Desvendando o futuro da Indústria Automotiva (Parte 2): Implementando analítica Geoespacial Escalável & AI
Impulsionando a Inovação Automotiva e de Mobilidade: Passando da teoria à aplicação com dados geoespaciais em tempo real, AI e analítica escalável
por Eumar Assis, Fareed Aref, Varun Mahajan, Andres Urrutia, Himanshu Gupta, Michael Johns e Zachary Ryan
- O Databricks permite que você atenda a aplicações e casos de uso relacionados a dados geoespaciais, incluindo ingestão, transformação, disponibilização e consumo.
- No desenvolvimento de uma aplicação completa, o Unity Catalog fornece gerenciamento seguro, governado e compartilhável de geocodificação; o AutoML permite a criação rápida de modelos do machine learning; e o Databricks Labs Data Generator facilita a geração de dados sintéticos para teste e validação
- O Databricks apresenta uma plataforma unificada para cada o passo necessário para desenvolver esses casos de uso em escala, com mais recursos e benefícios planejados no roteiro do produto.
Na Parte 1, exploramos os principais conceitos e datasets que impulsionam a analítica geoespacial na indústria automotiva. Na Parte 2, vamos nos aprofundar n'os passos práticos para construir pipelines geoespaciais escaláveis usando AI, ML e dados sintéticos, mantendo a governança e o desempenho no Databricks.
Nosso foco será em código real e padrões de arquitetura que dão vida a essas ideias em soluções automotivas e de mobilidade prontas para produção.
Oferecendo analítica geoespacial escalável
A Data Intelligence Platform da Databricks combina analítica geoespacial poderosa e AI para fornecer percepções escaláveis e em tempo real. Com recursos como o Liquid Clustering e a indexação espacial H3, ele permite o processamento rápido e eficiente de datasets geoespaciais massivos. As funções geoespaciais integradas simplificam tarefas espaciais, como mapear padrões de tráfego ou avaliar riscos nas estradas. O AutoML acelera o desenvolvimento de modelos para casos de uso como a previsão de direção agressiva, considerando as condições climáticas, de tráfego e da estrada. A plataforma também garante uma governança robusta através do Unity Catalog (UC), que gerencia o acesso e o compartilhamento de dados com segurança. Ferramentas como AI Query e funções governadas pelo UC facilitam a extração de dados de geolocalização estruturados de fontes não estruturadas.
Crie um pipeline geoespacial robusto para mobilidade inteligente e segurança viária
Esta postagem se concentrará em um pipeline completo de analítica geoespacial construído na Databricks Data Intelligence Platform. Abaixo, ilustramos o pipeline medalhão combinando dados geoespaciais, LLMs e o Genie para percepções conversacionais.
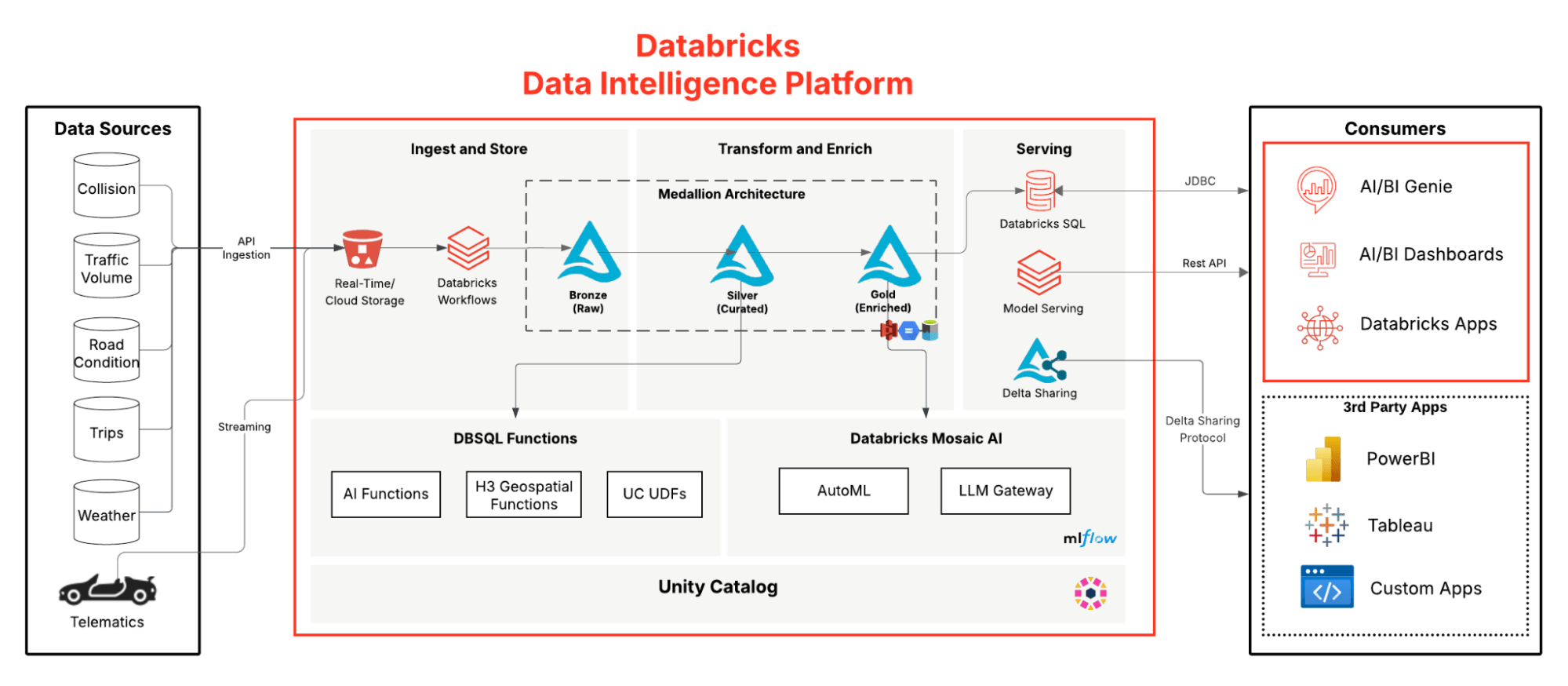
Ingestão Escalável
A ingestão de dados geoespaciais em escala no Databricks é perfeita graças à integração da plataforma com uma ampla variedade de bibliotecas e ferramentas geoespaciais. As funções geoespaciais do Databricks são projetadas especificamente para aprimorar o tratamento de dados espaciais. Auto Loader é a opção ideal para processar bilhões de arquivos do armazenamento em cloud, enquanto a geração de dados sintéticos pode servir como alternativa durante o desenvolvimento.
Criação de Dados Telemáticos Sintéticos
A telemática é um caso de uso robusto para dados sintéticos, pois permite testes realistas e desenvolvimento de modelos sem expor informações confidenciais ou pessoais do veículo. Embora os dados sintéticos possam ser criados usando qualquer lógica SQL ou Python, dependendo da criatividade do desenvolvedor, a biblioteca Databricks Labs Data Generator (dbldatagen) facilita significativamente esse processo. Ele oferece uma interface declarativa para criar grandes datasets sintéticos e escaláveis diretamente no Spark.
No exemplo abaixo, usamos o dbldatagen para simular 1 milhão de linhas de dados telemáticos. Essa configuração permite que os desenvolvedores gerem datasets realistas para modelagem e teste sem depender de dados de produção.
Transformação e Enriquecimento
Gere rotas para auxiliar na analítica e na modelagem
A geração de rotas permite o planejamento otimizado da mobilidade, segurança e infraestrutura, identificando caminhos eficientes e cientes de risco a partir de dados geoespaciais. Em nosso pipeline, reconstruímos rotas entre pontos de coleta e entrega para correlacionar trajetos com fatores externos e obter percepções mais aprofundadas.
No Databricks, os desenvolvedores podem usar osmnx e networkx, bibliotecas de código aberto que acessam dados do OpenStreetMap e calculam caminhos ideais em redes de ruas. O exemplo abaixo usa essas ferramentas com applyInPandas para paralelizar o roteamento nos executores do Spark. Também oferecemos um Acelerador de Solução para geração de rotas escalável usando um cluster Databricks equipado com OSRM.
Observe que este código de exemplo requer um cluster no Modelo de Acesso Dedicado, pois estamos usando sparkContext.broadcast para melhorar o desempenho, evitando a necessidade de download de arquivos de gráfico em cada executor de worker.
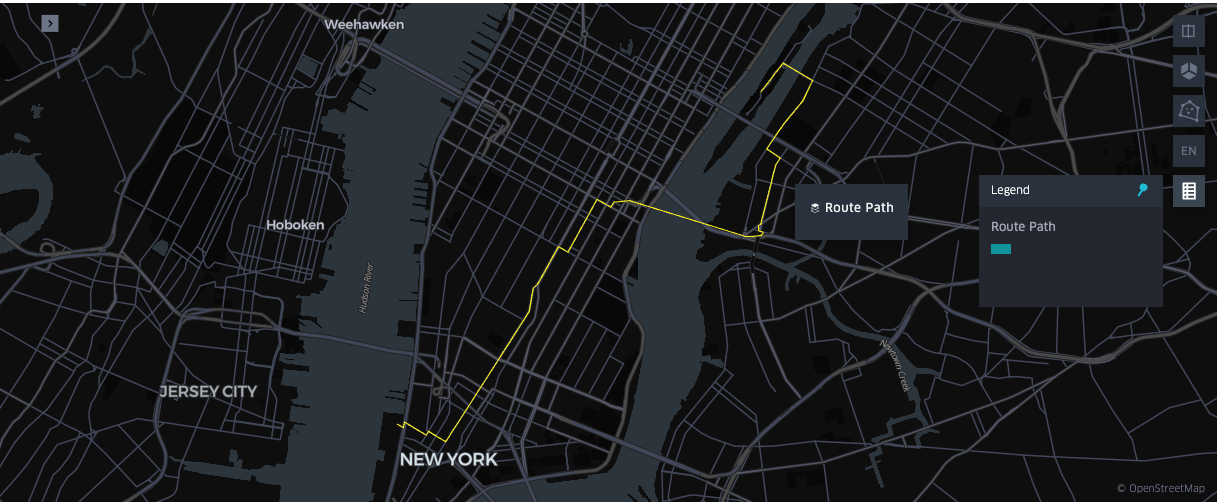
{kind=link}
Gere percepções com LLMs
O Databricks simplifica a geocodificação usando um modelo de linguagem grande (LLM) para converter texto não estruturado, como CEPs, em dados geoespaciais estruturados. Com um prompt de linguagem natural, a função ai_query chama o endpoint databricks-meta-llama-3-70b-instruct para gerar latitude e longitude, sem depender de APIs externas.
Embora as ferramentas de geocodificação tradicionais sejam recomendadas para fornecer resultados determinísticos, este exemplo mostra a facilidade com que os LLMs aprimoram os fluxos de trabalho geoespaciais e democratizam a inteligência de localização.
Disponibilizando
Forneça uma Indexação Eficiente de Dados Geoespaciais
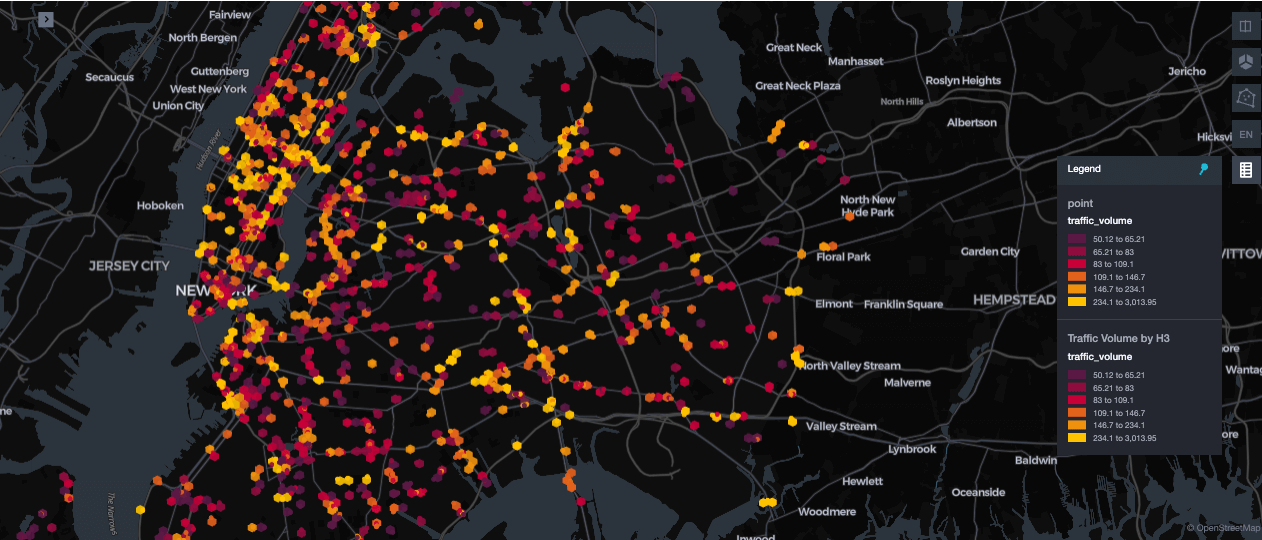
Workloads geoespaciais exigem indexação flexível para suportar padrões de query variados. O Databricks integra a indexação espacial H3 com o Liquid Clustering para lidar com consultas analíticas e fluxos de trabalho de treinamento de modelos de forma eficiente. Essa combinação permite a filtragem rápida de dados espaciais combinados com outros atributos, como velocidade ou determinantes sociais, sem exigir Z-ordering explícito.
O exemplo abaixo mostra como aproveitar o suporte H3 integrada com o Liquid Clustering. Ele usa ST_Centroid para compute os pontos centrais da geometria e ST_Transform para convertê-los para as coordenadas WGS84. Em seguida, h3_longlatash3 gera índices H3 na resolução 9, permitindo query espaciais rápidas e consistentes em uma grade hexagonal.
A operação MERGE INTO permite upserts idempotentes em tabelas Delta silver, evitando duplicatas ao processar os mesmos dados várias vezes. Combinado com CLUSTER BY h3_index, os registros são colocados juntos com base na proximidade espacial. Ao contrário do ZORDER estático, o Liquid Clustering suporta clusters dinâmicos em índices H3 e campos como Timestamp ou métricas do veículo sem exigir padrões de query predefinidos. Isso resulta em pesquisas mais rápidas, filtragem eficiente e treinamento de modelos escalável. Para mais detalhes, consulte as funções H3 do Databricks e a documentação do Liquid Clustering.
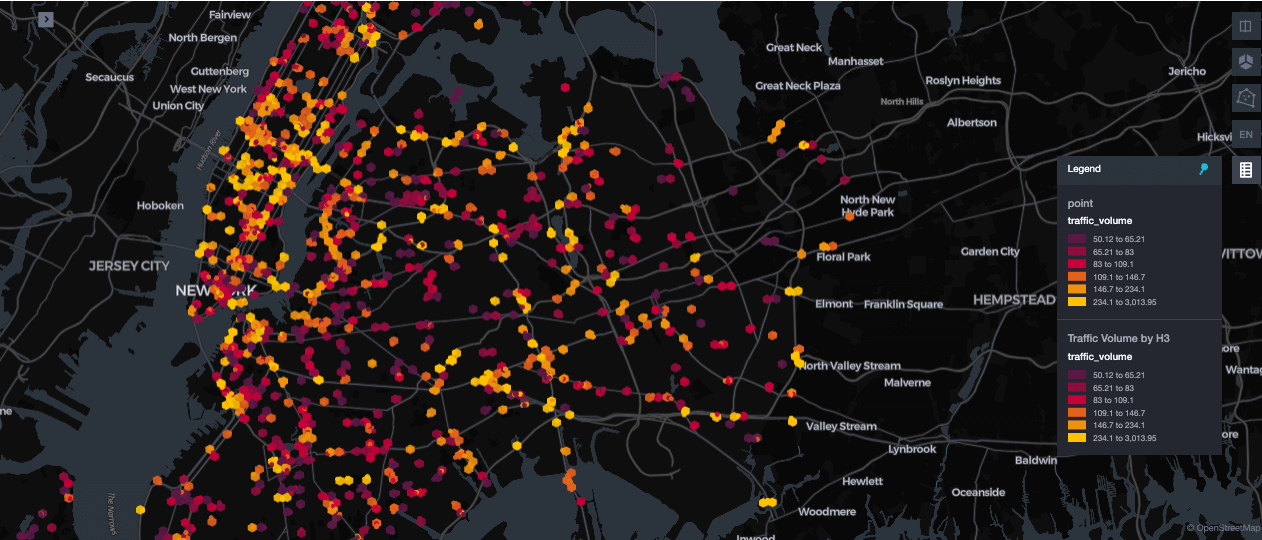
{kind=link}
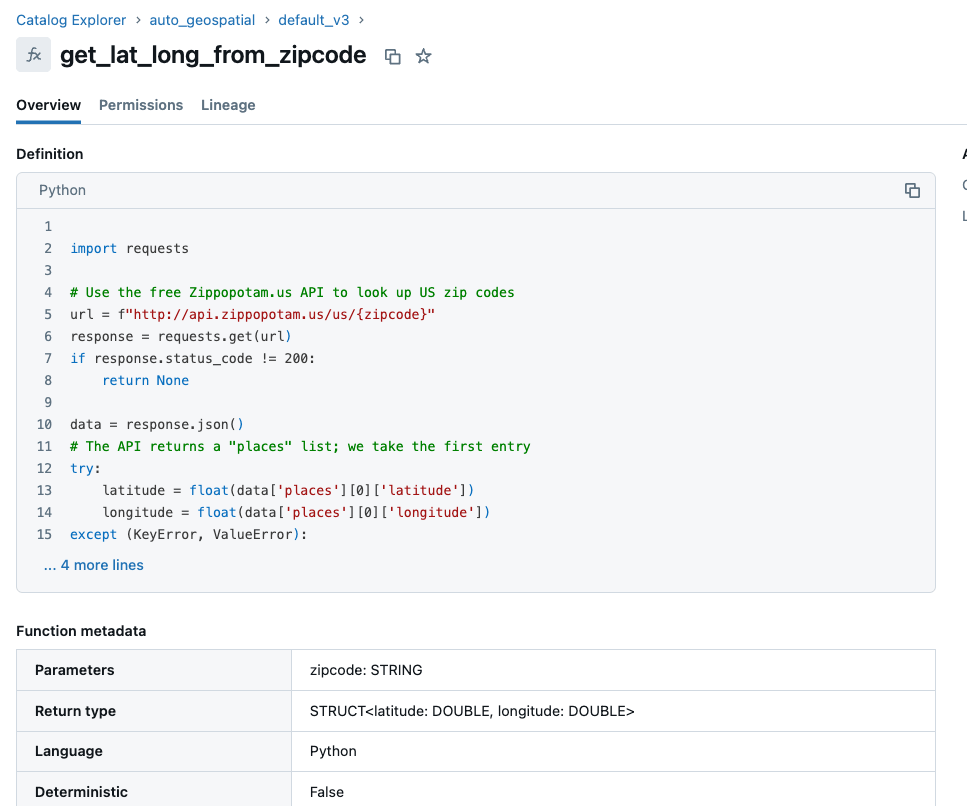
Governança da Lógica Personalizada com UDFs do Unity Catalog
As funções definidas pelo usuário (UDFs) no Unity Catalog oferecem uma maneira segura, governada e compartilhável de realizar geocodificação determinística em escala. Centralizar a lógica — como converter códigos postais (CEP) em latitude e longitude — garante que a lógica e os resultados permaneçam consistentes e auditáveis entre usuários e workloads. O código abaixo define uma UDF baseada em Python no Unity Catalog que retorna com segurança a latitude e a longitude para um determinado código postal (CEP) dos EUA usando uma API pública.
Consumo
Preveja o volume de tráfego com AutoML e séries temporais.
Compreender os padrões de tráfego e os comportamentos de direção arriscados é fundamental para uma mobilidade mais inteligente e segura. Com o Databricks AutoML e a indexação espacial, as equipes podem criar modelos com reconhecimento de tempo sem conhecimento aprofundado em ML.
O exemplo abaixo usa o automl.forecast para ensinar um modelo de série temporal sobre o volume de tráfego (vol) para uma localização específica (definida por h3_index). Ao focar em uma única célula H3, o modelo captura tendências temporais nessa área. O AutoML lida com a engenharia de recursos, o ajuste de modelos e o treinamento, otimizando a previsão para casos de uso como previsão de congestionamento e detecção de direção agressiva em diferentes zonas.
Ao combinar inteligência geoespacial com AI e processamento em tempo real, as organizações automotivas podem alcançar um novo nível de segurança, eficiência e inovação. Da manutenção preditiva à mobilidade inteligente e otimização de EV, o Databricks oferece a plataforma unificada necessária para operacionalizar esses casos de uso em escala. Hoje, os clientes estão obtendo um valor significativo com nossas funções geoespaciais H3, e temos muito mais planejado no roteiro do produto.
Pronto para acelerar sua jornada geoespacial automotiva? Explore nossos Aceleradores de Solução Geoespacial e experimente em seu próprio workspace hoje mesmo.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.