Plataforma de servicio de IA que se adapta a su modelo
Una sola plataforma para todos los modelos de AI (ML clásico, aprendizaje profundo y agentes): más de 300K QPS, menos de 10 ms, sin ajustes
por Anshul Gupta
- Qué es: Una plataforma totalmente gestionada que ejecuta cualquier modelo en producción, desde un clasificador de scikit-learn de 2 MB en un solo núcleo de CPU hasta un LLM de 70B ajustado en ocho GPUs, sin necesidad de ajustes manuales.
- El desafío que resuelve: Los modelos personalizados tienen perfiles de recursos y patrones de tráfico muy diferentes, por lo que ninguna configuración estática única se adapta a todos ellos. En su lugar, la plataforma se adapta, manteniendo la latencia baja y garantizando la eficiencia de cada nodo.
- Los resultados: más de 300K QPS con una sobrecarga de latencia p99 de <10 ms y un costo de infraestructura hasta un 90% menor para los clientes que migran desde entornos autogestionados.
Desafíos de ejecutar inferencias de modelos personalizados
Cuando despliegas un modelo de machine learning en producción, te comprometes con un contrato: cada solicitud se completa en unos pocos milisegundos, independientemente de los picos de tráfico, y tu factura se mantiene baja cuando el tráfico es bajo. El servicio de modelos es la infraestructura que mantiene ese contrato y, durante la mayor parte de la historia de la industria, mantenerlo ha sido tan difícil como construir el propio modelo.
Los modelos personalizados son fundamentalmente diferentes de los modelos fundacionales. Una plataforma que aloja un modelo fundacional (Llama, Mistral, una variante de CLIP) sabe exactamente qué está ejecutando: la arquitectura, la huella de memoria, las características de inferencia, y puede optimizar profundamente para ese modelo específico. Las plataformas de modelos personalizados son lo contrario. La misma plataforma tiene que servir un clasificador scikit-learn de 2 MB en un solo núcleo de CPU y un LLM de 70B ajustado en ocho GPUs; un modelo de ranking de baja latencia que no tolera colas y un modelo de embeddings que prospera con un procesamiento por lotes agresivo. Una plataforma que debe servir todo tipo de modelos, donde no hay dos con el mismo perfil de recursos, forma de tráfico o presupuesto de latencia.
Las plataformas tradicionales delegan esa complejidad en el cliente: número de réplicas, concurrencia por réplica, umbrales de escalado automático. Esto sigue siendo DIY, solo que a un nivel de abstracción más alto. Y nunca se detiene: cada nuevo modelo y cambio de tráfico implica volver a analizar el perfil y realizar un nuevo ajuste, por lo que tus mejores ingenieros se la pasan apagando incendios en producción antes y después del lanzamiento, y el servicio se convierte en el ancla que ralentiza cada despliegue. El resultado es el costo que más importa: modelos probados en desarrollo que se quedan parados durante semanas antes de llegar a producción.
Nuestra misión: eliminar el impuesto del stack de ML
Reajustar manualmente la infraestructura de servicio es un impuesto para cada modelo que ejecuta una organización; a gran escala se vuelve estructural, con equipos que crean grupos de servicio dedicados cuyo único trabajo es mantener los modelos activos y eficientes en producción. Lo llamamos el impuesto del stack de ML.
Databricks Custom Model Serving es una plataforma de inferencia en tiempo real totalmente gestionada para cualquier modelo empaquetado en MLflow. Nuestra misión es borrar ese impuesto en las tres etapas de la vida de un modelo para que los equipos de servicio de nuestros clientes puedan centrarse en aportar un valor más sofisticado:
- Simplificar la preproducción. Un modelo entrenado en Databricks se despliega con un solo clic: adaptamos el entorno exactamente, sin sorpresas en el tiempo de ejecución, y optimizamos el tiempo de despliegue para que la iteración y la reversión sigan siendo rápidas.
- Hacer que la producción sea confiable, escalable y rentable. La infraestructura se adapta a cada modelo y a su tráfico en tiempo de ejecución, manteniendo la latencia baja y los costos reducidos sin necesidad de realizar ajustes manuales. (El tema central de esta publicación).
- Simplificar la posproducción. Cada endpoint emite telemetría a Unity Catalog de forma nativa (métricas, registros y trazas nativos de OTel, tablas de inferencia instantáneas que capturan cada solicitud a Delta y MLflow Tracing). Genie Code se integra sobre todo esto para ofrecer una observabilidad operativa basada en agentes pionera en su clase. La observabilidad para la AI es un problema de contexto, y todo el contexto reside en una sola plataforma.
Esto funciona porque Custom Model Serving está integrado de forma nativa en Databricks: los datos, las características, el entrenamiento, el empaquetado de MLflow, el servicio y los agentes son un único stack gobernado, no sistemas separados unidos entre sí.
Esta publicación cubre la segunda etapa sobre cómo alcanzamos más de 300K QPS con baja latencia en una amplia variedad de modelos con un enfoque sin ajustes manuales. Esto es lo que hace que el impuesto desaparezca.
Arquitectura
Tres limitaciones dan forma a cada decisión en la arquitectura: baja latencia, gran escala y rentabilidad. Se oponen entre sí (la forma fácil de reducir la latencia es el sobredimensionamiento, la forma fácil de reducir costos es el subdimensionamiento) y mantener las tres a la vez, para cada tipo de modelo, sin desperdiciar recursos, es el verdadero desafío de ingeniería.
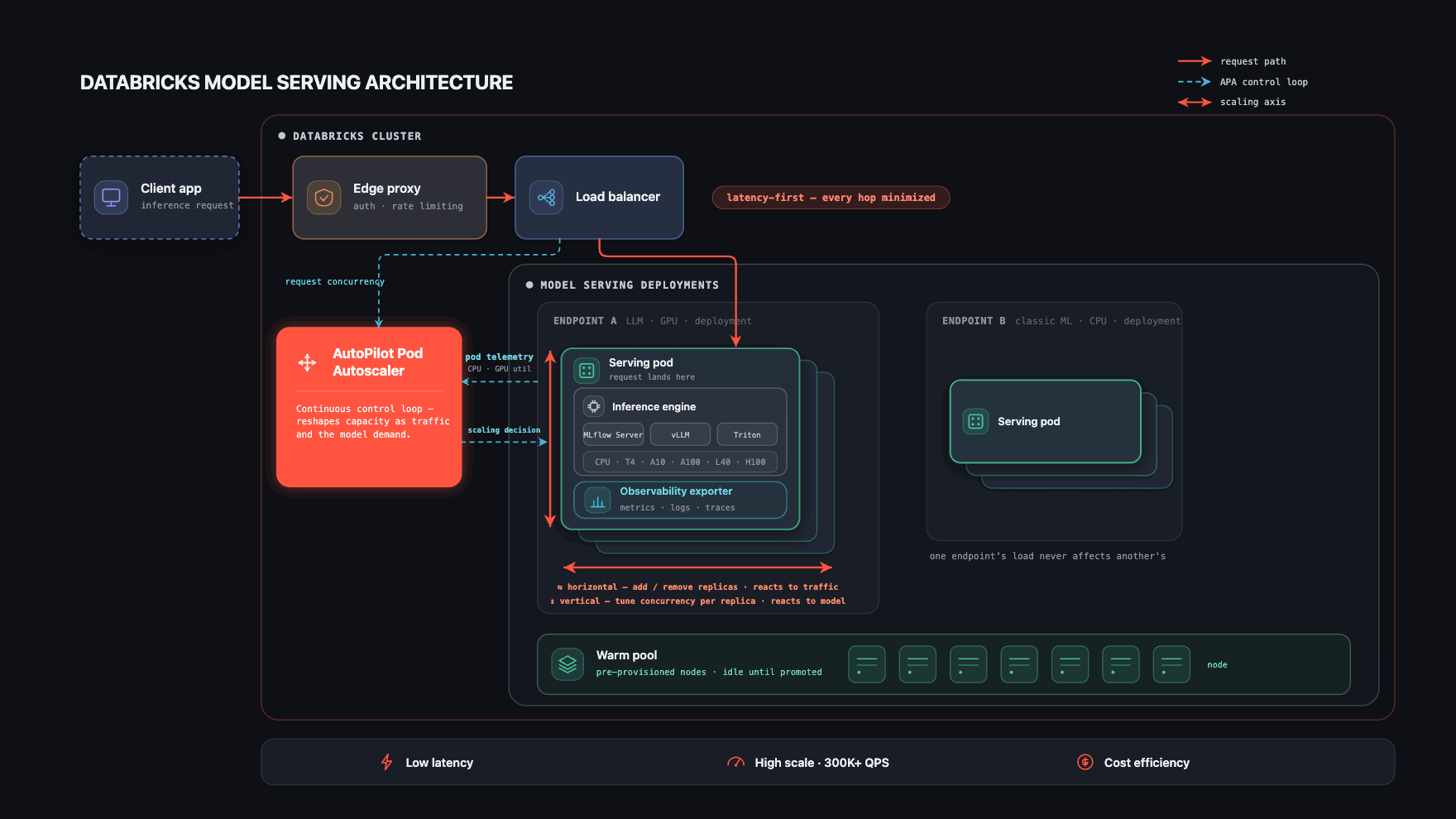
Tres elementos hacen que funcione.
- Una ruta de solicitud corta y aislada que mantiene al mínimo la sobrecarga de latencia en cada salto.
- Selección automática del tiempo de ejecución: cada modelo se sirve en el motor de inferencia que mejor se adapta a él.
- El corazón de la plataforma: un escalador automático (autoscaler) que se adapta tanto al modelo como a su tráfico en tiempo real, manteniendo la latencia baja y la escala alta mientras reduce los costos.
Los dos primeros mantienen rápida una sola solicitud; el tercero mantiene rápido y rentable todo el sistema a medida que cambian los modelos y el tráfico. La mayor parte de esta sección trata sobre el tercero.
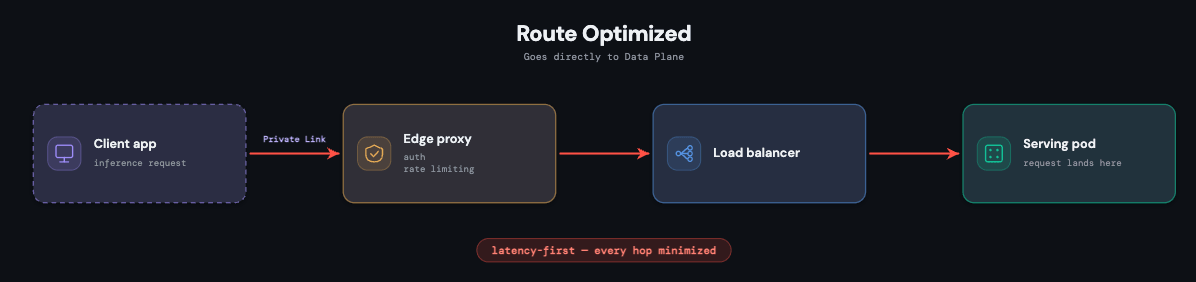
Ruta de solicitud corta y aislada
Cada endpoint de servicio es un despliegue de Kubernetes completamente aislado con sus propios pods y una imagen de contenedor específica para la versión del modelo. Este aislamiento es deliberado: el tráfico, las fallas o la presión de recursos de un endpoint no pueden afectar a otro, y mantiene seguras las cargas de trabajo personalizadas.
La ruta en sí se mantiene lo más corta posible, porque la latencia es una limitación de primer nivel en cada capa. Una solicitud llega a través de un proxy PoP; una vez autenticada, pasa a través de un balanceador de carga compartido para la gestión de conexiones e inmediatamente llega al pod que la sirve. Cada pod también ejecuta un sidecar de observabilidad que exporta métricas, registros, registros de carga útil y trazas, tanto para el monitoreo de la plataforma como para los paneles de control orientados al cliente.
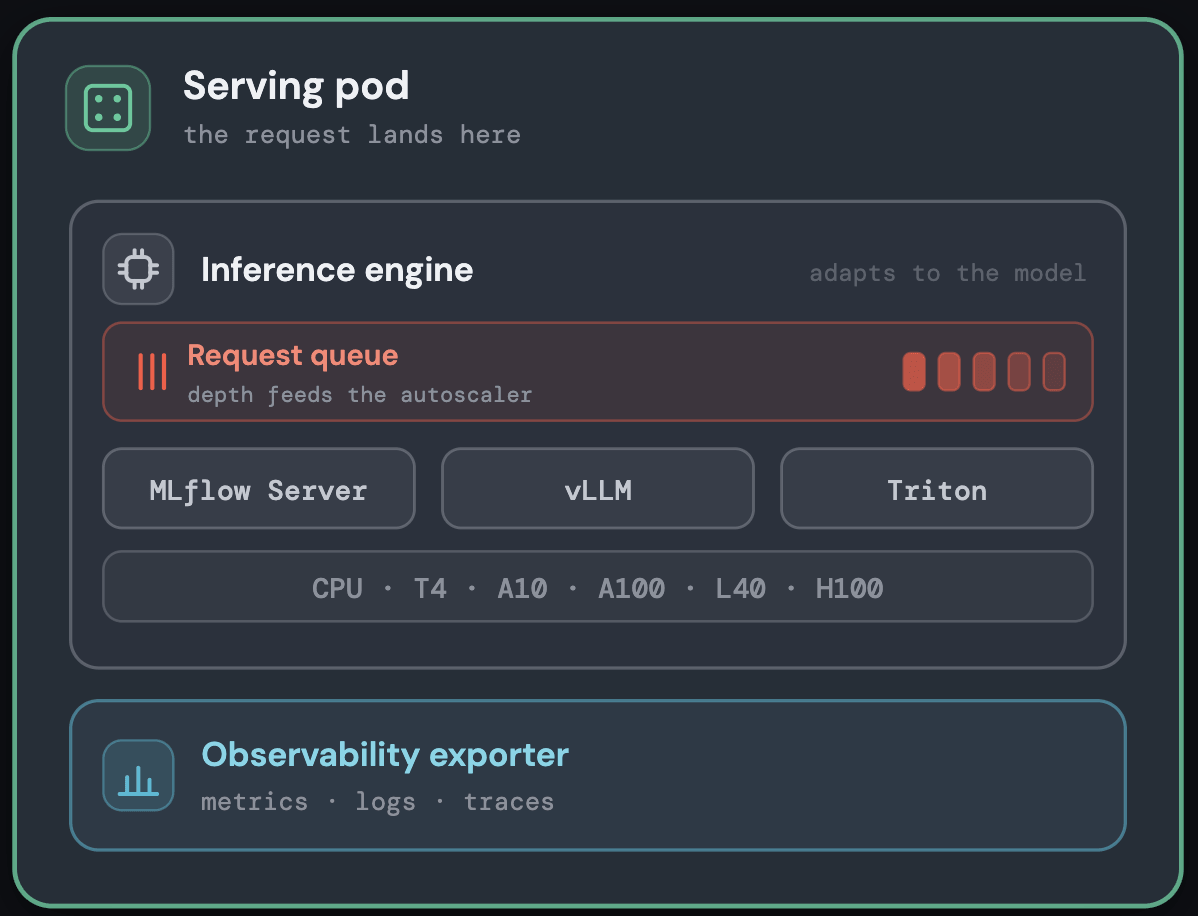
Selección eficiente del tiempo de ejecución del modelo
Dentro de cada pod, el modelo se ejecuta en el motor de inferencia que mejor se adapta a su tipo: un servidor asíncrono Gunicorn de MLflow para modelos de ML clásicos, y motores optimizados para GPU para modelos grandes con soporte para vLLM, Triton o el propio tiempo de ejecución del cliente, todo detrás de una interfaz de servicio uniforme.
Asociar cada modelo con el tiempo de ejecución adecuado mantiene baja la sobrecarga por solicitud sin necesidad de realizar ajustes manuales; los detalles se muestran en el siguiente diagrama.
El escalador automático (autoscaler): adaptación al modelo y al tráfico
Un controlador de Kubernetes personalizado que creamos, el AutoPilot Pod Autoscaler (APA), se encuentra en el centro de la plataforma. Recopila continuamente señales del balanceador de carga (concurrencia activa, profundidad de la cola) y de los propios pods (utilización de CPU, utilización de GPU, memoria de GPU y muchas otras), y las convierte en decisiones de escalado.
El escalador automático (autoscaler) existe para absorber dos tipos de imprevisibilidad a la vez:
- El modelo es impredecible. No se conoce de antemano el perfil de recursos de un modelo personalizado. Un modelo xgboost con uso intensivo de CPU puede servir solo 1 solicitud por núcleo, un agente puede ejecutar cientos de solicitudes por núcleo, mientras que un LLM de 13B ajustado se beneficia de varias solicitudes procesadas por lotes. APA aprende el límite de cada modelo en tiempo de ejecución y ajusta cuántas solicitudes debe aceptar cada réplica: escalado vertical consciente del modelo.
- El tráfico es impredecible. Presenta picos, ráfagas y cae a cero sin previo aviso. Un endpoint de fraude puede multiplicarse por 10 en segundos al inicio de una venta; un caso de uso específico de una región se activa intensamente durante una hora y luego permanece inactivo durante la noche. APA reacciona en el instante en que cambia la demanda: escalado horizontal basado en solicitudes.
Por eso el escalador automático (autoscaler) es el corazón del sistema: es el único componente que gestiona las tres limitaciones (latencia, escala y costo) al mismo tiempo, para cada modelo de la plataforma.
Dos ejes de elasticidad
Los escaladores automáticos (autoscalers) tradicionales realizan un escalado automático basado en solicitudes o en recursos, pero cada uno tiene una debilidad. El escalado basado en solicitudes reacciona rápidamente pero es ineficiente: trata cada solicitud de manera idéntica independientemente de qué tan cargada esté cada réplica, por lo que se sobredimensiona o se produce una fluctuación constante en el número de réplicas. El escalado basado en recursos (utilización de CPU, GPU) es eficiente pero tiene retraso: las métricas de utilización van por detrás del tráfico, por lo que para cuando se activa el escalador automático, el daño al p99 ya está hecho.
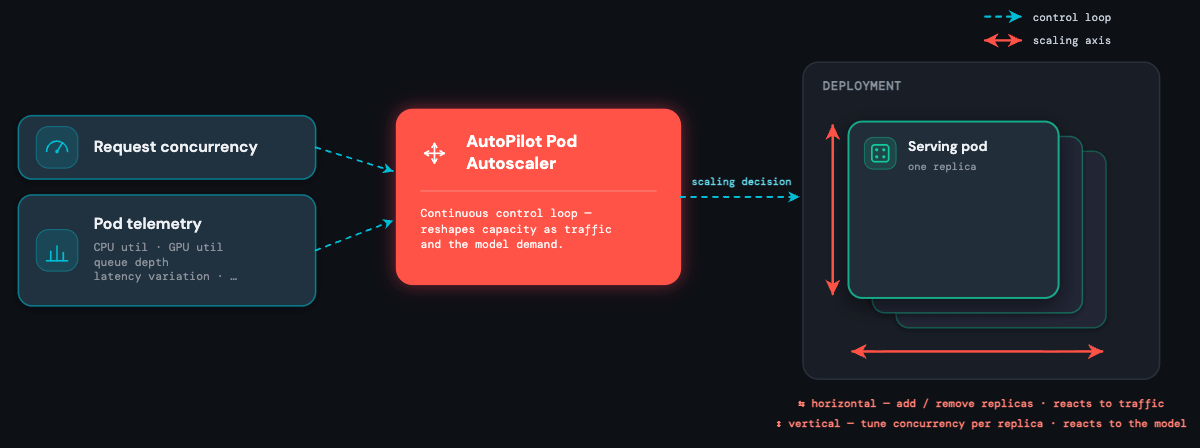
El escalado horizontal reacciona a las solicitudes. Monitorea las solicitudes concurrentes activas por endpoint y agrega o elimina réplicas en el momento en que cambia la demanda. La fórmula sigue al Horizontal Pod Autoscaler de Kubernetes:
El escalado vertical adaptado al modelo reacciona a las características del modelo. Periódicamente, el autoscaler analiza un conjunto de métricas para determinar cuánta carga puede manejar realmente una sola réplica y ajusta target_concurrency en la fórmula anterior en consecuencia. Esto es fundamentalmente diferente del escalado vertical tradicional, que cambia el tipo de hardware. Aquí el hardware sigue siendo el mismo: lo que cambia es cuántas solicitudes simultáneas acepta cada pod, adaptándose al perfil de recursos del modelo que se ejecuta en él.
Las métricas en las que nos basamos incluyen, entre otras, las siguientes:
- Métricas de hardware: utilización de CPU y GPU, utilización de memoria, espera de I/O
- Latencia actual y perfil de profundidad de la cola
- Métricas específicas de GPU: ancho de banda de memoria, utilización de FLOPS de FP16/BF16
Salvaguardas. Los cambios de concurrencia por nodo son delicados, y las variaciones grandes o frecuentes pueden deteriorar el rendimiento del sistema. Las métricas de los pods pueden fluctuar debido a cambios breves en el tráfico o cuando el costo por solicitud es muy diferente para un modelo. Nos protegemos contra este ruido en las métricas. Un pico breve de CPU no debería reducir de inmediato el límite de concurrencia para luego volver a ampliarlo unos segundos después. Para ello, tomamos tres medidas:
La concurrencia se ajusta solo cuando una métrica supera un umbral estable, y los umbrales se ajustan por métrica.
- Limitamos el cambio máximo de concurrencia por ciclo de decisión
- Siempre aplicamos los límites de concurrencia min/max para una carga de trabajo
- Los cambios de concurrencia ocurren a una frecuencia menor (cada 30 s) en comparación con el escalado horizontal. Esto también es importante porque se basan en métricas históricas en lugar del tráfico actual como el HPA.
Los dos ejes están acoplados: el resultado de concurrencia del escalado vertical alimenta el cálculo en el escalado horizontal a través del denominador target_concurrency. El escalado horizontal garantiza la disponibilidad y la baja latencia en el momento en que cambia el tráfico. El escalado vertical adaptado al modelo garantiza que cada nodo se utilice de manera eficiente y ajusta adecuadamente la concurrencia a medida que evoluciona el comportamiento del modelo. Juntos evitan la falsa elección entre rápido pero ineficiente y eficiente pero lento.
Umbrales de escalado ascendente y descendente
La fórmula básica de HPA no es suficiente por sí sola: no es resistente al tráfico con picos repentinos. Un pico breve de 10× calcula un aumento de réplicas de 10×; una breve caída del 95% calcula una disminución del 95%. Ambos son peligrosos, ya sea para el costo o para la latencia y la disponibilidad.
El escalado horizontal ascendente es agresivo En producción, una latencia alta puede significar un impacto comercial negativo masivo. Muchos casos de uso tienen de forma natural patrones de tráfico con picos muy altos que es fundamental admitir. Para manejar los picos, recopilamos las solicitudes entrantes cada 1 segundo y APA toma una decisión de escalado ascendente cada 5 segundos en función del tráfico de los últimos 20 segundos. Esto reduce significativamente las colas y los errores 429 durante los picos; muchos clientes notaron una diferencia de hasta 5 veces. También limitamos cuánto podemos escalar de forma ascendente en un solo ciclo en relación con la carga actual. En general, podemos pasar de 10 a 10K qps en 60 segundos (según el tiempo de carga del modelo)
El escalado descendente es conservador. Un pico a menudo indica que llegará más tráfico. Para el escalado descendente, APA sigue decidiendo cada 5 segundos, pero considera el tráfico de los últimos ~5 minutos antes de eliminar réplicas.
La asimetría es intencional. Los picos son repentinos; las caídas suelen ser temporales. El costo de un escalado descendente prematuro (un inicio en frío en el peor momento posible) supera el costo de mantener temporalmente algunas réplicas inactivas.
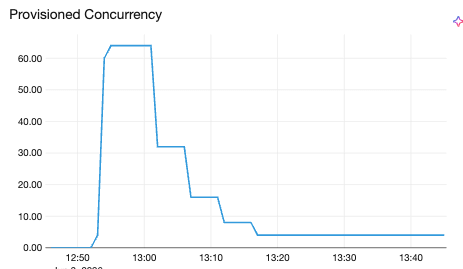
Escalado vertical ascendente y descendente de concurrencia. La misma filosofía asimétrica se aplica al escalado vertical: reducir rápidamente la concurrencia cuando un pod muestra sobrecarga (enrutar menos solicitudes a una réplica ya cargada protege la latencia), pero nunca por debajo de un mínimo. Estas decisiones se ejecutan en un intervalo de 30 segundos, más lento que el bucle horizontal de 5 segundos. Esto es intencional: el escalado vertical es una optimización del estado estable que se adapta al perfil de recursos de un modelo a lo largo del tiempo, no una reacción en tiempo real a los picos.
Minimizar el tiempo de inicio en frío
Un inicio en frío es el peor evento de latencia en un sistema de servicio; no se puede optimizar para solucionarlo una vez que está ocurriendo. Lo atacamos en dos frentes: mantener la mayor cantidad posible precalentada y hacer que las partes inevitables sean lo más rápidas posible.
Grupos de nodos precalentados. Un algoritmo predictivo mantiene un grupo de nodos preaprovisionados por clúster de Databricks, precargados con la imagen de tiempo de ejecución base. Cuando el autoscaler agrega una réplica, la elige de este grupo: el nodo ya está activo, la imagen base ya se ha descargado y el único trabajo restante es descargar el modelo. No cobramos a los clientes por la capacidad del grupo precalentado; es un valor directo que obtienen de Databricks.
Descarga rápida de modelos. Las imágenes de contenedor de modelos se almacenan en una capa de caché activa en el almacenamiento en la nube y se descargan en fragmentos paralelos al iniciar el pod, lo que reduce significativamente el tiempo de descarga de imágenes para contenedores de modelos grandes. Los cambios de configuración que no afectan al modelo ni a sus dependencias (actualizaciones de metadatos de endpoints, cambios en las reglas de enrutamiento) se aplican sin reiniciar el pod en absoluto, ya que evitar un reinicio es el inicio más rápido de todos.
Concurrencia aprovisionada. Para los endpoints críticos para la latencia que no pueden tolerar ningún inicio en frío, los usuarios configuran un límite mínimo de concurrencia. Esto mantiene una línea base de pods completamente listos con el modelo cargado y preparados para servir de inmediato, sin colas en la primera solicitud.
Actualizaciones y mantenimiento sin tiempo de inactividad. Las actualizaciones y el mantenimiento se realizan completamente sin tiempo de inactividad. Todos los pods con la nueva versión del modelo están activos y listos antes de que el tráfico se desvíe de los pods antiguos.
Lo que aprendimos en producción
Los clientes han visto beneficios en todas las dimensiones:
- Costo: Tenemos clientes que han obtenido un ahorro de costos de más del 90% en comparación con sus cargas de trabajo DIY.
- Latencia: La latencia p99 y p50 mejoró hasta 2 veces para muchos clientes.
- Escala: Los clientes han escalado a más de 100K QPS en producción con poco o ningún mantenimiento.
- Sostenemos una disponibilidad del 99.99% en producción.
El autoscaling de dos ejes se generaliza en todos los tipos de modelos. No estábamos seguros de si el enfoque horizontal + vertical se mantendría para todo, desde clasificadores de CPU hasta LLM de GPU. Así es: el eje horizontal maneja el tráfico de la misma manera para cada modelo, mientras que el eje vertical se establece en una mayor concurrencia para los modelos ligeros y menor para los que consumen mucha GPU. El mismo controlador, la misma lógica, el comportamiento adecuado para cada uno.
La mayoría de los modelos son homogéneos. Pensábamos que los límites de concurrencia variarían constantemente con el tráfico; en la práctica, el perfil de recursos de un modelo bajo la misma carga se mantiene casi igual. El eje vertical demuestra su valor durante la incorporación y luego se estabiliza.
No se pueden eliminar por completo los inicios en frío mediante optimización. Esperábamos que los grupos precalentados, las descargas de imágenes en paralelo y la reutilización de implementaciones redujeran los inicios en frío a casi cero. Ayudan enormemente, pero la física tiene un límite: activar un pod requiere un tiempo que aumenta con el tamaño del modelo, minutos para los modelos de GPU grandes. Más allá de ese límite, la única respuesta es mantener una capacidad mínima completamente lista, que es exactamente la razón por la que existe la concurrencia aprovisionada mínima.
El tráfico es más predecible de lo que parece. El mínimo adecuado no es estático: las aplicaciones B2C se calman durante la noche, las canalizaciones por lotes se ejecutan según lo programado. Estos patrones se pueden aprender, y estamos creando una previsión de tráfico para aumentar la concurrencia mínima antes de la demanda en lugar de ir tras ella. Estén atentos a las novedades.
Conclusión
Nos propusimos eliminar el ML Stack Tax: el ajuste continuo y el equipo de servicio dedicado que exige. Para toda la diversidad de modelos que se ejecutan hoy en Custom Model Serving, el autoscaler de dos ejes, los grupos precalentados y las implementaciones sin tiempo de inactividad hacen exactamente eso. La infraestructura se adapta al modelo en lugar de al revés. Usted trae un modelo, establece un rango de concurrencia y la plataforma se encarga del resto.
Sin embargo, el servicio de modelos no es un campo resuelto. Los modelos más grandes, el nuevo hardware y las cargas de trabajo de agentes siguen llevando la escala y la complejidad más allá de lo que la infraestructura de servicio tradicional estaba preparada para soportar. Los problemas abiertos son reales y la ambición es alta: tiempos de inicio en frío más bajos, previsión de tráfico para el escalado predictivo, más de 1M de QPS por endpoint y más de 10M de QPS por clúster, una distribución más inteligente (bin-packing) de cargas de trabajo de GPU heterogéneas y reducir la latencia p99 por debajo de los 5 ms.
Y este es un problema que Databricks está en una posición única para resolver. Adaptar la infraestructura a un modelo significa conocer el modelo: cómo se entrenó, de qué depende y cómo se comporta bajo carga. En Databricks, todo eso reside en una única plataforma gobernada: datos y características, entrenamiento, empaquetado de MLflow, servicio, agentes y la telemetría que los monitorea. Una capa de servicio independiente ve un contenedor; nosotros vemos todo el ciclo de vida. Ese contexto es lo que permite que la plataforma se ajuste a cada modelo, y por qué ningún producto de servicio complementario puede eliminar tan bien el impuesto de la pila de ML.
Si te interesa este tipo de problemas de infraestructura, estamos contratando.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.