O que é o ecossistema Hadoop?
Um conjunto abrangente de ferramentas de código aberto, incluindo HDFS, MapReduce, YARN, Hive e Spark, que trabalham em conjunto para armazenar, processar e analisar conjuntos de dados massivos.
- O HDFS fornece armazenamento distribuído tolerante a falhas usando a arquitetura NameNode e DataNode, enquanto o YARN gerencia os recursos do cluster e o MapReduce lida com o processamento paralelo de dados.
- O Apache Hive oferece consultas semelhantes a SQL por meio do HiveQL para operações de data warehouse, e o Apache Spark fornece processamento em memória para análises em tempo real e aprendizado de máquina.
- O ecossistema inclui ferramentas complementares como Pig para scripts, HBase para armazenamento NoSQL, Oozie para agendamento de fluxos de trabalho e Sqoop para transferência de dados entre Hadoop e bancos de dados relacionais.
O que é o ecossistema Hadoop?
O ecossistema Apache Hadoop se refere aos vários componentes da biblioteca de software Apache Hadoop. Ele inclui projetos de código aberto, bem como todas as ferramentas complementares. Algumas das ferramentas mais conhecidas no ecossistema Hadoop incluem HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase Oozie, Sqoop, Zookeeper e muito mais. Os principais componentes do ecossistema Hadoop usados com frequência pelos desenvolvedores são:
O que é o HDFS?
O Hadoop Distributed File System (HDFS) é um dos maiores projetos Apache e o principal sistema de armazenamento do Hadoop, empregando uma arquitetura de NameNode e DataNode. É um sistema de arquivos distribuído que pode armazenar arquivos grandes em execução em um cluster de hardware comum.
O que é o Hive?
Hive é uma ferramenta de ETL e data warehouse usada para consultar ou analisar grandes conjuntos de dados armazenados no ecossistema Hadoop. O Hive tem três funções principais: resumo, query e análise de dados não estruturados e semiestruturados no Hadoop. Ele tem uma interface semelhante ao SQL, a linguagem HQL que se comporta como SQL e traduz automaticamente as queries em jobs MapReduce.
O que é o Apache Pig?
Pig é uma linguagem de script de alto nível usada para consultar grandes conjuntos de dados usados no Hadoop. A linguagem de script simples semelhante a SQL do Pig é chamada de Pig Latin, e seu objetivo principal é realizar as operações necessárias e preparar a saída final no formato desejado.
O manual de IA agêntica para empresas

O que é MapReduce?

É outra camada de processamento de dados no Hadoop. Ele tem a capacidade de processar grandes quantidades de dados estruturados e não estruturados e pode dividir jobs em conjuntos de tarefas independentes (sub-job) para gerenciar arquivos de dados muito grandes em paralelo.
O que é YARN?
YARN é um acrônimo para Yet Another Resource Negotiator. Um dos principais componentes do Apache Hadoop de software livre para gerenciamento de recursos, é responsável por gerenciar, monitorar e implementar controles de segurança para cargas de trabalho. Ele também aloca recursos do sistema para os vários aplicativos executados no cluster Hadoop, bem como aloca tarefas a serem executadas em cada nó do cluster. O YARN tem dois componentes principais:
- Gerenciador de recursos
- Gerenciador de nós
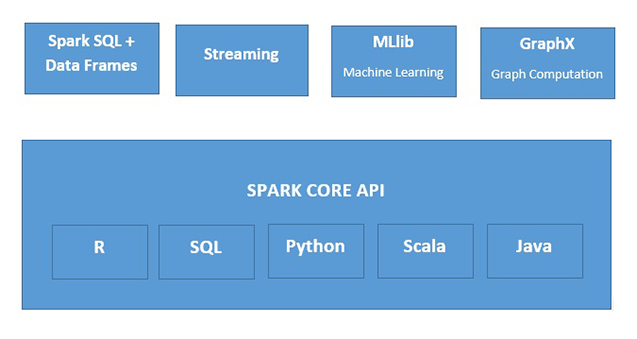
O que é o Apache Spark?
Apache Spark é um mecanismo de processamento de dados em memória rápido adequado para uso em uma ampla variedade de situações. O Spark pode ser implantado de várias maneiras, possui as linguagens de programação Java, Python, Scala e R e é compatível com SQL, streaming de dados, machine learning e processamento de gráficos, para que você possa usá-los em seus aplicativos.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.