O que é uma Plataforma de Funcionalidades?
Infraestrutura para gerenciamento do ciclo de vida de funcionalidades, incluindo engenharia, armazenamento, descoberta, monitoramento e governança, com APIs para criação e disponibilização.
- Os componentes incluem ferramentas de autoria de recursos para definir transformações, sistemas de orquestração para agendar pipelines de computação, camadas de armazenamento para recursos offline e online, APIs de serviço para acesso em tempo real e painéis de monitoramento para acompanhar a qualidade.
- Suporta computação de recursos em lote para treinamento de modelos, atualizações de recursos em fluxo contínuo para sistemas em tempo real, computação de recursos sob demanda durante a inferência e preenchimento retroativo de recursos para experimentos históricos.
- Os recursos avançados abrangem validação de recursos para garantir a qualidade, testes automatizados para pipelines de recursos, infraestrutura de testes A/B para experimentos de recursos e integração com plataformas de aprendizado de máquina para fluxos de trabalho de desenvolvimento de modelos contínuos.
Até dois anos atrás, apenas as grandes empresas de tecnologia possuíam os recursos e a experiência necessários para construir produtos que dependessem totalmente de sistemas de machine learning. Por exemplo, o Google gerenciando leilões de anúncios, o TikTok recomendando conteúdo e o Uber ajustando preços dinamicamente. Para potencializar seus aplicativos mais importantes com machine learning, as equipes criaram uma infraestrutura personalizada que atendeu às necessidades exclusivas de implantar sistemas de machine learning.
Alguns anos depois, surgiu todo um ecossistema de ferramentas de MLOps para democratizar o machine learning na produção. Mas, com centenas de ferramentas diferentes disponíveis, demanda muito tempo para entender o que cada uma delas faz. As plataformas de recursos e suas variantes, os Feature Stores, são uma parte comum desse ecossistema. Resumindo, uma plataforma de recursos habilita sua infraestrutura de dados existente (data warehouses; infraestrutura de transmissão, como Kafka; processadores de dados, como o Spark/Flink; etc.) para aplicações operacionais de ML. Este post explica em mais detalhes o que são plataformas de recursos e quais problemas elas resolvem.
Criar um machine learning operacional é complexo
Plataformas de recursos permitem machine learning operacional (ML), que ocorre quando uma aplicação voltada para o cliente usa ML para tomar decisões de forma autônoma e contínua que impactam o negócio em tempo real. Os exemplos que compartilhei do Google, TikTok e Uber são de aplicações operacionais de ML. Todo projeto de machine learning consiste em quatro etapas:
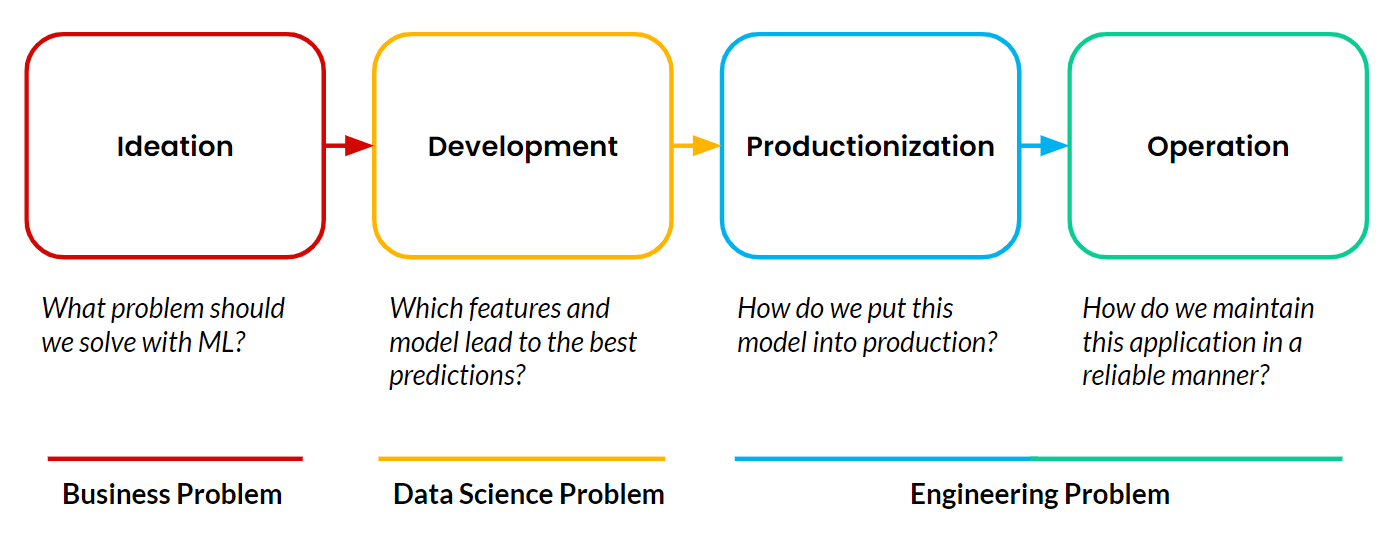
A maioria dos projetos nunca passa da fase de desenvolvimento. A produção e operação de aplicações de machine learning continuam sendo o principal obstáculo para as equipes. E a parte mais difícil de produzir e operar ML é gerenciar os pipelines de dados que precisam alimentar continuamente essas aplicações.
Uma plataforma de recursos resolve os desafios de dados associados à produção e operação. Isso possibilita a produção. Explicaremos melhor o que isso significa, mas primeiro vamos descrever o que é um recurso.
O que é um recurso de machine learning?
No machine learning, um recurso são dados usados como entrada para os modelos de ML realizarem previsões. Dados brutos raramente encontram-se em um formato que seja utilizável por um modelo de ML, então precisam ser transformados em recursos. Esse processo é chamado de engenharia de recursos.
Por exemplo, se uma empresa de cartão de crédito tenta detectar transações fraudulentas, uma transação realizada em um país estrangeiro pode ser um bom indicador de fraude. Os recursos acabam se tornando colunas nos dados que são enviados para um modelo.
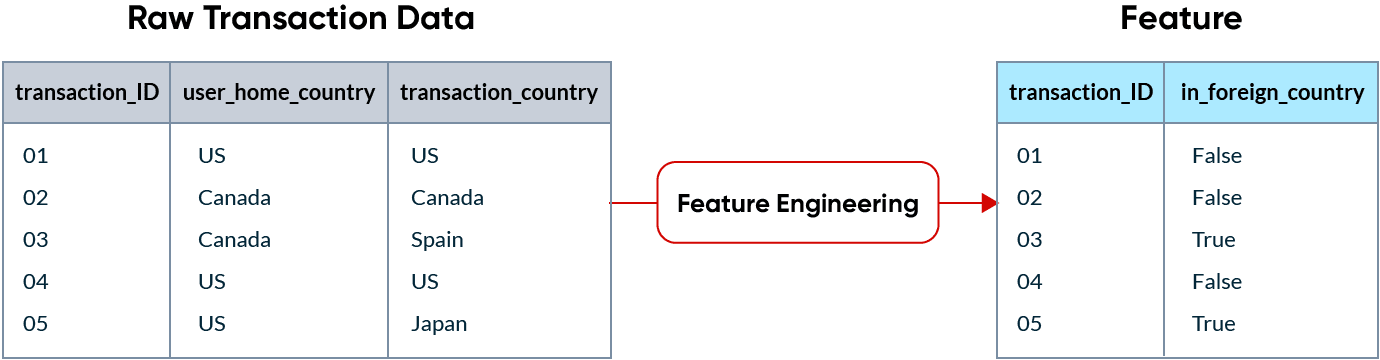
O diferencial do ML é que os recursos são consumidos de duas maneiras diferentes:
- Para ensinar um modelo, precisamos de grandes quantidades de dados históricos.
- Para fazer uma previsão em tempo real, precisamos fornecer ao modelo apenas os recursos mais recentes, no entanto, essas informações precisam ser enviadas em uma questão de milissegundos. Isso também é chamado de inferência online. Neste exemplo, o modelo só precisa saber se a transação atual está em um país estrangeiro ou não, e precisa processar essa informação enquanto a transação está acontecendo.
Quais problemas uma plataforma de recursos pode resolver?
Na fase de desenvolvimento de um projeto de machine learning, os cientistas de dados realizam uma grande quantidade de engenharia de recursos para encontrar os recursos que geram a maior precisão de previsão. Assim que esse processo estiver concluído, eles geralmente repassam o projeto para um colega engenheiro que começará a produzir esses pipelines de engenharia de recursos.
Se você é cientista de dados, você não quer se preocupar com a forma como os dados se tornam disponíveis ou como são computados. Você sabe quais recursos deseja e quer que esses recursos estejam disponíveis para que o modelo faça previsões em tempo real. Por outro lado, os engenheiros precisam reimplementar esses pipelines de dados em um ambiente de produção, o que rapidamente se torna muito complexo se há dados em tempo-real ou quase em tempo real envolvidos. Para impulsionar aplicações operacionais de ML, esses pipelines precisam de uma execução contínua, não podem falhar, precisam ser extremamente rápidos e precisam de crescer com o negócio.
A principal dificuldade para a implementação de projetos de ML em um ambiente de produção é a reimplementação de pipelines de dados. Voltando ao exemplo de detecção de fraudes, os recursos realistas que as empresas implementarão são:
- Distância entre o local de residência do usuário e o local onde a transação está ocorrendo, computada à medida que a transação ocorre.
- Se o valor da transação atual for maior que um desvio padrão acima da média histórica naquele local do comerciante.
- Número de transações de um usuário nos últimos 30 minutos, atualizado a cada segundo.
Os pipelines de engenharia de recursos são difíceis de implementar. Eles não podem ser computados diretamente em um data warehouse e exigem a configuração de uma infraestrutura de transmissão para processar dados em tempo real. Uma plataforma de recursos resolve os desafios de engenharia para colocar esses recursos em produção e, ao fazê-lo, facilita a produção. Em termos concretos, uma plataforma de recursos:
- Orquestra e executa continuamente pipelines de dados para computar recursos, e os disponibiliza para treinamento offline e inferência online.
- Gerencia recursos como código, permitindo que as equipes façam revisões de código, controlem as versões e integrem as alterações de recursos em pipelines de CI/CD.
- Cria uma biblioteca de recursos, padronizando as definições deles e permitindo que cientistas de dados compartilhem e descubram recursos nas equipes.
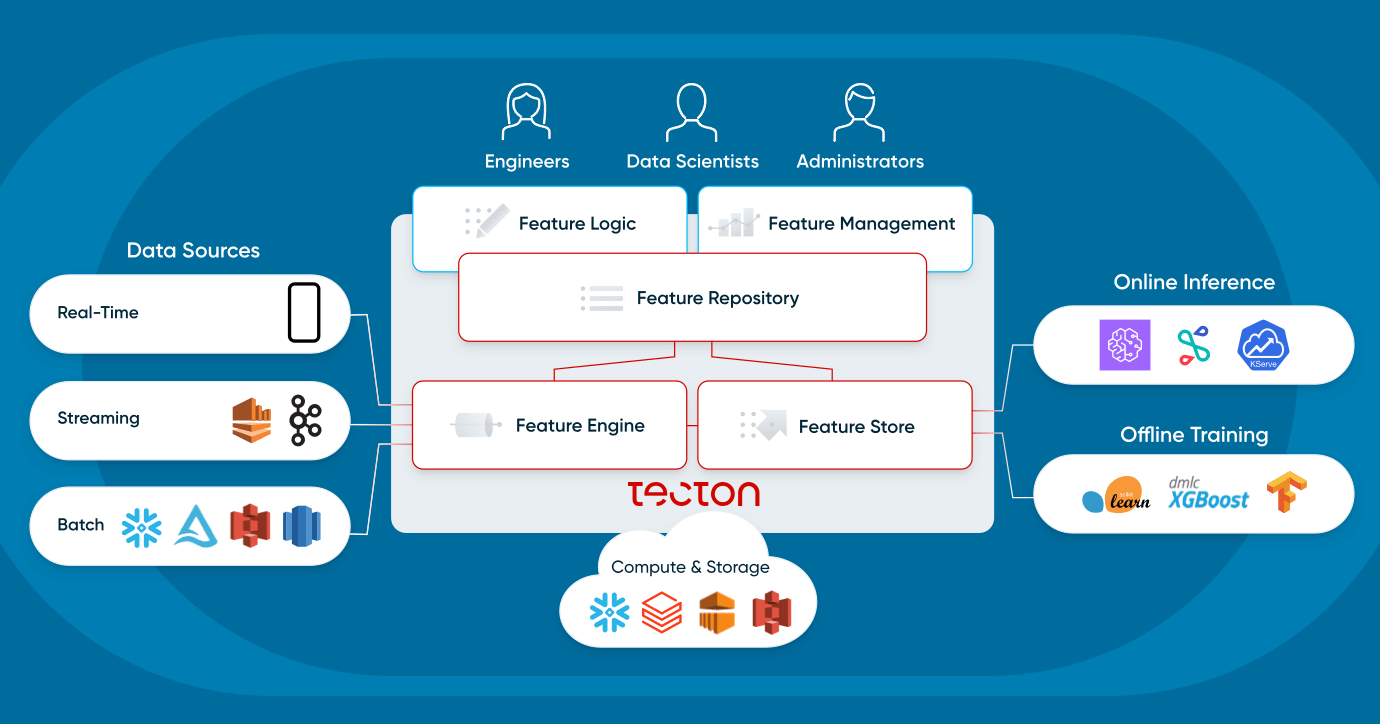
Vamos analisar como os usuários interagem com uma plataforma de recursos e quais são seus componentes.
O manual de IA agêntica para empresas

O que é uma plataforma de recursos?
Uma plataforma de recursos é um sistema que orquestra a infraestrutura de dados existente para transformar, armazenar e fornecer dados continuamente para aplicações operacionais de machine learning.
Existem duas formas principais pelas quais os usuários interagem com uma plataforma de recursos:
- Criação e descoberta de recursos
- Os usuários definem novos recursos como código em arquivos Python usando um framework declarativo. Definições de recursos são gerenciados em um repo do git.
- Os usuários descobrem recursos já existentes que outras equipes definiram.
- Recuperação de recursos
- Durante o treinamento, os usuários podem acessar a plataforma de recursos dentro de um notebook para obter todos os dados históricos de que precisam para ensinar um modelo. Isso pode ser feito com uma chamada como get_historical_features(fraud_model). A plataforma de recursos gerencia a complexidade do preenchimento retroativo de recursos e da realização de joins pontuais corretas, e o quadro de dados resultante pode ser utilizado por qualquer ferramenta de treinamento de modelos, como XGBoost, Scikit-learn etc.
- Para tempo de inferência, a plataforma de recursos expõe um endpoint REST que pode ser chamado por uma aplicação em tempo real. Isso retorna o vetor de recurso mais recente para um determinado ID de entidade em milissegundos, que o modelo usará para fazer uma previsão.
As plataformas de recursos não substituem a infraestrutura existente. Em vez disso, elas habilitam a infraestrutura existente para aplicações operacionais de machine learning — elas se conectam a (1) fontes de dados em lote, como data lakes e data warehouses, e (2) fontes de transmissão, como Kafka. Eles usam (3) infraestrutura de compute existente, como um data warehouse ou Spark, e (4) infraestrutura de armazenamento existente, como S3, DynamoDB ou Redis. Uma plataforma de recursos moderna se conecta de forma flexível à infraestrutura de dados existente de uma organização.
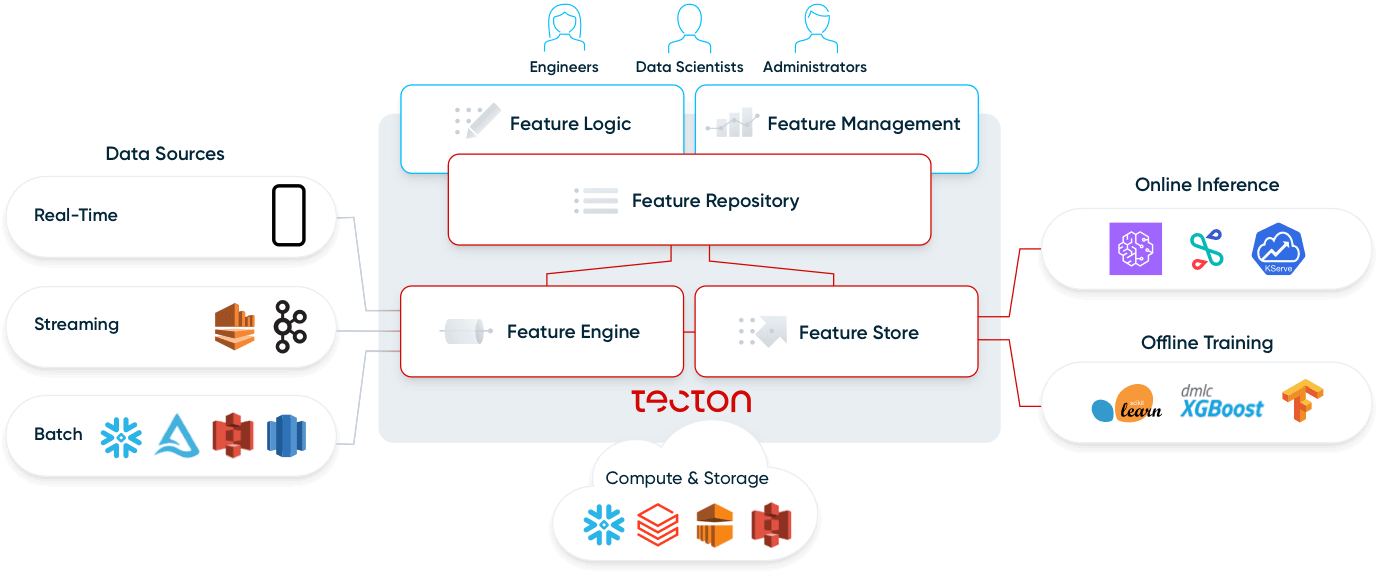
Vamos analisar os quatro componentes de uma plataforma de recursos: repositório de recursos, pipelines de recursos, Feature Store e monitoramento.
Repositório de recursos
Muitos cientistas de dados realizam sua engenharia de recursos em Notebooks. Eles são interativos, fáceis de usar e geram ciclos de desenvolvimento rápidos. O problema começa quando esses recursos precisam entrar em produção; é impossível integrá-los aos pipelines de CI/CD e ter os controles que utilizamos com software tradicional.
As equipes que implantam aplicações operacionais de ML gerenciam seus recursos como ativos de código. Isso traz todos os benefícios do DevOps: ele permite que as equipes façam revisões de código, rastreiem a linhagem e se integrem aos pipelines de CI/CD, resultando em equipes enviando mudanças de forma mais rápida e confiável. Um sintoma comum das equipes que não gerenciam recursos como código é que elas geralmente não conseguem repetir a primeira versão de um modelo.
Em uma plataforma de recursos, os usuários definem recursos como código usando uma interface declarativa que contém três elementos:
- Configuração sobre a frequência com que o recurso deve ser computado.
- Metadados, como o nome e a descrição do recurso, para permitir compartilhamento e descoberta.
- Lógica de transformação, definida em SQL ou Python.
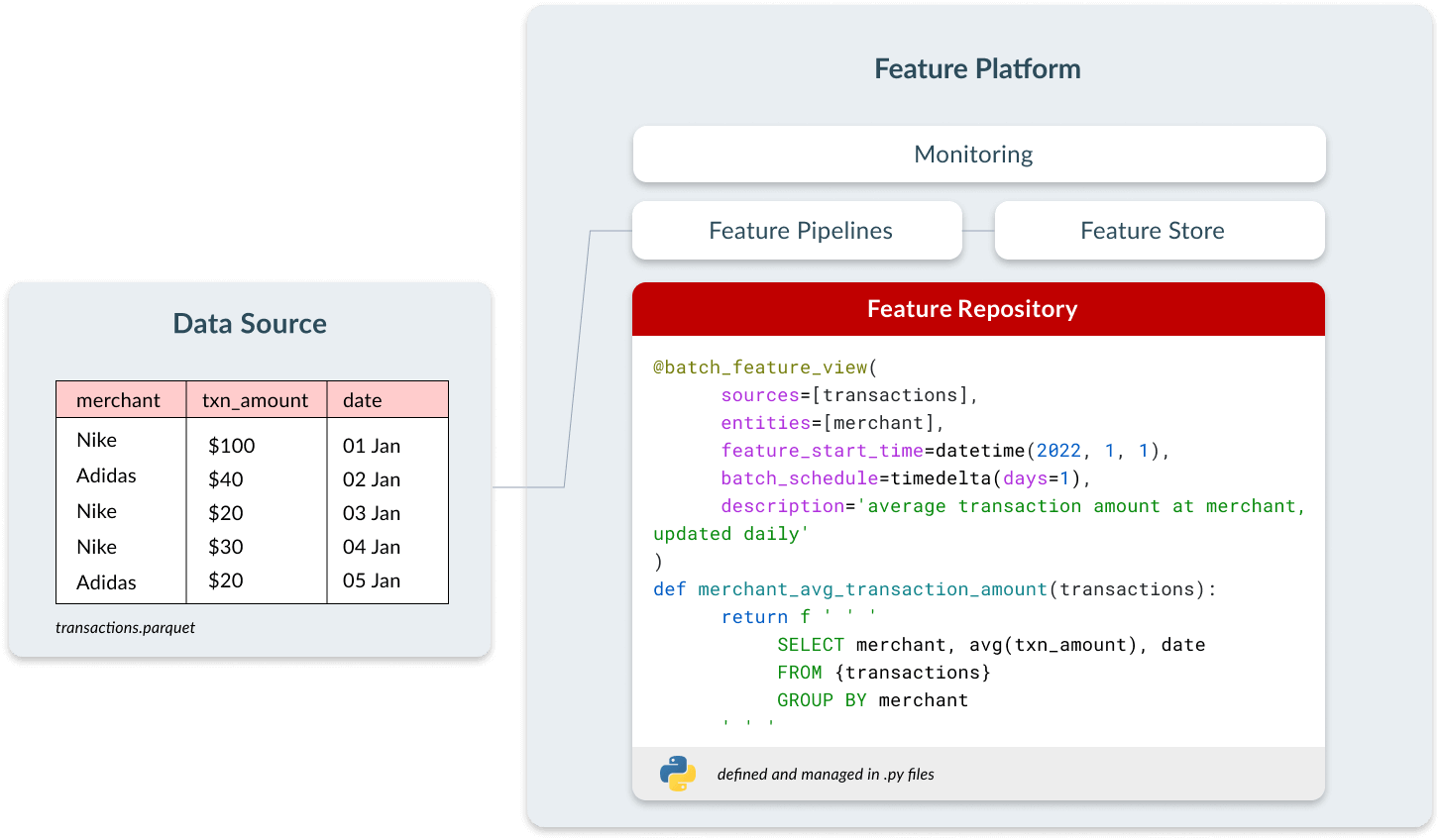
Esses recursos ficam disponíveis de forma centralizada para que todas as equipes possam descobrir e usar em seus próprios modelos. Isso economiza tempo de desenvolvimento, cria consistência entre as equipes e economiza custos de compute, já que os recursos não precisam ser computados várias vezes para diferentes casos de uso.
Pipelines de recursos
As aplicações operacionais de machine learning exigem o processamento contínuo de novos dados para que os modelos possam fazer previsões usando uma visualização atualizada do mundo. Depois que um usuário definir o recurso no repositório, a plataforma de recursos processará automaticamente os pipelines de dados para fazer compute desse recurso.
Existem três tipos de transformações de dados que uma plataforma de recursos deve aceitar:
| Transformação | Definição | Origem de dados | Exemplo |
|---|---|---|---|
| Batch | Transformações que são aplicadas somente a dados em repouso | Data warehouse, data lake, banco de dados | Valor médio de transações por comerciante, atualizado diariamente |
| Transmissão | Transformações aplicadas a fontes de transmissão | Kafka, Kinesis, PubSub, Flink | Número de transações do usuário nos últimos 30 minutos, atualizado a cada segundo |
| Sob demanda | Transformações utilizadas para gerar recursos com base em dados disponíveis apenas no momento da previsão. Estes recursos não podem ser pré-computados. | Aplicação voltada para o usuário, APIs para serviços RPC, dados em memória | O valor da transação atual é superior a dois desvios padrão em relação ao valor médio das transações do usuário, computado no momento da transação? |
Essas transformações são executadas em mecanismos de processamento de dados (Spark, Snowflake, Python) aos quais a plataforma de recursos está conectada. A plataforma de recursos passa o código de transformação definido pelo usuário 1:1 para o mecanismo de processamento de dados subjacente. Isso significa que a plataforma de recursos não deve ter seu próprio dialeto SQL personalizado ou DSL Python personalizado. Isso simplifica a experiência de integração à plataforma de recursos, bem como a experiência de depuração.
As transformações em lotes são simples de executar: elas podem ser executadas por meio de uma query SQL em um data warehouse ou executando um job Spark. Aplicações operacionais de ML, no entanto, se beneficiam mais de informações atualizadas que só podem ser acessadas por meio de transmissões e transformações sob demanda. No exemplo de detecção de fraude, os recursos que permitirão ao modelo fazer a melhor previsão conterão informações sobre a transação atual, como valor, comerciante e localização, ou informações sobre transações que aconteceram nos últimos minutos.
Todas as equipes com quem conversamos concordam que ter acesso a dados atualizados melhoraria o desempenho da maioria de seus modelos. A maioria das organizações ainda está usando transformações em lotes apenas porque o gerenciamento de transformações de transmissão e sob demanda é complexo. Uma plataforma de recursos abstrai essa complexidade, permitindo que o usuário defina a lógica das transformações e selecione se ela deve ser executada como uma transformação em lote, transmissão ou sob demanda.
Ao implementar novos recursos na fase de desenvolvimento, é necessário preencher dados retroativamente para gerar conjuntos de dados de treinamento. Por exemplo, podemos desenvolver hoje um novo recurso chamado `merchant_fraud_rate`, que precisará ser preenchido retroativamente para todo o período em que desejamos ensinarmos o modelo. As plataformas de recursos executam essas transformações automaticamente ao definir novos recursos, permitindo ciclos de iteração rápidos no processo de desenvolvimento.

Feature Store
Os Feature Stores se tornaram cada vez mais comuns desde que introduzimos o conceito com a Uber Michelangelo em 2017. Eles têm duas finalidades: armazenar e fornecer recursos de forma consistente em ambientes de treinamento offline e de inferência online.
Quando os recursos não são armazenados de forma consistente em ambos os ambientes, os recursos com os quais o modelo é treinado podem apresentar diferenças sutis em relação aos recursos que ele usa para inferência online. Esse fenômeno é chamado de "train-serve skew" e pode prejudicar o desempenho de um modelo de maneira silenciosa e catastrófica, algo extremamente difícil de depurar. Ao manter dados consistentes em ambos os ambientes, um Feature Store ajuda a resolver esse problema.
Para treinamento offline, os Feature Stores precisam conter meses ou anos de dados. Isso é armazenado em data warehouses ou data lakes, como S3, BigQuery, Snowflake ou Redshift. Essas fontes de dados são otimizadas para a recuperação em larga escala.
Para inferência online, as aplicações precisam ter acesso ultrarrápido a pequenas quantidades de dados. Para permitir consultas de baixa latência, esses dados são armazenados em um armazenamento online, como DynamoDB, Redis ou Cassandra. Apenas os valores mais recentes dos recursos para cada entidade são mantidos no armazenamento online.

Para recuperar dados offline, os valores dos recursos são comumente acessados por meio de um SDK compatível com Notebooks. Para inferência online, um Feature Store fornece um único vetor de recursos contendo os dados mais atualizados. Embora a quantidade de dados em cada uma dessas requisições seja pequena, um Feature Store deve ser capaz de escalar para milhares de requisições por segundo. Essas respostas são servidas em milissegundos para aplicações ativas por meio de um endpoint REST. Feature Stores de desempenho devem fornecer SLAs quando há disponibilidade e latência.

Monitoramento
Quando algo dá errado em um sistema de ML operacional, geralmente é um problema de dados. Como as plataformas de recursos gerenciam o processo desde os dados brutos até os modelos, elas estão em uma posição privilegiada para detectar problemas nos dados. Existem dois tipos de monitoramento que as plataformas de recursos aceitam:
Monitoramento da qualidade dos dados
As plataformas de recursos podem rastrear a distribuição e a qualidade dos dados recebidos. Houve mudanças significativas na distribuição dos dados desde o último treinamento do modelo? De repente, estamos vendo mais valores ausentes? Isso está afetando o desempenho do modelo?
Monitoramento operacional
Ao executar sistemas de produção, também é importante monitorar as métricas operacionais. Plataformas de recursos monitoram a estagnação de recursos para detectar quando os dados não estão sendo atualizados no ritmo esperado, junto com outras métricas relacionadas ao armazenamento de recursos (disponibilidade, capacidade, utilização) e métricas relacionadas a feature serving (taxa de transferência, latência, queries por segundo, taxas de erro). Uma plataforma de recursos também monitora se os pipelines de recursos estão executando jobs como esperado, detecta quando jobs não estão tendo sucesso e resolve problemas automaticamente.
As plataformas de recursos disponibilizam essas métricas para a infraestrutura de monitoramento existente. Aplicações operacionais de ML devem ser monitoradas como quaisquer outras aplicações de produção, que são gerenciadas com as ferramentas de observabilidade existentes.
Agora vamos juntar tudo
Parte da mágica de uma plataforma de recursos é que ela permite que as equipes de ML produzam rapidamente novos recursos. Mas a explosão de valor acontece quando a plataforma de recursos está sendo usada por várias equipes e impulsionando múltiplos casos de uso.

Uma plataforma de recursos permite que os engenheiros de dados deem suporte a um número maior de cientistas de dados do que seria possível de outra forma. Conversamos com muitas equipes que precisavam de dois engenheiros de dados para dar suporte a um único cientista de dados, sem uma plataforma de recursos. Uma plataforma de recursos ajudou eles a reverter essa proporção. Uma vez que uma plataforma de recursos seja amplamente adotada, cientistas de dados podem facilmente adicionar recursos que já estão sendo calculados em seus modelos. Vimos o mesmo padrão se repetir: as equipes levam alguns meses para que seu primeiro caso de uso seja totalmente implantado; algumas semanas para o segundo caso de uso; e apenas alguns dias para que novos casos de uso sejam implantados ou para iterar sobre casos de uso existentes depois disso.
Quando (e quando não) adotar uma plataforma de recursos
Comecei este artigo descrevendo como é difícil acompanhar todo o ecossistema de ferramentas MLOps que surgiram nos últimos anos. Na realidade, você deve manter sua infraestrutura da forma mais simples possível e adotar ferramentas somente quando for realmente necessário.
Observamos que as equipes descobrem valor em uma plataforma de recursos quando:
- Já experimentaram o processo de transferência entre cientistas de dados e engenheiros de dados e o problema associado à reimplementação de pipelines de dados para produção.
- Estão implantando aplicações operacionais de machine learning, que precisam atender a SLAs rigorosos, alcançar escala e não podem apresentar falhas em produção.
- Existem várias equipes que desejam ter definições de recursos padronizadas e reutilizar recursos em diferentes modelos.
As equipes devem evitar adotar uma plataforma de recursos quando:
- Estão nas fases de ideação ou desenvolvimento e ainda não estão prontas para enviar para produção.
- Têm apenas uma única equipe trabalhando somente com dados em lote.
Como começar
Existem algumas opções para começar:
- Tecton é uma plataforma de recursos gerenciada. Inclui todos os componentes descritos acima, e nossos clientes escolhem a Tecton porque precisam de SLAs de produção e capacidades empresariais, sem precisar gerenciar uma solução por conta própria. A Tecton é utilizada por equipes de ML que vão desde startups de tecnologia até diversas empresas da Fortune 500.
- Feast é o Feature Store de código aberto mais conhecido. É uma ótima opção se você já possui pipelines de transformação para fazer compute de seus recursos, e deseja armazenar e disponibilizar esses recursos em produção. Com o tempo, o Feast continuará adicionando pipelines de recursos e capacidades de monitoramento, que o tornarão uma plataforma de recursos completa.
Escrevi esta postagem no blog para oferecer uma definição comum de plataformas de recursos, visto que elas agora estão consolidadas como um componente central da pilha de aplicações operacionais de machine learning.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.