O que são modelos de aprendizado de máquina?
Algoritmos que aprendem padrões a partir de dados de treinamento para fazer previsões, desde regressão linear e árvores de decisão até redes neurais profundas.
- O processo de treinamento envolve alimentar dados rotulados por meio de algoritmos que ajustam parâmetros internos (pesos, coeficientes) para minimizar o erro de previsão em conjuntos de validação, usando técnicas como descida de gradiente, retropropagação e regularização.
- Os tipos de modelos abrangem aprendizado supervisionado (classificação, regressão), aprendizado não supervisionado (agrupamento, redução de dimensionalidade), aprendizado por reforço e abordagens semissupervisionadas, cada uma adequada para diferentes estruturas de problemas e disponibilidade de dados.
- As métricas de avaliação incluem acurácia, precisão, recall, pontuação F1, AUC-ROC para classificação; MSE, MAE, R² para regressão; e pontuação de silhueta, índice de Davies-Bouldin para agrupamento, orientando a seleção do modelo e o ajuste de hiperparâmetros.
O que é um modelo de machine learning?
Um modelo de machine learning é um programa que descobre padrões e extrai decisões de conjuntos de dados desconhecidos. Por exemplo, no processamento de linguagem natural, os modelos de machine learning podem analisar e reconhecer corretamente a intenção por trás de frases e combinações de palavras anteriormente inaudíveis. O reconhecimento de imagem também pode reconhecer objetos, como carros e cachorros, treinando modelos de machine learning. Os modelos de machine learning podem ser “treinados” em grandes conjuntos de dados para executar tarefas como as descritas acima. No treinamento, os algoritmos de machine learning são otimizados para descobrir padrões e resultados específicos de conjuntos de dados, dependendo da tarefa. A saída desse processo geralmente é um programa de computador com regras e estruturas de dados específicas, chamado de modelo de machine learning.
O que é um algoritmo de machine learning?
Algoritmos de machine learning são técnicas matemáticas para encontrar padrões em conjuntos de dados. Os algoritmos de machine learning geralmente usam conhecimento de estatística, cálculo e álgebra linear, e exemplos típicos incluem regressão linear, árvores de decisão, florestas aleatórias e XGBoost.
Como treinar um modelo em machine learning?
O processo de executar um algoritmo de machine learning em um conjunto de dados chamado dados de treinamento e otimizar o algoritmo para descobrir determinados padrões ou saídas é chamado de treinamento de modelo. A função com as regras resultantes e a estrutura de dados também é chamada de modelo de machine learning treinado.
Quais são os diferentes tipos de machine learning?
As técnicas de machine learning são classificadas principalmente em aprendizado supervisionado, aprendizado não supervisionado e aprendizado por reforço.
O que é aprendizado supervisionado?
No aprendizado supervisionado, os algoritmos são desafiados e otimizados para atender a um conjunto específico de saídas de acordo com um conjunto de dados de entrada. Por exemplo, no reconhecimento de imagens, uma técnica chamada classificação é amplamente utilizada no aprendizado supervisionado. Uma técnica chamada regressão também é usada para prever dados demográficos, como crescimento populacional e estado de saúde.
O que é aprendizado não supervisionado?
No aprendizado não supervisionado, um algoritmo recebe um conjunto de dados de entrada, mas não é recompensado ou otimizado para uma saída específica e é treinado para agrupar objetos no conjunto de dados por características comuns. Por exemplo, o mecanismo de recomendação de uma loja online usa uma técnica de aprendizado não supervisionado chamada clustering.
O que é aprendizado por reforço?
No aprendizado por reforço, o algoritmo se treina por meio de muitas iterações de tentativa e erro. O aprendizado por reforço é obtido fazendo com que o algoritmo interaja continuamente com o ambiente, em vez de depender de dados de treinamento. A direção autônoma é um exemplo típico de aprendizado por reforço.
Quais são os diferentes modelos de machine learning?
Existem muitos modelos de machine learning, a maioria dos quais é baseada em algoritmos específicos. Os algoritmos comuns de classificação e regressão se enquadram no aprendizado supervisionado, enquanto os algoritmos de clustering são utilizados em cenários de aprendizado não supervisionado.
Aprendizado supervisionado
- Regressão logística: a regressão logística é usada para determinar se uma entrada pertence a um determinado grupo.
- Máquina de vetores de suporte (SVM): uma máquina de vetores de suporte cria coordenadas para cada objeto no espaço n-dimensional e usa hiperplanos para agrupar objetos por recursos comuns.
- Naive Bayes: Naive Bayes é um algoritmo que assume independência entre variáveis e usa probabilidades para classificar objetos a partir de recursos.
- Árvores de decisão: uma árvore de decisão é usada como um classificador que determina em qual categoria uma entrada se enquadra, verificando as folhas e os nós em uma árvore.
- Regressão linear: a regressão linear é usada para identificar a relação entre uma variável de interesse e uma entrada e prever seu valor com base nos valores das variáveis de entrada.
- k-Nearest Neighbors (k-NN): k-Nearest Neighbors é uma técnica para agrupar os objetos mais próximos em um conjunto de dados e encontrar o modo ou característica média entre os objetos.
- Floresta aleatória (Random Forest): uma floresta aleatória é uma coleção de muitas árvores de decisão de um subconjunto aleatório de dados, o que pode resultar em melhor precisão de previsão do que uma única árvore de decisão.
- Algoritmos de boosting: algoritmos de boosting, como Gradient Boosting Machine, XGBoost e LightGBM, usam o aprendizado de conjunto. Eles combinam previsões de vários algoritmos, como árvores de decisão, enquanto contabiliza erros com algoritmos anteriores.
Aprendizado não supervisionado
- K-Médias: O algoritmo K-Médias encontra semelhanças entre objetos e os agrupa em clusters K diferentes.
- Clustering hierárquico: o clustering hierárquico cria uma árvore aninhada de agrupamentos. Não é necessário especificar o número de clusters.
O que é uma árvore de decisão em machine learning (ML)?
Uma árvore de decisão é uma técnica de previsão em ML que indica a qual classe um objeto pertence. Como o nome sugere, é um fluxograma semelhante a uma árvore que usa critérios específicos para determinar passo a passo a classe de um objeto. 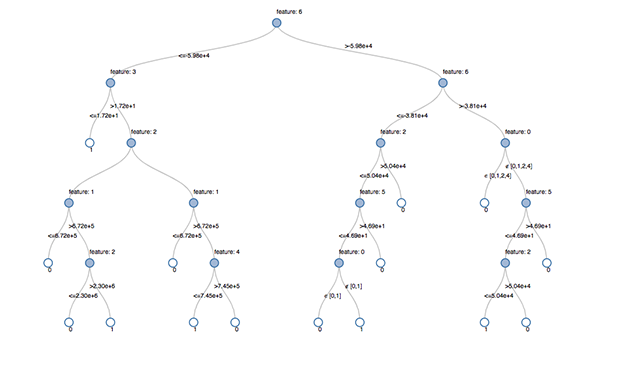 Árvore de decisão visualizada no Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
Árvore de decisão visualizada no Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
O manual de IA agêntica para empresas

O que é regressão em machine learning?
A regressão em data science e machine learning é uma técnica estatística que pode prever resultados com base em um conjunto de variáveis de entrada. O valor resultante geralmente depende da combinação de variáveis de entrada. 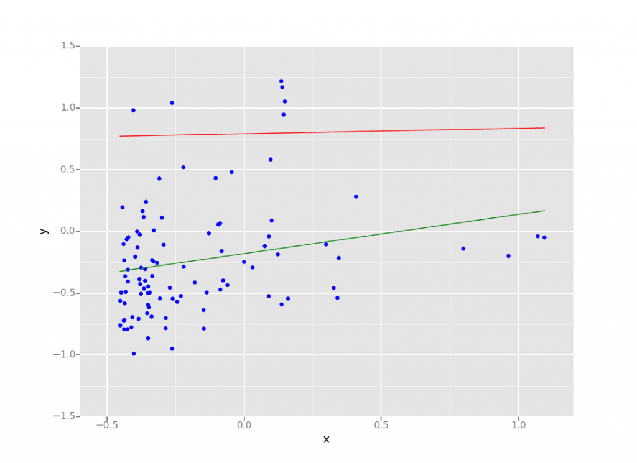 Modelo de regressão linear executado no Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
Modelo de regressão linear executado no Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
O que é um classificador em machine learning?
Um classificador é um algoritmo de machine learning que atribui objetos como membro de uma categoria ou grupo. Por exemplo, os classificadores são usados para detectar se um e-mail é spam ou se uma transação é fraudulenta.
Quantos modelos existem no machine learning?
Muitos! O machine learning é um campo em evolução e diversos modelos são desenvolvidos o tempo todo.
Qual é o melhor modelo para machine learning?
O melhor modelo de machine learning para uma determinada situação depende dos resultados desejados. Por exemplo, ao prever o número de carros comprados em uma determinada cidade a partir de dados anteriores, a técnica de aprendizado supervisionado, como a regressão linear, é considerada a mais eficaz. Por outro lado, uma árvore de decisão pode ser a melhor maneira de identificar se um cliente em potencial que mora em uma cidade compraria um carro com base em sua renda e histórico de deslocamento.
O que é implantação de modelo em machine learning (ML)?
A implantação do modelo refere-se ao processo de disponibilizar um modelo de machine learning em um ambiente de teste ou produção. O modelo geralmente é integrado por meio de APIs com outros aplicativos, como bancos de dados e UI, no ambiente. Após a implantação, as organizações podem realmente ver o retorno de seu investimento significativo no desenvolvimento do modelo. 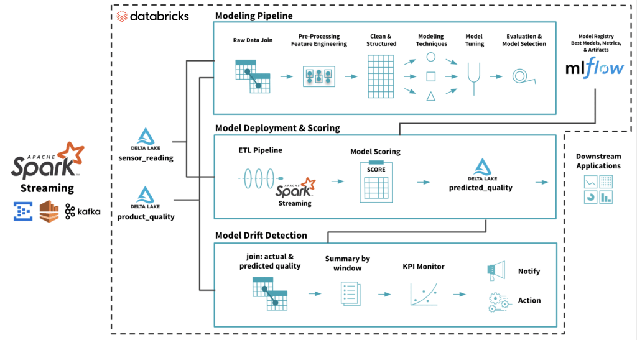 O ciclo de vida completo de um modelo de machine learning no Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
O ciclo de vida completo de um modelo de machine learning no Databricks Lakehouse. Fonte: https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
O que são modelos de deep learning?
Um modelo de deep learning é um tipo de modelo de ML que imita a maneira como os humanos processam informações. O modelo consiste em várias camadas de processamento para extrair recursos de alto nível dos dados fornecidos. Cada camada de processamento transmite uma representação de dados mais abstrata para a próxima camada, e a camada final obtém insights mais semelhantes aos humanos. Ao contrário dos modelos tradicionais de ML, que exigem dados rotulados, os modelos de deep learning podem ingerir grandes quantidades de dados não estruturados, permitindo funções mais semelhantes aos humanos, como reconhecimento facial e processamento de linguagem natural.  Representação simplificada de deep learning. Fonte: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
Representação simplificada de deep learning. Fonte: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
O que é machine learning para séries temporais?
Um modelo de machine learning para séries temporais é um modelo no qual a variável independente contém um período de tempo contínuo (minutos, dias, anos etc.) e está relacionado à variável dependente ou preditora. Os modelos de machine learning para séries temporais são usados para prever eventos relacionados ao tempo, como o clima da próxima semana, o número esperado de clientes do próximo mês e a orientação de receita do próximo ano.
Onde posso aprender mais sobre machine learning?
- Este e-book grátis apresenta muitos casos de uso de machine learning interessantes sendo implantados em empresas em todo o mundo.
- Para obter uma compreensão mais profunda do machine learning com os especialistas, confira os artigos sobre machine learning no blog da Databricks.
Recursos adicionais
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.