TensorFlow™ no Databricks

Computação distribuída com TensorFlow
O TensorFlow é compatível com computação distribuída, permitindo que partes do gráfico sejam calculadas em processos diferentes, que podem estar em servidores completamente diferentes! Além disso, isso pode ser usado para distribuir computação para servidores com GPUs poderosas, realizar outros cálculos feitos em servidores com mais memória, e assim por diante. A interface é um pouco complicada, então vamos começar do zero.
Este é nosso primeiro script, que executaremos em um único processo, e depois passaremos para vários processos.
A esta altura, esse script não deve parecer muito assustador. Temos uma constante e três equações básicas. O resultado (238) é impresso no final.
O TensorFlow funciona um pouco como um modelo cliente/servidor. A ideia é que você crie um monte de workers que executarão o trabalho pesado. Depois, você cria uma sessão em um desses workers, e ele calculará o gráfico, possivelmente distribuindo partes dele para outros clusters no servidor.
Para fazer isso, o worker principal, o mestre, precisa saber sobre os outros workers. Isso é feito por meio da criação de um ClusterSpec, que você precisa passar para todos os workers. Um ClusterSpec é construído usando um dicionário, onde a chave é um "nome de job", e cada job contém muitos workers.
Veja abaixo um diagrama de como isso seria.
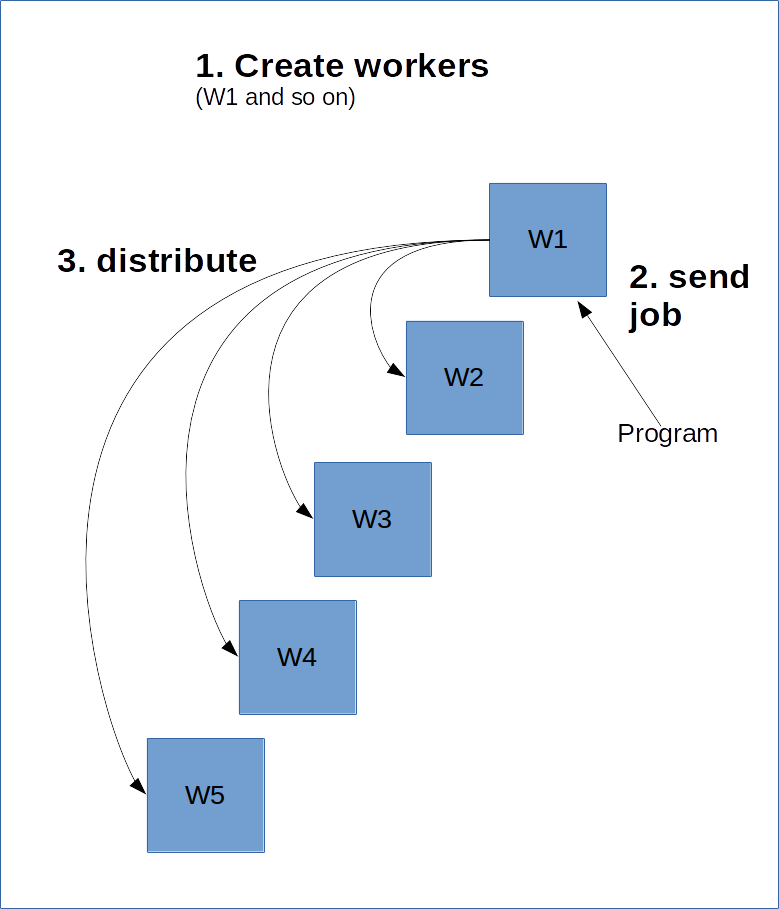
O código a seguir cria um ClusterSpect com um nome de job de "local" e dois processos de workers.
Observe que esses processos não são iniciados com esse código, apenas uma referência é criada para que eles sejam iniciados.
Em seguida, iniciamos o processo. Para fazer isso, representamos graficamente um desses workers e o iniciamos:
O código acima inicia o worker "localhost:2223" sob o job "local".
Abaixo está um script que você pode executar na linha de comando para iniciar os dois processos. Salve o código em seu computador como create_worker.py e execute com python create_worker.py 0 e, em seguida, python create_worker.py 1. Você precisará de terminais separados para fazer isso, pois os scripts não terminam sozinhos (eles estão esperando instruções).
Depois de fazer isso, você encontrará os servidores em execução em dois terminais. Tudo pronto para distribuir!
A maneira mais fácil de “distribuir” o job é simplesmente criar uma sessão em um desses processos e, em seguida, o gráfico é executado lá. Basta alterar a linha “sessão” acima para:
Isso não distribui tanto quanto envia o job para esse servidor. O TensorFlow pode distribuir o processamento para outros recursos no cluster, mas também pode não distribuir. Podemos forçar isso especificando dispositivos (da mesma forma que fizemos com as GPUs na última lição):
Agora, estamos distribuindo! Isso funciona alocando tarefas aos workers, com base no nome e número da tarefa. O formato é:
/job:JOB_NAME/task:TASK_NUMBER
Com vários jobs (ou seja, para identificar computadores com grandes GPUs), podemos distribuir o processamento de várias maneiras.
Mapear e reduzir
MapReduce é um paradigma popular para realizar grandes operações. É composto por duas etapas principais (embora, na prática, existam mais algumas).
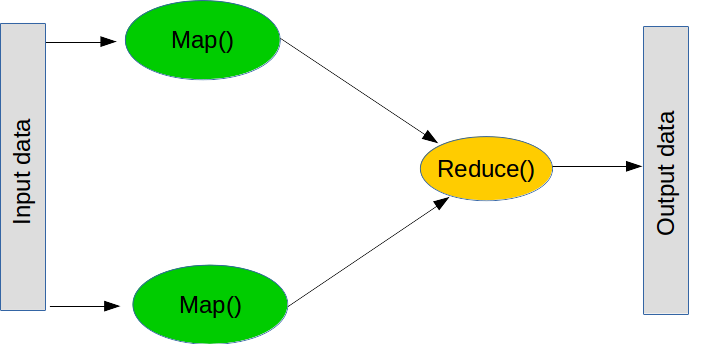
O primeiro passo é conhecido como mapa, que significa “pegue esta lista de coisas e aplique esta função a cada uma delas”. Você pode fazer um mapa em python normal assim:
A segunda etapa é uma redução, que significa "pegue esta lista de coisas e combine-as usando esta função". Uma operação de redução comum é a soma, ou seja, "pegue esta lista de números e combine-os somando-os todos", que pode ser realizada criando uma função que adiciona dois números. O que a redução faz é pegar os dois primeiros valores da lista, executar a função, obter o resultado e então executar a função com o resultado e o próximo valor. Para a soma, adicionamos os dois primeiros números, pegamos o resultado, adicionamos com o próximo número e assim por diante até atingirmos o fim da lista. Novamente, a redução faz parte do python normal (embora não esteja distribuída):
Observe que você nunca precisará de fato usar a redução. Basta usar um loop for.
De volta ao TensorFlow distribuído, executar operações de mapeamento e redução é um bloco de construção fundamental de muitos programas não triviais. Por exemplo, um conjunto de aprendizagem pode enviar modelos individuais de aprendizado de máquina para vários workers e, em seguida, combinar as classificações para formar o resultado final. Outro exemplo é um processo que
Este é outro script básico que vamos distribuir:
A conversão para uma versão distribuída é apenas uma alteração da conversão anterior:
É mais fácil entender a computação distribuída se você pensar nela em termos de mapas e reduções. Primeiro, "como posso dividir este problema em subproblemas que podem ser resolvidos de forma independente?". Temos o mapa para isso. Em segundo lugar, "como posso combinar as respostas para formar um resultado final?". Temos a redução para isso.
No aprendizado de máquina, o método mais comum para o mapa é simplesmente dividir seus conjuntos de dados. Os modelos lineares e as redes neurais geralmente são muito bons nisso, pois podem ser treinados individualmente e combinados posteriormente.
1) Altere a palavra "local" no ClusterSpec para outra coisa. O que mais você precisa alterar no script para que funcione?
2) O script de média atualmente depende do fato de que as fatias são do mesmo tamanho. Experimente com fatias de tamanhos diferentes e observe o erro. Corrija isso usando tf.size e a seguinte fórmula para combinar médias de fatias:
3) Você pode especificar um dispositivo em um computador remoto modificando a sequência de caracteres do dispositivo. Como exemplo, “/job:local/task:0/gpu:0” terá como alvo a GPU no job local. Crie um job que use uma GPU remota. Se você tiver um segundo computador disponível, tente fazer isso pela rede.