Anuncio del Feed de Cambios de Datos (CDF) de Lakebase
Abriendo la base de datos OLTP a otros motores
- El Feed de Cambios de Datos (CDF) de Lakebase (Vista Previa Pública) elimina la proliferación de pipelines desde bases de datos operativas. Active el CDF una vez por proyecto de Lakebase para exponer los cambios de cada tabla a través de Tablas Administradas de Unity Catalog para acceso de lectura directa por cualquier motor, modelo o agente.
- CDC nativo gobernado de extremo a extremo sin infraestructura secundaria: sin conectores de base de datos, monitoreo de estado de replicación ni trabajos de extracción separados; los consumidores downstream como pipelines de streaming SDP, vistas materializadas DBSQL y embeddings de Agent Bricks se suscriben al mismo feed aislado sin impactar la carga de trabajo principal.
- Los datos operativos ahora funcionan como la capa Bronze nativa en la arquitectura medallion. Las Tablas Sincronizadas de Lakebase ya sirven datos Gold a las aplicaciones; Lakebase CDF cierra el ciclo con gobernanza y linaje completos de Unity Catalog en todo el ciclo de vida de los datos.
Mover datos desde su base de datos operativa tradicionalmente significaba configurar y monitorear un pipeline desde cada fuente a cada destino. Para la mayoría de los equipos, esto es un esfuerzo humano frágil, sin gobernar y de orden O(n).
Hoy, estamos cambiando este enfoque. Disponible ahora en Vista Previa Pública, Lakebase presenta un Feed de Cambios de Datos (CDF) que se almacena y se gobierna en Tablas Administradas de Unity Catalog. Habilite el feed una vez y permita que todos los motores, modelos y agentes lean directamente de él.
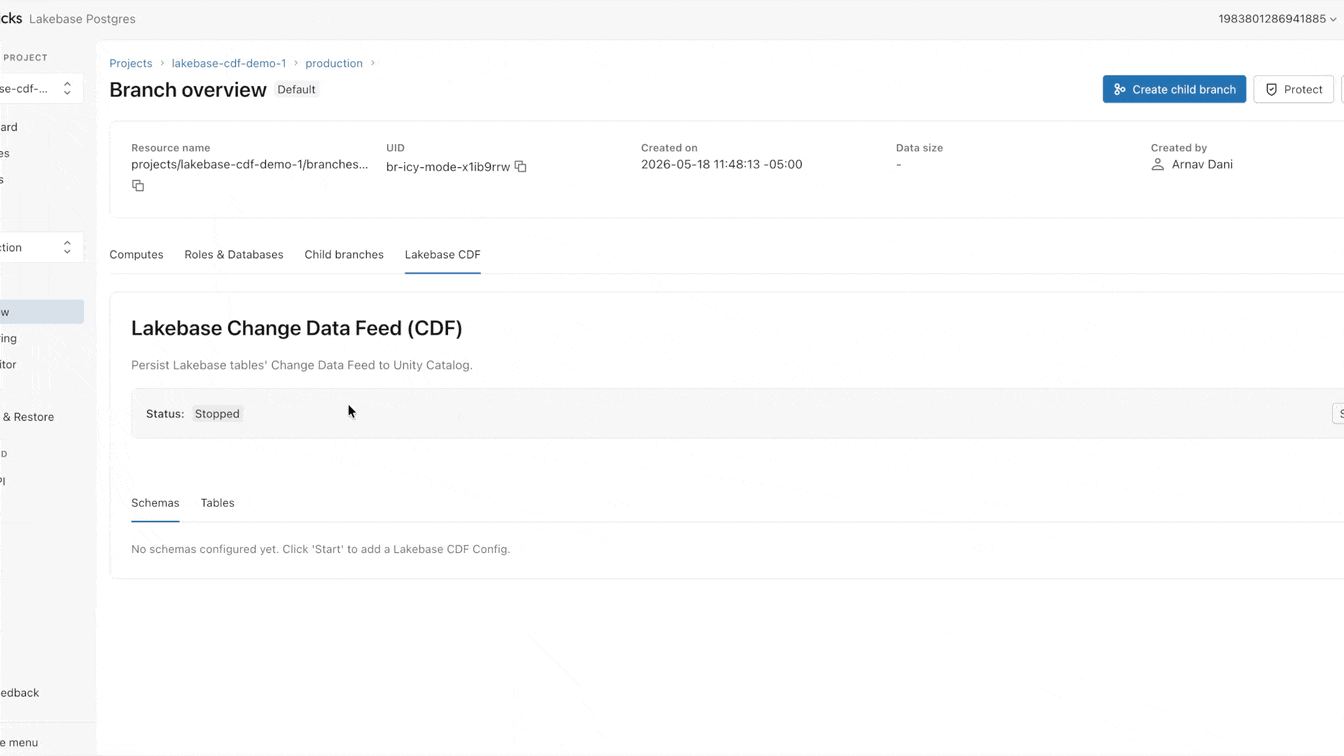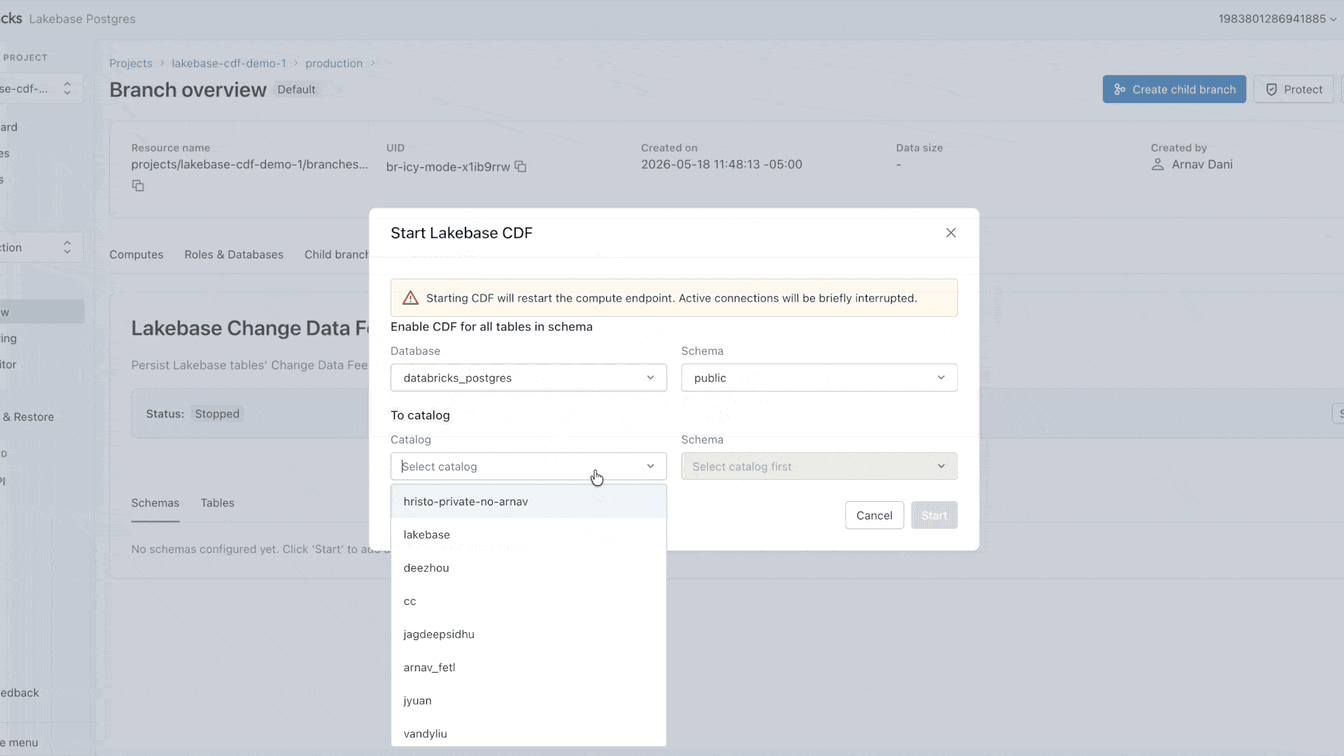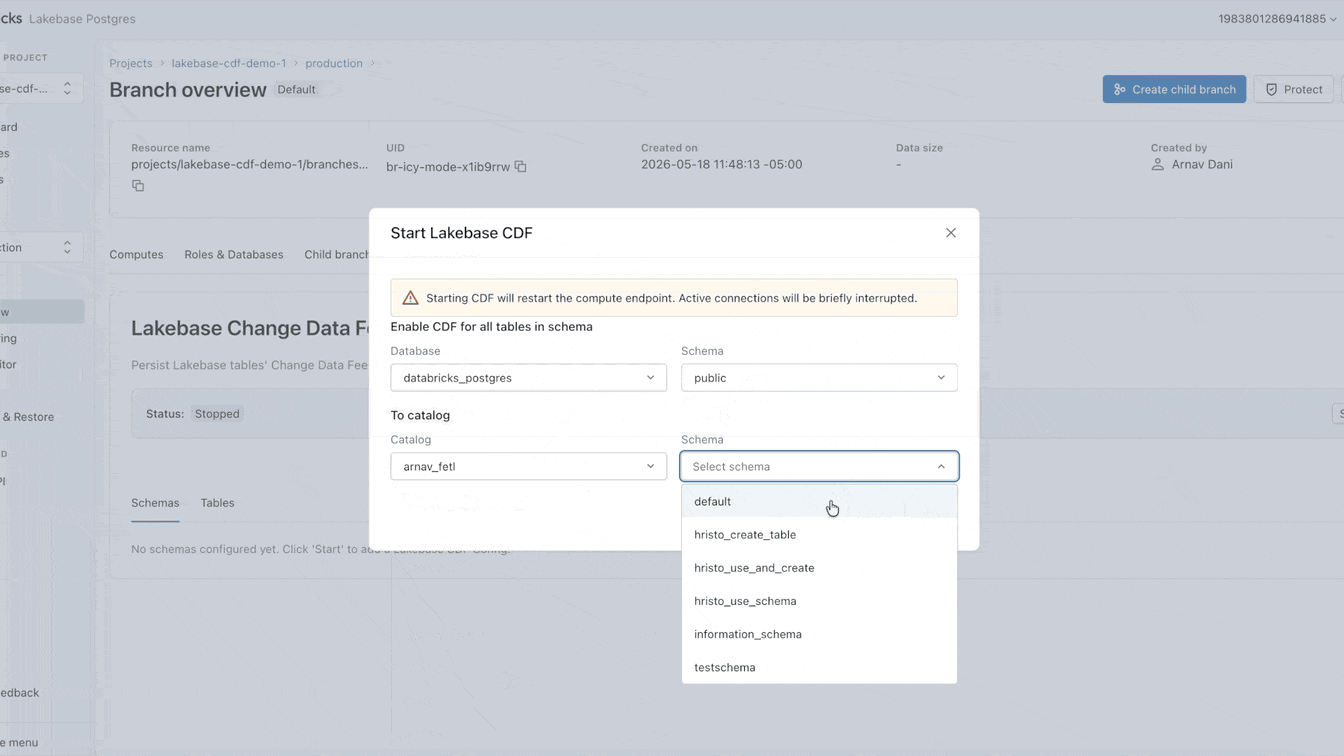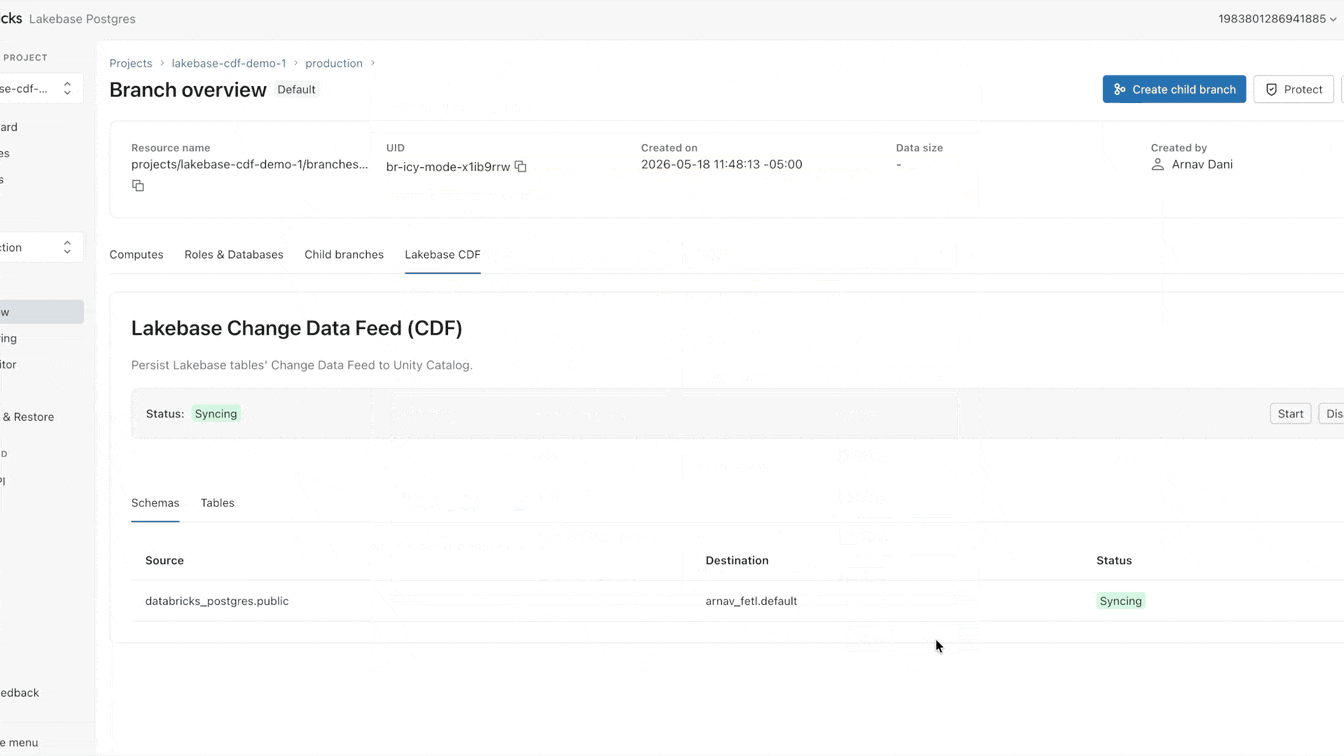
¿Por qué sigue siendo tan difícil cargar datos operativos en el lake?
Si bien Lakeflow Connect ha hecho que la ingesta de datos en el Lakehouse sea trivial, extraer datos de la base de datos OLTP sigue siendo un proceso manual y de alta fricción. Extraer la Captura de Datos de Cambios (CDC) obliga a los equipos a configurar conectores de bases de datos, supervisar los estados de replicación, mitigar los impactos en el rendimiento y rastrear errores a través de herramientas desconectadas. Este modelo se desmorona en el desarrollo basado en agentes que depende de la ramificación rápida de datos. Mantener pipelines de extracción complejos y sin gobernar para cada nueva rama a cada destino no es sostenible.
Lo resolvimos en el Lakehouse. Ahora lo llevamos a Lakebase.
El Lakehouse eliminó los pipelines de extracción para análisis al almacenar datos una vez en formatos abiertos (Apache Iceberg™, Delta Lake). Estableció el Feed de Cambios de Datos (CDF) como el estándar para la replicación downstream, potenciando flujos de trabajo ETL, de streaming y registros de auditoría.
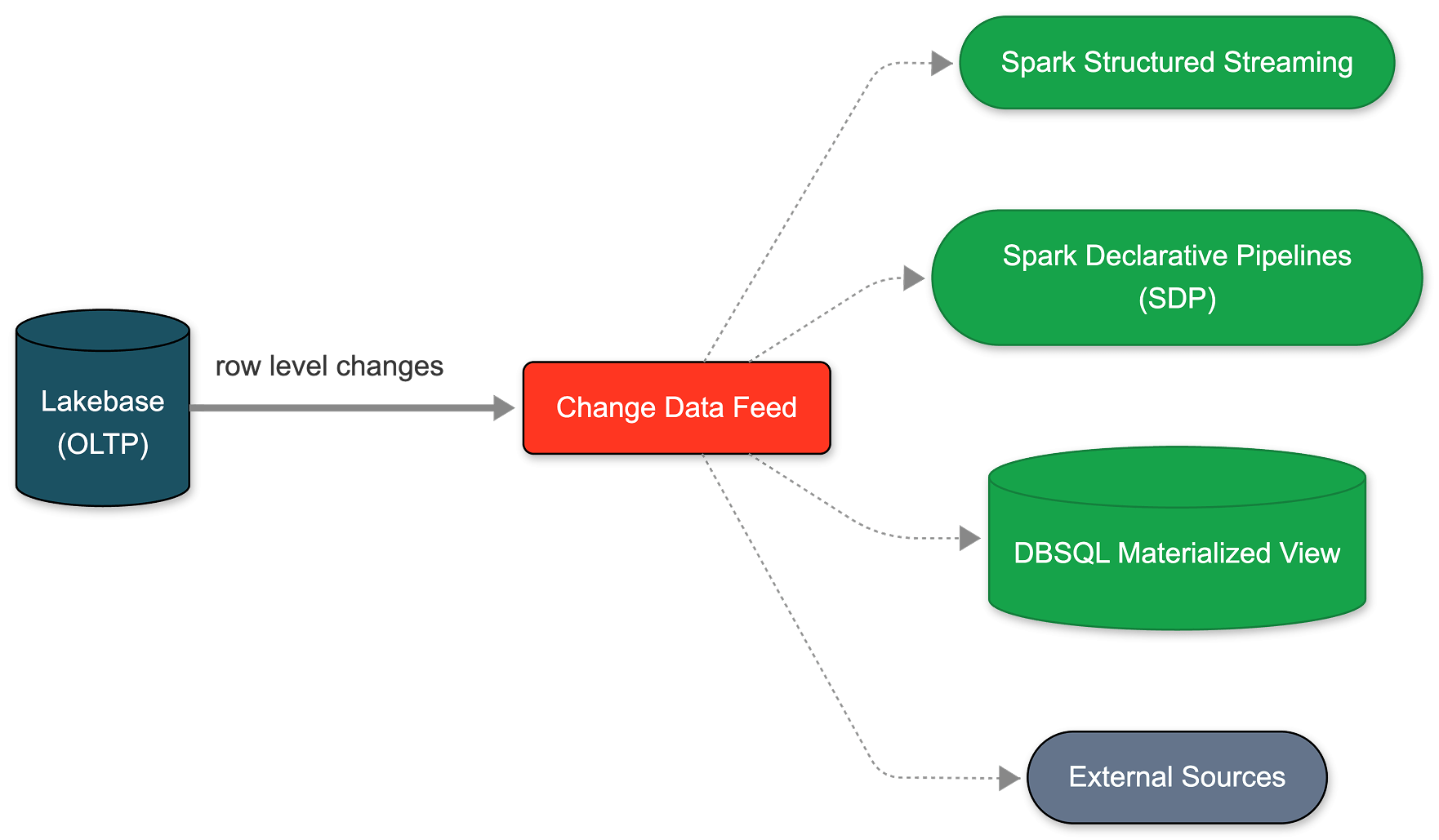
Ahora puede configurar ese CDF de forma nativa en Lakebase. Habilitarlo toma menos de un minuto y se aplica a todas las tablas dentro de un proyecto. Desde este único feed, puede construir pipelines de streaming con SDP, generar vistas materializadas con DBSQL o computar y almacenar embeddings con Agent Bricks. Cada consumidor downstream se suscribe al mismo feed exacto, completamente aislado de su carga de trabajo operativa principal.
Las bases de datos operativas pertenecen a la arquitectura medallion
Con Lakebase, sus datos operativos ya no están aislados del Lakehouse. Lakebase ya ofrece Tablas Sincronizadas, estableciendo el patrón de servir datasets Gold directamente a las aplicaciones. Lakebase CDF completa la arquitectura. Su base de datos operativa es ahora su capa Bronze nativa, eliminando la necesidad de pipelines separados o trabajos de extracción para cargar datos en el Lakehouse. En su lugar, obtiene gobernanza y linaje completos en todo el ciclo de vida de los datos a través de Unity Catalog.
Esto es solo el comienzo. Estamos llevando la apertura que ama del Lakehouse directamente a Lakebase. Manténgase atento a la Data and AI Summit y únase a nuestra sesión breakout sobre esta arquitectura.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.