Anunciando la vista previa pública de Lakebase
Postgres totalmente administrado para aplicaciones de datos y agentes de IA
por Jasraj Dange, Andrei Dragus, Dave Nettleton, Hans Norheim, Susan Pierce y Reynold Xin
- Las bases de datos tradicionales son lentas y caras de aprovisionar, no escalan bien, están aisladas de las plataformas de análisis y no encajan en un flujo de trabajo de desarrollador moderno.
- Lakebase es una base de datos Postgres totalmente administrada, integrada con el lakehouse y construida para IA.
- Las empresas utilizan Lakebase para servir datos y características del lakehouse, potenciar aplicaciones inteligentes independientes y analizar datos operativos en el lakehouse.
En la Data and AI Summit, presentamos una nueva categoría de bases de datos operacionales llamada lakebases para crear aplicaciones inteligentes. Hoy, nos complace anunciar la Vista Previa Pública de Databricks Lakebase, la primera base de datos Postgres totalmente administrada creada para aplicaciones de datos e IA.
Los clientes están combinando sus datos operacionales y analíticos para crear aplicaciones inteligentes: sirviendo características y modelos, creando aplicaciones independientes o analizando datos operacionales en un lakehouse. Pero continúan luchando con el aprovisionamiento, la escalabilidad y la falta de una experiencia de desarrollo moderna para los datos, ya que las bases de datos no han visto mucha innovación en las últimas décadas.
Las Lakebases ofrecen una solución para la era de la IA. En este blog, presentaremos las características y beneficios clave de Databricks Lakebase, y describiremos cómo los clientes ya utilizan Lakebase hoy en día.
Presentamos Lakebase
Las bases de datos OLTP no han cambiado fundamentalmente desde los años 90. Incluso cuando se implementan en la nube, estas bases de datos heredadas son lentas y costosas de aprovisionar y administrar. Las bases de datos operacionales se implementan típicamente en una pila separada de la plataforma de análisis, creando silos entre los datos transaccionales y analíticos. Además, estas bases de datos tampoco encajan en un flujo de trabajo de desarrollo moderno necesario para el desarrollo de IA. La arquitectura tradicional generalmente implica bases de datos separadas para entornos de desarrollo, pruebas, staging y producción, cada una aprovisionada, poblada y mantenida por separado.
Databricks Lakebase es una base de datos pionera creada sobre estándares de código abierto, con una arquitectura altamente escalable, basada en la separación de cómputo y almacenamiento, diseñada específicamente para el desarrollo de aplicaciones modernas. Lakebase está profundamente integrado en el lakehouse para facilitar la combinación de pilas operacionales, analíticas y de IA.
Creado sobre Postgres de código abierto
Durante los últimos 7 años, Postgres se ha convertido en la base de datos más popular en la comunidad de desarrolladores y es la opción de base de datos de facto para aplicaciones modernas. Es de código abierto, tiene un ecosistema vibrante de extensiones y está respaldado por una sólida comunidad de bibliotecas, herramientas y frameworks. Los ingenieros ya saben cómo trabajar con él, y todos los modelos fundamentales se entrenan con grandes cantidades de datos disponibles para el ecosistema Postgres, lo que lo hace muy accesible para aplicaciones y agentes inteligentes.
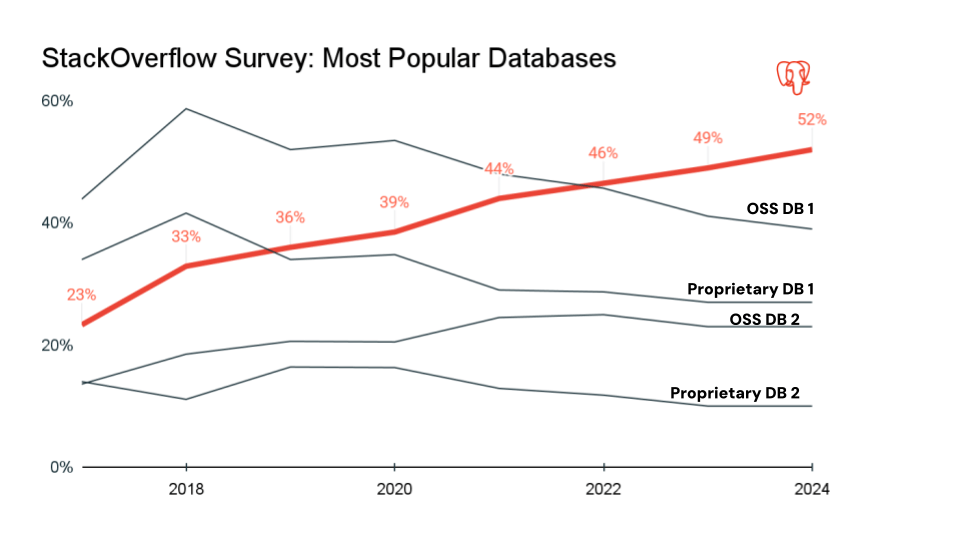
Con soporte para extensiones populares como PostGIS y pgvector, y un amplio ecosistema de drivers y herramientas, Lakebase proporciona un rico conjunto de capacidades que serán familiares para los equipos de desarrollo.
Separación de Cómputo y Almacenamiento
Lakebase aprovecha una arquitectura que separa el cómputo y el almacenamiento, lo que permite una escalabilidad independiente mientras soporta transacciones de baja latencia (<10ms) y alta concurrencia (>10k qps).
Lakebase es totalmente administrado por Databricks, lo que significa que no hay infraestructura que aprovisionar o mantener. El resultado es un servicio de base de datos que elimina la fricción tanto de los procesos de infraestructura como de desarrollo, permitiendo a los equipos avanzar más rápido sin comprometer el control o la fiabilidad.
- Alta disponibilidad con réplicas legibles: La alta disponibilidad multizona protege contra fallos zonales aprovisionando recursos de cómputo secundarios en diferentes zonas. Las réplicas pueden ser opcionalmente legibles para proporcionar aislamiento y escalabilidad horizontal de las cargas de trabajo de lectura.
- Almacenamiento y recuperación de datos: Todas las transacciones se persisten en almacenamiento cifrado que es duradero a nivel regional y, por lo tanto, protegido contra cualquier fallo de zona única. La recuperación puntual está disponible a través de una ventana de protección de datos que proporciona hasta 35 días de tiempo de recuperación.
- Ramificaciones para un entorno de prueba aislado o recuperación puntual: Lakebase utiliza ramificación copy-on-write para crear un clon instantáneo de cero copias de la base de datos, junto con cómputo dedicado para operar sobre esa rama. La rama hija se gestiona de forma independiente de la rama principal padre, y se puede crear basándose en los datos de la rama padre en el momento actual, o en un momento anterior o en un número de secuencia de registro (LSN). Esto se puede utilizar para crear un entorno de prueba aislado con datos de producción o para operaciones de recuperación puntual.
DevEx Moderna, Creada para IA
Lakebase está construido sobre la tecnología Neon, que proporciona ramificación copy-on-write y cómputo sin servidor con escalado automático. La ramificación copy-on-write hace posible crear instantáneamente una nueva base de datos con los mismos datos y esquema que una base de datos existente, sin afectar a la original. Esta nueva base de datos es económicamente ventajosa porque no duplica los datos subyacentes. El escalado automático del cómputo sin servidor proporciona tiempos de inicio inferiores a un segundo, y escala según la demanda, permitiendo un uso rentable del cómputo con escalado a cero.
En conjunto, el escalado automático sin servidor del cómputo y las capacidades de ramificación cambian completamente el paradigma de desarrollo de aplicaciones. Los desarrolladores pueden crear instantáneamente una rama de base de datos para que coincida con cada rama de git y no tienen que preocuparse por configurar nuevas instancias de base de datos, muestrear datos para entornos de desarrollo o prueba, o poblar múltiples bases de datos.
Para desarrolladores y agentes por igual, esto significa que los entornos de bases de datos efímeros se pueden crear, usar y desmantelar rápidamente con un costo prácticamente nulo y un esfuerzo prácticamente nulo.
La experiencia completa de desarrollador de Neon en Lakebase y muchas más características emocionantes estarán disponibles pronto.
Integrado con el lakehouse
Lakebase integra una capa de base de datos transaccional con el lakehouse y hereda la madurez operacional de la Plataforma Databricks, incluyendo observabilidad, seguridad y controles de acceso. Lakebase se sincroniza con las tablas administradas de Unity Catalog, lo que facilita y agiliza la combinación de cargas de trabajo operacionales, analíticas y de IA sin canalizaciones ETL personalizadas. Como resultado, puede crear aplicaciones inteligentes que consuman características o predicciones generadas en el lakehouse y actualicen la capa analítica con datos operacionales frescos, todo dentro de una plataforma unificada.
- Sincronización de datos totalmente administrada: Las canalizaciones de sincronización de datos fáciles de configurar proporcionan una forma sencilla y escalable de gestionar datos entre las tablas administradas de Unity Catalog y Lakebase. Las opciones de frecuencia de sincronización de datos incluyen instantánea única, activada o continua.
- Servicio de características y modelos: Sirva características y modelos de machine learning para aplicaciones con Lakebase como el almacén de características en línea, y el lakehouse como el almacén sin conexión para entrenamiento y análisis.
- Gobernanza unificada: Aproveche la integración nativa con Unity Catalog y la identidad de Databricks para simplificar el control de acceso en toda la plataforma. Utilice la identidad de Databricks y OAuth para mantener una identidad coherente entre sus usuarios operacionales y analíticos. Registre una base de datos Postgres en Unity Catalog para proporcionar gobernanza unificada y control de acceso para los usuarios analíticos.
- Integración con Databricks Apps: Cree y despliegue aplicaciones full-stack en Databricks con Lakebase potenciando las interacciones transaccionales. Databricks Apps soporta Lakebase como un tipo de recurso nativo.
- Entorno de desarrollo unificado: Utilice el Editor SQL de Databricks para consultar directamente Lakebase, así como para explorar datos.
- Monitoreo incorporado: Proporciona métricas clave de la base de datos como transacciones por segundo, número de conexiones abiertas y utilización de recursos.
- Seguridad de red: Lakebase se integra con las características de seguridad de red empresarial de Databricks, incluyendo PrivateLink y ACLs de IP, para proporcionar una seguridad de red consistente.
- Multinube: Lakebase está disponible en diferentes proveedores de nube sin necesidad de replataforma. En Vista Previa Pública, Lakebase está disponible en Azure y AWS, con soporte para Google Cloud Platform que se añadirá en el futuro.
Los clientes utilizan Lakebase
Con cientos de clientes en el programa de Vista Previa Privada, ha sido emocionante ver la variedad de casos de uso, incluyendo:
- Servir datos y/o características desde el lakehouse para aplicaciones como recomendaciones personalizadas, o segmentación de clientes,
- Crear aplicaciones y agentes para procesamiento de pedidos, aprobación de flujos de trabajo interactivos y chatbots.
- Analizar datos operacionales en el lakehouse sincronizando datos al lakehouse para análisis de pedidos históricos, o historial de chatbots para datos de entrenamiento.

En Heineken, nuestro objetivo es ser la cervecera mejor conectada. Para lograrlo, necesitábamos una forma de unificar todos nuestros conjuntos de datos para acelerar el camino de los datos al valor. Databricks ha sido durante mucho tiempo nuestra base para el análisis, creando información como recomendaciones de productos y mejoras en la cadena de suministro. Nuestra plataforma de datos analíticos está evolucionando para ser una plataforma de datos de IA operativa y necesita entregar esos insights a las aplicaciones con baja latencia. —Jelle Van Etten, Head of Global Data Platform, Heineken
En Tibber, empoderar a los clientes para que tomen el control de su consumo de energía requiere una infraestructura de datos flexible. La integración de Lakebase con Databricks facilita el servicio de datos analíticos y transaccionales, ayudándonos a ofrecer información en tiempo real a nuestros clientes. —Niklas Nordansjö, Data Platform Lead, Tibber AS
Una sólida red de socios ayuda a los clientes de Lakebase a trabajar con sus socios tecnológicos y System Integrators existentes para la integración de datos, inteligencia de negocios y gobernanza. Estamos entusiasmados de contar con un increíble grupo de socios de lanzamiento de la industria para Lakebase.

En dbt Labs, estamos cambiando la forma en que se realiza la ingeniería de datos. Con el nuevo Lakebase de Databricks, nuestros clientes conjuntos ahora podrán combinar datos transaccionales de baja latencia y datos analíticos en una sola plataforma en Databricks. Esto nos ayudará a ambos a ofrecer IA a escala empresarial para nuestros clientes. Estamos ansiosos por marcar el comienzo de la nueva era de análisis con Databricks. —Ryan Segar, Chief Product Officer, dbt Labs
Resumen
Lakebase combina la familiaridad y extensibilidad de Postgres, la escalabilidad de una arquitectura moderna sin servidor, una experiencia de desarrollador moderna, con la experiencia de datos unificada del lakehouse y la madurez operativa de la Plataforma de Inteligencia de Datos de Databricks. Al combinar estos elementos en una oferta única y totalmente administrada, Lakebase permite a los equipos crear aplicaciones inteligentes impulsadas por datos sin la complejidad operativa tradicionalmente asociada con los sistemas transaccionales.
Lakebase está disponible en Vista Previa Pública con precios disponibles aquí. Si buscas crear aplicaciones que incorporen análisis e IA, es la pieza que falta en tu stack, lista para acelerar el desarrollo y simplificar las operaciones. Si eres un administrador de Workspace o de Cuenta, puedes habilitarlo directamente desde tu Databricks Workspace. ¡Pruébalo hoy mismo!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.