Delta UniForm: un formato universal para la interoperabilidad del lakehouse
por Bilal Obeidat, Sirui Sun, Adam Wasserman, Susan Pierce, Fred Liu, Ryan Johnson y Himanshu Raja
Actualización: BigQuery ahora ofrece soporte nativo para Delta Lake a través de BigLake. Consulte la documentación para obtener más información.
Uno de los desafíos clave que enfrentan las organizaciones al adoptar el lakehouse de datos abierto es la selección del formato óptimo para sus datos. Entre las opciones disponibles, Linux Foundation Delta Lake, Apache Iceberg y Apache Hudi son excelentes formatos de almacenamiento que permiten la democratización e interoperabilidad de los datos. Cualquiera de estos formatos es mejor que poner sus datos en un formato propietario. Sin embargo, elegir un único formato de almacenamiento para estandarizar puede ser una tarea desalentadora, lo que puede resultar en fatiga de decisión y miedo a consecuencias irreversibles.
Delta UniForm (abreviatura de Delta Lake Universal Format) ofrece una unificación simple, fácil de implementar y sin interrupciones de los formatos de tabla sin crear copias de datos o silos adicionales. En este blog, cubriremos lo siguiente:
- Una introducción a Delta UniForm y sus beneficios
- Lectura de Delta UniForm como tablas Iceberg usando
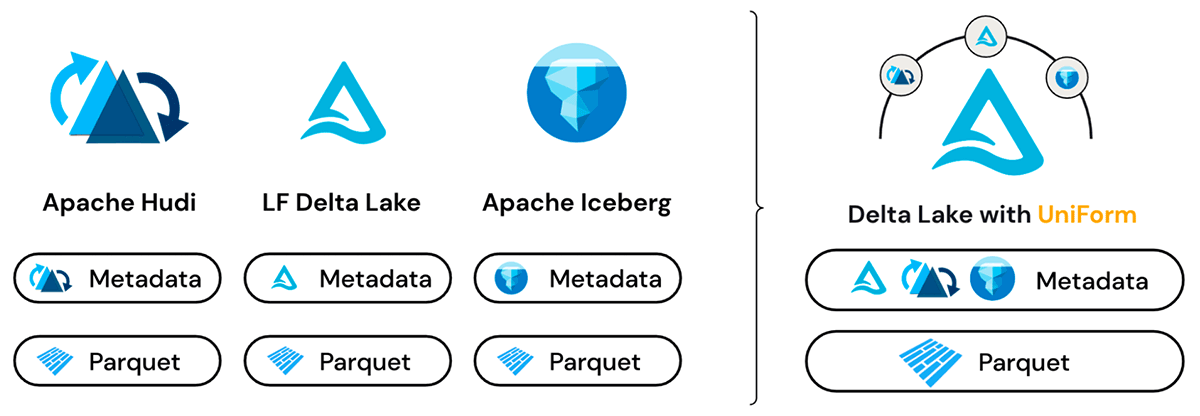
Múltiples formatos, una sola copia de datos
Delta UniForm aprovecha el hecho de que Delta Lake, Iceberg y Hudi están construidos sobre archivos de datos de Apache Parquet. La principal diferencia entre los formatos está en la capa de metadatos, e incluso entonces, las diferencias son sutiles. Los metadatos de los tres formatos cumplen el mismo propósito y contienen conjuntos de información superpuestos.
Antes del lanzamiento de Delta UniForm, las formas de cambiar entre formatos de tabla abiertos eran basadas en copias o conversiones y solo proporcionaban una vista de los datos en un momento dado. En contraste, Delta UniForm resuelve las necesidades de interoperabilidad de manera más elegante al proporcionar una vista en vivo de los datos para todos los lectores, independientemente del formato.
Bajo el capó, Delta UniForm funciona generando automáticamente los metadatos para Iceberg y Hudi junto con Delta Lake, todo contra una sola copia de los datos de Parquet. Como resultado, los equipos pueden usar la herramienta más adecuada para cada carga de trabajo de datos y todos operan sobre una única fuente de datos, con una interoperabilidad perfecta entre los tres ecosistemas diferentes.
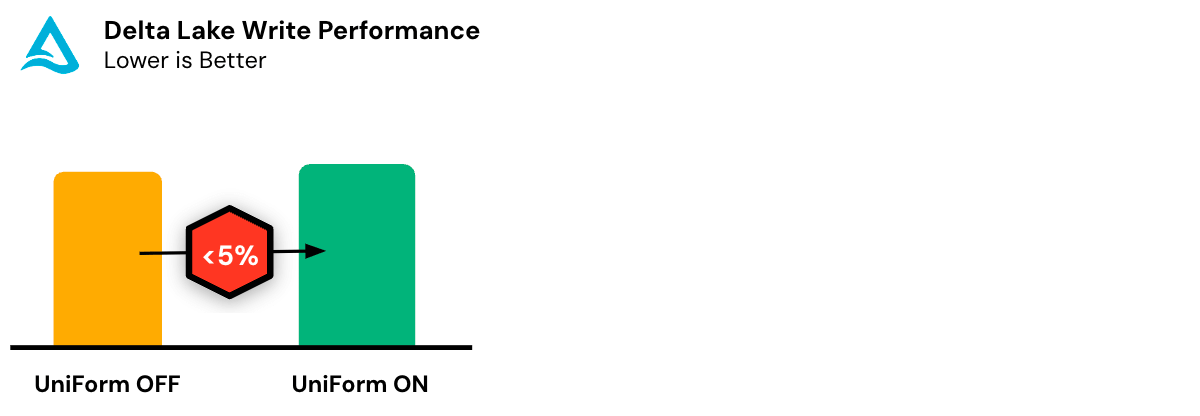
Configuración rápida, sobrecarga mínima
Delta UniForm es extremadamente fácil de configurar y, una vez habilitado, funciona de manera fluida y automática.
Para empezar, creemos una tabla Delta UniForm para generar metadatos de Iceberg:
Con las tablas Delta UniForm, los metadatos para los formatos adicionales se crean automáticamente al crear la tabla y se actualizan cada vez que la tabla se modifica. Esto significa que no hay necesidad de comandos de actualización manuales ni de ejecutar cómputos innecesarios para traducir formatos de tabla. Por ejemplo, escribamos una fila en esta tabla:
Este comando activa una confirmación de Delta Lake, que luego genera automática y asincrónicamente los metadatos de Iceberg para esta tabla. Al hacer esto, Delta UniForm asegura que los pipelines de datos no se interrumpan, permitiendo un acceso fluido a la información más actualizada para todos los lectores.
Delta UniForm tiene una sobrecarga de rendimiento y recursos insignificante, lo que garantiza una utilización óptima de los recursos computacionales. Incluso para tablas a escala de petabytes, los metadatos suelen ser una fracción minúscula del tamaño de los archivos de datos. Además, Delta UniForm puede generar metadatos incrementalmente, limitados solo a los cambios desde la última confirmación.
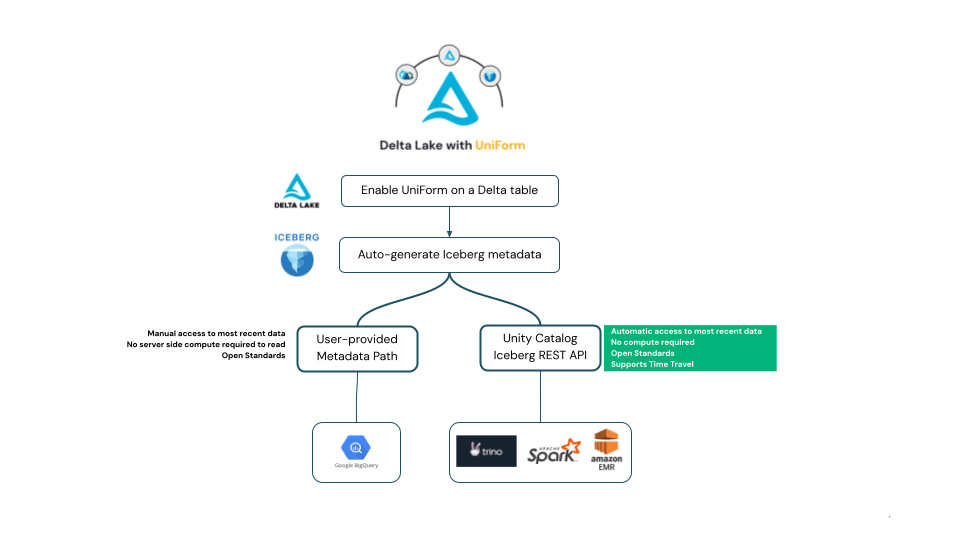
Lectura de Delta UniForm como Iceberg
Delta UniForm genera metadatos de Iceberg de acuerdo con la especificación de Apache Iceberg, lo que significa que cuando los datos se escriben en una tabla Delta UniForm, la tabla puede ser leída como Iceberg por cualquier cliente en el ecosistema de Iceberg que se adhiera a la especificación de código abierto de Iceberg.
Según la especificación de Iceberg, los clientes lectores deben determinar qué metadatos de Iceberg representan la versión más reciente y actualizada de la tabla de Iceberg. En todo el ecosistema de Iceberg, hemos visto que los clientes adoptan dos enfoques diferentes para esto, ambos compatibles con UniForm. Explicaremos las diferencias aquí y luego proporcionaremos ejemplos en la siguiente sección.
Algunos lectores de Iceberg requieren que los usuarios proporcionen la ruta a un archivo de metadatos que represente la última instantánea de la tabla de Iceberg. Este enfoque puede ser engorroso para los clientes, ya que requiere que los usuarios proporcionen rutas de archivo de metadatos actualizadas cada vez que la tabla cambia.
Como alternativa, la comunidad de Iceberg recomienda usar la API de catálogo REST. El cliente habla con el catálogo para obtener el último estado de la tabla, lo que permite a los usuarios leer el último estado de una tabla de Iceberg sin actualizaciones manuales ni preocuparse por las rutas de metadatos.
Unity Catalog ahora implementa la API REST de catálogo abierta de Iceberg de acuerdo con la especificación de Apache Iceberg. Esto está alineado con el compromiso de Unity Catalog de admitir API abiertas, y se basa en el impulso del soporte de la API HMS de Unity Catalog. La API REST de catálogo de Iceberg de Unity Catalog ofrece acceso abierto a tablas UniForm en formato Iceberg sin cargos por cómputo de Databricks, al tiempo que permite la interoperabilidad y el soporte de actualización automática para acceder a los datos más recientes. Como subproducto, esto debería permitir que otros catálogos se federen a Unity Catalog y admitan tablas Delta UniForm.
Las bibliotecas cliente de Apache Iceberg vienen preempaquetadas con la capacidad de interactuar con el Catálogo de API REST de Iceberg; esto significa que cualquier cliente que implemente completamente el estándar Apache Iceberg y tenga soporte para configurar puntos de conexión de catálogo debería poder acceder fácilmente al Catálogo de API REST de Iceberg de Unity Catalog y recuperar los metadatos más recientes de sus tablas. Esto elimina la tarea de administrar los metadatos de la tabla.
En la siguiente sección, veremos ejemplos del soporte de Delta UniForm para ambos enfoques: la ruta de metadatos y la API de catálogo REST de Iceberg.
Ejemplo: leer Delta Lake como Iceberg en BigQuery proporcionando la ubicación de los metadatos
Al leer Iceberg en un catálogo existente, BigQuery requiere que proporciones un puntero al archivo JSON que representa la última instantánea de Iceberg (documentación de BigQuery), como la siguiente:
En BigQuery:
Delta UniForm con Unity Catalog facilita la búsqueda de la ruta del archivo de metadatos de Iceberg requerida. Unity Catalog expone una serie de propiedades de tabla de Delta Lake, incluida esta ruta. Puedes recuperar la ubicación de los metadatos de tu tabla Delta UniForm a través de la UI o la API.
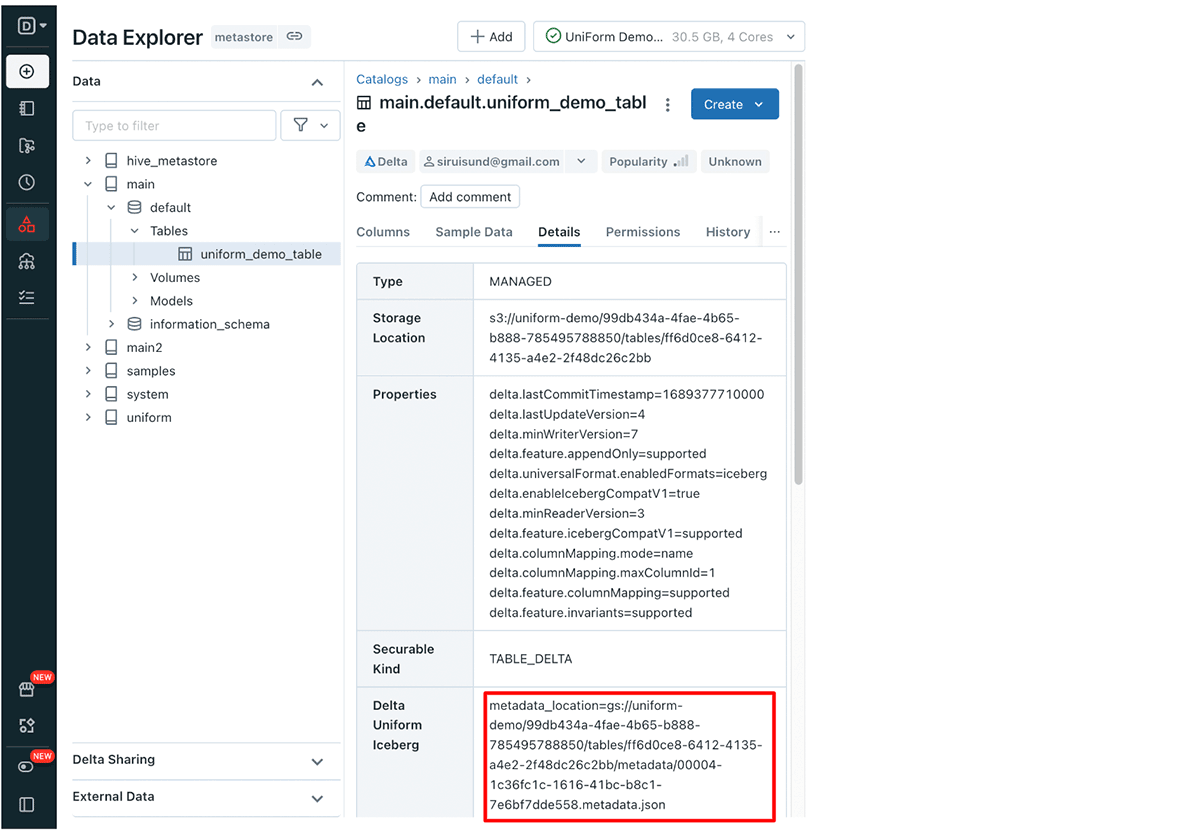
Recuperación de la ruta de metadatos de Iceberg de Delta UniForm a través de la UI:
Navega a tu tabla Delta UniForm en el Explorador de Datos de Databricks, luego haz clic en la pestaña Detalles. Aquí, encontrarás la fila Delta UniForm Iceberg que contiene la ruta de los metadatos.
En Databricks:
Recuperación de la ubicación de metadatos de Iceberg de Delta UniForm a través de la API:
Desde la herramienta de tu elección, envía la siguiente solicitud GET para recuperar la ubicación de los metadatos de Iceberg de tu tabla Delta UniForm.
El campo delta_uniform_iceberg.metadata_location en la respuesta contiene la ubicación de los metadatos para la última instantánea de Iceberg.
Simplemente pega la ubicación de la interfaz de usuario o de los métodos de la API descritos anteriormente en el comando de BigQuery mencionado, y BigQuery leerá la instantánea como Iceberg.
Si tu tabla se actualiza, tendrás que proporcionar a BigQuery la ubicación de metadatos actualizada para leer los datos más recientes. Para casos de uso en producción, deberías añadir un paso en tu pipeline de ingesta que actualice BigQuery con la(s) última(s) ruta(s) de metadatos de Iceberg cada vez que escribas en la tabla Delta UniForm. Ten en cuenta que la necesidad de actualizar la ruta de metadatos es una limitación general de este enfoque y no es específica de UniForm.
Ejemplo: Leer Delta Lake como Iceberg en Trino a través de la API REST de Catálogo
Leamos ahora la misma tabla Delta UniForm que creamos anteriormente a través de Trino utilizando la API REST de Catálogo de Iceberg de Unity Catalog.
Nota: UniForm no es necesario para leer tablas Delta con Trino, ya que Trino soporta directamente las tablas Delta. Esto es solo para ilustrar cómo UniForm amplía aún más la interoperabilidad en el ecosistema de código abierto.
Después de configurar Trino, puedes ajustar las propiedades de Iceberg actualizando el archivo etc/catalog/iceberg.properties para configurar Trino para que utilice el punto final del Catálogo de la API REST de Iceberg de Unity Catalog:
Donde:
- UNITY_CATALOG_ICEBERG_URL - la URL del punto final de la API REST de Iceberg de Unity Catalog; tiene la forma: https://{DATABRICKS_WORKSPACE_URL}/api/2.1/unity-catalog/iceberg
- DATABRICKS_WORKSPACE_URL - la URL de tu espacio de trabajo de Databricks, que puedes encontrar navegando a tu espacio de trabajo de Databricks en un navegador web; tiene la forma: mydatabricksworkspace.cloud.databricks.com/?o=1231231231231231
- PERSONAL_ACCESS_TOKEN - un Token de Acceso Personal de Databricks que se puede generar en un espacio de trabajo de Databricks según estas instrucciones
Una vez configurado tu archivo de propiedades, puedes ejecutar la CLI de Trino y emitir una consulta de Iceberg a la tabla Delta UniForm:
Dado que Trino implementa la API REST de Catálogo de Apache Iceberg, no creamos ninguna tabla externa, ni necesitamos proporcionar la ruta a los últimos archivos de metadatos de Iceberg. Trino recupera automáticamente los últimos metadatos de Iceberg de UC y luego lee los datos más recientes en la tabla Delta UniForm.
Es importante tener en cuenta que, desde la perspectiva de Trino, aquí no está sucediendo nada específico de Delta UniForm. Está leyendo una tabla Iceberg, cuyos metadatos se han generado según las especificaciones, y recuperando esos metadatos con una llamada estándar a la API REST a un catálogo de Iceberg.
Esta es la simplicidad de Delta UniForm. Para los escritores y lectores de Delta Lake, la tabla Delta UniForm es una tabla Delta Lake. Para los lectores de Iceberg, la tabla Delta UniForm es una tabla Iceberg, todo en un único conjunto de archivos de datos sin copias innecesarias de datos y tablas.
Impacto de Delta UniForm
A lo largo de su Vista Previa, ya hemos ayudado a muchos clientes a acelerar la interoperabilidad del data lakehouse abierto con Delta UniForm. Las organizaciones pueden escribir una vez en Delta Lake y luego acceder a estos datos de cualquier manera, logrando un rendimiento óptimo, rentabilidad y flexibilidad de datos en diversas cargas de trabajo como ETL, BI y IA, todo ello sin la carga de migraciones costosas y complejas.
"En Instacart, nuestra visión es tener un data lakehouse abierto con una única copia de datos que sea interoperable con todas las plataformas de cómputo. Delta UniForm es fundamental para ese objetivo. Con Delta UniForm, podemos generar tablas de forma rápida y sencilla que se pueden leer como Delta Lake o Iceberg, desbloqueando la interoperabilidad con todas las herramientas de nuestro ecosistema." —Doug Hyde, Ingeniero de Software Senior Staff en Instacart, compartió su experiencia con Delta UniForm
La misión de Databricks es ayudar a los equipos de datos a resolver los problemas más difíciles del mundo, y eso comienza con poder usar la herramienta adecuada para el trabajo correcto sin tener que hacer copias de tus datos. Estamos entusiasmados con las mejoras en interoperabilidad que aporta Delta UniForm y continuaremos invirtiendo en esta área en los próximos años.
Delta UniForm está disponible como parte de la versión candidata de vista previa para Delta Lake 3.0. Los clientes de Databricks también pueden obtener una vista previa de Delta UniForm con la versión 13.2 de Databricks Runtime o el canal de vista previa de Databricks SQL 2023.35.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.