Arquitectura de la colaboración global de datos con Delta Sharing
Permita a su organización escalar al compartir datos de manera segura y eficiente entre nubes, plataformas y regiones
por Matei Zaharia, Bilal Obeidat, Tianyi Huang y Giselle Goicochea
Delta Sharing ha evolucionado a OpenSharing, el primer protocolo abierto y neutral con respecto al proveedor para compartir de forma segura activos de IA, incluidos Agent Skills, modelos de IA y datos no estructurados. Lee el anuncio.
En el panorama digital interconectado de hoy, el intercambio de datos y la colaboración entre organizaciones y plataformas son cruciales para las operaciones comerciales modernas. Delta Sharing, un innovador protocolo abierto de intercambio de datos, permite a las organizaciones compartir y acceder a datos de forma segura en diversas plataformas, priorizando la seguridad y la escalabilidad sin las limitaciones de un proveedor o formato de datos específico.
Este blog está dedicado a presentar las opciones de replicación de datos dentro de Delta Sharing mediante la exploración de guías de arquitectura adaptadas a escenarios específicos de intercambio de datos. Basándonos en nuestra experiencia con muchos clientes de Delta Sharing, nuestro objetivo es reducir los costos de salida de datos (egress) y mejorar el rendimiento al proporcionar alternativas específicas de replicación de datos. Aunque el intercambio en tiempo real (live sharing) sigue siendo adecuado para muchos escenarios de intercambio de datos entre regiones, existen casos en los que replicar todo el conjunto de datos y establecer un proceso de actualización de datos para las réplicas regionales locales resulta más rentable. Delta Sharing facilita esto mediante el uso del almacenamiento Cloudflare R2, Change Data Feed (CDF) Delta Sharing y las funcionalidades de Delta Deep Cloning. Como resultado de estas capacidades, Delta Sharing es muy valorado por los clientes por empoderar a los usuarios y brindar una flexibilidad excepcional para satisfacer sus necesidades de intercambio de datos.
Delta Sharing es abierto, flexible y rentable
Databricks y la Linux Foundation desarrollaron Delta Sharing para proporcionar el primer enfoque de código abierto para el intercambio de datos en datos, analítica e IA. Los clientes pueden compartir datos en tiempo real entre plataformas, nubes y regiones con una sólida seguridad y gobernanza. Ya sea que utilices el proyecto de código abierto mediante alojamiento propio o el servicio totalmente administrado de Delta Sharing en Databricks, ambos ofrecen una solución flexible, rentable e independiente de la plataforma para la entrega global de datos. Los clientes de Databricks reciben beneficios adicionales dentro de un entorno administrado que minimiza la sobrecarga administrativa y se integra de forma nativa con Databricks Unity Catalog. Esta integración ofrece una experiencia optimizada para el intercambio de datos dentro y fuera de las organizaciones.
Delta Sharing en Databricks ha experimentado una adopción generalizada en diversos escenarios de colaboración desde su disponibilidad general en agosto de 2022.
En este blog, exploraremos dos patrones de arquitectura comunes en los que Delta Sharing ha desempeñado un papel fundamental para habilitar y mejorar escenarios comerciales críticos:
- Intercambio de datos entre regiones dentro de la empresa
- Modelo de agregador de datos (Hub and Spoke)
Como parte de este blog, también demostraremos que la arquitectura de implementación de Delta Sharing es flexible y se puede ampliar sin problemas para cumplir con nuevos requisitos de intercambio de datos.
Intercambio de datos entre regiones dentro de la empresa
En este caso de uso, ilustraremos un patrón de implementación común de Delta Sharing entre nuestros clientes cuando existe la necesidad comercial de compartir algunos de los datos entre regiones, como tener un equipo de QA en regiones separadas o un equipo de informes interesado en los datos de actividad comercial a nivel global. Por lo general, compartir tablas dentro de la empresa implica:
- Compartir tablas grandes: Existe el requisito de compartir tablas grandes en tiempo real con los destinatarios, donde los patrones de acceso varían. Los destinatarios suelen ejecutar consultas diversas con diferentes predicados. Un buen ejemplo son los datos de clickstream y de actividad del usuario, donde en esos casos el acceso remoto es más adecuado.
- Replicación local: Para mejorar el rendimiento y administrar mejor los costos de salida de datos (egress), algunos datos deben replicarse para crear una copia local, especialmente cuando la región del destinatario tiene un número significativo de usuarios que acceden con frecuencia a estas tablas.
En este escenario, tanto la unidad de negocio del proveedor de datos como la del destinatario comparten la misma cuenta de Unity Catalog, pero tienen diferentes metastores en Databricks.
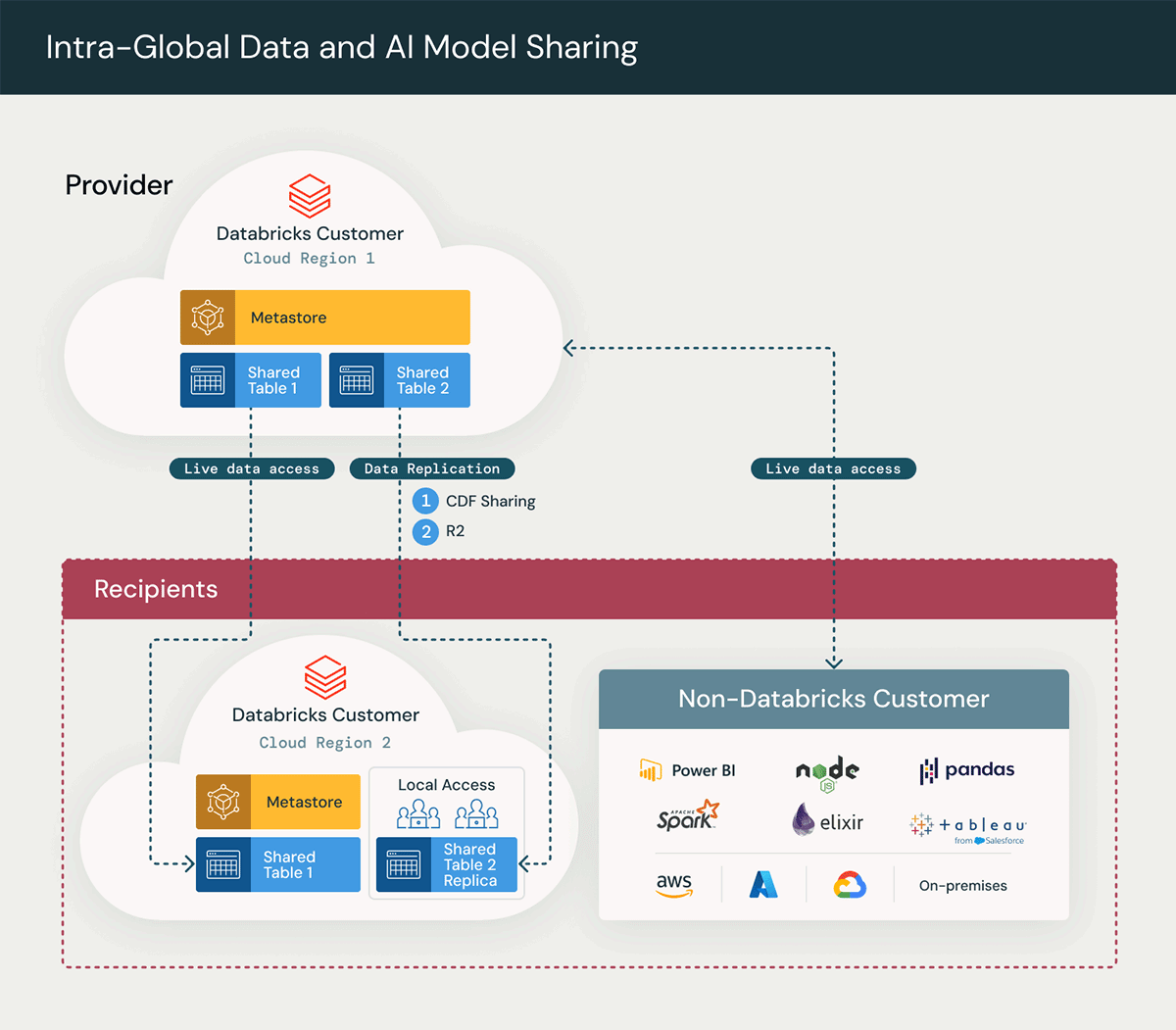
El diagrama anterior ilustra una arquitectura de alto nivel de la solución Delta Sharing, destacando los pasos clave en el proceso de Delta Sharing:
- Creación de un recurso compartido (share): Las tablas en tiempo real se comparten con el destinatario, lo que permite el acceso inmediato a los datos.
- Replicación de datos bajo demanda: La implementación de la replicación de datos bajo demanda implica generar un duplicado regional de los datos para mejorar el rendimiento, reducir la necesidad de acceso a la red entre regiones y minimizar las tarifas de salida de datos asociadas. Esto se logra mediante el uso de los siguientes enfoques para la replicación de datos:
A. Change Data Feed en una tabla compartida
Esta opción requiere compartir el historial de la tabla y habilitar el Change Data Feed (CDF), que debe habilitarse explícitamente en el código de configuración estableciendo la propiedad de la tabla delta.enableChangeDataFeed = true mediante los comandos Create/Alter table.
Además, al agregar la tabla al recurso compartido (Share), asegúrate de que se agregue con la opción CDF, como se muestra en el ejemplo siguiente.
Una vez que se agregan o actualizan los datos, se puede acceder a los cambios como en este ejemplo
En el lado del destinatario, se puede acceder a los cambios y fusionarlos en una copia local de los datos de manera similar a como se muestra en este notebook. La propagación de los cambios desde la tabla compartida a una réplica local se puede orquestar mediante un trabajo de flujo de trabajo (workflow job) de Databricks.
B. Cloudflare R2 con Databricks
R2 es una excelente opción para todos los escenarios de Delta Sharing porque los clientes pueden aprovechar al máximo el potencial de compartir sin preocuparse por cargos de salida de datos (egress) impredecibles. Esto se analiza en detalle más adelante en este blog.
C. Delta Deep Clone
Otra opción de caso especial para el intercambio dentro de la empresa es utilizar Delta Deep Clone cuando se comparte dentro de la misma cuenta de nube de Databricks. El clonado profundo (Deep Cloning) es una funcionalidad de Delta que copia tanto los datos de la tabla de origen como los metadatos de la tabla existente en el destino del clon. Además, el comando de clonado profundo tiene la capacidad de identificar nuevos datos y actualizarlos en consecuencia. Aquí está la sintaxis:
El comando anterior se ejecuta en el lado del destinatario, donde source_table_name es la tabla compartida y table_name es la copia local de los datos a la que pueden acceder los usuarios.
Se puede programar un trabajo simple de Databricks Workflows para una actualización incremental de los datos con las actualizaciones recientes utilizando el siguiente comando:
El mismo caso de uso se puede ampliar fácilmente para compartir datos con socios y clientes externos en la plataforma de Databricks o en cualquier otra plataforma. Este es otro patrón extendido común en el que los socios y clientes externos, que no utilizan Databricks, desean acceder a estos datos a través de Excel, Power BI, Pandas y otros softwares compatibles como Oracle.
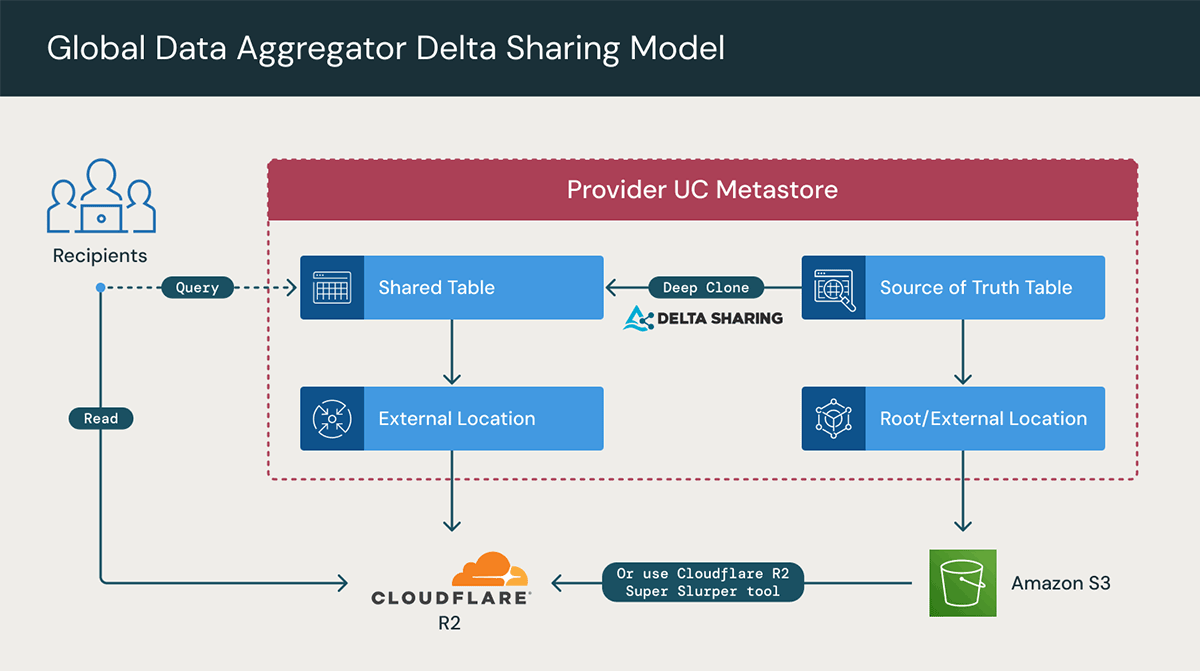
Modelo de agregador de datos (modelo Hub and Spoke)
Otro patrón de escenario común surge cuando una empresa se enfoca en compartir datos con clientes, particularmente en casos que involucran empresas agregadoras de datos o cuando la función comercial principal es recopilar datos en nombre de los clientes. Un agregador de datos, como entidad, se especializa en recopilar y fusionar datos de diversas fuentes en un conjunto de datos unificado y cohesivo. Estos recursos compartidos de datos son fundamentales para atender diversas necesidades comerciales, como la toma de decisiones empresariales, el análisis de mercado, la investigación y el respaldo de las operaciones comerciales generales.
El modelo de intercambio de datos en este patrón hace lo siguiente:
- Conecta a destinatarios distribuidos en varias nubes, incluidas AWS, Azure y GCP.
- Admite el consumo de datos en diversas plataformas, con una complejidad que va desde código Python hasta hojas de cálculo de Excel.
- Permite la escalabilidad del número de destinatarios, la cantidad de recursos compartidos y los volúmenes de datos.
En general, esto se puede lograr si el proveedor establece un espacio de trabajo de Databricks en cada nube y replica los datos mediante CDF en una tabla compartida (como se analizó anteriormente) en las tres nubes para mejorar el rendimiento y reducir los costos de salida de datos. Luego, dentro de cada región de la nube, los datos se pueden compartir con los clientes y socios correspondientes.
Sin embargo, se puede emplear un enfoque nuevo, más eficiente y directo utilizando R2 a través de Cloudflare con Databricks, actualmente en vista previa privada.
La integración de Cloudflare R2 con Databricks permitirá a las organizaciones compartir datos en vivo y colaborar con ellos de manera segura, sencilla y económica. Con Cloudflare y Databricks, los clientes conjuntos pueden eliminar la complejidad y los costos dinámicos que obstaculizan el pleno potencial de las iniciativas de IA y analítica multinube. Específicamente, no habrá tarifas de salida de datos ni necesidad de transferencias de datos complejas o costosas replicaciones de conjuntos de datos entre regiones.
El uso de esta opción requiere los siguientes pasos:
- Agregar Cloudflare R2 como una ubicación de almacenamiento externo (mientras se mantienen los datos de la fuente de verdad en S3/ADLS/etc.)
- Crear nuevas tablas en Cloudflare R2 y sincronizar los datos de forma incremental
- Delta deep clone
- R2 Super Slurper
- Crear un Delta Share, como de costumbre, en la tabla R2
Como se explicó anteriormente, estos enfoques demuestran varios métodos de replicación de datos bajo demanda, cada uno con sus ventajas distintivas y requisitos específicos, lo que los hace adecuados para diversos casos de uso.
Comparación de métodos de replicación de datos para el intercambio entre regiones
Los tres mecanismos anteriores permiten a los usuarios de Delta Sharing crear una copia local para minimizar las tarifas de salida de datos, especialmente entre nubes y regiones. La siguiente tabla proporciona un resumen rápido para diferenciar estas opciones.
| Herramienta de replicación de datos | Aspectos clave | Recomendación |
|---|---|---|
| Change data feed en una tabla compartida |
| Usar para el intercambio externo con socios/clientes entre regiones |
| Cloudflare R2 con Databricks |
| Muy recomendado para Delta Sharing a gran escala en términos de cantidad de recursos compartidos y más de 2 regiones |
| Delta Deep Clone |
| Recomendado al compartir internamente entre regiones |
Delta Sharing es abierto, flexible y rentable, y en Databricks admite una amplia gama de activos de datos, incluidos notebooks, volúmenes y modelos de IA. Además, varias optimizaciones han mejorado significativamente el rendimiento de los protocolos de Delta Sharing. La inversión continua de Databricks en las capacidades de Delta Sharing, que incluye un monitoreo mejorado, escalabilidad, facilidad de uso y observabilidad, subraya su compromiso de mejorar la experiencia del usuario y garantizar que Delta Sharing se mantenga a la vanguardia de la colaboración de datos en el futuro.
Próximos pasos
A lo largo de este blog, hemos brindado orientación arquitectónica basada en nuestra experiencia con muchos clientes de Delta Sharing. Nuestro enfoque principal está en la gestión de costos y el rendimiento. Si bien el intercambio en vivo es adecuado para muchos escenarios de intercambio de datos entre regiones, hemos explorado casos en los que replicar todo el conjunto de datos y establecer un proceso de actualización de datos para las réplicas regionales locales resulta más rentable. Delta Sharing facilita esto mediante el uso de las funcionalidades de Delta Sharing de R2 y CDF, lo que brinda a los usuarios una mayor flexibilidad.
En el caso de uso de intercambio de datos interregional dentro de la empresa, Delta Sharing se destaca al compartir tablas grandes con patrones de acceso variados. La replicación local, facilitada por el intercambio de CDF, garantiza un rendimiento y una gestión de costos óptimos. Además, R2 a través de Cloudflare con Databricks ofrece una opción eficiente para Delta Sharing a gran escala en múltiples regiones y nubes.
Para obtener más información sobre cómo integrar Delta Sharing en su estrategia de colaboración de datos, consulte los recursos más recientes:
- Lea la guía técnica de O'Reilly, Data Sharing and Collaboration with Delta Sharing (versión preliminar)
- Profundice en la documentación de Delta Sharing de Databricks.
- Lea más sobre Delta Sharing: un estándar abierto para el intercambio seguro de datos
- Vea el anuncio en video de Delta Sharing con Matei Zaharia (Keynote de Data + AI Summit 2021)
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.