Entrega de contenido de marketing generativo a los clientes
Combinación de datos de clientes y AI generativa para conectar mejor con los clientes, parte 2
por Camden Clark, Joyce Gordon, Ally Hepp, Alex Rees, Tristen Wentling y Bryan Smith
- Personalización escalable: la AI generativa automatiza la creación de contenido de marketing personalizado utilizando datos de clientes de Databricks y Amperity.
- Integración perfecta: Amperity sincroniza los datos de la audiencia con Braze, lo que permite una entrega de contenido precisa a través de Cloud Data Ingestion.
- Entrega dinámica de correos electrónicos: las plantillas de Liquid en Braze personalizan el asunto y el cuerpo de los correos electrónicos, lo que mejora la interacción y las conversiones.

Los profesionales del marketing llevan mucho tiempo soñando con una interacción personalizada uno a uno con el cliente, pero crear el volumen de mensajes necesario para lograr ese nivel de personalización ha sido un gran desafío. Aunque muchas organizaciones aspiran a un marketing más personalizado, a menudo se dirigen a grandes grupos de miles o millones de clientes en los que sigue existiendo una gran diversidad. Aunque esto es mejor que un enfoque genérico y único para todos, las organizaciones preferirían ser más precisas, si tan solo tuvieran el ancho de banda para interactuar a un nivel más detallado.
Como mencionamos en nuestro blog anterior, la AI generativa puede ayudar a facilitar el desafío de crear contenido de marketing altamente personalizado. Aunque lograr una interacción real uno a uno todavía puede ser difícil debido a algunas de las limitaciones de la tecnología en su estado actual, combinar los detalles del cliente con contenido de muestra y un diseño de prompts inteligente (prompt engineering) puede servir para crear, de manera rentable, un volumen manejable de variantes adaptadas. Aplicar modelos independientes para evaluar el contenido generado antes de que pase a una revisión final por parte de un profesional del marketing experto puede contribuir en gran medida a garantizar que este contenido más detallado cumpla con los estándares de la organización y, al mismo tiempo, se alinee de manera más precisa con las necesidades y preferencias de un subsegmento específico.
Pero ¿cómo convertimos esto en un flujo de trabajo confiable? Y lo que es más importante, ¿cómo hacemos llegar realmente todas estas variantes de contenido a los clientes destinatarios utilizando nuestras tecnologías de marketing actuales? En esta publicación, seguimos desarrollando el escenario de la guía de regalos navideños presentado en el blog anterior y demostramos un flujo de trabajo de extremo a extremo para la entrega de contenido por correo electrónico con Amperity y Braze, dos plataformas ampliamente adoptadas en el ecosistema tecnológico de marketing (MarTech) empresarial.
Generación del contenido
En nuestro blog anterior, explicamos cómo diseñar un prompt capaz de activar un modelo de AI generativa para crear un mensaje de correo electrónico de marketing adaptado a los intereses de un subsegmento de la audiencia. El prompt utilizaba un mensaje de correo electrónico de muestra como guía y luego le encargaba al modelo modificar el contenido para que resonara mejor con una audiencia que tuviera sensibilidades de precio y preferencias de actividad específicas (Figura 1).
Figura 1. El prompt desarrollado para la creación de una guía de regalos navideños personalizada
Para aplicar este prompt a escala, necesitamos eliminar los elementos específicos del cliente (como la subcategoría de producto y las preferencias de precio en este ejemplo) e insertar marcadores de posición donde estos elementos puedan introducirse según sea necesario, creando así una plantilla de prompt. Luego, los detalles específicos del cliente se pueden insertar en la plantilla de prompt (alojada en el entorno de Databricks) junto con los detalles del cliente alojados en la plataforma de datos de clientes (CDP).
Dado que utilizamos Amperity como nuestra CDP de demostración, la integración es un proceso bastante sencillo. Mediante la función Amperity Bridge, desarrollada con el protocolo de código abierto Delta Sharing compatible con el entorno de Databricks, simplemente creamos una conexión entre las dos plataformas y compartimos la información adecuada (Figura 2). (Los pasos detallados para configurar la conexión del puente se encuentran aquí).
Figura 2. Un video explicativo sobre cómo conectarse a Databricks a través de Amperity Bridge
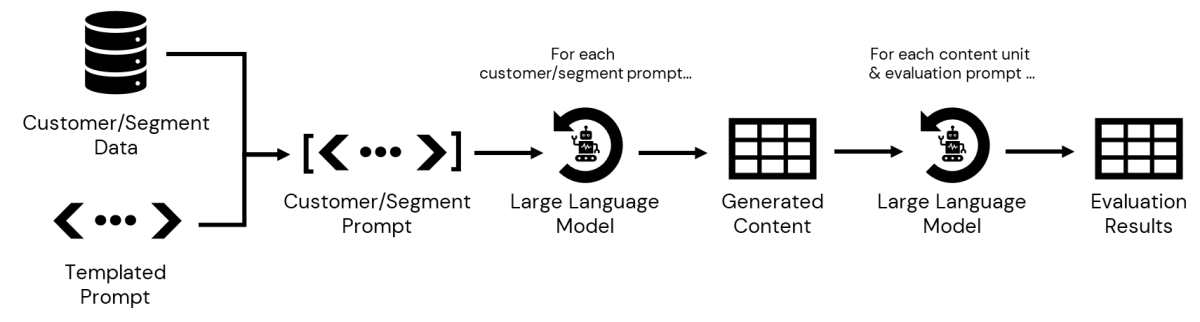
Nuestro siguiente paso es consultar los datos almacenados en la CDP, accesibles dentro de Databricks, para recopilar detalles de cada subsegmento. Una vez definidos, podemos pasar la información asociada con cada uno a nuestro prompt para generar mensajes personalizados. Una vez guardados, podemos iterar sobre el resultado, evaluando cada mensaje generado según varios criterios antes de que ese contenido y los resultados de la evaluación se presenten a un profesional del marketing para su revisión y aprobación final (Figura 3).
{kind=link}
El resultado final de este proceso es una tabla de variantes de contenido, una para cada combinación de punto de precio preferido y subcategoría de producto, junto con una tabla de resultados de evaluación para cada paso de la evaluación. Los datos ya están listos para la revisión del profesional del marketing.
NOTA: Para obtener una implementación técnica detallada del flujo de trabajo de la Figura 3, consulte este notebook.
Entrega del contenido
Una vez creadas nuestras variantes de contenido, podemos centrarnos en la entrega. Los detalles exactos de cómo llevar a cabo este paso dependen de la plataforma de entrega específica que esté utilizando. Para nuestra demostración, veremos cómo se puede entregar este contenido utilizando Braze, una plataforma líder de interacción con el cliente (Customer Engagement Platform) ampliamente adoptada en las organizaciones de marketing.
A grandes rasgos, los pasos necesarios para entregar este contenido a través de Braze son los siguientes:
- Enviar las variantes de contenido a Braze
- Identificar a los miembros de la audiencia que recibirán el contenido
- Conectar a los miembros de la audiencia con variantes de contenido específicas
Enviar variantes de contenido a Braze
Dentro de Braze, el contenido empleado como parte de una campaña se define como un Braze Catalog. Mediante la ingesta de datos en la nube de Braze (Braze Cloud Data Ingestion), este contenido se puede leer desde Databricks siempre que se presente dentro de una tabla o vista que contenga un identificador único (ID), un campo de fecha y hora que indique cuándo se actualizó el contenido por última vez (UPDATED_AT) y un payload JSON (PAYLOAD) con elementos de título y cuerpo que se utilizarán para construir el contenido entregado.
Para ilustrar cómo podríamos construir este conjunto de datos, supongamos que el resultado de nuestro flujo de trabajo de generación de contenido (como se muestra en la Figura 4) dio lugar a una tabla de contenido con la siguiente estructura, donde preferred_price_point y holiday_preferred_subcategory representan los detalles del subsegmento únicos para cada registro de la tabla:
Podríamos definir una vista de esta tabla para estructurarla para su implementación como un catálogo de Braze de la siguiente manera:
Dentro de Braze, ahora podemos definir un catálogo para este contenido (Figura 3).
Figura 3. El catálogo de Braze destinado a albergar nuestro contenido generado
Luego, configuramos una sincronización de Cloud Data Ingestion (CDI), conectando la vista de Databricks a la estructura del catálogo de Braze, y la configuramos para la sincronización, asegurando que se mantenga actualizada (Figura 4).
Figura 4. La sincronización de Cloud Data Ingestion (CDI) que mapea el catálogo de Braze con la vista de contenido de Databricks
Identificar a los miembros de la audiencia
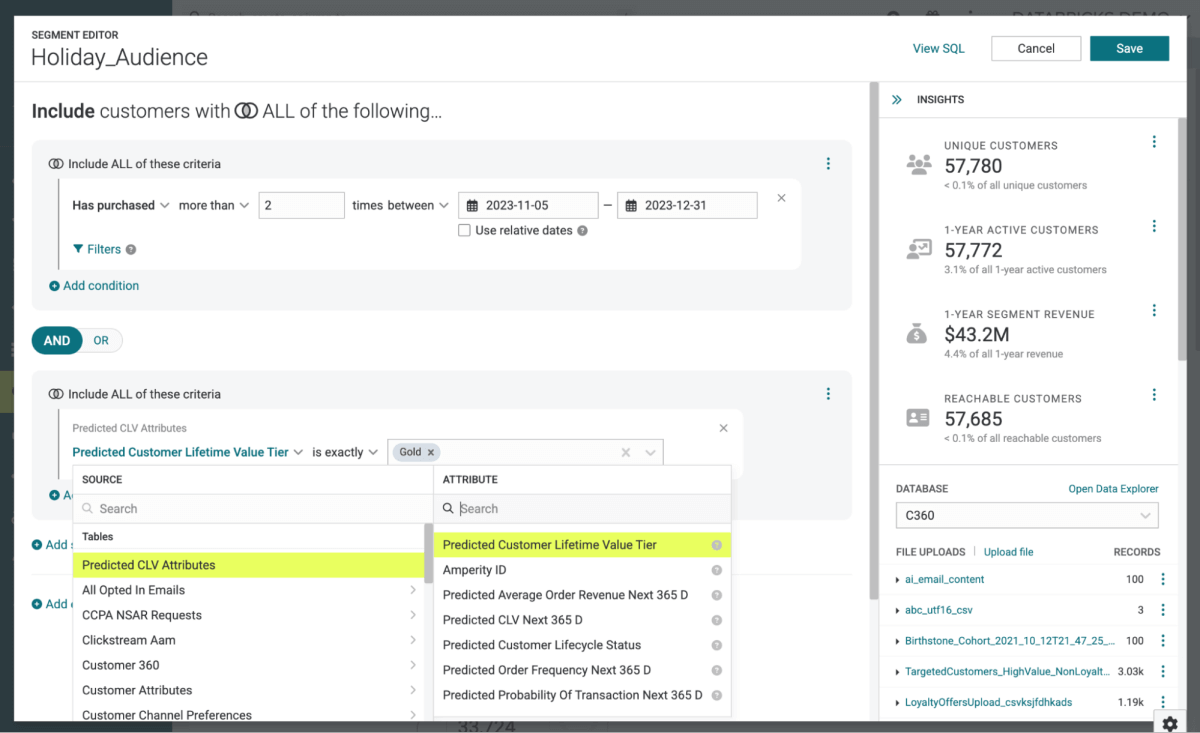
Ahora necesitamos los detalles de las personas a las que queremos enviar este contenido. Como nuestro objetivo es entregar este contenido por correo electrónico, necesitaremos las direcciones de correo electrónico de las personas destinatarias. También pueden ser necesarios elementos como el nombre y el apellido para que el contenido se pueda dirigir al destinatario de una manera más personalizada. Y necesitaremos detalles sobre cómo se alinean las personas con la subcategoría de productos y las preferencias de precios. Este último elemento será esencial para conectar a los miembros de la audiencia con las variaciones de contenido específicas alojadas en el catálogo de Braze.
Dado que utilizamos Amperity como nuestra CDP, enviar esta información a Braze es tan sencillo como definir el grupo de destinatarios como una audiencia y utilizar el conector de Amperity para transferir estos detalles (Figura 5).
{kind=link}
Conectar a los miembros de la audiencia con las variantes de contenido
Con todos los elementos listos en Braze, ahora podemos conectar a los miembros de la audiencia con variantes de contenido específicas y programar el envío. Esto se hace dentro de Braze utilizando plantillas de Liquid, un lenguaje de plantillas de código abierto desarrollado por Shopify y escrito en Ruby. Este lenguaje es muy accesible para los profesionales del marketing y les permite definir contenido personalizable para su distribución a gran escala.
Primeros pasos
Databricks se utiliza cada vez más en las empresas como el núcleo central para las capacidades de datos y analítica. Con capacidades de IA generativa integradas y altamente extensibles, así como una profunda integración con una variedad de plataformas complementarias como la CDP de Amperity y la plataforma de interacción con el cliente de Braze, las organizaciones están creando una amplia gama de aplicaciones como la que se muestra en este blog, con Databricks en el centro.
Si deseas obtener más información sobre cómo se puede utilizar Databricks para ayudar a tus equipos de marketing a crear y ofrecer contenido más personalizado a tus clientes, ponte en contacto con nosotros y analicemos las diversas opciones disponibles para desarrollar soluciones utilizando la plataforma.
Este proceso aprovecha varios componentes clave y utiliza el siguiente flujo de trabajo:
- Estructura e ingesta de contenido
- Se crea una vista a partir de la tabla de variantes de contenido, estructurada para su uso por Braze Cloud Data Ingestion
- Se crea un catálogo de Braze como repositorio para las variantes de contenido
- Se configura una sincronización de Cloud Data Ingestion, y Braze sincroniza las variantes de contenido desde la vista hacia el catálogo
- Activación de audiencia de Amperity: Amperity sincroniza la audiencia de usuarios para quienes se creó el contenido con Braze para una segmentación precisa.
- Construcción de campañas y plantillas de Liquid
- Se utiliza el lenguaje de plantillas de Liquid para hacer referencia a la fila correspondiente en el catálogo de variantes de contenido.
- Liquid completa dinámicamente el asunto y el cuerpo del correo electrónico, de forma personalizada para cada usuario.
Paso 3: Construcción de campañas y plantillas de Liquid
La etapa final consiste en crear la campaña de Braze.
Las plantillas de Liquid desempeñan un papel fundamental aquí, ya que permiten la inserción dinámica del contenido generado en función de los atributos de usuario almacenados en los perfiles de Braze. Se hace referencia a estos atributos, sincronizados mediante la activación de Amperity, para crear un ID de fila de catálogo coincidente. Luego, este ID se utiliza para recuperar e insertar la línea de asunto y el cuerpo del texto generados en el correo electrónico.
3a. Email Subject LineUsing Liquid filters, we combine the `preferred_price_point` and `holiday_preferred_subcategory` attributes, separated by an underscore, to create a local `identifier` variable:
Este `identifier` generado dinámicamente se utiliza luego para hacer referencia al ID correspondiente en el catálogo HolidayGenAI:
Figura 5. Captura de pantalla de la configuración de envío con Liquid
Para un usuario con un `preferred_price_point` alto y una `holiday_preferred_subcategory` de Hiking, el resultado de Liquid en la línea de asunto del correo electrónico se derivará del título del elemento del catálogo coincidente:
Figura 6. Elemento del catálogo que muestra la fila correspondiente
3b. Cuerpo del correo electrónico
Podemos seguir el mismo enfoque para incorporar el contenido generado al cuerpo del correo electrónico.
El resultado final es un correo electrónico que extrae dinámicamente el contenido generativo, personalizado según el punto de precio y la subcategoría preferidos de cada usuario, lo que genera una mejor interacción y mayores tasas de conversión.
Figura 7. Captura de pantalla del correo electrónico
Este caso de uso podría ampliarse aún más para incluir la adición de imágenes generativas o incluso el uso de Connected Content para consultar un endpoint de Databricks directamente en el momento del envío.
Para obtener una implementación técnica detallada del flujo de trabajo de la Figura 3, consulta este notebook.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.