Anuncio de compatibilidad total con Apache Iceberg™ en Databricks
Lee y escribe tablas de Iceberg administradas y usa Unity Catalog para acceder y gobernar tablas de Iceberg en catálogos externos
por Ali Ghodsi, Reynold Xin, Adam Conway, Daniel Weeks, Ryan Blue y Jason Reid
- Escribe tablas de Iceberg administradas abiertas usando Databricks o motores externos de Apache Iceberg™ a través de la API REST Catalog de Unity Catalog.
- Accede y gobierna tablas de Iceberg administradas por catálogos externos.
- Estas adiciones impulsan la industria aún más hacia un formato de tabla abierto único y unificado.
Nos complace anunciar la Vista Previa Pública del soporte de Apache IcebergTM en Databricks, desbloqueando los ecosistemas completos de Apache Iceberg y Delta Lake con Unity Catalog. Esta Vista Previa introduce dos nuevas funcionalidades en Unity Catalog. Primero, ahora puedes leer y escribir tablas de Iceberg administradas usando Databricks o motores de Iceberg externos a través de la API de Catálogo REST de Iceberg de Unity Catalog. Impulsadas por Optimización Predictiva, estas tablas ejecutan automáticamente operaciones avanzadas de tablas, incluido el Clúster Líquido, para ofrecer un rendimiento de consulta rápido y eficiencia de almacenamiento listos para usar. Las tablas de Iceberg administradas también se integran con funciones avanzadas en la plataforma Databricks, incluidas DBSQL, Databricks, Delta Sharing y MVs. Segundo, como parte de Federación de Lakehouse, Unity Catalog ahora te permite acceder y gobernar sin problemas tablas de Iceberg administradas por catálogos externos como AWS Glue, Hive Metastores y Snowflake Horizon Catalog.
Con estas nuevas funcionalidades, puedes conectarte a Unity Catalog desde cualquier motor y acceder a todos tus datos, a través de catálogos e independientemente del formato, rompiendo silos de datos y resolviendo incompatibilidades del ecosistema. En este blog, cubriremos:
- Identificación de nuevos silos de datos
- Uso de Unity Catalog como un catálogo de Iceberg completamente abierto
- Extensión de la gobernanza de UC a todo el Lakehouse
- Nuestra visión para el futuro de los formatos de tabla abiertos
Los nuevos silos de datos
Han surgido nuevos silos de datos en torno a dos componentes fundamentales del Lakehouse: formatos de tabla abiertos y catálogos de datos. Los formatos de tabla abiertos permiten transacciones ACID en datos almacenados en almacenamiento de objetos. Delta Lake y Apache Iceberg, los dos formatos de tabla abiertos líderes, desarrollaron ecosistemas de conectores en una amplia gama de marcos de código abierto y plataformas comerciales. Sin embargo, la mayoría de las plataformas populares solo adoptaron uno de los dos estándares, lo que obligó a los clientes a elegir motores al elegir un formato.
Los catálogos introducen desafíos adicionales. Una responsabilidad central de un catálogo es administrar los archivos de metadatos actuales de una tabla entre escritores y lectores. Sin embargo, algunos catálogos restringen qué motores tienen permitido escribir en ellos. Incluso si logras almacenar todos tus datos en un formato compatible con todos tus motores, es posible que aún no puedas usar el motor elegido porque no puede conectarse a tu catálogo. Este bloqueo de proveedor obliga a los clientes a fragmentar el descubrimiento y la gobernanza de datos en catálogos dispares.
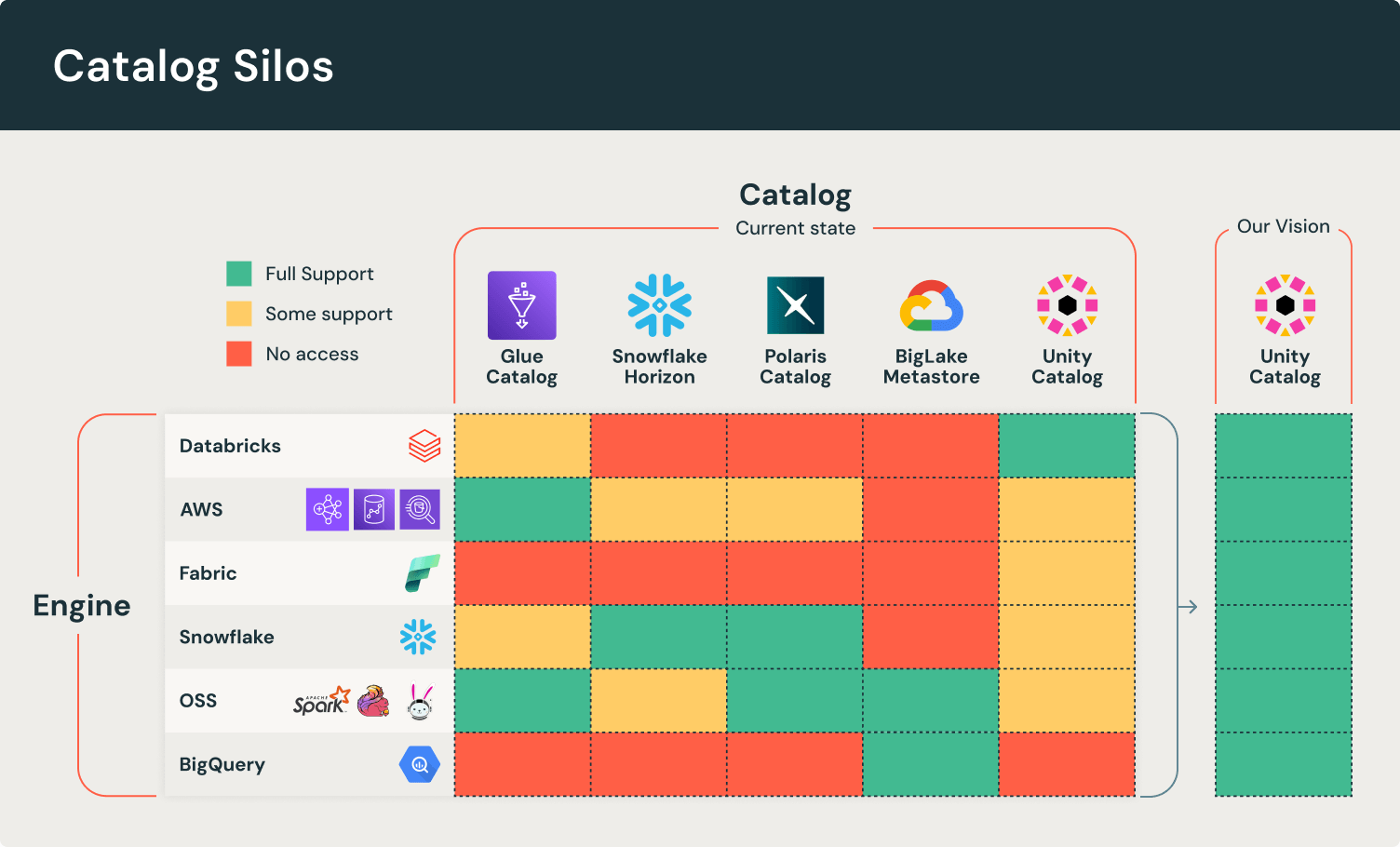
En las próximas dos secciones, cubriremos cómo Unity Catalog utiliza estándares abiertos y federación de catálogos para resolver incompatibilidades de formato y catálogo.
Un Catálogo de Iceberg Completamente Abierto
Unity Catalog rompe los silos de formato a través de estándares abiertos. Ahora en Vista Previa Pública, puedes usar Databricks y motores externos para escribir tablas de Iceberg administradas por Unity Catalog. Las tablas de Iceberg administradas están completamente abiertas al ecosistema de Iceberg a través de la implementación de Unity Catalog de las API de Catálogo REST de Iceberg. El Catálogo REST es una especificación de API abierta que proporciona una interfaz estándar para interactuar con tablas de Iceberg. Unity Catalog fue uno de los primeros en adoptar el Catálogo REST, lanzando por primera vez el soporte en 2023. Esta Vista Previa se basa en esa base. Ahora, prácticamente cualquier cliente de Iceberg compatible con la especificación REST, como Apache Spark™, Apache Flink o Trino, puede leer y escribir en Unity Catalog.
Planeamos almacenar todos nuestros datos en un formato abierto y queremos un único catálogo que pueda conectarse a todas las herramientas que usamos. Unity Catalog nos permite escribir tablas de Iceberg que están completamente abiertas a cualquier cliente de Iceberg, desbloqueando todo el ecosistema del Lakehouse y asegurando nuestra arquitectura para el futuro. —Hen Ben-Hemo, Arquitecto de Plataforma de Datos

Con Iceberg Administrado, puedes llevar la gobernanza de Unity Catalog al ecosistema de Iceberg, incluso entre herramientas OSS como PyIceberg que no admiten autorización de forma nativa. Unity Catalog te permite crear canalizaciones de datos que abarcan todo el ecosistema del Lakehouse. Por ejemplo, Apache Iceberg ofrece un conector sink popular para escribir desde Kafka a tablas de Iceberg. Puedes usar Kafka Connect para escribir tablas de Iceberg en Unity Catalog y, downstream, usar las capacidades de rendimiento de precio de Databricks para ETL, almacenamiento de datos y aprendizaje automático.
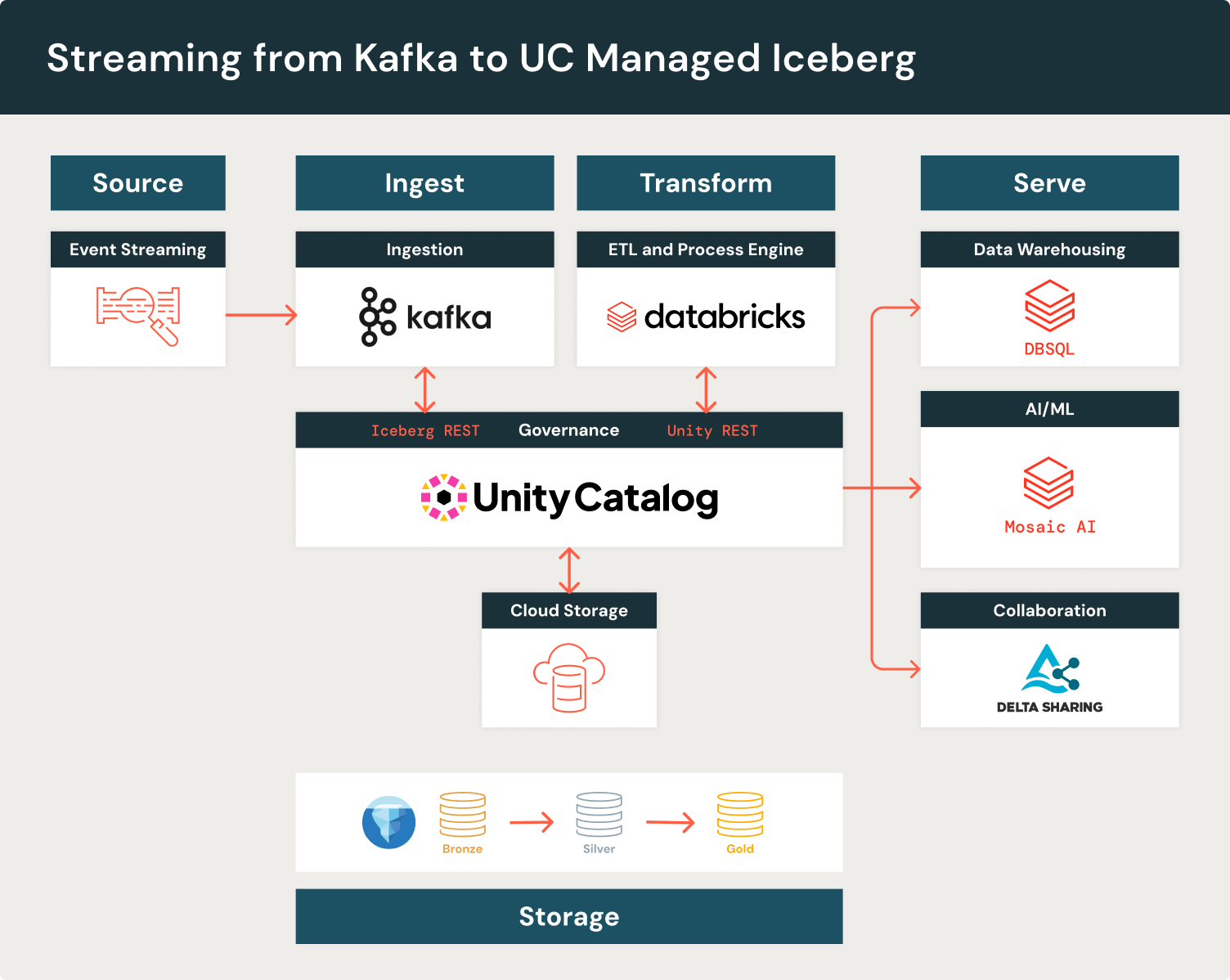
Todas las Tablas Administradas ofrecen automáticamente el mejor rendimiento de lectura y optimización de almacenamiento utilizando Optimización Predictiva. Optimización Predictiva expira automáticamente las instantáneas antiguas, elimina los archivos no referenciados y agrupa incrementalmente tus datos utilizando Clúster Líquido. En nuestro ejemplo usando Kafka, esto previene la degradación del rendimiento comúnmente causada por la proliferación de archivos pequeños. Puedes mantener tus tablas de Iceberg saludables y de alto rendimiento sin la molestia de administrar manualmente tu propio mantenimiento de tablas.
Las tablas de Iceberg administradas se integran con la plataforma Databricks, lo que te permite aprovechar estas tablas con funciones avanzadas de la plataforma como DBSQL, Databricks, Delta Sharing y MVs. Más allá de Databricks, Unity Catalog admite un ecosistema de socios para aterrizar datos de forma segura en Iceberg utilizando herramientas externas. Por ejemplo, Redpanda ingiere datos de streaming producidos en temas de Kafka a través de la API de Catálogo REST de Iceberg de Unity Catalog:
Con las Tablas de Iceberg Administradas de Unity Catalog y el Catálogo REST de Iceberg, Redpanda ahora puede transmitir las cargas de trabajo de Kafka más grandes y exigentes directamente a tablas de Iceberg que son optimizadas por Unity Catalog, desbloqueando la descubribilidad lista para usar y un rendimiento de consulta rápido en flujos arbitrarios. Con configuración de un solo clic, todos los datos de streaming en tiempo real ahora están completamente disponibles para el ecosistema de Iceberg, por lo que los clientes pueden tener la confianza de que su arquitectura está construida para durar, sin importar cómo evolucione su pila. —Matthew Schumpert, Jefe de Producto, Plataforma

Estamos entusiasmados de tener a los siguientes socios de lanzamiento a bordo: Atlan, Buf, CelerData, Clickhouse, dbt Labs, dltHub, Fivetran, Informatica, PuppyGraph, Redpanda, RisingWave, StreamNative y más.
El Catálogo del Lakehouse
Con Unity Catalog, puedes interoperar no solo entre formatos de tabla, sino también entre catálogos. Ahora también en Vista Previa Pública, puedes consultar y gobernar sin problemas tablas de Iceberg administradas por catálogos externos como AWS Glue, Hive Metastores y Snowflake Horizon Catalog. Extendiendo la Federación de Hive Metastore y AWS Glue, estos conectores te permiten montar catálogos completos dentro de Unity Catalog, creando una interfaz unificada para el descubrimiento y la gobernanza de datos.

La federación proporciona una integración perfecta para aprovechar las funciones avanzadas de Unity Catalog en tablas de Iceberg administradas por catálogos externos. Puedes usar los controles de acceso detallados, el linaje y la auditoría de Databricks en todos tus datos, a través de catálogos e independientemente del formato.
Unity Catalog permite a los ingenieros de ML y científicos de datos de Rippling acceder sin problemas a tablas de Iceberg en almacenes OLAP existentes con cero copias. Esto nos ayuda a reducir costos, crear fuentes de verdad consistentes y reducir la latencia de la actualización de datos, todo mientras mantenemos altos estándares en el acceso y la privacidad de los datos a lo largo de todo el ciclo de vida de los datos. —Albert Strasheim, Director de Tecnología

Con la federación, Unity Catalog puede gobernar la totalidad de tu Lakehouse, a través de todas tus tablas, modelos de IA, archivos, cuadernos y paneles.
El Futuro de los Formatos de Tabla
Unity Catalog está acercando la industria a la realización de la simplicidad, flexibilidad y menores costos del lakehouse de datos abierto. En Databricks, creemos que podemos hacer avanzar la industria aún más, con un formato de tabla abierto único y unificado. Delta Lake y Apache Iceberg comparten gran parte del mismo diseño, pero diferencias sutiles causan grandes incompatibilidades para los clientes. Para resolver estos problemas compartidos, las comunidades de Delta y Apache Iceberg están alineando conceptos y contribuciones, unificando el ecosistema Lakehouse.
Iceberg v3 es un gran paso hacia esta visión. Iceberg v3 incluye características clave como Deletion Vectors, Variant data type, Row IDs y geospatial data types que comparten implementaciones idénticas en Delta Lake. Estas mejoras te permiten mover datos y eliminar archivos entre formatos fácilmente, sin reescribir petabytes de datos.
En futuras versiones de Delta Lake y Apache Iceberg, queremos construir sobre esta base para que los clientes de Delta e Iceberg puedan usar los mismos metadatos y, por lo tanto, puedan compartir tablas directamente. Con estas inversiones, los clientes pueden realizar el objetivo original de un lakehouse de datos abierto: una plataforma totalmente integrada para datos e IA en una sola copia de datos.
Las tablas de Iceberg administradas y externas ahora están disponibles en vista previa pública. Consulta nuestra documentación para empezar. Vuelve a ver nuestros anuncios en Data and AI Summit del 9 al 12 de junio de 2025 para obtener más información sobre nuestras características más recientes de Iceberg y el futuro de los formatos de tabla abiertos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.