O que é Spark Streaming?
Como o Spark Streaming processa micro-lotes de dados em tempo real com DStreams e por que o Structured Streaming é agora o mecanismo preferido.
- Entenda o que é o Apache Spark Streaming, como ele estende a API principal do Spark e por que agora é considerado um mecanismo de streaming legado em favor do Structured Streaming.
- Veja como o Spark Streaming ingere dados de fontes como Kafka, Flume e Amazon Kinesis, os processa em micro-lotes e envia os resultados para arquivos, bancos de dados ou painéis usando DStreams.
- Explore os principais benefícios introduzidos pelo Spark Streaming, como processamento unificado em lote e em fluxo contínuo, tolerância a falhas e integração com MLlib e Spark SQL.
O Apache Spark Streaming é a geração anterior do mecanismo de streaming do Apache Spark. Não há mais atualizações para o Spark Streaming, e é um projeto legado. Há um mecanismo de streaming mais novo e mais fácil de usar no Apache Spark chamado streaming estruturado. Você deve usar o streaming estruturado do Spark para suas aplicações de streaming e pipelines. Consulte streaming estruturado.
O que é o Spark Streaming?
O Apache Spark Streaming é um sistema escalável de processamento de streaming tolerante a falhas que suporta nativamente workloads em batch e de streaming. O Spark Streaming é uma extensão da API principal do Spark que permite que engenheiros de dados e cientistas de dados processem dados em tempo real de várias fontes, incluindo (mas não se limitando a) Kafka, Flume e Amazon Kinesis. Esses dados processados podem ser enviados para sistemas de arquivos, bancos de dados e painéis de controle em tempo real. Sua principal abstração é um Discretized Stream, ou DStream, que representa um stream de dados dividido em pequenos lotes. Os DStreams são criados com base em RDDs, a abstração de dados principal do Spark. Isso permite que o Spark Streaming se integre perfeitamente a qualquer outro componente do Spark, como MLlib e Spark SQL. O Spark Streaming é diferente de outros sistemas que têm um mecanismo de processamento projetado apenas para streaming ou que têm APIs de lote e streaming semelhantes, mas compilam internamente para mecanismos diferentes. O mecanismo de execução único do Spark e o modelo de programação unificado para lote e streaming geram alguns benefícios exclusivos em relação a outros sistemas de streaming tradicionais.
O manual de IA agêntica para empresas

Quatro principais aspectos do Spark Streaming
- Recuperação rápida de falhas e retardatários
- Melhor equilíbrio de carga e uso de recursos
- Combinação de dados de streaming com conjuntos de dados estáticos e consultas interativas
- Integração nativa com bibliotecas de processamento avançadas (SQL, machine learning, processamento de gráficos)
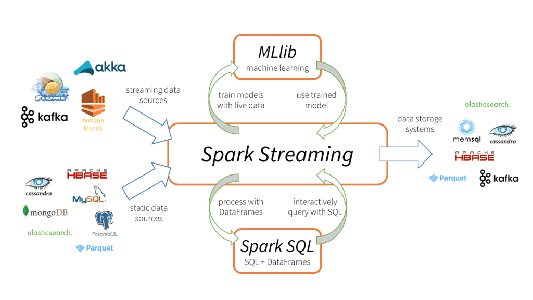
Essa unificação de recursos de processamento de dados diferentes é a principal razão por trás da rápida adoção do Spark Streaming. É muito mais fácil para os desenvolvedores usarem uma única estrutura para satisfazer todas as suas necessidades de processamento.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.