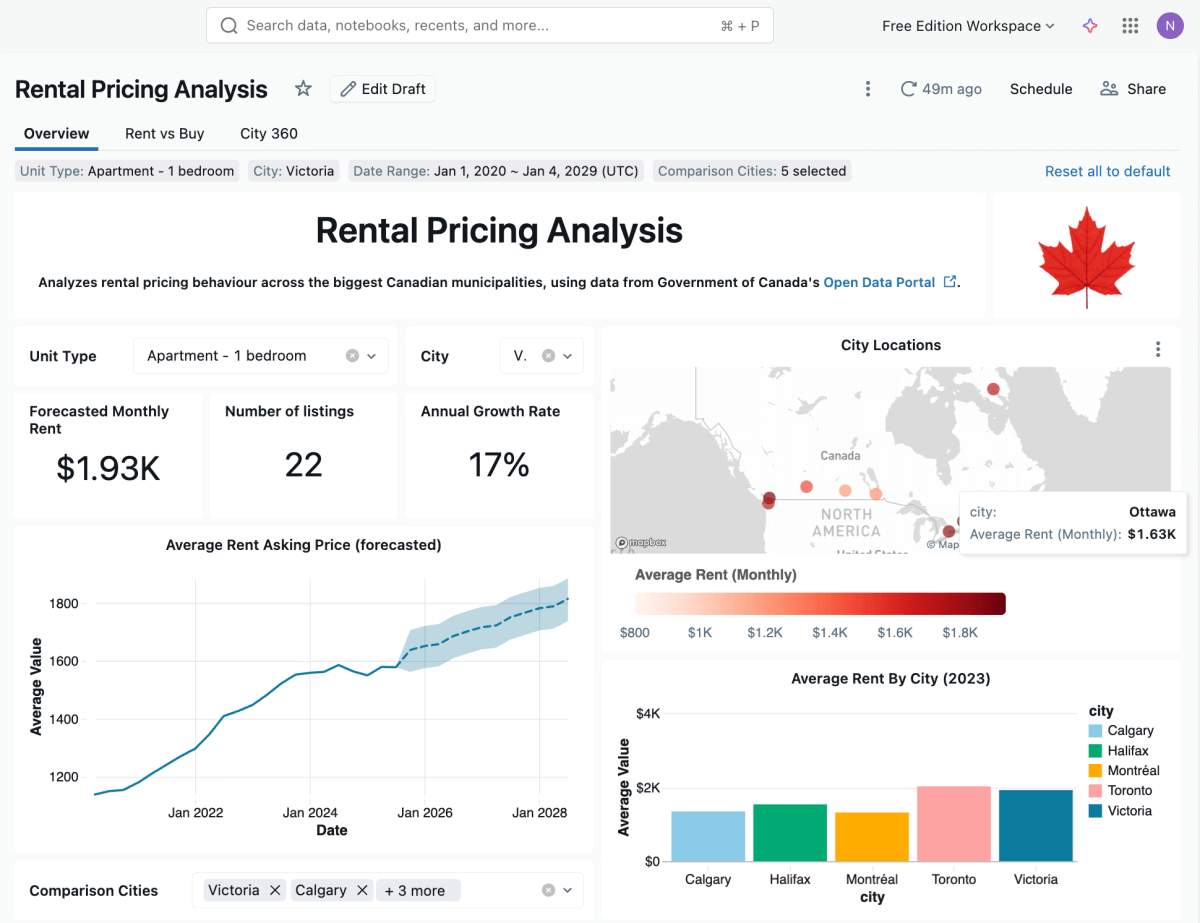
Para gerar uma previsão, comece com um gráfico de linha comum, onde o eixo x é a data de referência e o eixo y é o preço de consulta (valor). Em seguida, procure o botão ‘adicionar previsão’ na barra lateral. Isso adicionará uma nova visualização de previsão à tela do seu painel, criada a partir de um novo conjunto de dados SQL com a função SQL ‘AI_Forecast()’ do Databricks, que chama um modelo de ML de série temporal e o aplica aos seus dados. Este recurso beta ainda está em evolução (adoraríamos ouvir seu feedback!), mas ainda é um ponto de partida útil para aplicar ML a um caso de uso do mundo real. Lembre-se também que o Databricks Assistant pode sempre ajudá-lo a criar seu próprio SQL personalizado para novos conjuntos de dados.
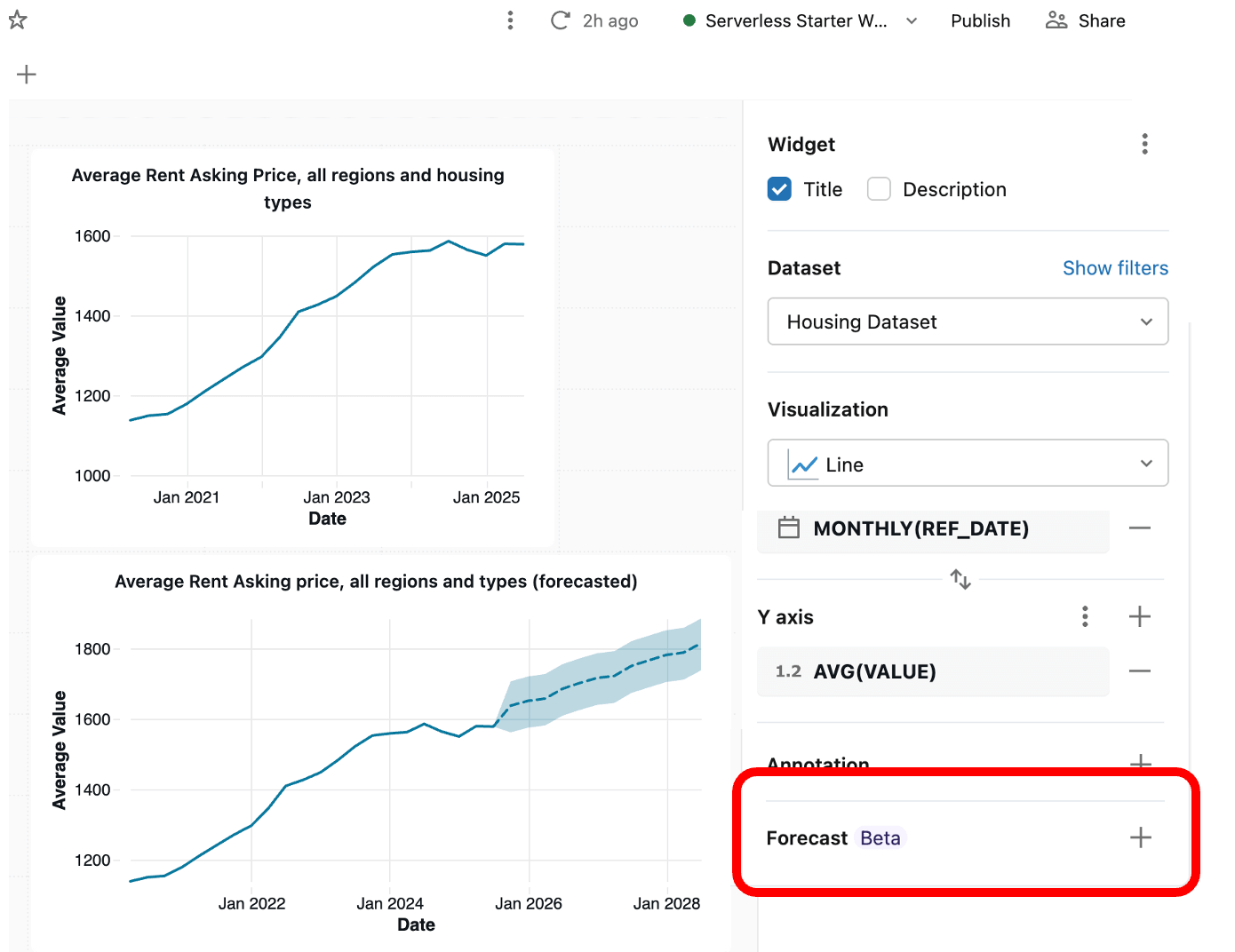
Desafio de nível avançado: Embora o AI_Forecast() seja ótimo para uma previsão de referência rápida, uma mais precisa envolveria a combinação de outros pontos de dados e a aplicação de um algoritmo de machine learning personalizado — você pode ver como seria uma solução completa (neste caso, prevendo a manutenção de turbinas eólicas) em nosso site de demonstrações do Databricks.
3. Encontre uma Filmagem para Observar
Em cidades frequentemente usadas como cenário de filmes, você pode ter sorte de encontrar caminhões de filmagem, assistentes de produção e pequenas cabines de direção perto de edifícios históricos ou partes pitorescas da cidade. Antes que as produções de filmes possam bloquear propriedades públicas para essas filmagens, elas devem obter licenças de filmagem, que são então publicadas em conjuntos de dados abertos por agências governamentais.
Embora não contenha permissões com visão de futuro, um dos melhores exemplos desse tipo de conjunto de dados é a listagem do Portal de Dados Abertos da Cidade de Nova York para licenças de filmagem. Ele lista o tipo de filmagem (ou seja, notícias, longa-metragem ou série), juntamente com o horário de início e término da filmagem, bairro e código postal. Ao fatiar e picar o conjunto de dados, você pode identificar os locais mais comuns e, esperançosamente, vislumbrar uma estrela em ação.
Como nos exemplos anteriores, temos que começar carregando os dados no Databricks. O portal de dados abertos de Nova York permite baixar facilmente o .csv e importá-lo através do ‘upload de dados’ na interface do usuário, como fizemos para os exercícios anteriores. No entanto, um recurso interessante deste conjunto de dados é que ele é atualizado diariamente. Vamos obter esses dados programaticamente para que possamos executá-los em um cronograma. Isso está muito mais próximo de como você abordaria isso em um contexto corporativo.
O Databricks torna muito fácil executar o Python de que precisamos através de Notebooks. Neste caso, crie um notebook (novo -> notebook no canto superior esquerdo), copie e cole o código abaixo e pressione executar para baixar o CSV em seu espaço de trabalho e analisá-lo em uma tabela. Lembre-se que se você tiver problemas, pode sempre usar o Databricks Assistant (através do diamante roxo) para ajudar!
Esta primeira parte do código cria um Volume (um local para armazenar arquivos arbitrários) e, em seguida, baixa o conjunto de dados usando a biblioteca Python URLLib. Sinta-se à vontade para modificar os nomes do catálogo + esquema para se adequar ao seu estilo!
Esta segunda parte do código pega o arquivo bruto e cria uma tabela chamada ‘film_permits’ que podemos usar em nosso painel. Tente pedir ao Assistant para explicá-lo, se precisar.
Se funcionou com sucesso, você deverá ser capaz de encontrar a tabela através da parte do catálogo do espaço de trabalho ou abrindo a barra lateral do explorador de dados (ícone de três formas) no notebook, e, em seguida, expandindo o catálogo databricks_demo e o esquema open_nyc para ver a tabela. Pode ser necessário clicar no botão ‘atualizar’ se você já o tinha aberto.
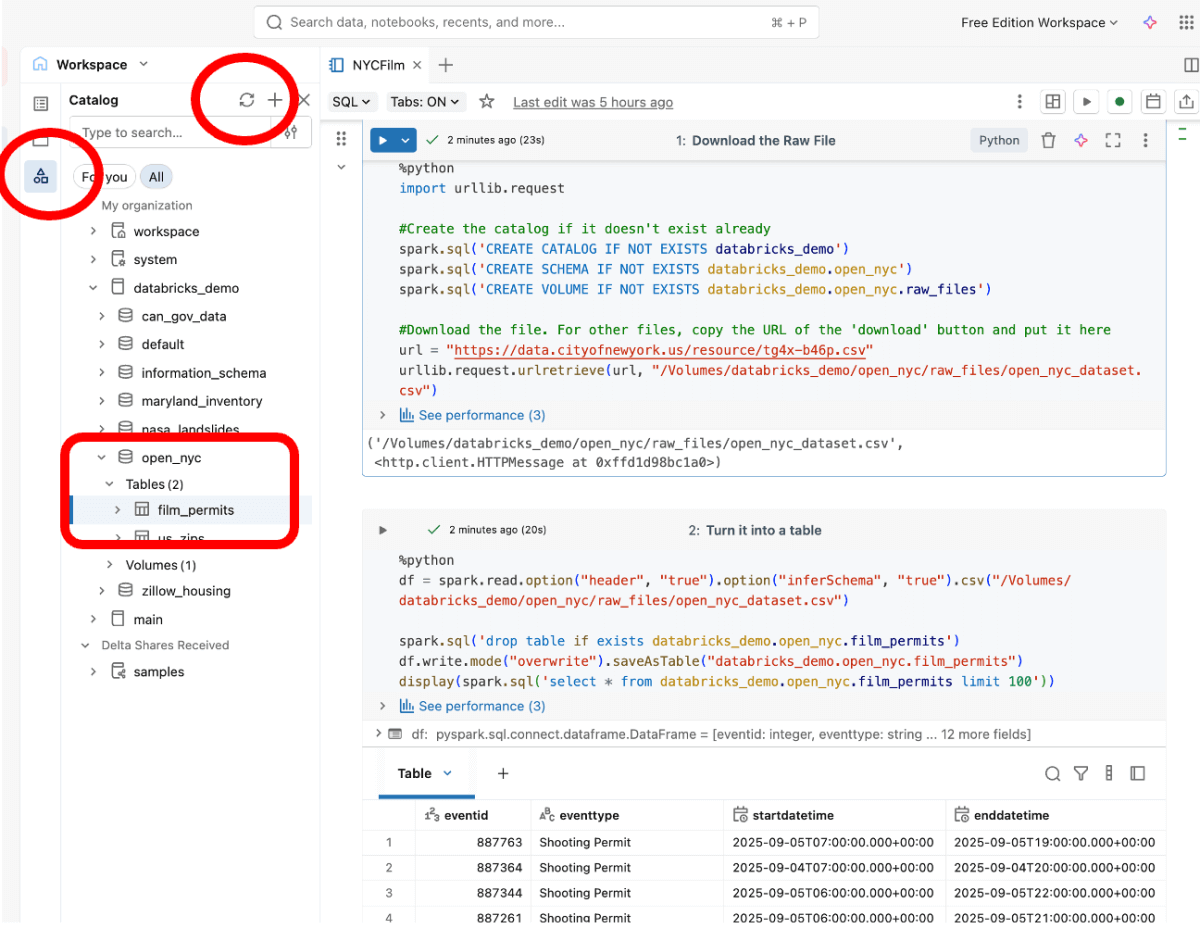
Lembrete: Se você encontrar algum problema com o código, lembre-se que sempre pode abandonar a abordagem de código e importar os dados manualmente, baixando-os do portal e carregando-os através do botão ‘Upload Data’ na página inicial do seu espaço de trabalho.
Assim que a tabela for carregada, é hora de fatiar, picar e apresentar uma história! Você pode querer verificar tendências com um gráfico de linha - há mais filmagens de séries ou longas-metragens? Isso está mudando ao longo do tempo? Ou você pode pensar na distribuição com um gráfico de barras ou pizza - os locais de filmagem de notícias ou comerciais se sobrepõem muito com filmes?
Se você tentar criar uma visualização de mapa, poderá notar que, embora as licenças de filmagem tenham um código postal, a visualização de mapa do painel de IA/BI requer atributos de latitude e longitude. Felizmente, conjuntos de dados de mapeamento de CEP para coordenadas são fáceis de encontrar online e podem ser trazidos para o painel usando o Assistant. Você pode baixar este conjunto de dados aberto (licenciado sob Creative Commons) e, em seguida, criar um novo conjunto de dados em seu painel, pedindo ao Assistant para gerar uma consulta combinada. Aqui está o prompt que usei (ajuste para seus nomes de catálogo e tabela específicos):
E aqui está uma versão de como seu painel final pode ficar!
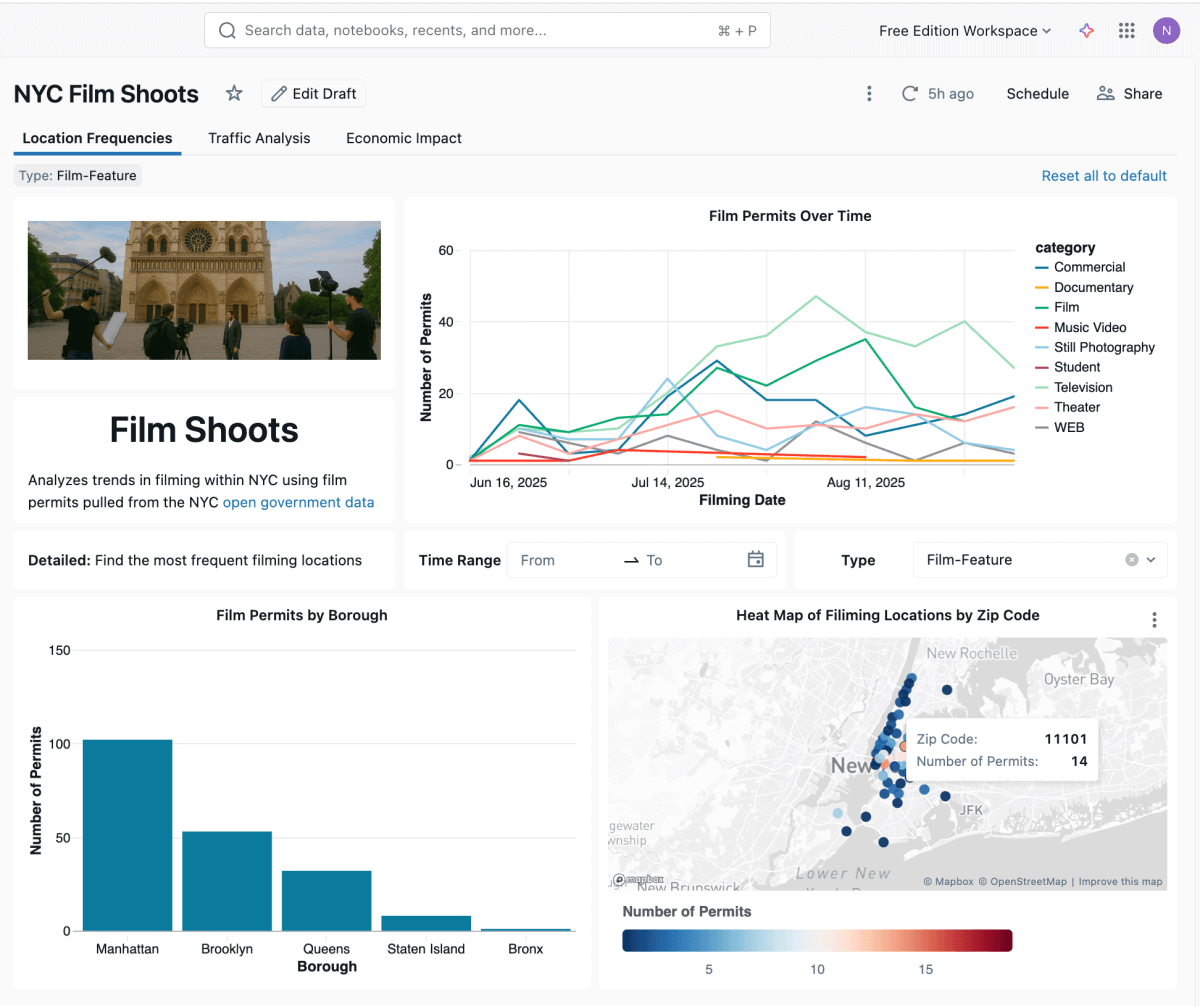
Desafio: Que outros dados do OpenNYC você poderia sobrepor, talvez volumes de táxi ou de carros de aplicativo? Marcos significativos? Se você for politicamente ativo, há alguma análise que aprofundaria sua causa? Outras cidades e estados oferecem conjuntos de dados abertos semelhantes, como o conjunto de dados de benchmark de energia de edifícios de Seattle de emissões que podem ser mais próximas de você.
Você consegue estender a análise geoespacial usando as funções ‘ST Functions’ nativas do Databricks, para procurar os pontos mais próximos?
Conclusão
Minha parte favorita da análise são os momentos de epifania que você tem ao perseguir a curiosidade, e espero que estes exemplos tenham despertado algumas ideias. Se você quiser aprender mais ou decidir trabalhar para uma certificação que possa colocar em um currículo, você pode acessar o curso de treinamento gratuito de visão geral de IA/BI do Databricks, ministrado no seu próprio ritmo aqui, um curso de treinamento de autor mais aprofundado aqui, ou participar de uma aula de integração ao vivo gratuita! O site de documentação do Databricks também é um ótimo lugar para consultar recursos sobre funcionalidades específicas
Se você quiser importar qualquer um dos painéis de exemplo neste blog, pode conferir este repositório para o código-fonte. As especificações do painel de IA/BI são apenas JSON, então baixe o arquivo e importe através do menu suspenso ‘importar’ na página inicial dos painéis.
Por fim, você pode encontrar dezenas de demonstrações instaláveis, de ML a criação de painéis e IA generativa, na Central de Demonstrações da Databricks. Experimente algo novo ou compartilhe o que você construiu com a comunidade Databricks em sua plataforma de mídia social favorita. Bom trabalho!
Comece a criar com a Edição Gratuita da Databricks
Inicie seu espaço de trabalho gratuito — sem necessidade de cartão de crédito — e transforme esses projetos em painéis prontos para portfólio hoje mesmo.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.