Conecte qualquer fonte de dados, uma única plataforma.
Aprimore seus agentes de IA com contexto empresarial completo.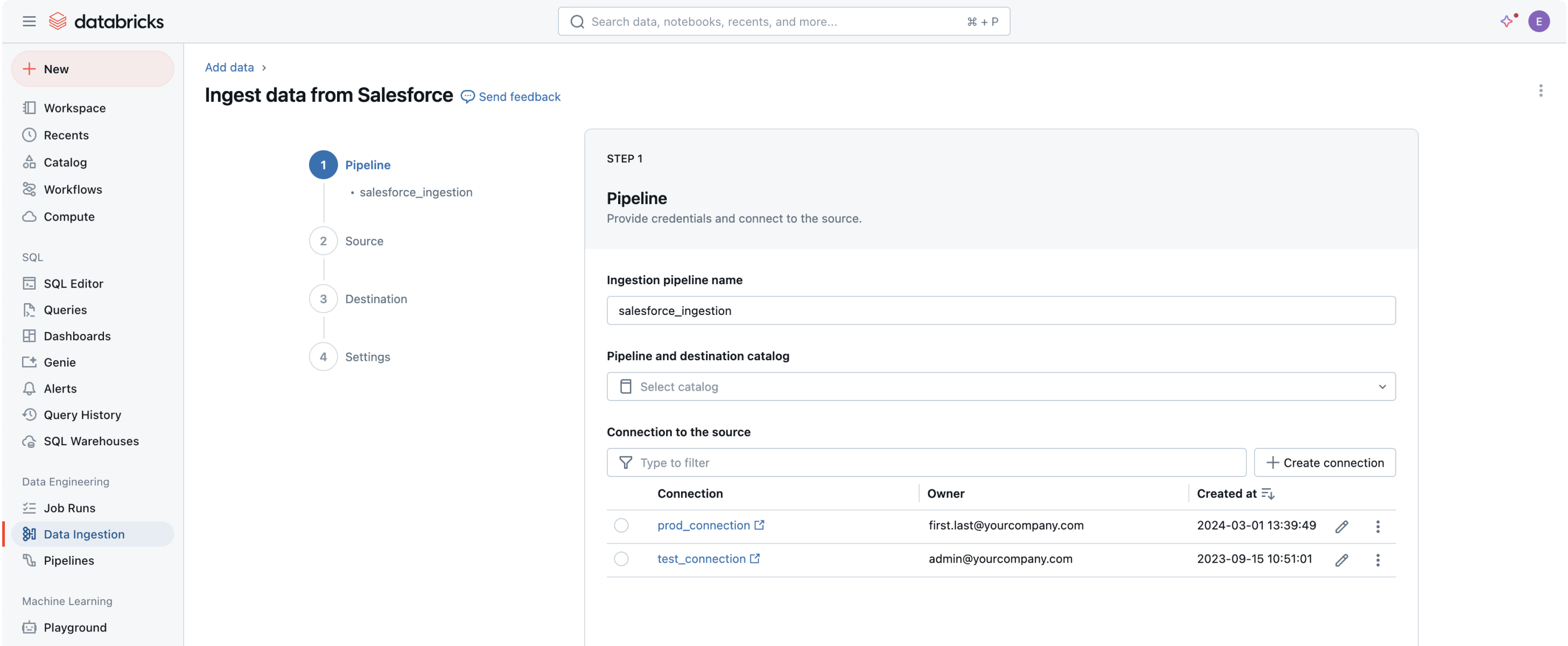

Conecte qualquer fonte de dados, uma única plataforma.
Mais de 100 conectores integrados para aplicativos empresariais, bancos de dados e fontes de arquivos fornecem aos seus agentes de IA um contexto completo e confiável.Flexível e fácil
Conectores totalmente gerenciados fornecem uma UI e uma API simples para facilitar a configuração e democratizam o acesso aos dados. Recursos automatizados também ajudam a simplificar a manutenção de pipelines com sobrecarga mínima.
Conectores integrados
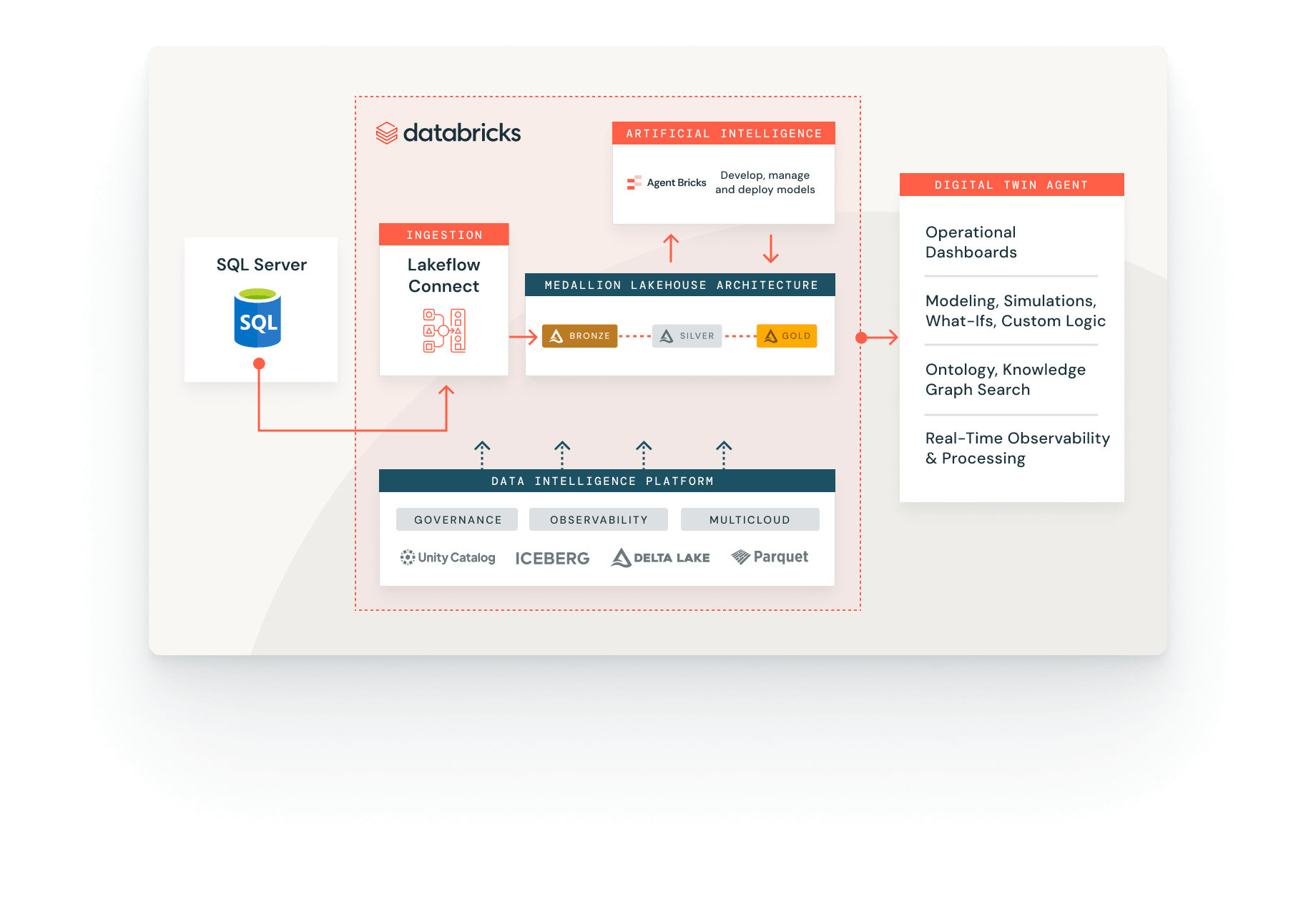
A ingestão de dados está totalmente integrada com a Data Intelligence Platform. Crie pipelines de ingestão com governança do Unity Catalog, observabilidade do Lakehouse Monitoring e orquestração contínua com fluxos de trabalho para analítica, Machine Learning e BI.
Integração direta com agentes de AI
Impulsione sua AI e seu BI downstream com um contexto empresarial de alta fidelidade. Elimine silos e alimente seus agentes de AI com lógica de negócios completa para um raciocínio confiável.
Capacidades robustas de ingestão para fontes de dados populares
Trazer todos os seus dados para a Data Intelligence Platform é o passo para extrair valor e ajudar a resolver os problemas de dados mais desafiadores da sua organização.A interface do usuário (UI) sem código ou uma API simples capacita os profissionais de dados a realizar o autoatendimento, economizando horas de programação.
Ingira apenas novos dados ou atualizações de tabela, tornando a ingestão de dados rápida, escalável e operacionalmente eficiente.

Ingira dados em um ambiente 100% Serverless que oferece Startup rápida e escalonamento automático da infraestrutura.

A integração profunda com o Databricks Unity Catalog oferece recursos robustos, incluindo linhagem e qualidade de dados.

Ingestão de dados com Databricks
Resolvendo problemas de clientes em diversas indústrias

Meça o desempenho da campanha e mapeie a jornada do cliente
Consolide dados fragmentados de anúncios e campanhas do Meta, Google Ads e TikTok Ads. Capture os estados históricos da plataforma para realizar análises pontuais precisas e construir uma jornada do cliente unificada.





O preço baseado no uso ajuda a controlar despesas
Pague apenas pelos produtos que usar por segundo.Descubra mais
Explore outras ofertas integradas e inteligentes na plataforma de inteligência de dados.
Jobs do Lakeflow
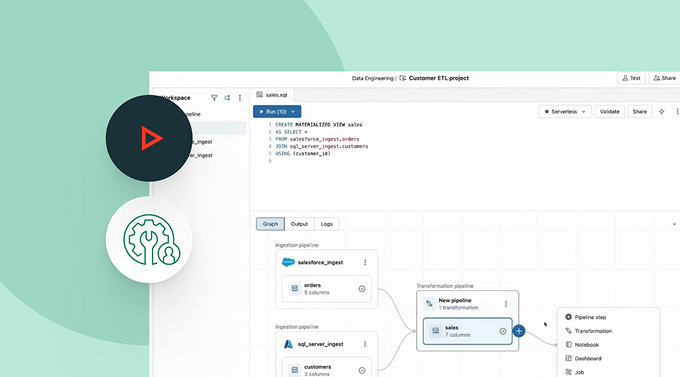
Capacite as equipes para automatizar e orquestrar melhor qualquer fluxo de trabalho de ETL, analítica e IA com observabilidade detalhada, alta confiabilidade e amplo suporte a tipos de tarefas.
Pipelines Declarativos do Apache Spark™
Simplifique o ETL em lotes e transmissão com qualidade de dados automatizada, captura de dados de alterações (CDC), ingestão de dados, transformações e governança unificada.

Unity Catalog
Governe sem esforço todos os seus ativos de dados com a única solução de governança unificada e aberta do setor para dados e AI, integrada à Databricks Data Intelligence Platform.

Delta Lake
Unifique os dados em seu lakehouse, em todos os formatos e tipos, para todas as suas cargas de trabalho de analytics e AI.

Genie Code
Desenvolva e mantenha pipelines de dados com uma IA agêntica que entende seus dados.
Introdução
Explore a documentação de ingestão de dados
Ingerir dados de diversas fontes, entre cloud e via Lakeflow Connect.
Tour pelo Lakeflow Connect
O Lakeflow Connect agora está em disponibilidade geral para Salesforce, Workday e SQL Server.
Para ter acesso à pré-visualização de outros conectores, entre em contato com a equipe da sua conta Databricks.



Perguntas frequentes sobre ingestão de dados
Pronto para se tornar uma empresa de dados + AI?
Dê os primeiros passos na transformação dos seus dados