O que é virtualização de dados?
Acesse e consulte dados de múltiplas fontes sem precisar movê-los ou replicá-los fisicamente, criando uma camada virtual unificada.
- Compreenda o que é virtualização de dados e como ela abstrai o acesso a dados em sistemas distintos por meio de uma interface unificada.
- Aprenda como a virtualização reduz a movimentação de dados, simplifica a arquitetura e fornece acesso em tempo real a fontes de dados distribuídas.
- Descubra casos de uso, incluindo consultas federadas, integração com sistemas legados e análises ágeis sem processos ETL complexos.
O que é virtualização de dados?
A virtualização de dados é um método de integração de dados que permite que as organizações criem exibições unificadas de informações de múltiplas fontes de dados sem mover ou copiar fisicamente os dados. Como uma tecnología central de virtualização de dados, essa abordagem para a gestão de dados permite que os consumidores de dados acessem informações de sistemas díspares por meio de uma única camada virtual. Em vez de extrair dados para um repositório central, a virtualização de dados coloca uma camada abstrata entre os consumidores de dados e os sistemas de origem. Os usuários fazem query nesta camada por meio de uma única interface, enquanto os dados subjacentes permanecem em sua localização original.
A virtualização de dados soluciona um desafio fundamental na gestão de dados moderna: os dados corporativos estão espalhados por múltiplas fontes, incluindo bancos de dados, data lakes, aplicações em cloud e sistemas legados. As soluções tradicionais de integração de dados exigem a construção de pipelines complexos para mover os dados para um warehouse central antes que a análise possa começar. A virtualização de dados elimina esse atraso, proporcionando acesso em tempo real onde as informações estiverem armazenadas.
O interesse pela virtualização de dados acelera à medida que as organizações adotam ambientes multi-cloud, arquiteturas lakehouse e o compartilhamento de dados entre organizações. Essas tendências multiplicam o número de fontes que as equipes precisam acessar, tornando a consolidação física cada vez mais impraticável. A virtualização de dados oferece uma maneira de unificar o acesso sem unificar o armazenamento.
A tecnologia de virtualização de dados cria uma camada de virtualização que se encontra entre os consumidores de dados e os sistemas de origem. Essa camada virtual permite que os usuários corporativos executem queries de dados em data lakes, data warehouses e serviços de armazenamento em cloud sem ter que entender as complexidades técnicas de cada fonte. Ao implementar a virtualização de dados, as organizações permitem que suas equipes combinem dados de diversas fontes em tempo real, mantendo uma governança centralizada.
Existe um ponto de confusão que precisa ser esclarecido: a virtualização de dados e a visualização de dados parecem semelhantes, mas resolvem problemas totalmente diferentes. A virtualização de dados é uma tecnología de integração que cria camadas de acesso em fontes distribuídas. A visualização de dados é uma tecnología de apresentação que renderiza informações na forma de tabelas, gráficos e painéis para o Business Intelligence. Os dois são complementares: a virtualização de dados fornece um acesso unificado que as ferramentas de visualização podem exibir em formatos legíveis por humanos.
Para organizações que buscam uma gestão ágil de dados, a virtualização de dados oferece um entendimento mais rápido, sem a sobrecarga de infraestrutura das soluções tradicionais.
Crosslink: processos ETL e estratégias de integração de dados
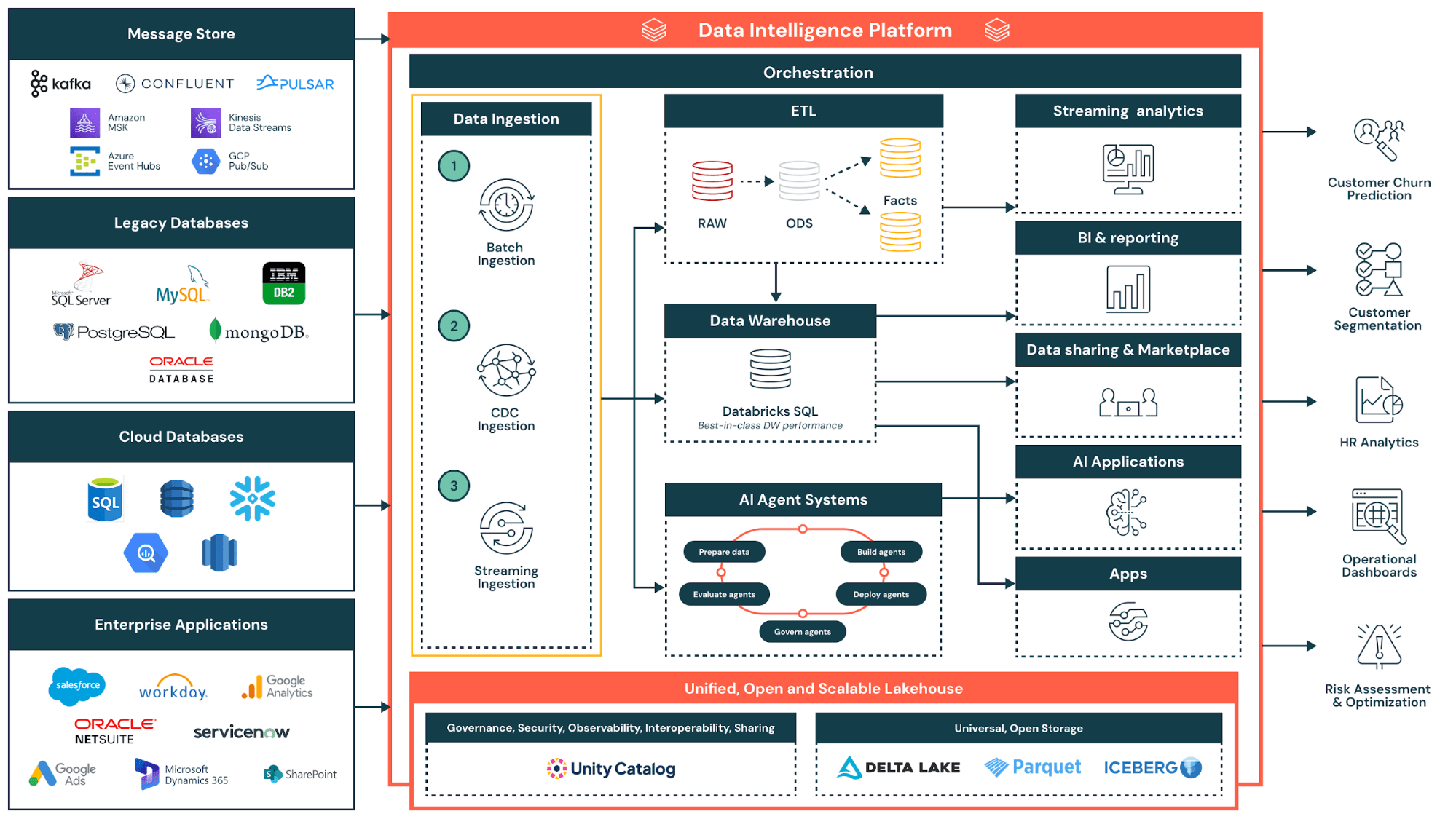
Como funciona a virtualização de dados: arquitetura e componentes
A arquitetura da virtualização de dados depende de três componentes centrais da infraestrutura da gestão de dados: uma camada semântica de dados para definições de negócios, uma camada de virtualização para a federação de queries e a gestão de metadados para governança. Plataformas modernas integram esses componentes para criar ambientes virtuais completos de dados, onde cientistas de dados, usuários de negócios e consumidores de dados podem acessar fontes e serviços de dados sem saber onde as informações estão armazenadas.
A camada de virtualização fica entre os consumidores de dados (como analistas, aplicativos e ferramentas de BI) e as fontes de dados subjacentes. Essa camada mantém metadados sobre onde os dados residem, como estão estruturados e como acessá-los. A camada em si não armazena dados, ela funciona como um mecanismo inteligente de roteamento e tradução. Soluções de governança como o Unity Catalog podem gerenciar esses metadados de forma centralizada, fornecendo um ponto único de controle para políticas de descoberta e acesso.
Quando um usuário envia uma query, o mecanismo de virtualização de dados determina quais fontes de dados contêm as informações relevantes. Ele traduz a query para a linguagem nativa de cada sistema, seja SQL para bancos de dados relacionais, chamadas de API para aplicativos em cloud ou protocolos de acesso a arquivos para data lakes. Em seguida, o mecanismo reúne a solicitação entre os sistemas e os resultados em uma resposta unificada.
A virtualização de dados permite a federação de queries, que descreve esse modelo de execução distribuída. Queries complexas se dividem em sub-queries, cada uma direcionada para a fonte apropriada. Os resultados retornam à camada de virtualização, que os une e os transforma antes de fornecer uma única resposta ao usuário. A Lakehouse Federation, por exemplo, permite aos usuários a execução de queries em bancos de dados externos, warehouses e aplicativos em cloud diretamente do lakehouse sem primeiro migrar os dados. A otimização do desempenho acontece por meio de técnicas como o predicate pushdown, em que a lógica de filtragem é executada na origem e não centralmente.
As plataformas modernas também implementam o join pushdown, a poda de colunas e o armazenamento inteligente em cache. Quando as fontes têm tempos de resposta variáveis, o mecanismo executa consultas em paralelo e aplica o gerenciamento de tempo limite para evitar que fontes lentas bloqueiem os resultados. Essas otimizações ajudam as queries virtualizadas a se aproximarem do desempenho das queries em dados fisicamente consolidados.
A virtualização de dados nativa da Lakehouse oferece uma vantagem adicional: governança unificada tanto para dados federados quanto para dados internos. Com o Unity Catalog gerenciando as políticas de acesso, as organizações aplicam as mesmas regras de segurança a bancos de dados externos e tabelas do lakehouse. Os usuários podem executar query em dados virtualizados e físicos na mesma instrução SQL, sem precisar gerenciar sistemas ou permissões separados.
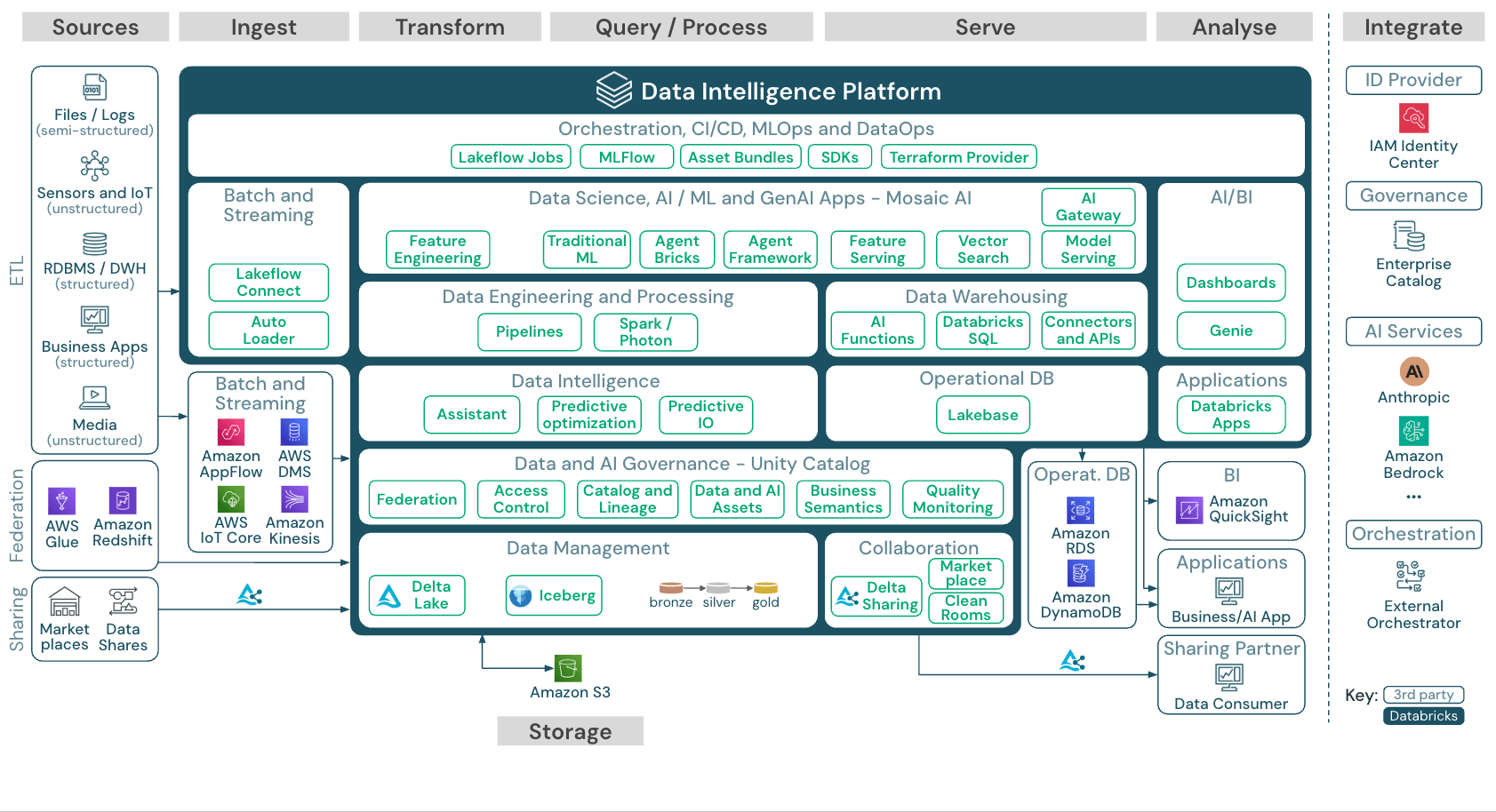
Virtualização de dados x ETL: diferenças-chave
O ETL tradicional (extrair, transformar, carregar) move fisicamente os dados dos sistemas de origem para um repositório ou warehouse centralizado. Isso cria cópias, introduz latência entre os ciclos de extração e exige manutenção contínua do pipeline. A virtualização de dados adota a abordagem oposta: os dados permanecem no mesmo local e são acessados sob demanda.
Cada abordagem soluciona diferentes casos de uso. Veja as principais diferenças:
Movimentação de dados: o processo ETL copia os dados para um repositório central. A virtualização de dados realiza queries aos dados diretamente no local, sem criar duplicados.
Atualização dos dados: ETL entrega dados tão atuais quanto o último ciclo de refresh, que pode ter horas ou dias de idade. A virtualização de dados fornece acesso em tempo real aos dados de origem ao vivo.
Tempo para obter percepções: o processo ETL exige a construção de pipelines antes que a análise possa começar, o que geralmente leva semanas ou meses. A virtualização de dados proporciona acesso imediato assim que as conexões são configuradas.
Transformações complexas: o ETL se destaca no processamento em várias etapas e na análise histórica. A virtualização de dados gerencia joins e filtros, mas tem dificuldade com lógicas de transformações complexas.
A maioria das organizações usa as duas abordagens em conjunto. O ETL e o ELT gerenciam transformações complexas, tendências históricas e cargas de trabalho em lotes essenciais para o desempenho. A virtualização de dados fornece acesso ágil e em tempo real para análises ad hoc e painéis operacionais. A escolha depende das características da carga de trabalho e não da ideologia.
Crosslink: Unity Catalog para padrões unificados de governança e arquitetura de dados
Principais benefícios: acesso em tempo real sem movimento de dados
A justificativa comercial para a virtualização de dados é baseada na velocidade, na redução de custos e na simplificação da governança. A virtualização de dados permite que as organizações reduzam os custos de armazenamento, melhorem o acesso aos dados para usuários corporativos e simplifiquem a infraestrutura em fontes distintas.
1. Redução nos custos de armazenamento e infraestrutura
A virtualização de dados gera valor imediato por meio da redução dos custos de replicação de dados. Eliminar a duplicação significa que as organizações param de pagar para armazenar várias cópias da mesma informação em warehouses, marts e ambientes analíticos. A economia de armazenamento aumenta à medida que os volumes crescem e as equipes evitam a complexidade da infraestrutura de manter cópias sincronizadas.
2. Percepções quase em tempo real para consumidores de dados
As queries atingem sistemas ativos em vez de cópias desatualizadas do warehouse. Por exemplo, empresas de serviços financeiros utilizam essa capacidade para a detecção de fraudes; os varejistas acompanham o estoque entre canais conforme as transações ocorrem; e os sistemas de saúde podem acessar prontuários atuais dos pacientes durante os episódios de atendimento. A analítica em tempo real torna-se possível sem a necessidade de construir pipelines de transmissão.
3. Infraestrutura simplificada
Ao implementar a virtualização de dados, as organizações centralizam as regras de acesso, as políticas de segurança e os metadados em uma camada de dados virtual, em vez de replicar a governança em vários sistemas. Os administradores definem as políticas uma única vez, em vez de mantê-las separadamente em cada fonte. Ao serem integradas a uma plataforma lakehouse em vez de implantadas como infraestrutura independente, as equipes evitam gerenciar mais um sistema.
4. Retorno mais rápido do investimento para iniciativas de negócios
Organizações podem reduzir os prazos de entrega de semanas para dias ou horas. A aceleração resulta da eliminação dos meses normalmente necessários para projetar, construir, testar e manter pipelines ETL para cada novo caso de uso analítico.
Esses benefícios se aplicam mais a cenários que envolvem diversas fontes de dados, requisitos que mudam rapidamente e valorizam a atualização dos dados em relação à profundidade histórica.
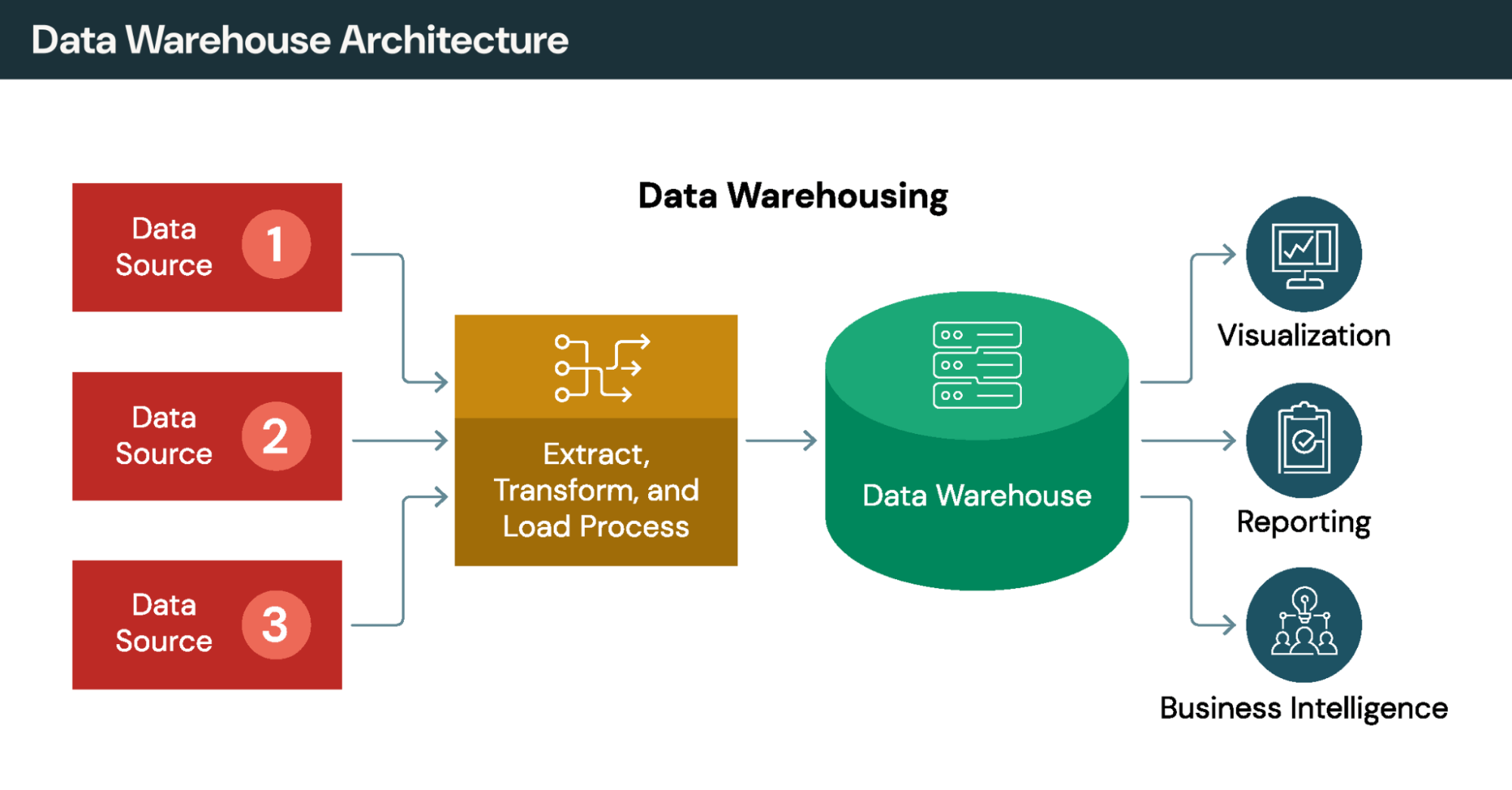
Comparação de abordagens de integração
Os métodos tradicionais de integração, como o ETL, movem fisicamente os dados para repositórios centrais. A virtualização de dados adota outra abordagem: acessar os dados diretamente, sem replicação. As organizações frequentemente combinam ambas as estratégias: ETL para transformações complexas e virtualização de dados para acesso ágil.
Crosslink: capacidades de analítica em tempo real e data warehousing moderno
O manual de IA agêntica para empresas

Casos de uso práticos e aplicações na indústria
A tecnologia de virtualização de dados mostra sua força quando as organizações precisam de acesso unificado em sistemas operacionais, data lakes e aplicações em cloud. A virtualização de dados permite o acesso em tempo real a partir de múltiplas fontes, sem o tempo de espera dos projetos tradicionais de integração de dados. Veja padrões comuns nos exemplos a seguir.
Varejo
Os varejistas operam em plataformas ecommerce, sistemas de lojas físicas, aplicativos de gerenciamento de warehouses, terminais de ponto de venda e redes de fornecedores. A implementação da virtualização de dados cria visibilidade de ponta a ponta da cadeia de suprimentos, fornecendo acesso a vários sistemas sem criar integrações ponto a ponto.
A gestão de inventário beneficia-se principalmente da virtualização de dados em tempo-real. Em vez de sincronizar lotes de contagens de estoque todas as noites, os varejistas fazem queries de dados em tempo real de todos os canais para fornecer níveis precisos de disponibilidade. Isso oferece suporte a funcionalidades como comprar online e retirar na loja, em que os clientes precisam de informações atualizadas sobre o estoque antes de fazerem seus pedidos. Organizações que implementam a virtualização de dados para o acesso à cadeia de suprimentos obtêm economias significativas de custos por meio da redução dos custos de manutenção de estoque e da melhoria na precisão da previsão da demanda.
Serviços financeiros
Empresas de serviços financeiros utilizam soluções de virtualização de dados para agregar dados do cliente obtidos de transações com cartão de crédito, depósitos, sistemas de empréstimo, plataformas CRM e provedores externos, a fim de construir perfis completos dos clientes. A virtualização de dados reúne essas visualizações sob demanda, em vez de manter registros de clientes pré-definidos que se tornam obsoletos entre as atualizações.
A detecção de fraudes em tempo real requer acesso em menos de um segundo aos padrões de transação em todas as contas. Warehouses orientados a lotes não conseguem atender a esse requisito de latência. A compliance regulatória também obtém benefícios: torna-se possível consolidar a geração de relatórios em todos os sistemas, e também manter trilhas de auditoria para revisão pelos auditores.
Cuidados de saúde
Os dados dos pacientes são confidenciais e estão distribuídos em registros eletrônicos de saúde, sistemas de cobrança, arquivos de imagens e sistemas de informações laboratoriais. A virtualização de dados permite que os médicos acessem visualizações unificadas de pacientes durante o atendimento, mantendo os dados em sua origem. Um médico que analisa o histórico de um paciente pode visualizar registros de atendimento primário, consultas com especialistas e resultados de exames laboratoriais em uma única query, mesmo que cada sistema armazene os dados de forma independente.
Essa arquitetura atende aos requisitos de privacidade, pois as informações confidenciais nunca se concentram em um único local vulnerável a violações. Hospitais e sistemas de saúde podem compartilhar o acesso sem a necessidade de transferência física de dados entre organizações, possibilitando um atendimento coordenado.
Quando a virtualização de dados não é a solução ideal
A virtualização de dados tem limitações claras. O processamento em lote de alto volume ainda exige movimentação física; o processamento de milhões de linhas não oferece nenhuma vantagem de desempenho em relação à movimentação de dados uma única vez. Um processador de pagamentos que lida com milhões de transações por hora, por exemplo, não obteria nenhum benefício com a virtualização dessa carga de trabalho. A análise histórica que exige snapshots pontuais precisa de um warehouse que registre o estado ao longo do tempo, já que a virtualização de dados acessa apenas os dados atuais. As transformações complexas de várias etapas excedem as capacidades, que são limitadas a joins, filtros e agregações no estilo de banco de dados.
Implementações de warehouse de grande porte, operações entre data centers e cargas de trabalho que exigem baixa latência garantida normalmente justificam a movimentação física por meio de pipelines de engenharia de dados.
Crosslink: data lakes e aplicações de Business Intelligence
Governança e segurança e considerações de qualidade
A virtualização de dados fortalece a governança ao consolidar o controle em uma camada de virtualização centralizada. As ferramentas de virtualização de dados permitem que os administradores definam as políticas de segurança uma única vez, em vez de gerenciá-las separadamente em fontes distintas.
Os recursos de segurança em plataformas modernas incluem controle de acesso baseado na função, segurança em nível de linha e coluna e mascaramento de dados para campos confidenciais. O controle de acesso baseado em atributos, vinculado a tags de classificação, permite que as políticas acompanhem os dados, independentemente de como os usuários acessem os dados. Independentemente de os analistas se conectarem por meio de SQL queries, APIs REST ou ferramentas de BI, as mesmas regras de segurança se aplicam.
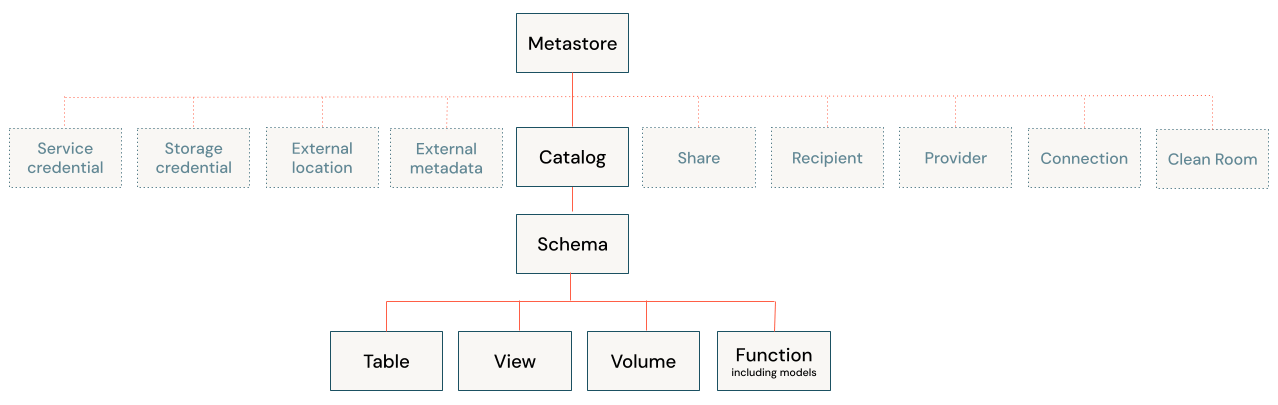
O acompanhamento de auditoria e linhagem captura quem acessou quais dados, quando e de qual aplicativo. O Unity Catalog fornece logs de auditoria em nível de usuário e linhagem em todos os idiomas para relatórios de compliance. Essa visibilidade suporta GDPR, HIPAA, CCPA e regulamentações financeiras que exigem governança demonstrável.
A atualização constante dos dados é inerente à virtualização de dados, uma vez que as queries acessam fontes em tempo real. Mas isso gera algumas considerações sobre a qualidade dos dados: se os sistemas contiverem erros ou inconsistências, a virtualização de dados expõe esses problemas diretamente aos consumidores. Implementações eficazes combinam a virtualização de dados com o monitoramento da qualidade dos dados para garantir a integridade da visualização unificada.
A consistência semântica gera outro desafio. Diferentes sistemas podem usar diferentes nomes para o mesmo conceito, diferentes tipos de dados para campos equivalentes ou definições comerciais alternativas para métricas semelhantes. A camada de virtualização deve impor convenções de nomenclatura consistentes para que os dados do cliente no CRM correspondam ao mesmo cliente no sistema de cobrança, mesmo que cada sistema utilize diferentes rótulos e formatos para os dados. Algumas organizações adicionam uma camada de dados semânticos para definir termos e cálculos de negócios canônicos que se aplicam a todas as fontes virtualizadas, garantindo que os analistas vejam definições consistentes independentemente de qual sistema subjacente armazene os dados.
Crosslink: governança de dados com Unity Catalog e melhores práticas de gestão de dados
Melhores práticas de implementação e seleção de ferramentas
As organizações que implementam a virtualização de dados devem seguir padrões comprovados para garantir uma implantação bem-sucedida. Comece aos poucos: implementações bem-sucedidas frequentemente começam com uma equipe reduzida trabalhando em projetos específicos e de alto valor, sendo expandidas apenas depois de demonstrar valor para as partes interessadas. Defina a governança primeiro estabelecendo propriedade, modelos de segurança e padrões de desenvolvimento antes de implantar a tecnología. Monitore o desempenho regularmente para identificar queries de execução lenta, otimize visualizações virtuais acessadas com frequência e ajuste as conexões conforme os padrões de uso evoluem.
Como é a virtualização de dados na prática: implementação no mundo real
Vejamos este exemplo prático. Uma empresa de varejo quer analisar o valor vitalício do cliente, mas os dados do cliente residem no Salesforce CRM, a história de transações reside em um banco de dados PostgreSQL, o comportamento do site fica no Google Analytics e os dados retornam em um sistema Oracle legado.
A integração de dados tradicional exige a criação de pipelines de ETL para extrair, transformar e carregar todos esses dados em um warehouse. É um projeto que leva meses. Com a virtualização de dados, um administrador cria conexões com cada fonte e publica uma visualização virtual que combina dados entre sistemas. Os analistas fazem queries nessa visualização por meio de SQL familiar ou conectam ferramentas de BI diretamente. Eles veem os dados atuais de todas as fontes em um esquema unificado. Quando a empresa adiciona posteriormente um aplicativo móvel com seu próprio banco de dados, adicionar essa fonte à visualização virtual leva dias, em vez de exigir a reformulação do warehouse.
Esse padrão também é compatível com uma estratégia de "virtualizar primeiro, migrar depois". As equipes começam federando as queries a fontes externas e, em seguida, monitoram quais dados são acessados com mais frequência. Datasets de uso elevado tornam-se candidatos para a migração física para Delta Lake, onde o desempenho das queries melhora e os custos de armazenamento podem diminuir. Os dados de menor utilização permanecem virtualizados, evitando esforços desnecessários de migração.
Avaliando software e ferramentas de virtualização de dados
Ao avaliar ferramentas de virtualização de dados, priorize três critérios.
Suporte à diversidade de fontes: a plataforma se conecta a todas as suas fontes atuais e futuras, incluindo bancos de dados relacionais, aplicativos em cloud, APIs e armazenamento baseado em arquivos? Descubra se ela é compatível com os serviços de dados de que você precisa. As falhas de conectividade forçam você a implementar soluções alternativas que comprometem as promessas da virtualização de dados de acesso unificado.
Recursos de segurança: procure segurança em nível de linha e coluna, mascaramento, criptografia e registros de auditoria abrangentes. Essas capacidades devem ser aplicadas de forma consistente, independentemente de como os usuários acessam os dados virtualizados.
Capacidades de autoatendimento: os usuários comerciais conseguem descobrir e acessar dados virtualizados sem a intervenção da TI para cada solicitação? O valor da virtualização de dados diminui se cada nova query exigir a intervenção de um administrador.
Além desses três critérios, considere os requisitos de desempenho de query, as preferências de modelo de implantação e o custo total de propriedade.
Crosslink: LakeFlow para a integração de dados e capacidades de camada semântica
Conclusão: quando escolher a virtualização de dados
A virtualização de dados é excelente para a analítica operacional em tempo real, exploração periódica de diversas fontes, desenvolvimento de provas de conceito e cenários em que o frescor dos dados é mais importante do que o desempenho da query. A virtualização de dados permite que as organizações acessem dados de várias fontes sem pipelines complexos, enquanto as abordagens tradicionais por meio de warehouses permanecem superiores para transformações complexas, tendências históricas, processamento de lotes de alto volume e cargas de trabalho analíticas críticas para a latência.
A questão não é qual abordagem escolher exclusivamente, mas onde cada uma se encaixa dentro de uma arquitetura abrangente. As organizações cada vez mais implementam ambas as tecnologias: virtualização de dados para acesso ágil e experimentação; e integração física onde exigidas pelas características da carga de trabalho. O padrão "virtualizar primeiro, migrar depois" permite que as equipes entreguem valor imediatamente por meio de queries federadas, enquanto utiliza dados reais de uso para priorizar quais fontes justificam o investimento da migração física para Delta Lake ou outros armazenamentos de lakehouse.
Comece identificando casos de uso em que o acesso em tempo real a dados distribuídos cria um valor comercial claro. Pilote a virtualização de dados, meça os resultados e amplie com base no sucesso demonstrado.
Crosslink: estrutura de decisão ETL x ELT
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.