Databricks se asocia con OpenAI en GPT-5.5
GPT-5.5 establece el rendimiento de vanguardia en el benchmark OfficeQA de Databricks
por Hanlin Tang, Ahmed Bilal, Arnav Singhvi, Ivan Zhou y Harish Gaur
- Databricks se asocia con OpenAI en GPT-5.5
- GPT-5.5 reduce los errores casi a la mitad en OfficeQA Pro
- OpenAI GPT-5.5 y Codex estarán disponibles pronto en Databricks y se regirán a través de Unity AI Gateway
Databricks se complace en asociarse con OpenAI en GPT-5.5, su último modelo de vanguardia. GPT-5.5 es el modelo de vanguardia más potente de OpenAI para el trabajo de agentes en empresas, el razonamiento de documentos complejos y los agentes de codificación de largo alcance. GPT-5.5 también impulsa ahora Codex, el agente de codificación de OpenAI.
Características y beneficios de GPT-5.5
GPT-5.5 es el modelo de vanguardia más inteligente hasta la fecha y el siguiente paso hacia una nueva forma de hacer el trabajo. Comprende lo que intentas hacer más rápidamente y puede asumir más trabajo por sí mismo. Codex, el agente de codificación de OpenAI, ahora está impulsado por GPT-5.5, con capacidades de razonamiento y ejecución más sólidas para los flujos de trabajo de los desarrolladores.
Las mismas fortalezas que hacen que GPT-5.5 sea excelente en codificación también lo hacen potente para el trabajo diario en una computadora. Debido a que el modelo es mejor para comprender la intención, puede moverse de manera más natural a través del ciclo completo del trabajo de conocimiento: encontrar información, comprender lo que importa, usar herramientas, verificar el resultado y convertir material en bruto en algo útil.
Puede escribir y depurar código, investigar en línea, analizar datos, crear documentos y hojas de cálculo, operar software y moverse entre herramientas hasta que se complete una tarea. En lugar de administrar cuidadosamente cada paso, puedes darle a GPT-5.5 una tarea desordenada y de varias partes y confiar en que planificará, usará herramientas, verificará su trabajo, se recuperará de la ambigüedad y seguirá adelante.
GPT-5.5 establece el rendimiento de vanguardia
Para comprender cómo estas mejoras se traducen en cargas de trabajo empresariales reales, evaluamos GPT-5.5 en OfficeQA, el benchmark de Databricks para tareas analíticas complejas y con muchos documentos que los clientes realizan todos los días. OfficeQA, construido a partir de 89,000 páginas de boletines del Tesoro de EE. UU., mide la capacidad de un modelo para recuperar información de documentos, interpretar tablas complejas y realizar cálculos precisos basados en datos empresariales reales.
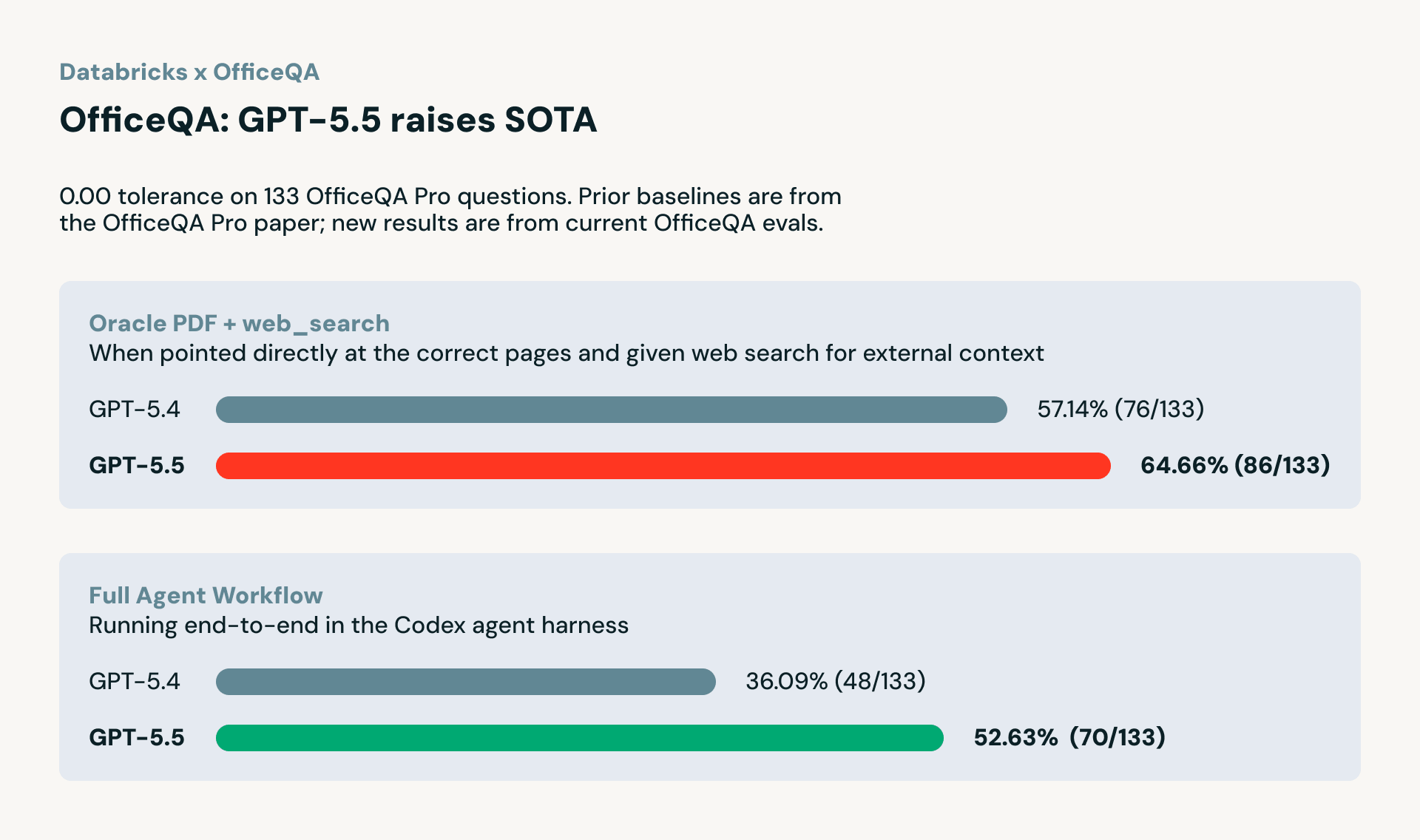
Cuando se le dan los documentos correctos (OfficeQA Pro LLM con Oracle PDF + Búsqueda Web), GPT-5.5 obtuvo un 64.66%, un salto decente desde el 57.14% de GPT-5.4, lo que representa una mejora de ~13% y un nuevo estado del arte en este benchmark. Esto prueba el límite de lo que el modelo puede hacer cuando la recuperación ya está manejada.
En una evaluación de flujo de trabajo de agente completo (OfficeQA Pro Agent Harness), donde el modelo debe encontrar los documentos correctos, analizarlos y calcular respuestas por sí mismo utilizando el arnés del agente Codex, GPT-5.5 obtuvo un 52.63%, frente al 36.10% de GPT-5.4. Eso es una reducción del 46% en errores, lo que demuestra que las ganancias de GPT-5.5 no son solo teóricas; se mantienen en flujos de trabajo empresariales realistas y de extremo a extremo.
GPT-5.5 estará disponible pronto en Databricks. Lleva el razonamiento de vanguardia a tus datos empresariales, de forma segura y a escala.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.