Apresentando o Apache Spark 3.0
Agora disponível no Databricks Runtime 7.0
por Matei Zaharia, Reynold Xin, Xiao Li, Wenchen Fan e Yin Huai
Temos o prazer de anunciar que o Apache SparkTM 3.0.0 já está disponível no Databricks como parte do nosso novo Databricks Runtime 7.0. A versão 3.0.0 inclui mais de 3.400 patches e é o resultado de enormes contribuições da comunidade de código aberto, trazendo grandes avanços nos recursos de Python e SQL e um foco na facilidade de uso tanto para exploração quanto para produção. Essas iniciativas refletem como o projeto evoluiu para atender a mais casos de uso e a públicos mais amplos, com este ano marcando seu 10º aniversário como um projeto de código aberto.
Aqui estão os principais novos recursos do Spark 3.0:
- Melhoria de desempenho de 2x no TPC-DS em relação ao Spark 2.4, possibilitada por execução adaptativa de query, eliminação dinâmica de partições e outras otimizações
- compliance com ANSI SQL
- Melhorias significativas nas APIs do pandas, incluindo dicas de tipo do Python e UDFs adicionais do pandas
- Melhor tratamento de erros em Python, simplificando as exceções do PySpark
- Nova UI para transmissão estructurada
- Aceleração de até 40x para chamar funções definidas pelo usuário em R
- Mais de 3.400 tickets do Jira resolvidos
Não são necessárias grandes alterações de código para adotar esta versão do Apache Spark. Para mais informações, consulte o guia de migração.
Comemorando 10 anos de desenvolvimento e evolução do Spark
O Spark começou no AMPlab da UC Berkeley, um laboratório de pesquisa focado em computação intensiva de dados. Os pesquisadores do AMPlab estavam trabalhando com grandes empresas de escala de internet em seus problemas de dados e IA, mas perceberam que esses mesmos problemas também seriam enfrentados por todas as empresas com volumes de dados grandes e crescentes. A equipe desenvolveu um novo mecanismo para lidar com essas cargas de trabalho emergentes e, ao mesmo tempo, tornar as APIs para trabalhar com big data significativamente mais acessíveis para os desenvolvedores.
As contribuições da comunidade surgiram rapidamente para expandir o Spark para diferentes áreas, com novos recursos em torno de transmissão, Python e SQL, e esses padrões agora compõem alguns dos casos de uso dominantes do Spark. Esse investimento contínuo trouxe o Spark para onde ele está hoje, como o mecanismo de fato para cargas de trabalho de processamento de dados, ciência de dados, machine learning e análise de dados. O Apache Spark 3.0 dá continuidade a essa tendência, melhorando significativamente o suporte para SQL e Python — as duas linguagens mais usadas com o Spark hoje — bem como com otimizações de desempenho e operabilidade em todo o restante do Spark.
Melhorando o mecanismo Spark SQL
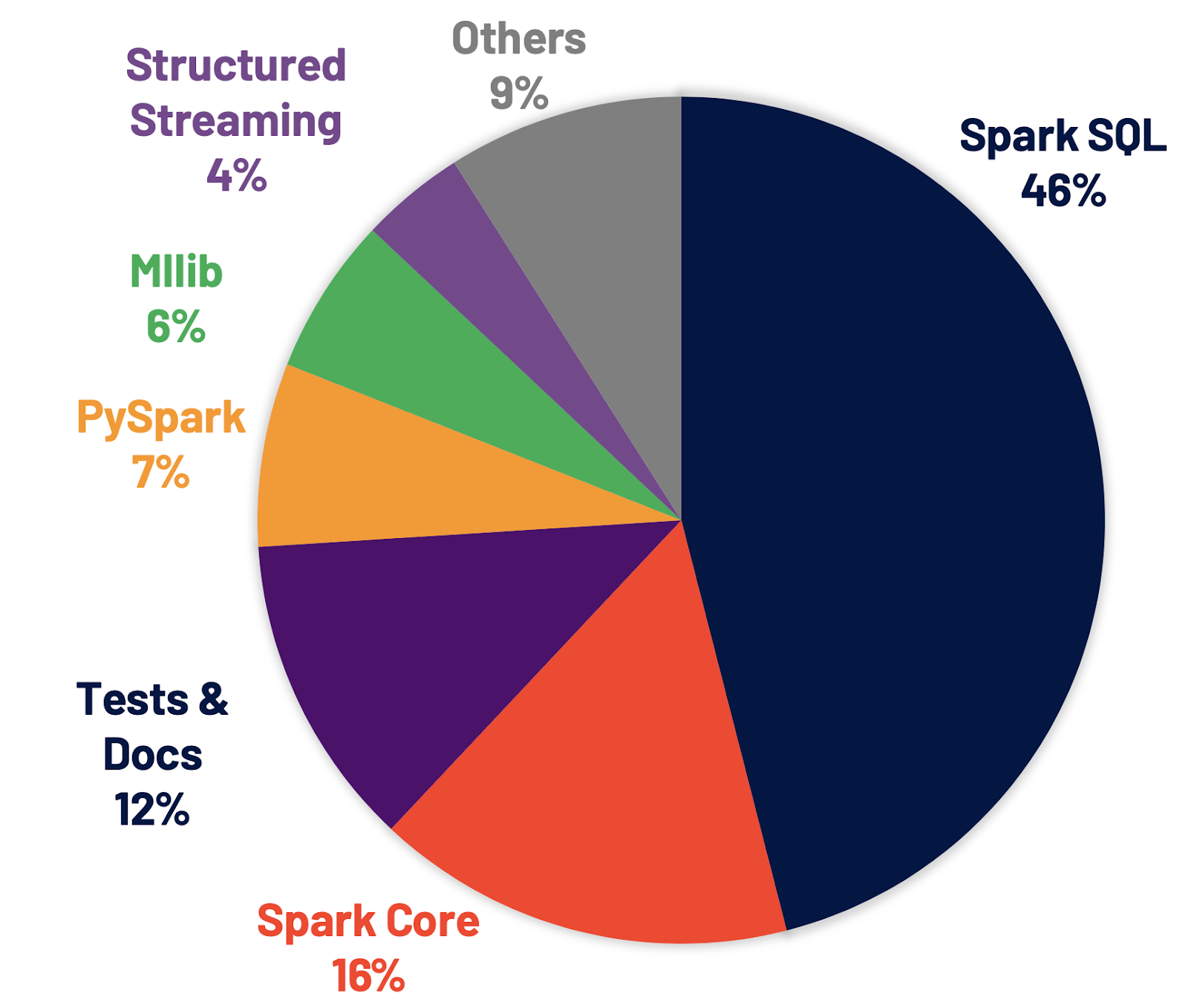
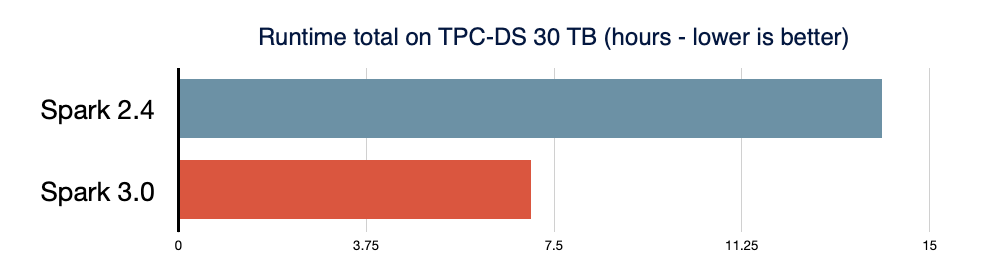
O Spark SQL é o mecanismo que sustenta a maioria das aplicações Spark. Por exemplo, no Databricks, descobrimos que mais de 90% das chamadas da API do Spark usam as APIs DataFrame, dataset e SQL, além de outras bibliotecas otimizadas pelo otimizador SQL. Isso significa que até mesmo os desenvolvedores de Python e Scala passam grande parte de seu trabalho pelo mecanismo Spark SQL. No lançamento do Spark 3.0, 46% de todos os patches contribuídos foram para o SQL, melhorando tanto o desempenho quanto a compatibilidade com o ANSI. Conforme ilustrado abaixo, o Spark 3.0 teve um desempenho aproximadamente 2x melhor que o Spark 2.4 no tempo total de Runtime. A seguir, explicamos quatro novos recursos no mecanismo Spark SQL.
O novo framework de Execução de query Adaptativa (AQE) melhora o desempenho e simplifica o ajuste, gerando um plano de execução melhor em Runtime, mesmo que o plano inicial não seja o ideal devido a estatísticas de dados ausentes/imprecisas e custos mal estimados. Devido à separação de armazenamento e computação no Spark, a chegada de dados pode ser imprevisível. Por todos esses motivos, a adaptabilidade em Runtime torna-se mais crítica para o Spark do que para os sistemas tradicionais. Este lançamento apresenta três otimizações adaptativas principais:
- A aglutinação dinâmica de partições de shuffle simplifica ou até mesmo evita o ajuste do número de partições de shuffle. Os usuários podem definir um número relativamente grande de partições de embaralhamento no início, e o AQE pode então combinar pequenas partições adjacentes em maiores em Runtime.
- A troca dinâmica de estratégias de junção evita parcialmente a execução de planos subótimos devido a estatísticas ausentes e/ou estimativas de tamanho incorretas. Essa otimização adaptativa pode converter automaticamente sort-merge join em broadcast-hash join em Runtime, simplificando ainda mais o ajuste e melhorando o desempenho.
- A otimização dinâmica de skew joins é outro aprimoramento de desempenho essencial, já que skew joins podem levar a um desequilíbrio extremo de trabalho e degradar severamente o desempenho. Depois que o AQE detecta qualquer assimetria a partir das estatísticas do arquivo de 'shuffle', ele pode dividir as partições assimétricas em menores e uni-las com as partições correspondentes do outro lado. Essa otimização pode paralelizar o processamento de 'skew' e alcançar um desempenho geral melhor.
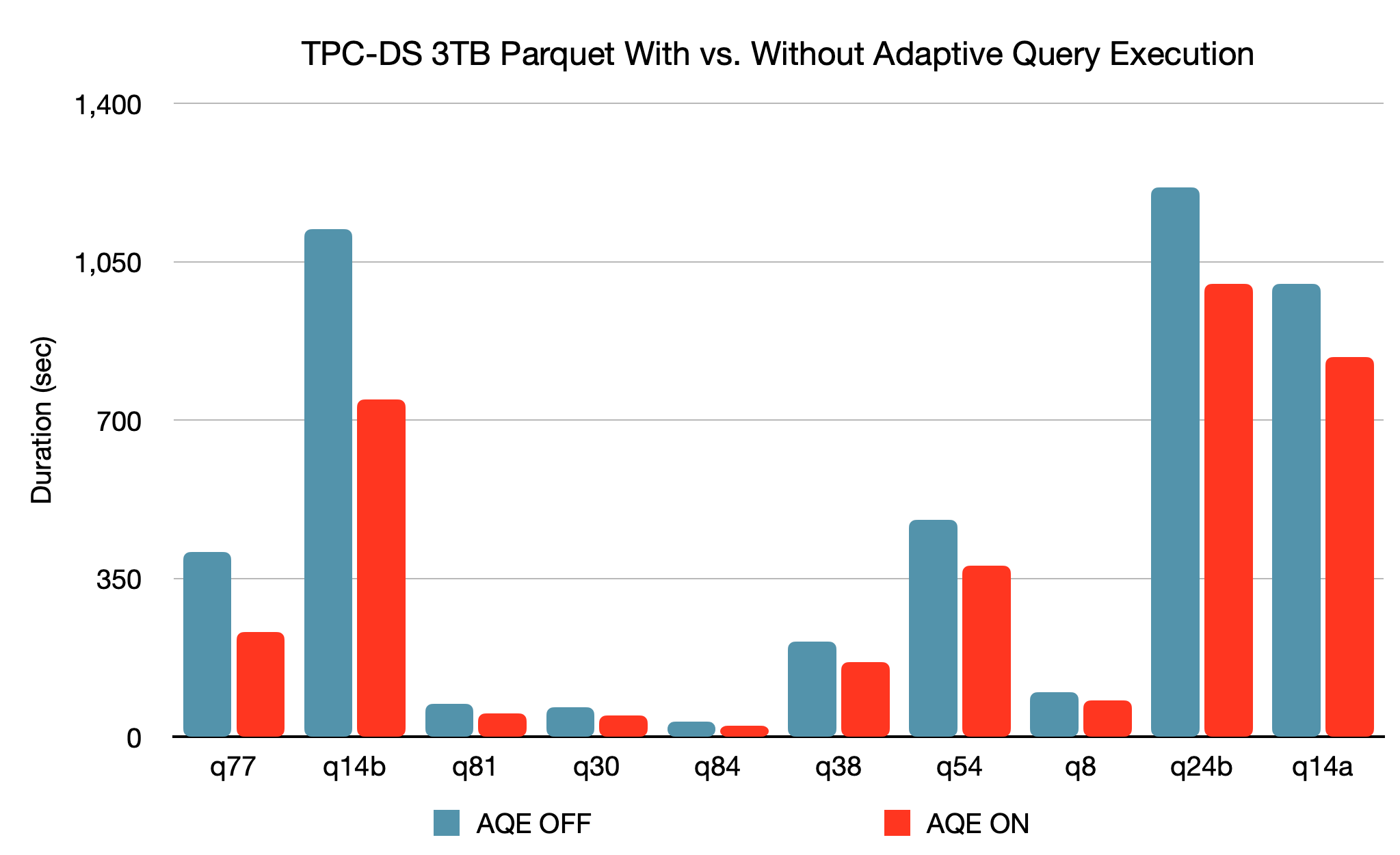
Com base em um benchmark TPC-DS de 3 TB, em comparação com a execução sem AQE, o Spark com AQE pode proporcionar acelerações de desempenho de mais de 1,5x para duas consultas e de mais de 1,1x para outras 37 consultas.
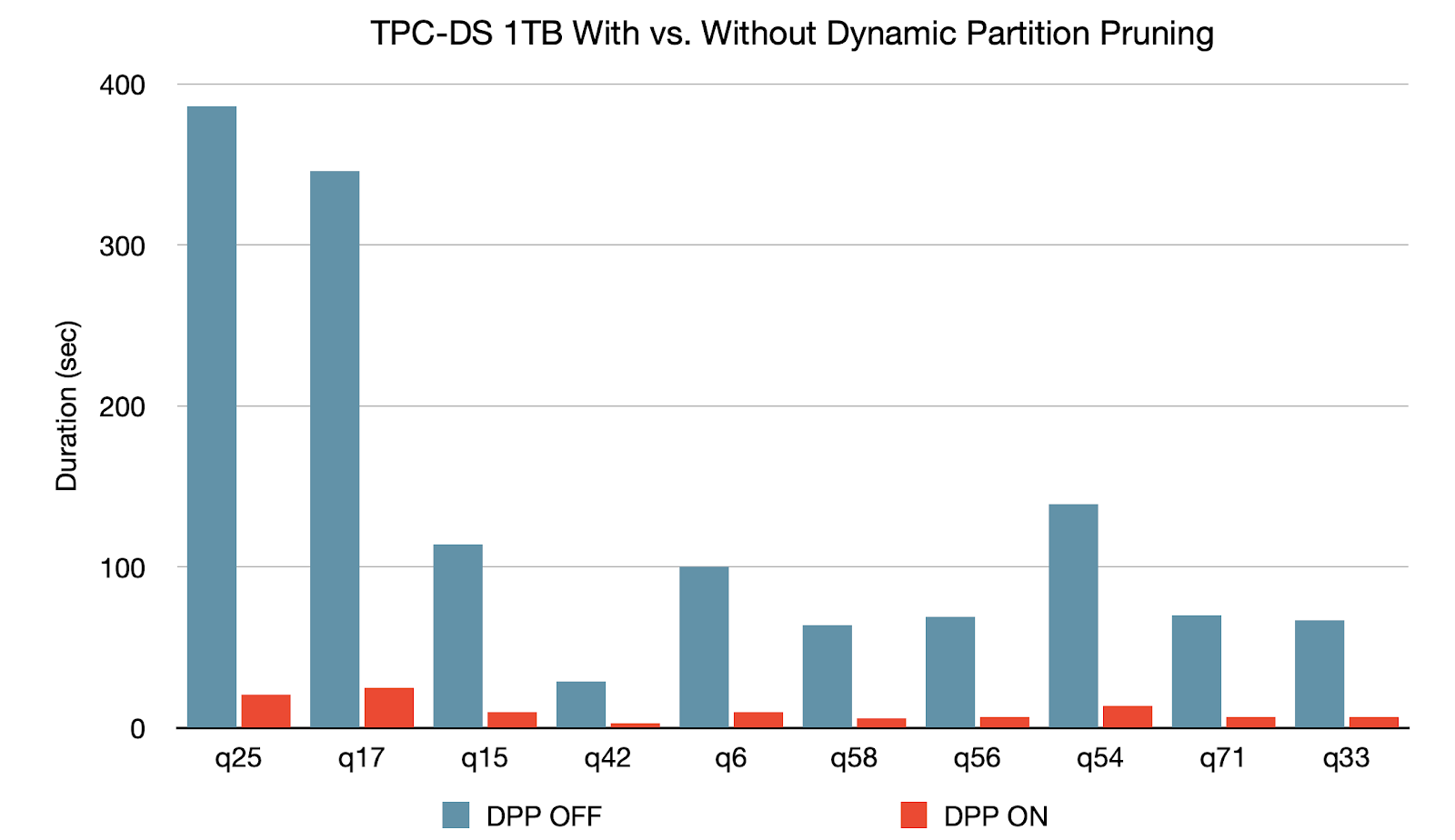
Dynamic Partition Pruning é aplicado quando o otimizador não consegue identificar em tempo de compilação as partições que pode ignorar. Isso não é incomum em esquemas estrela, que consistem em uma ou várias tabelas de fatos que fazem referência a qualquer número de tabelas de dimensão. Nessas operações de join, podemos podar as partições que o join lê de uma tabela de fatos, identificando as partições que resultam da filtragem das tabelas de dimensão. Em um benchmark TPC-DS, 60 de 102 queries mostram uma aceleração significativa entre 2x e 18x.
A compliance com ANSI SQL é fundamental para a migração de cargas de trabalho de outros mecanismos SQL para o Spark SQL. Para melhorar a compliance, esta versão muda para o calendário gregoriano proléptico e também permite que os usuários proíbam o uso das palavras-chave reservadas do ANSI SQL como identificadores. Além disso, introduzimos a verificação de overflow em Runtime em operações numéricas e a imposição de tipo em tempo de compilação ao inserir dados em uma tabela com um esquema predefinido. Essas novas validações melhoram a qualidade dos dados.
Dicas de join: embora continuemos a aprimorar o compilador, não há garantia de que ele sempre possa tomar a decisão ideal em todas as situações — a seleção do algoritmo de join é baseada em estatísticas e heurísticas. Quando o compilador não consegue fazer a melhor escolha, os usuários podem usar dicas de join para influenciar o otimizador a escolher um plano melhor. Esta versão estende as dicas de join existentes, adicionando novas dicas: SHUFFLE_MERGE, SHUFFLE_HASH e SHUFFLE_REPLICATE_NL.
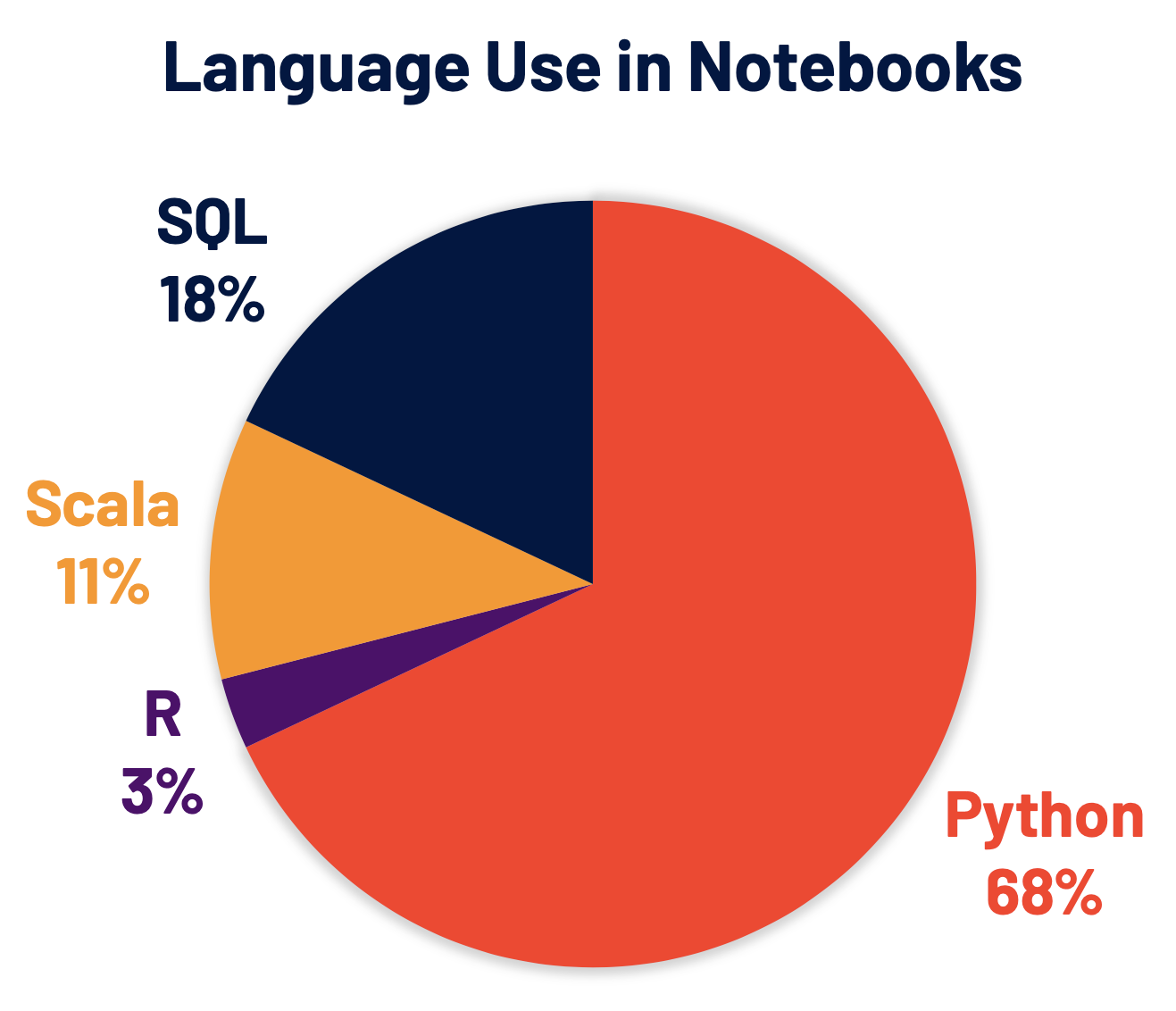
O Python agora é a linguagem mais usada no Spark e, consequentemente, foi uma área de foco principal do desenvolvimento do Spark 3.0. 68% dos comandos de notebook no Databricks são em Python. O PySpark, a API Python do Apache Spark, tem mais de 5 milhões de downloads mensais no PyPI, o Python Package Index.
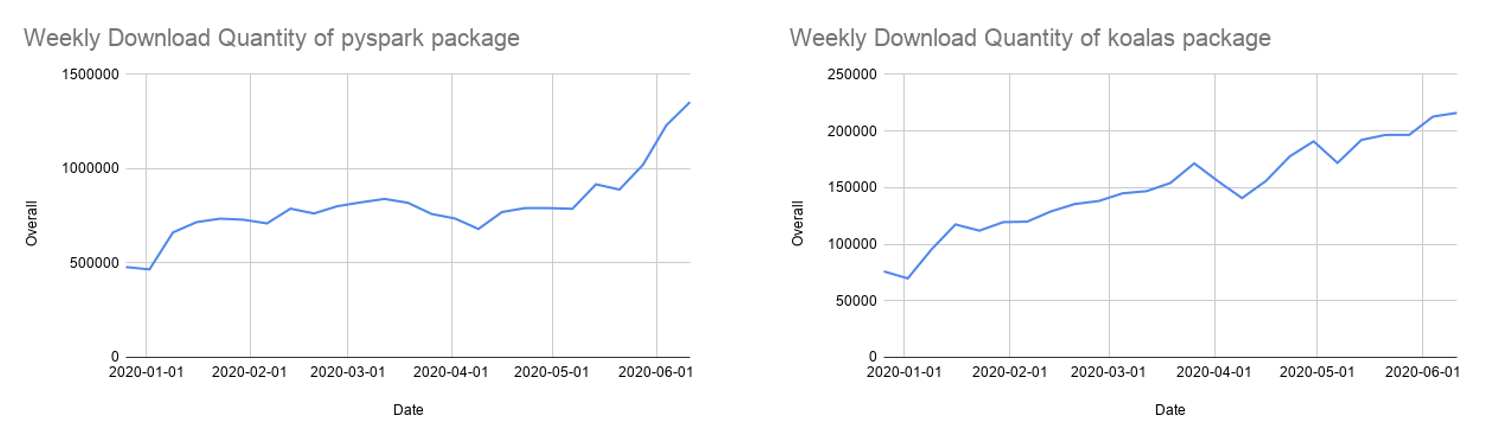
Muitos desenvolvedores Python usam a API do pandas para estruturas de dados e análise de dados, mas ela é limitada ao processamento em um único nó. Também continuamos a desenvolver o Koalas, uma implementação da API do pandas no Apache Spark, para tornar os data scientists mais produtivos ao trabalhar com big data em ambientes distribuídos. O Koalas elimina a necessidade de criar muitas funções (por exemplo, suporte para plotagem) no PySpark para obter um desempenho eficiente em um cluster.
Após mais de um ano de desenvolvimento, a cobertura da API do Koalas para pandas é de quase 80%. Os downloads mensais do Koalas no PyPI cresceram rapidamente para 850.000, e o Koalas está evoluindo rapidamente com uma cadência de lançamento quinzenal. Embora o Koalas possa ser a maneira mais fácil de migrar do seu código pandas de nó único, muitos ainda usam as APIs do PySpark, que também estão crescendo em popularidade.
O Spark 3.0 traz várias melhorias para as APIs do PySpark:
- Novas APIs do pandas com dicas de tipo: as UDFs do pandas foram introduzidas inicialmente no Spark 2.3 para dimensionar funções definidas pelo usuário no PySpark e integrar as APIs do pandas em aplicações PySpark. No entanto, a interface existente é difícil de entender quando mais tipos de UDF são adicionados. Este lançamento introduz uma nova interface UDF do pandas que aproveita as dicas de tipo do Python para lidar com a proliferação de tipos de UDF do pandas. A nova interface se torna mais pythônica e autodescritiva.
- Novos tipos de UDFs do pandas e APIs de função do pandas: Este lançamento adiciona dois novos tipos de UDF do pandas, iterador de séries para iterador de séries e iterador de várias séries para iterador de séries. É útil para a pré-busca de dados e inicializações caras. Além disso, duas novas APIs de função pandas, map e co-grouped map, foram adicionadas. Mais detalhes estão disponíveis nesta postagem no blog.
- Melhor tratamento de erros: o tratamento de erros do PySpark nem sempre é amigável para os usuários de Python. Esta versão simplifica as exceções do PySpark, oculta o stack trace da JVM desnecessário e as torna mais Pythônicas.
Melhorar o suporte e a usabilidade do Python no Spark continua a ser uma das nossas maiores prioridades.
Hydrogen, transmissão e extensibilidade
Com o Spark 3.0, concluímos os principais componentes do Project Hydrogen, bem como introduzimos novos recursos para melhorar a transmissão e a extensibilidade.
- Agendamento com reconhecimento de acelerador: o Projeto Hydrogen é uma importante iniciativa do Spark para unificar melhor a aprendizagem profunda e o processamento de dados no Spark. GPUs e outros aceleradores têm sido amplamente utilizados para acelerar cargas de trabalho de aprendizagem profunda. Para que o Spark aproveite os aceleradores de hardware nas plataformas de destino, esta versão aprimora o programador existente para que o gerenciador de cluster reconheça os aceleradores. Os usuários podem especificar aceleradores por meio da configuração com a ajuda de um script de descoberta. Os usuários podem então chamar as novas APIs RDD para aproveitar esses aceleradores.
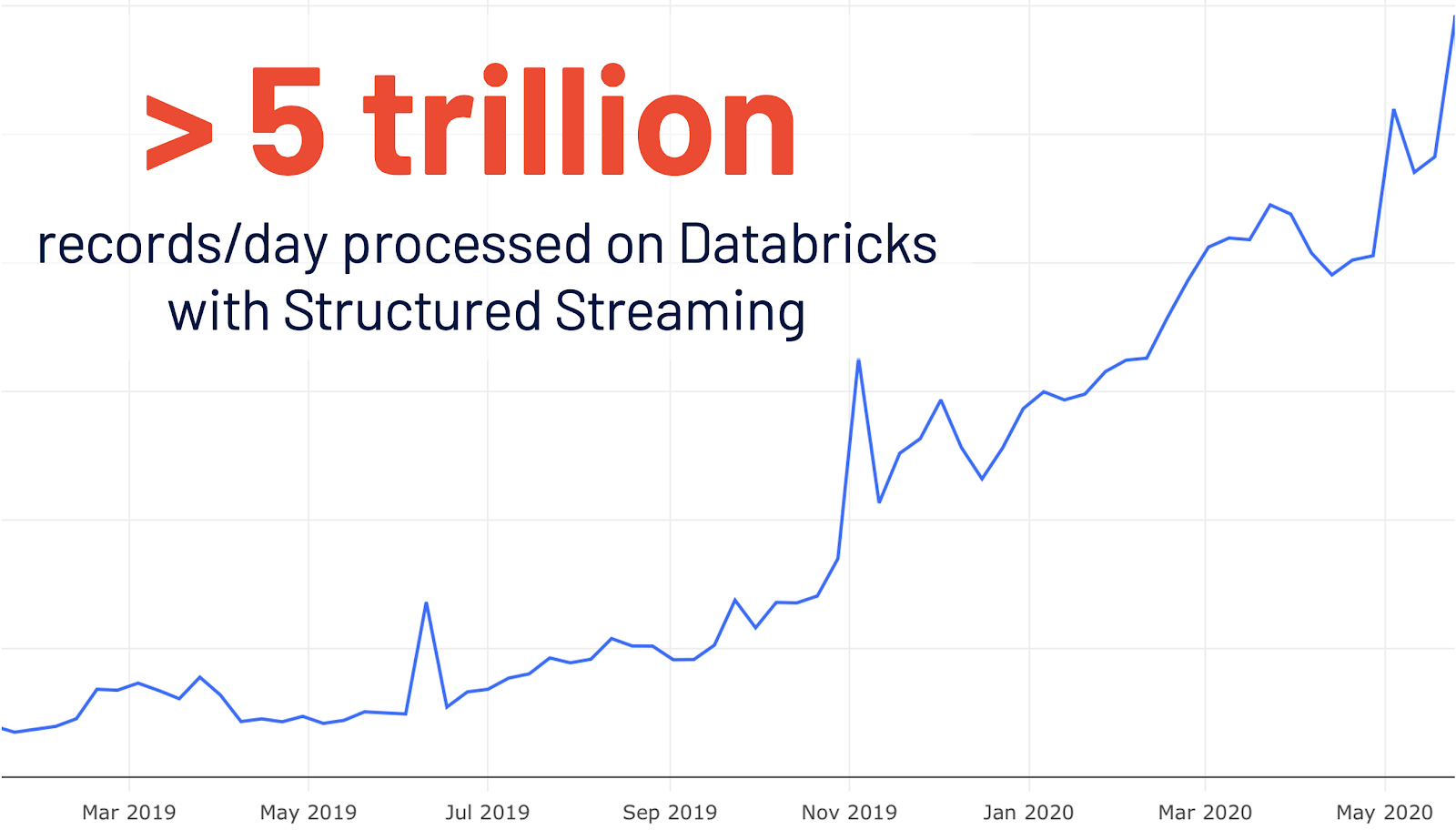
- Nova UI para transmissão estructurada: a transmissão estructurada foi introduzida inicialmente no Spark 2.0. Após um crescimento de 4x ano a ano no uso do Databricks, mais de 5 trilhões de registros por dia são processados no Databricks com transmissão estructurada. Este lançamento adiciona uma nova UI do Spark dedicada para a inspeção desses Jobs de transmissão. Esta nova UI oferece dois conjuntos de estatísticas: 1) informação agregada dos Jobs de query de transmissão concluídos e 2) informação estatística detalhada sobre as queries de transmissão.
- Métricas observáveis: o monitoramento contínuo de alterações na qualidade dos dados é um recurso altamente desejável para gerenciar pipelines de dados. Esta versão introduz o monitoramento para aplicações em lote e de transmissão. Métricas observáveis são funções de agregação arbitrárias que podem ser definidas em uma query (DataFrame). Assim que a execução de um DataFrame atinge um ponto de conclusão (por exemplo, conclui a query de lotes ou atinge a época de transmissão), um evento nomeado é emitido contendo as métricas dos dados processados desde o último ponto de conclusão.
- Nova API de plug-in de catálogo: A API de fonte de dados existente não tem a capacidade de acessar e manipular os metadados de fontes de dados externas. Esta versão enriquece a API V2 de fonte de dados e introduz a nova API de plug-in de catálogo. Para fontes de dados externas que implementam tanto a API de plug-in de catálogo quanto a API V2 de fonte de dados, os usuários podem manipular diretamente os dados e os metadados de tabelas externas por meio de identificadores de várias partes, depois que o catálogo externo correspondente for registrado.
Outras atualizações no Spark 3.0
O Spark 3.0 é um grande lançamento para a comunidade, com mais de 3.400 tickets do Jira resolvidos. É o resultado das contribuições de mais de 440 colaboradores, incluindo pessoas físicas e empresas como Databricks, Google, Microsoft, Intel, IBM, Alibaba, Facebook, Nvidia, Netflix, Adobe e muitas outras. Destacamos vários dos principais avanços em SQL, Python e transmissão no Spark nesta postagem do blog, mas há muitos outros recursos neste marco 3.0 que não foram abordados aqui. Saiba mais nas notas sobre a versão e descubra todas as outras melhorias no Spark, incluindo fontes de dados, ecossistema, monitoramento e muito mais.
Comece a usar o Spark 3.0 hoje
Se você quiser experimentar o Apache Spark 3.0 no Databricks Runtime 7.0, inscreva-se para uma account de trial grátis e comece a usar em minutos. Usar o Spark 3.0 é tão simples quanto selecionar a versão “7.0” ao iniciar um cluster.
Saiba mais sobre os detalhes do recurso e da versão:
- O’Reilly's New Learning Spark, 2nd Edition download gratuito do ebook
- blog sobre a Execução de query Adaptativa
- UDFs do Pandas e dicas de tipo do Python blog
- Preview do Spark 3.0 webinar sob demanda
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.